 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOLGA : An Ontology and LSTM-based approach for generating Arithmetic Word Problems of transfer type
Nov 22, 2022Machine generation of Arithmetic Word Problems (AWPs) is challenging as they express quantities and mathematical relationships and need to be consistent. ML-solvers require a large annotated training set of consistent problems with language variations. Exploiting domain-knowledge is needed for consistency checking whereas LSTM-based approaches are good for producing text with language variations. Combining these we propose a system, OLGA, to generate consistent word problems of TC (Transfer-Case) type, involving object transfers among agents. Though we provide a dataset of consistent 2-agent TC-problems for training, only about 36% of the outputs of an LSTM-based generator are found consistent. We use an extension of TC-Ontology, proposed by us previously, to determine the consistency of problems. Among the remaining 64%, about 40% have minor errors which we repair using the same ontology. To check consistency and for the repair process, we construct an instance-specific representation (ABox) of an auto-generated problem. We use a sentence classifier and BERT models for this task. The training set for these LMs is problem-texts where sentence-parts are annotated with ontology class-names. As three-agent problems are longer, the percentage of consistent problems generated by an LSTM-based approach drops further. Hence, we propose an ontology-based method that extends consistent 2-agent problems into consistent 3-agent problems. Overall, our approach generates a large number of consistent TC-type AWPs involving 2 or 3 agents. As ABox has all the information of a problem, any annotations can also be generated. Adopting the proposed approach to generate other types of AWPs is interesting future work.
Extracting Ontological Knowledge from Textual Descriptions
Sep 28, 2017


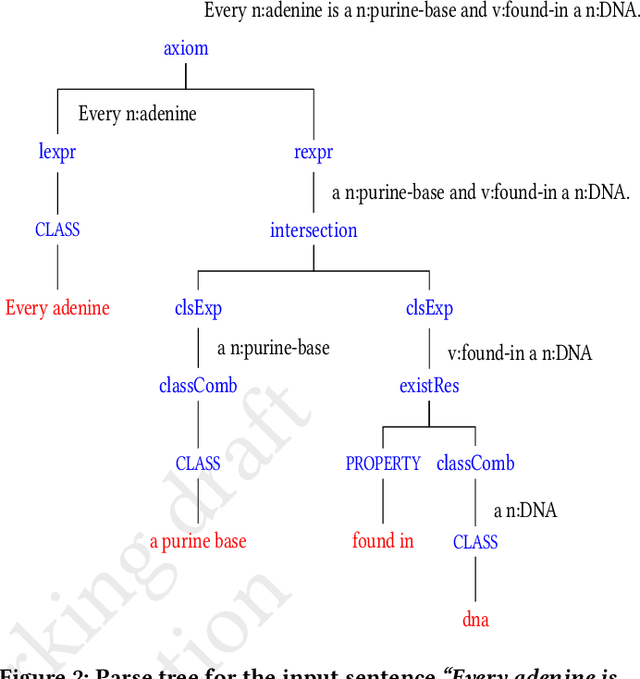
Authoring of OWL-DL ontologies is intellectually challenging and to make this process simpler, many systems accept natural language text as input. A text-based ontology authoring approach can be successful only when it is combined with an effective method for extracting ontological axioms from text. Extracting axioms from unrestricted English input is a substantially challenging task due to the richness of the language. Controlled natural languages (CNLs) have been proposed in this context and these tend to be highly restrictive. In this paper, we propose a new CNL called TEDEI (TExtual DEscription Identifier) whose grammar is inspired by the different ways OWL-DL constructs are expressed in English. We built a system that transforms TEDEI sentences into corresponding OWL-DL axioms. Now, ambiguity due to different possible lexicalizations of sentences and semantic ambiguity present in sentences are challenges in this context. We find that the best way to handle these challenges is to construct axioms corresponding to alternative formalizations of the sentence so that the end-user can make an appropriate choice. The output is compared against human-authored axioms and in substantial number of cases, human-authored axiom is indeed one of the alternatives given by the system. The proposed system substantially enhances the types of sentence structures that can be used for ontology authoring.
Enriching Linked Datasets with New Object Properties
Sep 04, 2017



Although several RDF knowledge bases are available through the LOD initiative, the ontology schema of such linked datasets is not very rich. In particular, they lack object properties. The problem of finding new object properties (and their instances) between any two given classes has not been investigated in detail in the context of Linked Data. In this paper, we present DART (Detecting Arbitrary Relations for enriching T-Boxes of Linked Data) - an unsupervised solution to enrich the LOD cloud with new object properties between two given classes. DART exploits contextual similarity to identify text patterns from the web corpus that can potentially represent relations between individuals. These text patterns are then clustered by means of paraphrase detection to capture the object properties between the two given LOD classes. DART also performs fully automated mapping of the discovered relations to the properties in the linked dataset. This serves many purposes such as identification of completely new relations, elimination of irrelevant relations, and generation of prospective property axioms. We have empirically evaluated our approach on several pairs of classes and found that the system can indeed be used for enriching the linked datasets with new object properties and their instances. We compared DART with newOntExt system which is an offshoot of the NELL (Never-Ending Language Learning) effort. Our experiments reveal that DART gives better results than newOntExt with respect to both the correctness, as well as the number of relations.
Ontology Verbalization using Semantic-Refinement
Oct 31, 2016

