 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePartial Hypernetworks for Continual Learning
Jun 19, 2023



Hypernetworks mitigate forgetting in continual learning (CL) by generating task-dependent weights and penalizing weight changes at a meta-model level. Unfortunately, generating all weights is not only computationally expensive for larger architectures, but also, it is not well understood whether generating all model weights is necessary. Inspired by latent replay methods in CL, we propose partial weight generation for the final layers of a model using hypernetworks while freezing the initial layers. With this objective, we first answer the question of how many layers can be frozen without compromising the final performance. Through several experiments, we empirically show that the number of layers that can be frozen is proportional to the distributional similarity in the CL stream. Then, to demonstrate the effectiveness of hypernetworks, we show that noisy streams can significantly impact the performance of latent replay methods, leading to increased forgetting when features from noisy experiences are replayed with old samples. In contrast, partial hypernetworks are more robust to noise by maintaining accuracy on previous experiences. Finally, we conduct experiments on the split CIFAR-100 and TinyImagenet benchmarks and compare different versions of partial hypernetworks to latent replay methods. We conclude that partial weight generation using hypernetworks is a promising solution to the problem of forgetting in neural networks. It can provide an effective balance between computation and final test accuracy in CL streams.
Projected Latent Distillation for Data-Agnostic Consolidation in Distributed Continual Learning
Mar 28, 2023



Distributed learning on the edge often comprises self-centered devices (SCD) which learn local tasks independently and are unwilling to contribute to the performance of other SDCs. How do we achieve forward transfer at zero cost for the single SCDs? We formalize this problem as a Distributed Continual Learning scenario, where SCD adapt to local tasks and a CL model consolidates the knowledge from the resulting stream of models without looking at the SCD's private data. Unfortunately, current CL methods are not directly applicable to this scenario. We propose Data-Agnostic Consolidation (DAC), a novel double knowledge distillation method that consolidates the stream of SC models without using the original data. DAC performs distillation in the latent space via a novel Projected Latent Distillation loss. Experimental results show that DAC enables forward transfer between SCDs and reaches state-of-the-art accuracy on Split CIFAR100, CORe50 and Split TinyImageNet, both in reharsal-free and distributed CL scenarios. Somewhat surprisingly, even a single out-of-distribution image is sufficient as the only source of data during consolidation.
Avalanche: A PyTorch Library for Deep Continual Learning
Feb 02, 2023

Continual learning is the problem of learning from a nonstationary stream of data, a fundamental issue for sustainable and efficient training of deep neural networks over time. Unfortunately, deep learning libraries only provide primitives for offline training, assuming that model's architecture and data are fixed. Avalanche is an open source library maintained by the ContinualAI non-profit organization that extends PyTorch by providing first-class support for dynamic architectures, streams of datasets, and incremental training and evaluation methods. Avalanche provides a large set of predefined benchmarks and training algorithms and it is easy to extend and modular while supporting a wide range of continual learning scenarios. Documentation is available at \url{https://avalanche.continualai.org}.
Continual Learning for Predictive Maintenance: Overview and Challenges
Jan 29, 2023



Machine learning techniques have become one of the main propellers for solving many engineering problems effectively and efficiently. In Predictive Maintenance, for instance, Data-Driven methods have been used to improve predictions of when maintenance is needed on different machines and operative contexts. However, one of the limitations of these methods is that they are trained on a fixed distribution that does not change over time, which seldom happens in real-world applications. When internal or external factors alter the data distribution, the model performance may decrease or even fail unpredictably, resulting in severe consequences for machine maintenance. Continual Learning methods propose ways of adapting prediction models and incorporating new knowledge after deployment. The main objective of these methods is to avoid the plasticity-stability dilemma by updating the parametric model while not forgetting previously learned tasks. In this work, we present the current state of the art in applying Continual Learning to Predictive Maintenance, with an extensive review of both disciplines. We first introduce the two research themes independently, then discuss the current intersection of Continual Learning and Predictive Maintenance. Finally, we discuss the main research directions and conclusions.
Class-Incremental Learning with Repetition
Jan 26, 2023



