 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHyperNet-Adaptation for Diffusion-Based Test Case Generation
Jan 21, 2026The increasing deployment of deep learning systems requires systematic evaluation of their reliability in real-world scenarios. Traditional gradient-based adversarial attacks introduce small perturbations that rarely correspond to realistic failures and mainly assess robustness rather than functional behavior. Generative test generation methods offer an alternative but are often limited to simple datasets or constrained input domains. Although diffusion models enable high-fidelity image synthesis, their computational cost and limited controllability restrict their applicability to large-scale testing. We present HyNeA, a generative testing method that enables direct and efficient control over diffusion-based generation. HyNeA provides dataset-free controllability through hypernetworks, allowing targeted manipulation of the generative process without relying on architecture-specific conditioning mechanisms or dataset-driven adaptations such as fine-tuning. HyNeA employs a distinct training strategy that supports instance-level tuning to identify failure-inducing test cases without requiring datasets that explicitly contain examples of similar failures. This approach enables the targeted generation of realistic failure cases at substantially lower computational cost than search-based methods. Experimental results show that HyNeA improves controllability and test diversity compared to existing generative test generators and generalizes to domains where failure-labeled training data is unavailable.
Benchmarking Generative AI Models for Deep Learning Test Input Generation
Dec 23, 2024



Test Input Generators (TIGs) are crucial to assess the ability of Deep Learning (DL) image classifiers to provide correct predictions for inputs beyond their training and test sets. Recent advancements in Generative AI (GenAI) models have made them a powerful tool for creating and manipulating synthetic images, although these advancements also imply increased complexity and resource demands for training. In this work, we benchmark and combine different GenAI models with TIGs, assessing their effectiveness, efficiency, and quality of the generated test images, in terms of domain validity and label preservation. We conduct an empirical study involving three different GenAI architectures (VAEs, GANs, Diffusion Models), five classification tasks of increasing complexity, and 364 human evaluations. Our results show that simpler architectures, such as VAEs, are sufficient for less complex datasets like MNIST. However, when dealing with feature-rich datasets, such as ImageNet, more sophisticated architectures like Diffusion Models achieve superior performance by generating a higher number of valid, misclassification-inducing inputs.
Deep Learning System Boundary Testing through Latent Space Style Mixing
Aug 12, 2024Evaluating the behavioral frontier of deep learning (DL) systems is crucial for understanding their generalizability and robustness. However, boundary testing is challenging due to their high-dimensional input space. Generative artificial intelligence offers a promising solution by modeling data distribution within compact latent space representations, thereby facilitating finer-grained explorations. In this work, we introduce MIMICRY, a novel black-box system-agnostic test generator that leverages these latent representations to generate frontier inputs for the DL systems under test. Specifically, MIMICRY uses style-based generative adversarial networks trained to learn the representation of inputs with disentangled features. This representation enables embedding style-mixing operations between a source and a target input, combining their features to explore the boundary between them. We evaluated the effectiveness of different MIMICRY configurations in generating boundary inputs for four popular DL image classification systems. Our results show that manipulating the latent space allows for effective and efficient exploration of behavioral frontiers. As opposed to a model-based baseline, MIMICRY generates a higher quality frontier of behaviors which includes more and closer inputs. Additionally, we assessed the validity of these inputs, revealing a high validity rate according to human assessors.
Two is Better Than One: Digital Siblings to Improve Autonomous Driving Testing
May 14, 2023Simulation-based testing represents an important step to ensure the reliability of autonomous driving software. In practice, when companies rely on third-party general-purpose simulators, either for in-house or outsourced testing, the generalizability of testing results to real autonomous vehicles is at stake. In this paper, we strengthen simulation-based testing by introducing the notion of digital siblings, a novel framework in which the AV is tested on multiple general-purpose simulators, built with different technologies. First, test cases are automatically generated for each individual simulator. Then, tests are migrated between simulators, using feature maps to characterize of the exercised driving conditions. Finally, the joint predicted failure probability is computed and a failure is reported only in cases of agreement among the siblings. We implemented our framework using two open-source simulators and we empirically compared it against a digital twin of a physical scaled autonomous vehicle on a large set of test cases. Our study shows that the ensemble failure predictor by the digital siblings is superior to each individual simulator at predicting the failures of the digital twin. We discuss several ways in which our framework can help researchers interested in automated testing of autonomous driving software.
