 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIs Medical Chest X-ray Data Anonymous?
Mar 15, 2021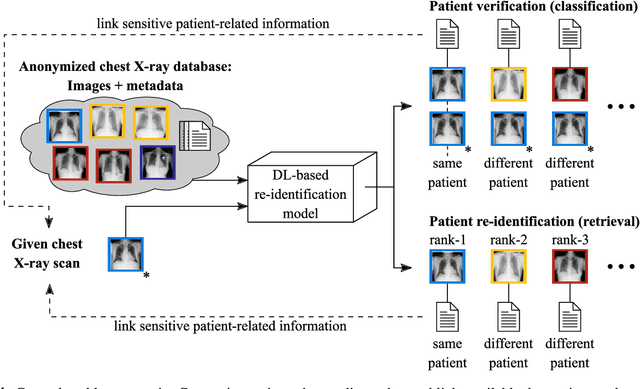
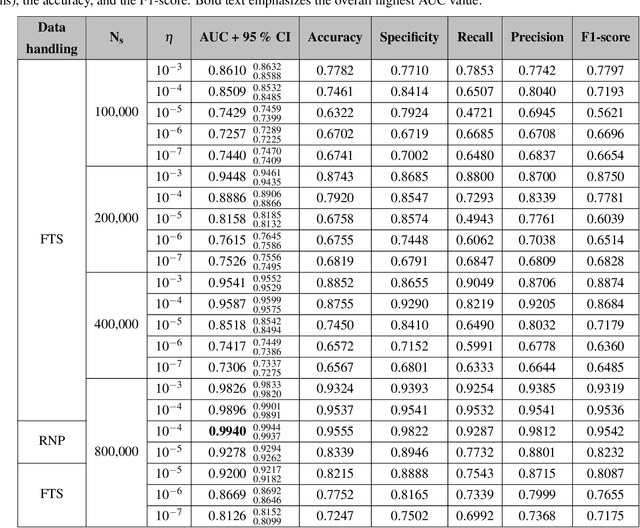
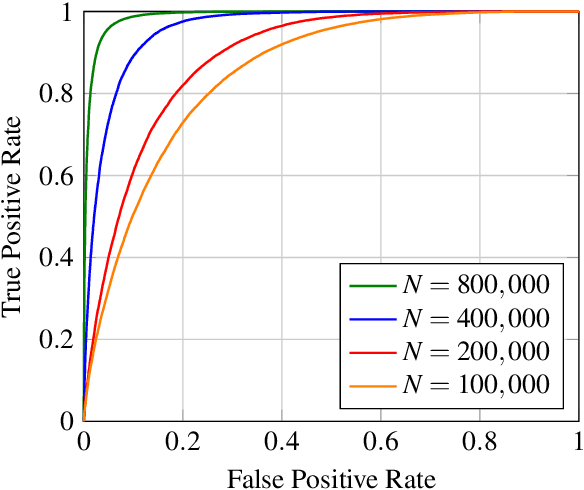
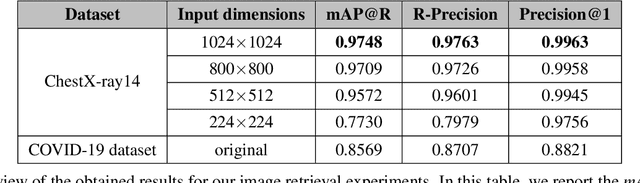
With the rise and ever-increasing potential of deep learning techniques in recent years, publicly available medical data sets became a key factor to enable reproducible development of diagnostic algorithms in the medical domain. Medical data contains sensitive patient-related information and is therefore usually anonymized by removing patient identifiers, e.g., patient names before publication. To the best of our knowledge, we are the first to show that a well-trained deep learning system is able to recover the patient identity from chest X-ray data. We demonstrate this using the publicly available large-scale ChestX-ray14 dataset, a collection of 112,120 frontal-view chest X-ray images from 30,805 unique patients. Our verification system is able to identify whether two frontal chest X-ray images are from the same person with an AUC of 0.9940 and a classification accuracy of 95.55%. We further highlight that the proposed system is able to reveal the same person even ten and more years after the initial scan. When pursuing a retrieval approach, we observe an mAP@R of 0.9748 and a precision@1 of 0.9963. Based on this high identification rate, a potential attacker may leak patient-related information and additionally cross-reference images to obtain more information. Thus, there is a great risk of sensitive content falling into unauthorized hands or being disseminated against the will of the concerned patients. Especially during the COVID-19 pandemic, numerous chest X-ray datasets have been published to advance research. Therefore, such data may be vulnerable to potential attacks by deep learning-based re-identification algorithms.