Real-world data streams naturally include the repetition of previous concepts. From a Continual Learning (CL) perspective, repetition is a property of the environment and, unlike replay, cannot be controlled by the user. Nowadays, Class-Incremental scenarios represent the leading test-bed for assessing and comparing CL strategies. This family of scenarios is very easy to use, but it never allows revisiting previously seen classes, thus completely disregarding the role of repetition. We focus on the family of Class-Incremental with Repetition (CIR) scenarios, where repetition is embedded in the definition of the stream. We propose two stochastic scenario generators that produce a wide range of CIR scenarios starting from a single dataset and a few control parameters. We conduct the first comprehensive evaluation of repetition in CL by studying the behavior of existing CL strategies under different CIR scenarios. We then present a novel replay strategy that exploits repetition and counteracts the natural imbalance present in the stream. On both CIFAR100 and TinyImageNet, our strategy outperforms other replay approaches, which are not designed for environments with repetition.
Architect, Regularize and Replay (ARR): a Flexible Hybrid Approach for Continual Learning
Jan 06, 2023



In recent years we have witnessed a renewed interest in machine learning methodologies, especially for deep representation learning, that could overcome basic i.i.d. assumptions and tackle non-stationary environments subject to various distributional shifts or sample selection biases. Within this context, several computational approaches based on architectural priors, regularizers and replay policies have been proposed with different degrees of success depending on the specific scenario in which they were developed and assessed. However, designing comprehensive hybrid solutions that can flexibly and generally be applied with tunable efficiency-effectiveness trade-offs still seems a distant goal. In this paper, we propose "Architect, Regularize and Replay" (ARR), an hybrid generalization of the renowned AR1 algorithm and its variants, that can achieve state-of-the-art results in classic scenarios (e.g. class-incremental learning) but also generalize to arbitrary data streams generated from real-world datasets such as CIFAR-100, CORe50 and ImageNet-1000.
3rd Continual Learning Workshop Challenge on Egocentric Category and Instance Level Object Understanding
Dec 13, 2022