When and Why Test Generators for Deep Learning Produce Invalid Inputs: an Empirical Study
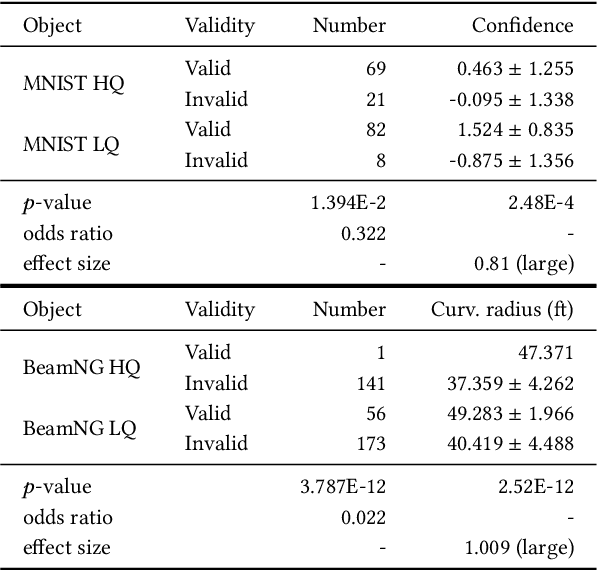
Dec 21, 2022Testing Deep Learning (DL) based systems inherently requires large and representative test sets to evaluate whether DL systems generalise beyond their training datasets. Diverse Test Input Generators (TIGs) have been proposed to produce artificial inputs that expose issues of the DL systems by triggering misbehaviours. Unfortunately, such generated inputs may be invalid, i.e., not recognisable as part of the input domain, thus providing an unreliable quality assessment. Automated validators can ease the burden of manually checking the validity of inputs for human testers, although input validity is a concept difficult to formalise and, thus, automate. In this paper, we investigate to what extent TIGs can generate valid inputs, according to both automated and human validators. We conduct a large empirical study, involving 2 different automated validators, 220 human assessors, 5 different TIGs and 3 classification tasks. Our results show that 84% artificially generated inputs are valid, according to automated validators, but their expected label is not always preserved. Automated validators reach a good consensus with humans (78% accuracy), but still have limitations when dealing with feature-rich datasets.
DeepMetis: Augmenting a Deep Learning Test Set to Increase its Mutation Score
Sep 15, 2021
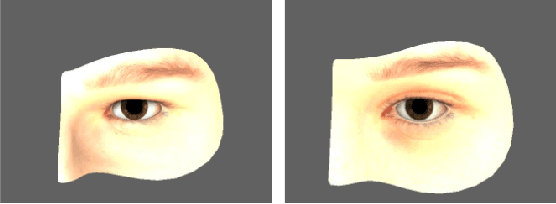

Deep Learning (DL) components are routinely integrated into software systems that need to perform complex tasks such as image or natural language processing. The adequacy of the test data used to test such systems can be assessed by their ability to expose artificially injected faults (mutations) that simulate real DL faults. In this paper, we describe an approach to automatically generate new test inputs that can be used to augment the existing test set so that its capability to detect DL mutations increases. Our tool DeepMetis implements a search based input generation strategy. To account for the non-determinism of the training and the mutation processes, our fitness function involves multiple instances of the DL model under test. Experimental results show that \tool is effective at augmenting the given test set, increasing its capability to detect mutants by 63% on average. A leave-one-out experiment shows that the augmented test set is capable of exposing unseen mutants, which simulate the occurrence of yet undetected faults.
DeepHyperion: Exploring the Feature Space of Deep Learning-Based Systems through Illumination Search