On Mathews Correlation Coefficient and Improved Distance Map Loss for Automatic Glacier Calving Front Segmentation in SAR Imagery
Mar 09, 2021
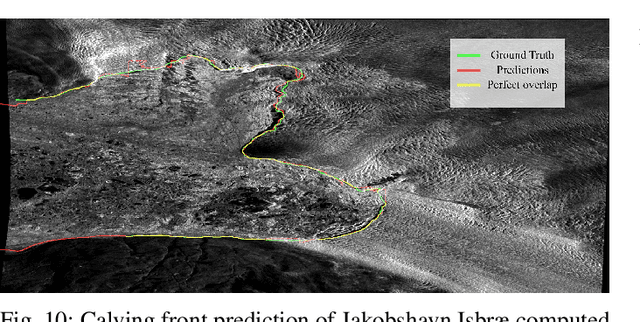

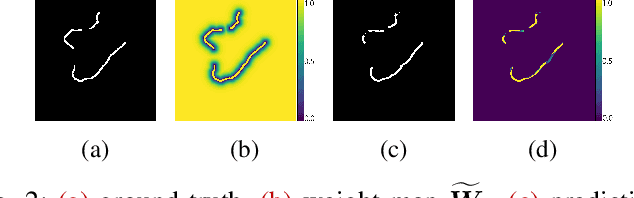
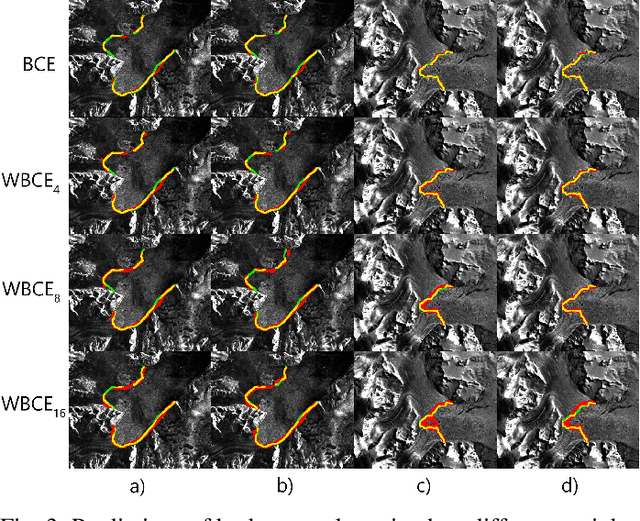
The vast majority of the outlet glaciers and ice streams of the polar ice sheets end in the ocean. Ice mass loss via calving of the glaciers into the ocean has increased over the last few decades. Information on the temporal variability of the calving front position provides fundamental information on the state of the glacier and ice stream, which can be exploited as calibration and validation data to enhance ice dynamics modeling. To identify the calving front position automatically, deep neural network-based semantic segmentation pipelines can be used to delineate the acquired SAR imagery. However, the extreme class imbalance is highly challenging for the accurate calving front segmentation in these images. Therefore, we propose the use of the Mathews correlation coefficient (MCC) as an early stopping criterion because of its symmetrical properties and its invariance towards class imbalance. Moreover, we propose an improvement to the distance map-based binary cross-entropy (BCE) loss function. The distance map adds context to the loss function about the important regions for segmentation and helps accounting for the imbalanced data. Using Mathews correlation coefficient as early stopping demonstrates an average 15% dice coefficient improvement compared to the commonly used BCE. The modified distance map loss further improves the segmentation performance by another 2%. These results are encouraging as they support the effectiveness of the proposed methods for segmentation problems suffering from extreme class imbalances.
