 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMore Parameters? No Thanks!
Jul 20, 2021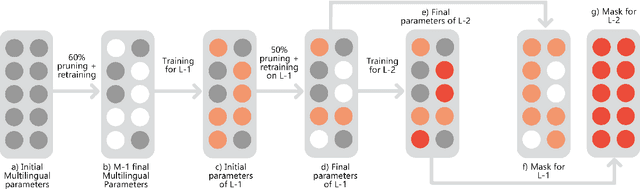
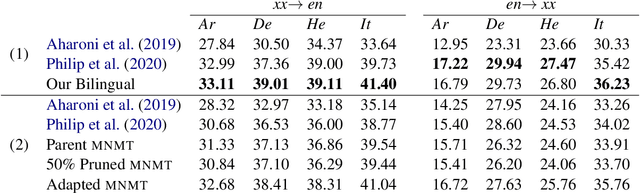
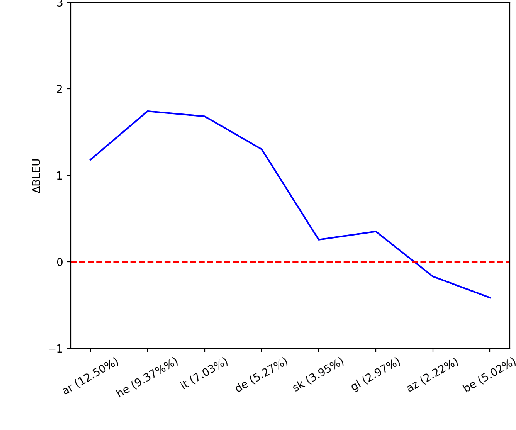

This work studies the long-standing problems of model capacity and negative interference in multilingual neural machine translation MNMT. We use network pruning techniques and observe that pruning 50-70% of the parameters from a trained MNMT model results only in a 0.29-1.98 drop in the BLEU score. Suggesting that there exist large redundancies even in MNMT models. These observations motivate us to use the redundant parameters and counter the interference problem efficiently. We propose a novel adaptation strategy, where we iteratively prune and retrain the redundant parameters of an MNMT to improve bilingual representations while retaining the multilinguality. Negative interference severely affects high resource languages, and our method alleviates it without any additional adapter modules. Hence, we call it parameter-free adaptation strategy, paving way for the efficient adaptation of MNMT. We demonstrate the effectiveness of our method on a 9 language MNMT trained on TED talks, and report an average improvement of +1.36 BLEU on high resource pairs. Code will be released here.