Jul 05, 2021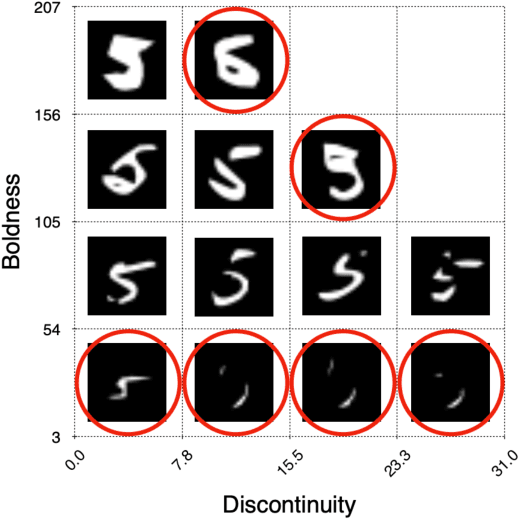
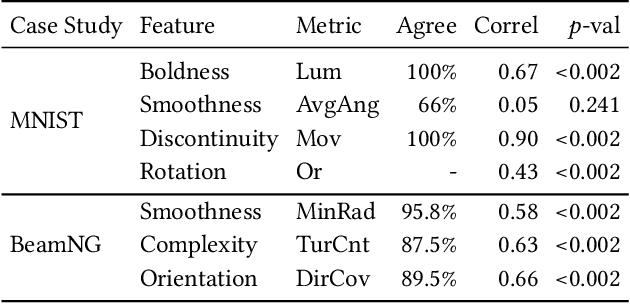
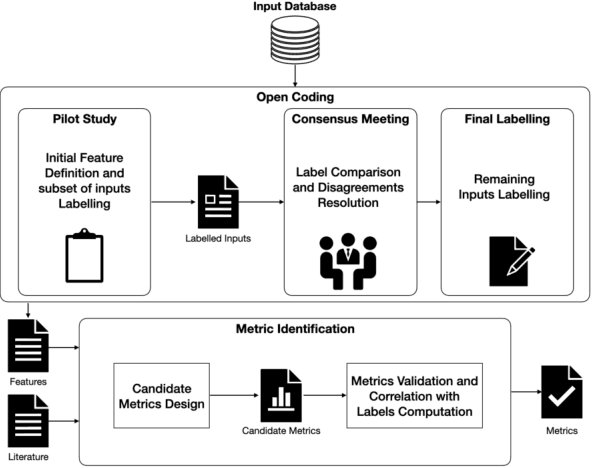
Deep Learning (DL) has been successfully applied to a wide range of application domains, including safety-critical ones. Several DL testing approaches have been recently proposed in the literature but none of them aims to assess how different interpretable features of the generated inputs affect the system's behaviour. In this paper, we resort to Illumination Search to find the highest-performing test cases (i.e., misbehaving and closest to misbehaving), spread across the cells of a map representing the feature space of the system. We introduce a methodology that guides the users of our approach in the tasks of identifying and quantifying the dimensions of the feature space for a given domain. We developed DeepHyperion, a search-based tool for DL systems that illuminates, i.e., explores at large, the feature space, by providing developers with an interpretable feature map where automatically generated inputs are placed along with information about the exposed behaviours.
Model-based Exploration of the Frontier of Behaviours for Deep Learning System Testing
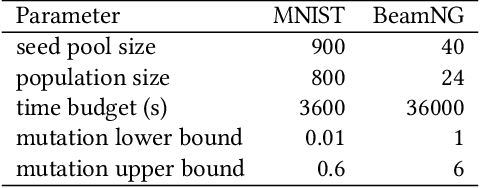
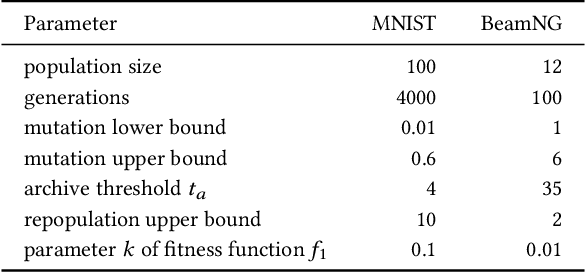
Jul 06, 2020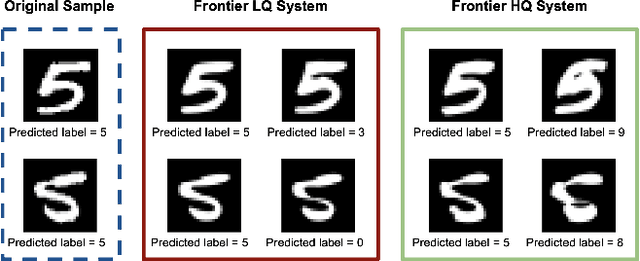
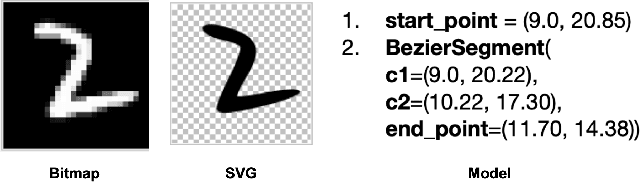
With the increasing adoption of Deep Learning (DL) for critical tasks, such as autonomous driving, the evaluation of the quality of systems that rely on DL has become crucial. Once trained, DL systems produce an output for any arbitrary numeric vector provided as input, regardless of whether it is within or outside the validity domain of the system under test. Hence, the quality of such systems is determined by the intersection between their validity domain and the regions where their outputs exhibit a misbehaviour. In this paper, we introduce the notion of frontier of behaviours, i.e., the inputs at which the DL system starts to misbehave. If the frontier of misbehaviours is outside the validity domain of the system, the quality check is passed. Otherwise, the inputs at the intersection represent quality deficiencies of the system. We developed DeepJanus, a search-based tool that generates frontier inputs for DL systems. The experimental results obtained for the lane keeping component of a self-driving car show that the frontier of a well trained system contains almost exclusively unrealistic roads that violate the best practices of civil engineering, while the frontier of a poorly trained one includes many valid inputs that point to serious deficiencies of the system.