Pixel-wise Distance Regression for Glacier Calving Front Detection and Segmentation
Mar 09, 2021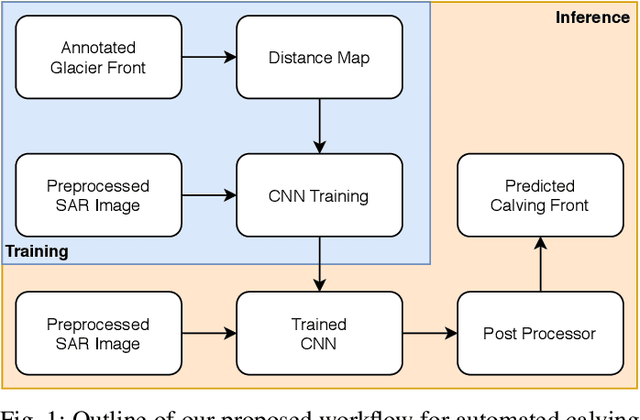


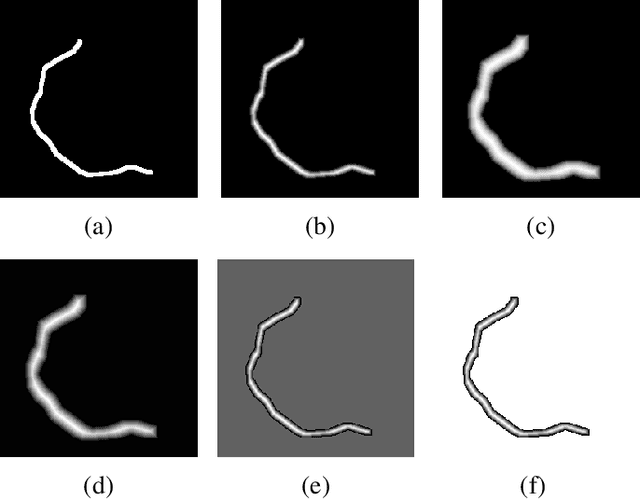
Glacier calving front position (CFP) is an important glaciological variable. Traditionally, delineating the CFPs has been carried out manually, which was subjective, tedious and expensive. Automating this process is crucial for continuously monitoring the evolution and status of glaciers. Recently, deep learning approaches have been investigated for this application. However, the current methods get challenged by a severe class-imbalance problem. In this work, we propose to mitigate the class-imbalance between the calving front class and the non-calving front class by reformulating the segmentation problem into a pixel-wise regression task. A Convolutional Neural Network gets optimized to predict the distance values to the glacier front for each pixel in the image. The resulting distance map localizes the CFP and is further post-processed to extract the calving front line. We propose three post-processing methods, one method based on statistical thresholding, a second method based on conditional random fields (CRF), and finally the use of a second U-Net. The experimental results confirm that our approach significantly outperforms the state-of-the-art methods and produces accurate delineation. The Second U-Net obtains the best performance results, resulting in an average improvement of about 21% dice coefficient enhancement.
