 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRiverine Flood Prediction and Early Warning in Mountainous Regions using Artificial Intelligence
May 24, 2025Flooding is the most devastating phenomenon occurring globally, particularly in mountainous regions, risk dramatically increases due to complex terrains and extreme climate changes. These situations are damaging livelihoods, agriculture, infrastructure, and human lives. This study uses the Kabul River between Pakistan and Afghanistan as a case study to reflect the complications of flood forecasting in transboundary basins. The challenges in obtaining upstream data impede the efficacy of flood control measures and early warning systems, a common global problem in similar basins. Utilizing satellite-based climatic data, this study applied numerous advanced machine-learning and deep learning models, such as Support Vector Machines (SVM), XGBoost, and Artificial Neural Networks (ANN), Long Short-Term Memory (LSTM) networks, and Gated Recurrent Units (GRU) to predict daily and multi-step river flow. The LSTM network outperformed other models, achieving the highest R2 value of 0.96 and the lowest RMSE value of 140.96 m3/sec. The time series LSTM and GRU network models, utilized for short-term forecasts of up to five days, performed significantly. However, the accuracy declined beyond the fourth day, highlighting the need for longer-term historical datasets for reliable long-term flood predictions. The results of the study are directly aligned with Sustainable Development Goals 6, 11, 13, and 15, facilitating disaster and water management, timely evacuations, improved preparedness, and effective early warning.
Modeling of Item-Difficulty for Ontology-based MCQs
Jul 04, 2016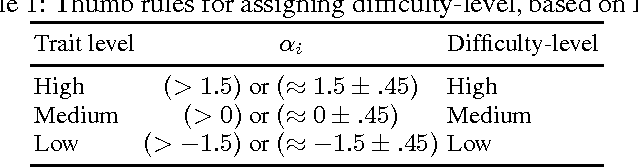
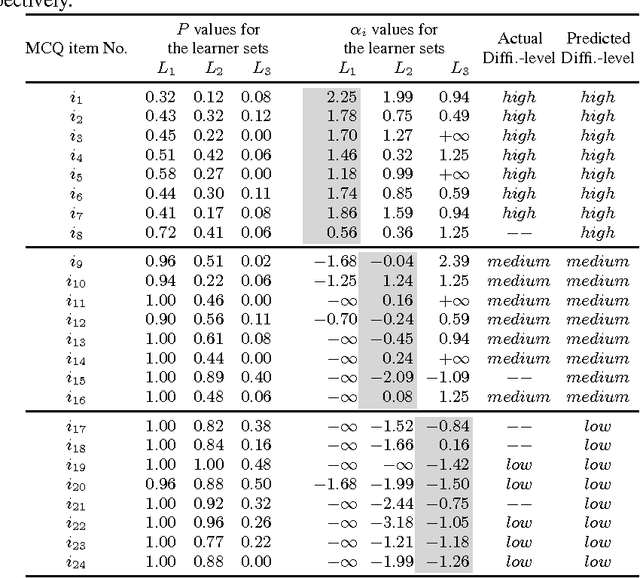
Multiple choice questions (MCQs) that can be generated from a domain ontology can significantly reduce human effort & time required for authoring & administering assessments in an e-Learning environment. Even though here are various methods for generating MCQs from ontologies, methods for determining the difficulty-levels of such MCQs are less explored. In this paper, we study various aspects and factors that are involved in determining the difficulty-score of an MCQ, and propose an ontology-based model for the prediction. This model characterizes the difficulty values associated with the stem and choice set of the MCQs, and describes a measure which combines both the scores. Further more, the notion of assigning difficultly-scores based on the skill level of the test taker is utilized for predicating difficulty-score of a stem. We studied the effectiveness of the predicted difficulty-scores with the help of a psychometric model from the Item Response Theory, by involving real-students and domain experts. Our results show that, the predicated difficulty-levels of the MCQs are having high correlation with their actual difficulty-levels.