 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIndividualised Treatment Effects Estimation with Composite Treatments and Composite Outcomes
Feb 12, 2025



Estimating individualised treatment effect (ITE) -- that is the causal effect of a set of variables (also called exposures, treatments, actions, policies, or interventions), referred to as \textit{composite treatments}, on a set of outcome variables of interest, referred to as \textit{composite outcomes}, for a unit from observational data -- remains a fundamental problem in causal inference with applications across disciplines, such as healthcare, economics, education, social science, marketing, and computer science. Previous work in causal machine learning for ITE estimation is limited to simple settings, like single treatments and single outcomes. This hinders their use in complex real-world scenarios; for example, consider studying the effect of different ICU interventions, such as beta-blockers and statins for a patient admitted for heart surgery, on different outcomes of interest such as atrial fibrillation and in-hospital mortality. The limited research into composite treatments and outcomes is primarily due to data scarcity for all treatments and outcomes. To address the above challenges, we propose a novel and innovative hypernetwork-based approach, called \emph{H-Learner}, to solve ITE estimation under composite treatments and composite outcomes, which tackles the data scarcity issue by dynamically sharing information across treatments and outcomes. Our empirical analysis with binary and arbitrary composite treatments and outcomes demonstrates the effectiveness of the proposed approach compared to existing methods.
Sample Selection Bias in Machine Learning for Healthcare
May 13, 2024



While machine learning algorithms hold promise for personalised medicine, their clinical adoption remains limited. One critical factor contributing to this restraint is sample selection bias (SSB) which refers to the study population being less representative of the target population, leading to biased and potentially harmful decisions. Despite being well-known in the literature, SSB remains scarcely studied in machine learning for healthcare. Moreover, the existing techniques try to correct the bias by balancing distributions between the study and the target populations, which may result in a loss of predictive performance. To address these problems, our study illustrates the potential risks associated with SSB by examining SSB's impact on the performance of machine learning algorithms. Most importantly, we propose a new research direction for addressing SSB, based on the target population identification rather than the bias correction. Specifically, we propose two independent networks (T-Net) and a multitasking network (MT-Net) for addressing SSB, where one network/task identifies the target subpopulation which is representative of the study population and the second makes predictions for the identified subpopulation. Our empirical results with synthetic and semi-synthetic datasets highlight that SSB can lead to a large drop in the performance of an algorithm for the target population as compared with the study population, as well as a substantial difference in the performance for the target subpopulations that are representative of the selected and the non-selected patients from the study population. Furthermore, our proposed techniques demonstrate robustness across various settings, including different dataset sizes, event rates, and selection rates, outperforming the existing bias correction techniques.
GTAGCN: Generalized Topology Adaptive Graph Convolutional Networks
Mar 22, 2024



Graph Neural Networks (GNN) have emerged as a popular and standard approach for learning from graph-structured data. The literature on GNN highlights the potential of this evolving research area and its widespread adoption in real-life applications. However, most of the approaches are either new in concept or derived from specific techniques. Therefore, the potential of more than one approach in hybrid form has not been studied extensively, which can be well utilized for sequenced data or static data together. We derive a hybrid approach based on two established techniques as generalized aggregation networks and topology adaptive graph convolution networks that solve our purpose to apply on both types of sequenced and static nature of data, effectively. The proposed method applies to both node and graph classification. Our empirical analysis reveals that the results are at par with literature results and better for handwritten strokes as sequenced data, where graph structures have not been explored.
A Brief Review of Hypernetworks in Deep Learning
Jun 12, 2023Hypernetworks, or hypernets in short, are neural networks that generate weights for another neural network, known as the target network. They have emerged as a powerful deep learning technique that allows for greater flexibility, adaptability, faster training, information sharing, and model compression etc. Hypernets have shown promising results in a variety of deep learning problems, including continual learning, causal inference, transfer learning, weight pruning, uncertainty quantification, zero-shot learning, natural language processing, and reinforcement learning etc. Despite their success across different problem settings, currently, there is no review available to inform the researchers about the developments and help in utilizing hypernets. To fill this gap, we review the progress in hypernets. We present an illustrative example to train deep neural networks using hypernets and propose to categorize hypernets on five criteria that affect the design of hypernets as inputs, outputs, variability of inputs and outputs, and architecture of hypernets. We also review applications of hypernets across different deep learning problem settings. Finally, we discuss the challenges and future directions that remain under-explored in the field of hypernets. We believe that hypernetworks have the potential to revolutionize the field of deep learning. They offer a new way to design and train neural networks, and they have the potential to improve the performance of deep learning models on a variety of tasks. Through this review, we aim to inspire further advancements in deep learning through hypernetworks.
Dynamic Inter-treatment Information Sharing for Heterogeneous Treatment Effects Estimation
May 25, 2023