Continual Learning, also known as Lifelong or Incremental Learning, has recently gained renewed interest among the Artificial Intelligence research community. Recent research efforts have quickly led to the design of novel algorithms able to reduce the impact of the catastrophic forgetting phenomenon in deep neural networks. Due to this surge of interest in the field, many competitions have been held in recent years, as they are an excellent opportunity to stimulate research in promising directions. This paper summarizes the ideas, design choices, rules, and results of the challenge held at the 3rd Continual Learning in Computer Vision (CLVision) Workshop at CVPR 2022. The focus of this competition is the complex continual object detection task, which is still underexplored in literature compared to classification tasks. The challenge is based on the challenge version of the novel EgoObjects dataset, a large-scale egocentric object dataset explicitly designed to benchmark continual learning algorithms for egocentric category-/instance-level object understanding, which covers more than 1k unique main objects and 250+ categories in around 100k video frames.
It's all About Consistency: A Study on Memory Composition for Replay-Based Methods in Continual Learning
Jul 04, 2022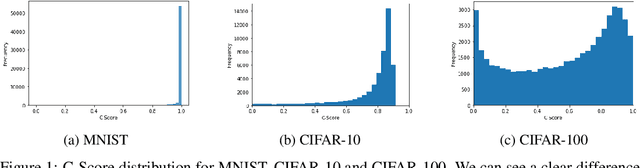
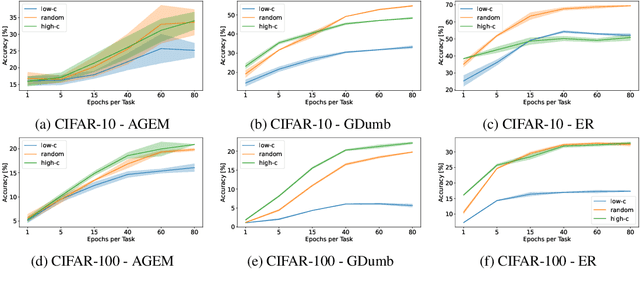
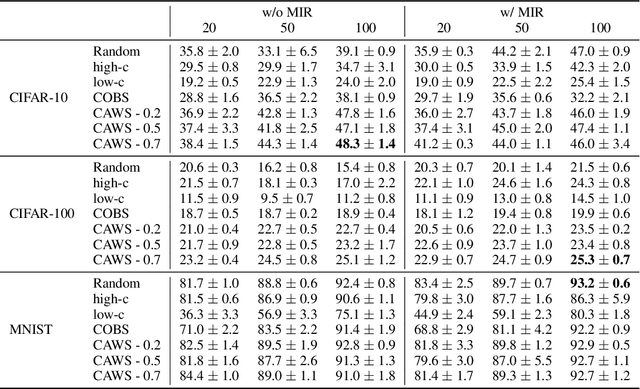
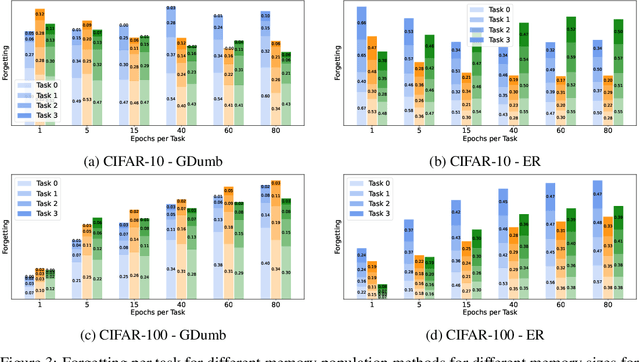
Continual Learning methods strive to mitigate Catastrophic Forgetting (CF), where knowledge from previously learned tasks is lost when learning a new one. Among those algorithms, some maintain a subset of samples from previous tasks when training. These samples are referred to as a memory. These methods have shown outstanding performance while being conceptually simple and easy to implement. Yet, despite their popularity, little has been done to understand which elements to be included into the memory. Currently, this memory is often filled via random sampling with no guiding principles that may aid in retaining previous knowledge. In this work, we propose a criterion based on the learning consistency of a sample called Consistency AWare Sampling (CAWS). This criterion prioritizes samples that are easier to learn by deep networks. We perform studies on three different memory-based methods: AGEM, GDumb, and Experience Replay, on MNIST, CIFAR-10 and CIFAR-100 datasets. We show that using the most consistent elements yields performance gains when constrained by a compute budget; when under no such constrain, random sampling is a strong baseline. However, using CAWS on Experience Replay yields improved performance over the random baseline. Finally, we show that CAWS achieves similar results to a popular memory selection method while requiring significantly less computational resources.