Synthetic Glacier SAR Image Generation from Arbitrary Masks Using Pix2Pix Algorithm
Jan 14, 2021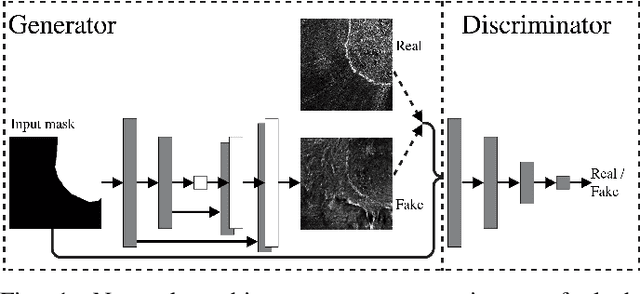
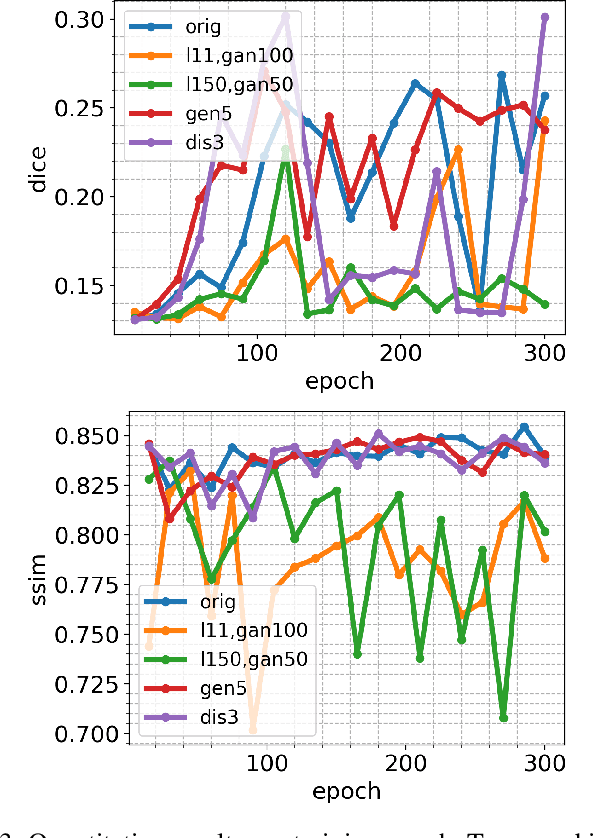

Supervised machine learning requires a large amount of labeled data to achieve proper test results. However, generating accurately labeled segmentation maps on remote sensing imagery, including images from synthetic aperture radar (SAR), is tedious and highly subjective. In this work, we propose to alleviate the issue of limited training data by generating synthetic SAR images with the pix2pix algorithm. This algorithm uses conditional Generative Adversarial Networks (cGANs) to generate an artificial image while preserving the structure of the input. In our case, the input is a segmentation mask, from which a corresponding synthetic SAR image is generated. We present different models, perform a comparative study and demonstrate that this approach synthesizes convincing glaciers in SAR images with promising qualitative and quantitative results.
Bayesian U-Net for Segmenting Glaciers in SAR Imagery
Jan 08, 2021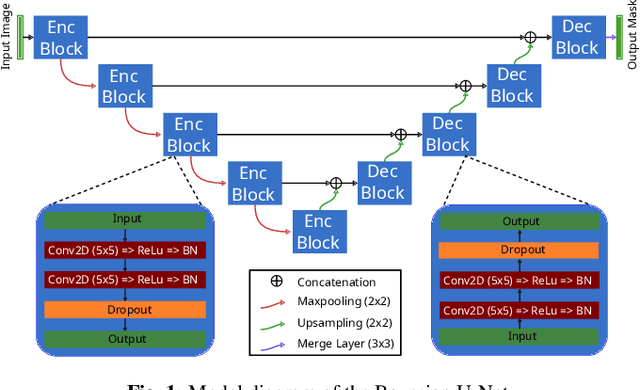
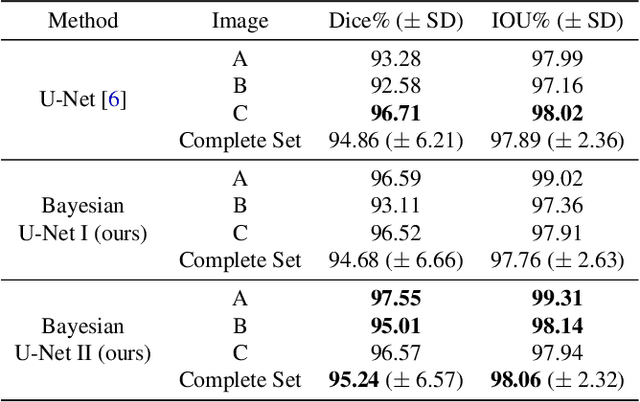

Fluctuations of the glacier calving front have an important influence over the ice flow of whole glacier systems. It is therefore important to precisely monitor the position of the calving front. However, the manual delineation of SAR images is a difficult, laborious and subjective task. Convolutional neural networks have previously shown promising results in automating the glacier segmentation in SAR images, making them desirable for further exploration of their possibilities. In this work, we propose to compute uncertainty and use it in an Uncertainty Optimization regime as a novel two-stage process. By using dropout as a random sampling layer in a U-Net architecture, we create a probabilistic Bayesian Neural Network. With