Existing heterogeneous treatment effects learners, also known as conditional average treatment effects (CATE) learners, lack a general mechanism for end-to-end inter-treatment information sharing, and data have to be split among potential outcome functions to train CATE learners which can lead to biased estimates with limited observational datasets. To address this issue, we propose a novel deep learning-based framework to train CATE learners that facilitates dynamic end-to-end information sharing among treatment groups. The framework is based on \textit{soft weight sharing} of \textit{hypernetworks}, which offers advantages such as parameter efficiency, faster training, and improved results. The proposed framework complements existing CATE learners and introduces a new class of uncertainty-aware CATE learners that we refer to as \textit{HyperCATE}. We develop HyperCATE versions of commonly used CATE learners and evaluate them on IHDP, ACIC-2016, and Twins benchmarks. Our experimental results show that the proposed framework improves the CATE estimation error via counterfactual inference, with increasing effectiveness for smaller datasets.
Synthesizing Mixed-type Electronic Health Records using Diffusion Models
Feb 28, 2023



Electronic Health Records (EHRs) contain sensitive patient information, which presents privacy concerns when sharing such data. Synthetic data generation is a promising solution to mitigate these risks, often relying on deep generative models such as Generative Adversarial Networks (GANs). However, recent studies have shown that diffusion models offer several advantages over GANs, such as generation of more realistic synthetic data and stable training in generating data modalities, including image, text, and sound. In this work, we investigate the potential of diffusion models for generating realistic mixed-type tabular EHRs, comparing TabDDPM model with existing methods on four datasets in terms of data quality, utility, privacy, and augmentation. Our experiments demonstrate that TabDDPM outperforms the state-of-the-art models across all evaluation metrics, except for privacy, which confirms the trade-off between privacy and utility.
Adversarial De-confounding in Individualised Treatment Effects Estimation
Oct 19, 2022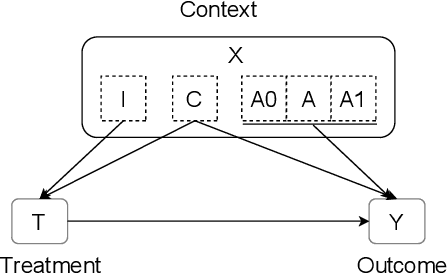