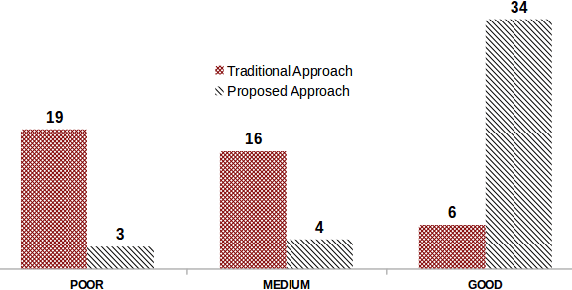
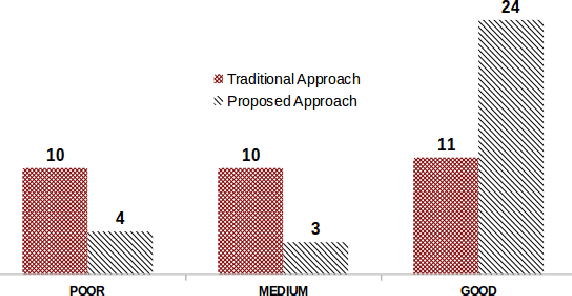
We propose a rule-based technique to generate redundancy-free NL descriptions of OWL entities.The existing approaches which address the problem of verbalizing OWL ontologies generate NL text segments which are close to their counterpart OWL statements.Some of these approaches also perform grouping and aggregating of these NL text segments to generate a more fluent and comprehensive form of the content.Restricting our attention to description of individuals and concepts, we find that the approach currently followed in the available tools is that of determining the set of all logical conditions that are satisfied by the given individual/concept name and translate these conditions verbatim into corresponding NL descriptions.Human-understandability of such descriptions is affected by the presence of repetitions and redundancies, as they have high fidelity to their OWL representation.In the literature, no efforts had been taken to remove redundancies and repetitions at the logical-level before generating the NL descriptions of entities and we find this to be the main reason for lack of readability of the generated text.Herein, we propose a technique called semantic-refinement(SR) to generate meaningful and easily-understandable descriptions of individuals and concepts of a given OWLontology.We identify the combinations of OWL/DL constructs that lead to repetitive/redundant descriptions and propose a series of refinement rules to rewrite the conditions that are satisfied by an individual/concept in a meaning-preserving manner.The reduced set of conditions are then employed for generating NL descriptions.Our experiments show that, SR leads to significantly improved descriptions of ontology entities.We also test the effectiveness and usefulness of the the generated descriptions for the purpose of validating the ontologies and find that the proposed technique is indeed helpful in the context.
Redundancy-free Verbalization of Individuals for Ontology Validation
Jul 24, 2016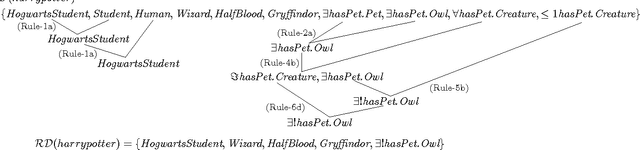

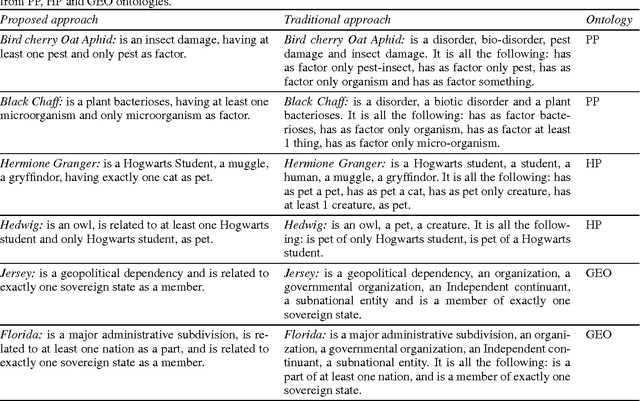

We investigate the problem of verbalizing Web Ontology Language (OWL) axioms of domain ontologies in this paper. The existing approaches address the problem of fidelity of verbalized OWL texts to OWL semantics by exploring different ways of expressing the same OWL axiom in various linguistic forms. They also perform grouping and aggregating of the natural language (NL) sentences that are generated corresponding to each OWL statement into a comprehensible structure. However, no efforts have been taken to try out a semantic reduction at logical level to remove redundancies and repetitions, so that the reduced set of axioms can be used for generating a more meaningful and human-understandable (what we call redundancy-free) text. Our experiments show that, formal semantic reduction at logical level is very helpful to generate redundancy-free descriptions of ontology entities. In this paper, we particularly focus on generating descriptions of individuals of SHIQ based ontologies. The details of a case study are provided to support the usefulness of the redundancy-free NL descriptions of individuals, in knowledge validation application.