Continual Learning for Human State Monitoring
Jun 29, 2022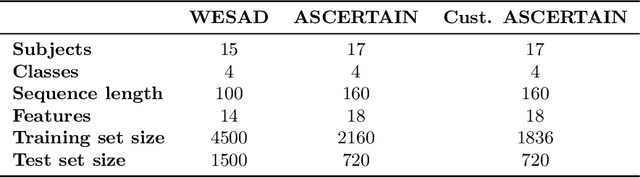
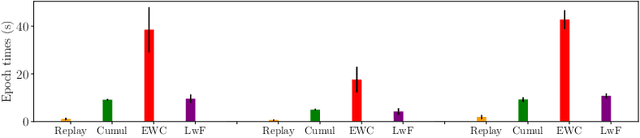
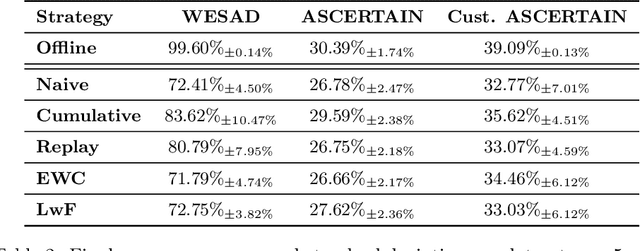
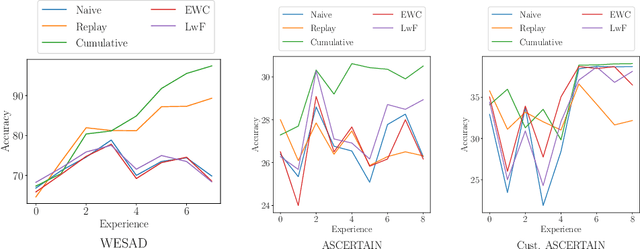
Continual Learning (CL) on time series data represents a promising but under-studied avenue for real-world applications. We propose two new CL benchmarks for Human State Monitoring. We carefully designed the benchmarks to mirror real-world environments in which new subjects are continuously added. We conducted an empirical evaluation to assess the ability of popular CL strategies to mitigate forgetting in our benchmarks. Our results show that, possibly due to the domain-incremental properties of our benchmarks, forgetting can be easily tackled even with a simple finetuning and that existing strategies struggle in accumulating knowledge over a fixed, held-out, test subject.
Continual-Learning-as-a-Service : On-Demand Efficient Adaptation of Predictive Models
Jun 14, 2022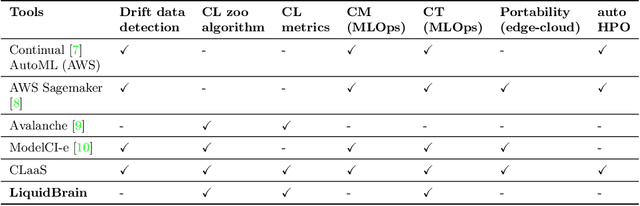
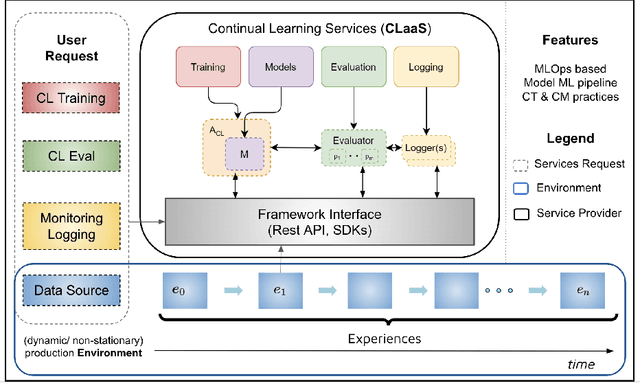
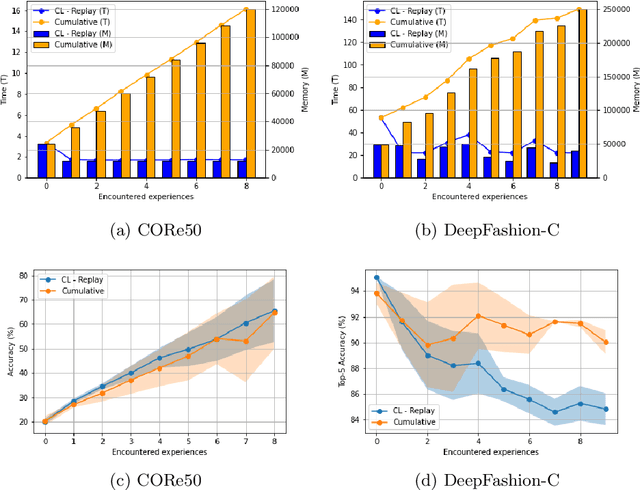
Predictive machine learning models nowadays are often updated in a stateless and expensive way. The two main future trends for companies that want to build machine learning-based applications and systems are real-time inference and continual updating. Unfortunately, both trends require a mature infrastructure that is hard and costly to realize on-premise. This paper defines a novel software service and model delivery infrastructure termed Continual Learning-as-a-Service (CLaaS) to address these issues. Specifically, it embraces continual machine learning and continuous integration techniques. It provides support for model updating and validation tools for data scientists without an on-premise solution and in an efficient, stateful and easy-to-use manner. Finally, this CL model service is easy to encapsulate in any machine learning infrastructure or cloud system. This paper presents the design and implementation of a CLaaS instantiation, called LiquidBrain, evaluated in two real-world scenarios. The former is a robotic object recognition setting using the CORe50 dataset while the latter is a named category and attribute prediction using the DeepFashion-C dataset in the fashion domain. Our preliminary results suggest the usability and efficiency of the Continual Learning model services and the effectiveness of the solution in addressing real-world use-cases regardless of where the computation happens in the continuum Edge-Cloud.