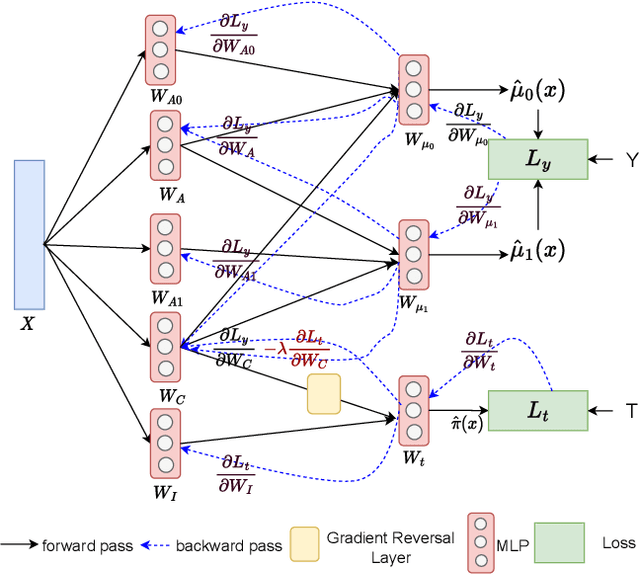
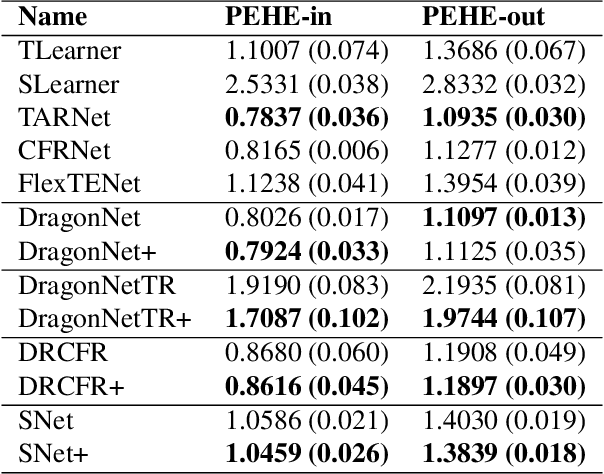
Observational studies have recently received significant attention from the machine learning community due to the increasingly available non-experimental observational data and the limitations of the experimental studies, such as considerable cost, impracticality, small and less representative sample sizes, etc. In observational studies, de-confounding is a fundamental problem of individualised treatment effects (ITE) estimation. This paper proposes disentangled representations with adversarial training to selectively balance the confounders in the binary treatment setting for the ITE estimation. The adversarial training of treatment policy selectively encourages treatment-agnostic balanced representations for the confounders and helps to estimate the ITE in the observational studies via counterfactual inference. Empirical results on synthetic and real-world datasets, with varying degrees of confounding, prove that our proposed approach improves the state-of-the-art methods in achieving lower error in the ITE estimation.
COPER: Continuous Patient State Perceiver
Aug 05, 2022

In electronic health records (EHRs), irregular time-series (ITS) occur naturally due to patient health dynamics, reflected by irregular hospital visits, diseases/conditions and the necessity to measure different vitals signs at each visit etc. ITS present challenges in training machine learning algorithms which mostly are built on assumption of coherent fixed dimensional feature space. In this paper, we propose a novel COntinuous patient state PERceiver model, called COPER, to cope with ITS in EHRs. COPER uses Perceiver model and the concept of neural ordinary differential equations (ODEs) to learn the continuous time dynamics of patient state, i.e., continuity of input space and continuity of output space. The neural ODEs help COPER to generate regular time-series to feed to Perceiver model which has the capability to handle multi-modality large-scale inputs. To evaluate the performance of the proposed model, we use in-hospital mortality prediction task on MIMIC-III dataset and carefully design experiments to study irregularity. The results are compared with the baselines which prove the efficacy of the proposed model.
HCR-Net: A deep learning based script independent handwritten character recognition network
Aug 15, 2021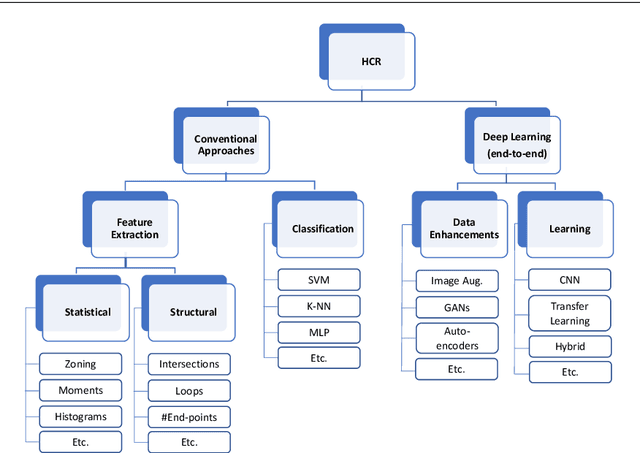
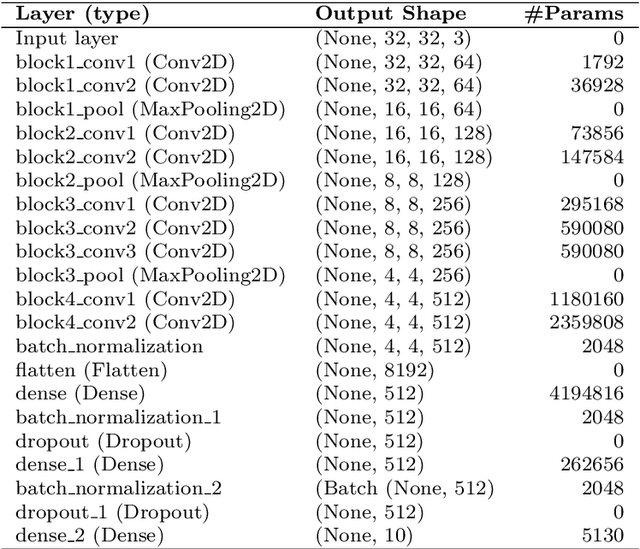