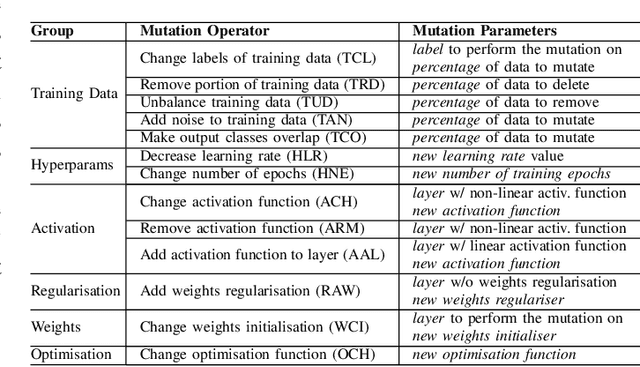
Taxonomy of Real Faults in Deep Learning Systems
Nov 07, 2019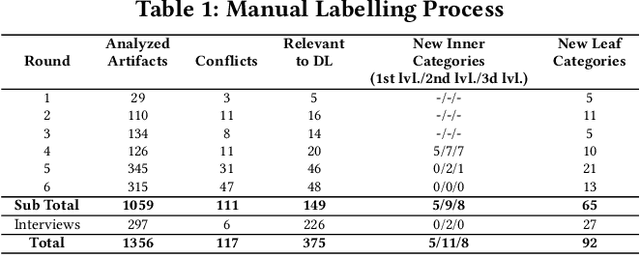
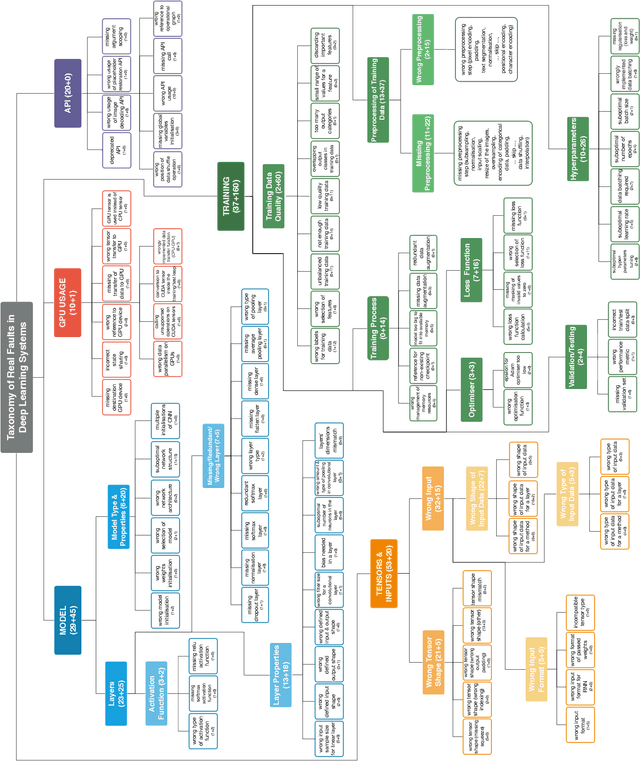
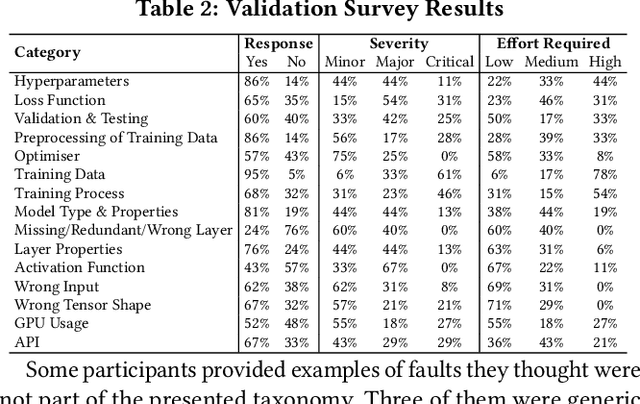

The growing application of deep neural networks in safety-critical domains makes the analysis of faults that occur in such systems of enormous importance. In this paper we introduce a large taxonomy of faults in deep learning (DL) systems. We have manually analysed 1059 artefacts gathered from GitHub commits and issues of projects that use the most popular DL frameworks (TensorFlow, Keras and PyTorch) and from related Stack Overflow posts. Structured interviews with 20 researchers and practitioners describing the problems they have encountered in their experience have enriched our taxonomy with a variety of additional faults that did not emerge from the other two sources. Our final taxonomy was validated with a survey involving an additional set of 21 developers, confirming that almost all fault categories (13/15) were experienced by at least 50% of the survey participants.