several forward passes, we create a sampling distribution, which can estimate the model uncertainty for each pixel in the segmentation mask. The additional uncertainty map information can serve as a guideline for the experts in the manual annotation of the data. Furthermore, feeding the uncertainty map to the network leads to 95.24% Dice similarity, which is an overall improvement in the segmentation performance compared to the state-of-the-art deterministic U-Net-based glacier segmentation pipelines.
Glacier Calving Front Segmentation Using Attention U-Net
Jan 08, 2021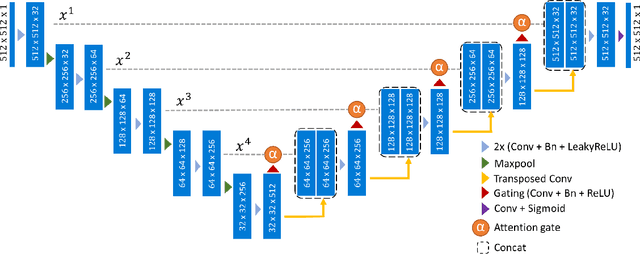
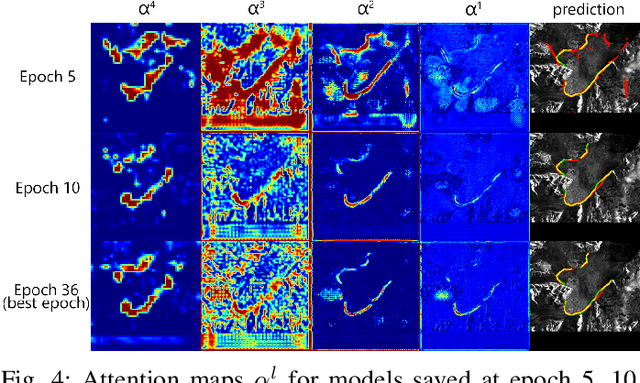
An essential climate variable to determine the tidewater glacier status is the location of the calving front position and the separation of seasonal variability from long-term trends. Previous studies have proposed deep learning-based methods to semi-automatically delineate the calving fronts of tidewater glaciers. They used U-Net to segment the ice and non-ice regions and extracted the calving fronts in a post-processing step. In this work, we show a method to segment the glacier calving fronts from SAR images in an end-to-end fashion using Attention U-Net. The main objective is to investigate the attention mechanism in this application. Adding attention modules to the state-of-the-art U-Net network lets us analyze the learning process by extracting its attention maps. We use these maps as a tool to search for proper hyperparameters and loss functions in order to generate higher qualitative results. Our proposed attention U-Net performs comparably to the standard U-Net while providing additional insight into those regions on which the network learned to focus more. In the best case, the attention U-Net achieves a 1.5% better Dice score compared to the canonical U-Net with a glacier front line prediction certainty of up to 237.12 meters.