Handwritten character recognition (HCR) is a challenging learning problem in pattern recognition, mainly due to similarity in structure of characters, different handwriting styles, noisy datasets and a large variety of languages and scripts. HCR problem is studied extensively for a few decades but there is very limited research on script independent models. This is because of factors, like, diversity of scripts, focus of the most of conventional research efforts on handcrafted feature extraction techniques which are language/script specific and are not always available, and unavailability of public datasets and codes to reproduce the results. On the other hand, deep learning has witnessed huge success in different areas of pattern recognition, including HCR, and provides end-to-end learning, i.e., automated feature extraction and recognition. In this paper, we have proposed a novel deep learning architecture which exploits transfer learning and image-augmentation for end-to-end learning for script independent handwritten character recognition, called HCR-Net. The network is based on a novel transfer learning approach for HCR, where some of lower layers of a pre-trained VGG16 network are utilised. Due to transfer learning and image-augmentation, HCR-Net provides faster training, better performance and better generalisations. The experimental results on publicly available datasets of Bangla, Punjabi, Hindi, English, Swedish, Urdu, Farsi, Tibetan, Kannada, Malayalam, Telugu, Marathi, Nepali and Arabic languages prove the efficacy of HCR-Net and establishes several new benchmarks. For reproducibility of the results and for the advancements of the HCR research, complete code is publicly released at \href{https://github.com/jmdvinodjmd/HCR-Net}{GitHub}.
LIBS2ML: A Library for Scalable Second Order Machine Learning Algorithms
Apr 20, 2019
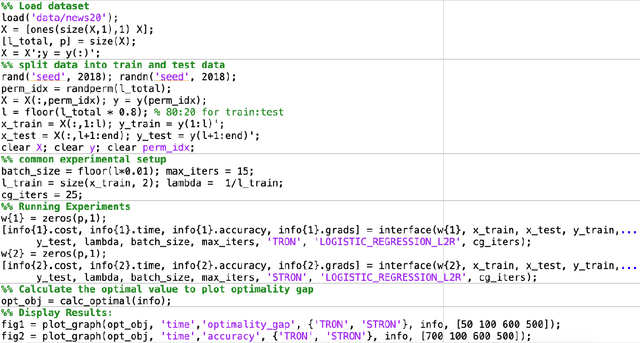
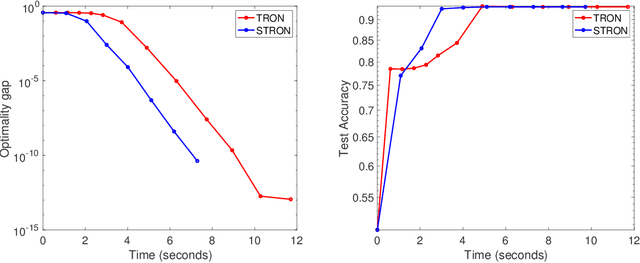
LIBS2ML is a library based on scalable second order learning algorithms for solving large-scale problems, i.e., big data problems in machine learning. LIBS2ML has been developed using MEX files, i.e., C++ with MATLAB/Octave interface to take the advantage of both the worlds, i.e., faster learning using C++ and easy I/O using MATLAB. Most of the available libraries are either in MATLAB/Python/R which are very slow and not suitable for large-scale learning, or are in C/C++ which does not have easy ways to take input and display results. So LIBS2ML is completely unique due to its focus on the scalable second order methods, the hot research topic, and being based on MEX files. Thus it provides researchers a comprehensive environment to evaluate their ideas and it also provides machine learning practitioners an effective tool to deal with the large-scale learning problems. LIBS2ML is an open-source, highly efficient, extensible, scalable, readable, portable and easy to use library. The library can be downloaded from the URL: \url{https://github.com/jmdvinodjmd/LIBS2ML}.