Enhancing Human Pose Estimation in Ancient Vase Paintings via Perceptually-grounded Style Transfer Learning
Dec 10, 2020
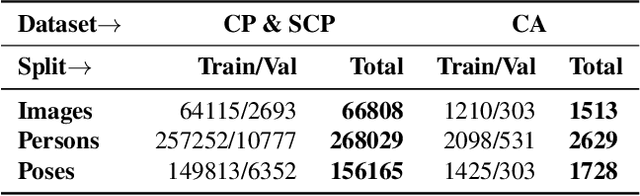

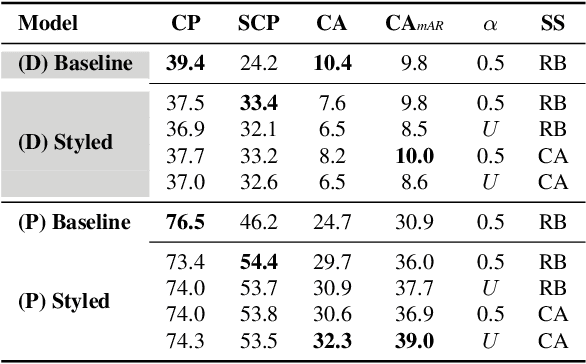
Human pose estimation (HPE) is a central part of understanding the visual narration and body movements of characters depicted in artwork collections, such as Greek vase paintings. Unfortunately, existing HPE methods do not generalise well across domains resulting in poorly recognized poses. Therefore, we propose a two step approach: (1) adapting a dataset of natural images of known person and pose annotations to the style of Greek vase paintings by means of image style-transfer. We introduce a perceptually-grounded style transfer training to enforce perceptual consistency. Then, we fine-tune the base model with this newly created dataset. We show that using style-transfer learning significantly improves the SOTA performance on unlabelled data by more than 6% mean average precision (mAP) as well as mean average recall (mAR). (2) To improve the already strong results further, we created a small dataset (ClassArch) consisting of ancient Greek vase paintings from the 6-5th century BCE with person and pose annotations. We show that fine-tuning on this data with a style-transferred model improves the performance further. In a thorough ablation study, we give a targeted analysis of the influence of style intensities, revealing that the model learns generic domain styles. Additionally, we provide a pose-based image retrieval to demonstrate the effectiveness of our method.
Joint Super-Resolution and Rectification for Solar Cell Inspection
Nov 10, 2020
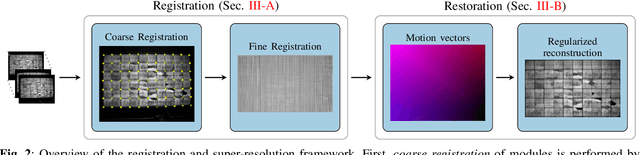

Visual inspection of solar modules is an important monitoring facility in photovoltaic power plants. Since a single measurement of fast CMOS sensors is limited in spatial resolution and often not sufficient to reliably detect small defects, we apply multi-frame super-resolution (MFSR) to a sequence of low resolution measurements. In addition, the rectification and removal of lens distortion simplifies subsequent analysis. Therefore, we propose to fuse this pre-processing with standard MFSR algorithms. This is advantageous, because we omit a separate processing step, the motion estimation becomes more stable and the spacing of high-resolution (HR) pixels on the rectified module image becomes uniform w.r.t. the module plane, regardless of perspective distortion. We present a comprehensive user study showing that MFSR is beneficial for defect recognition by human experts and that the proposed method performs better than the state of the art. Furthermore, we apply automated crack segmentation and show that the proposed method performs 3x better than bicubic upsampling and 2x better than the state of the art for automated inspection.
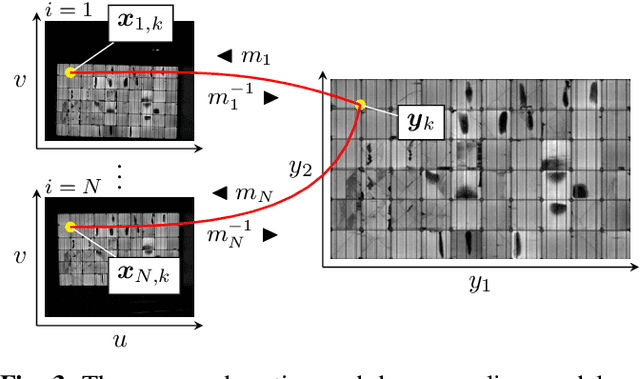
ICFHR 2020 Competition on Image Retrieval for Historical Handwritten Fragments
Oct 20, 2020


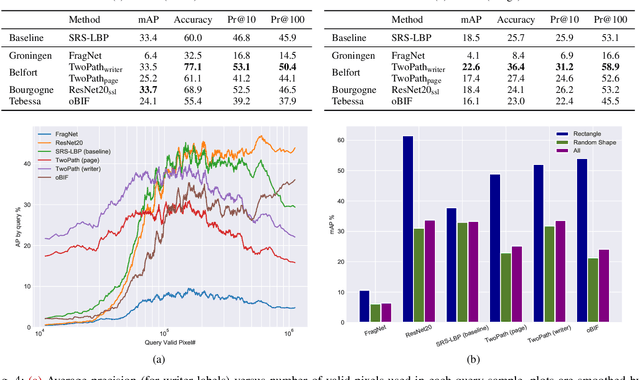
This competition succeeds upon a line of competitions for writer and style analysis of historical document images. In particular, we investigate the performance of large-scale retrieval of historical document fragments in terms of style and writer identification. The analysis of historic fragments is a difficult challenge commonly solved by trained humanists. In comparison to previous competitions, we make the results more meaningful by addressing the issue of sample granularity and moving from writer to page fragment retrieval. The two approaches, style and author identification, provide information on what kind of information each method makes better use of and indirectly contribute to the interpretability of the participating method. Therefore, we created a large dataset consisting of more than 120 000 fragments. Although the most teams submitted methods based on convolutional neural networks, the winning entry achieves an mAP below 40%.
Deep Learning-based Pipeline for Module Power Prediction from EL Measurements
Sep 30, 2020


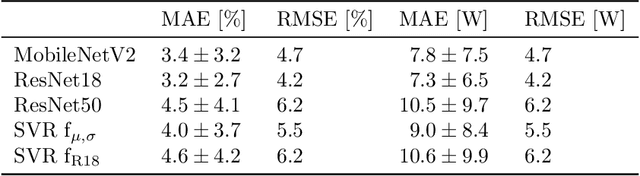
Automated inspection plays an important role in monitoring large-scale photovoltaic power plants. Commonly, electroluminescense measurements are used to identify various types of defects on solar modules but have not been used to determine the power of a module. However, knowledge of the power at maximum power point is important as well, since drops in the power of a single module can affect the performance of an entire string. By now, this is commonly determined by measurements that require to discontact or even dismount the module, rendering a regular inspection of individual modules infeasible. In this work, we bridge the gap between electroluminescense measurements and the power determination of a module. We compile a large dataset of 719 electroluminescense measurementsof modules at various stages of degradation, especially cell cracks and fractures, and the corresponding power at maximum power point. Here,we focus on inactive regions and cracks as the predominant type of defect. We set up a baseline regression model to predict the power from electroluminescense measurements with a mean absolute error of 9.0+/-3.7W (4.0+/-8.4%). Then, we show that deep-learning can be used to train a model that performs significantly better (7.3+/-2.7W or 3.2+/-6.5%). With this work, we aim to open a new research topic. Therefore, we publicly release the dataset, the code and trained models to empower other researchers to compare against our results. Finally, we present a thorough evaluation of certain boundary conditions like the dataset size and an automated preprocessing pipeline for on-site measurements showing multiple modules at once.