Prb-GAN: A Probabilistic Framework for GAN Modelling
Jul 12, 2021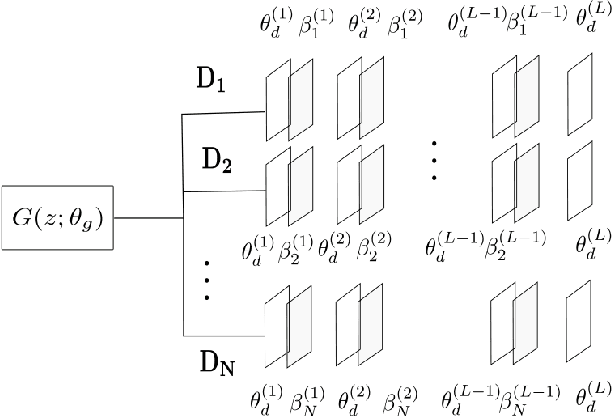
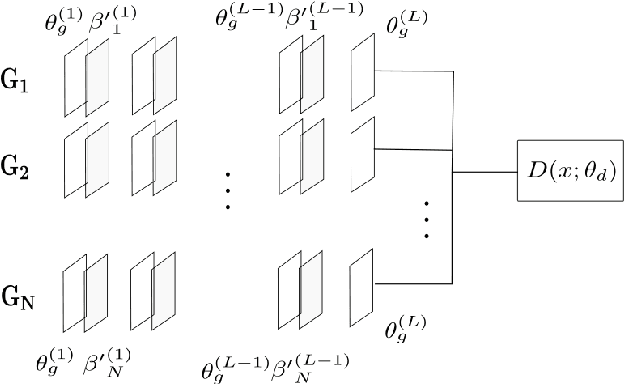
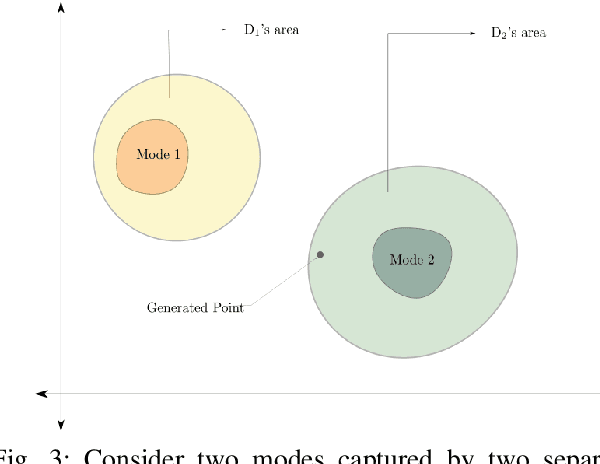
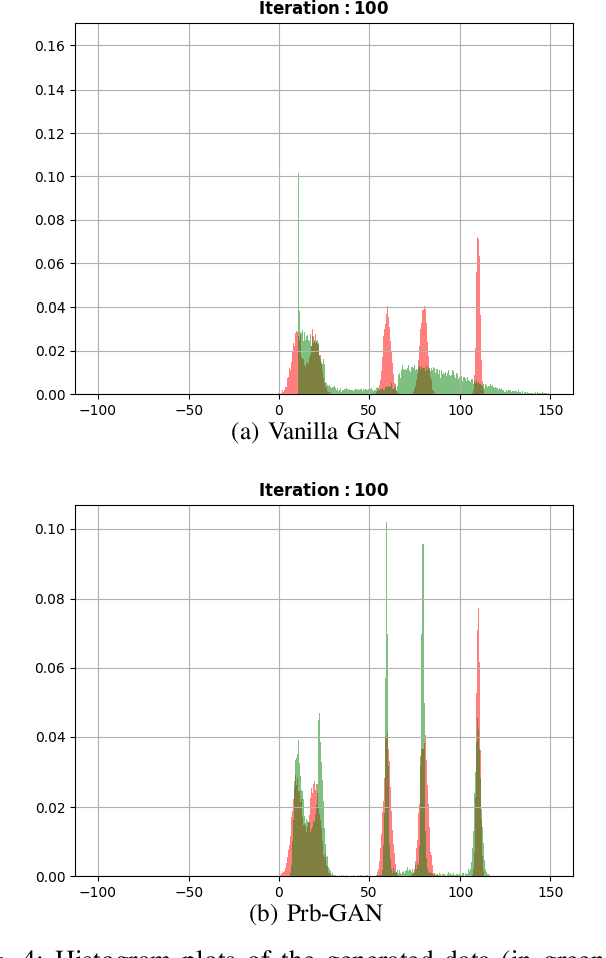
Generative adversarial networks (GANs) are very popular to generate realistic images, but they often suffer from the training instability issues and the phenomenon of mode loss. In order to attain greater diversity in GAN synthesized data, it is critical to solving the problem of mode loss. Our work explores probabilistic approaches to GAN modelling that could allow us to tackle these issues. We present Prb-GANs, a new variation that uses dropout to create a distribution over the network parameters with the posterior learnt using variational inference. We describe theoretically and validate experimentally using simple and complex datasets the benefits of such an approach. We look into further improvements using the concept of uncertainty measures. Through a set of further modifications to the loss functions for each network of the GAN, we are able to get results that show the improvement of GAN performance. Our methods are extremely simple and require very little modification to existing GAN architecture.
Exploring Dropout Discriminator for Domain Adaptation
Jul 09, 2021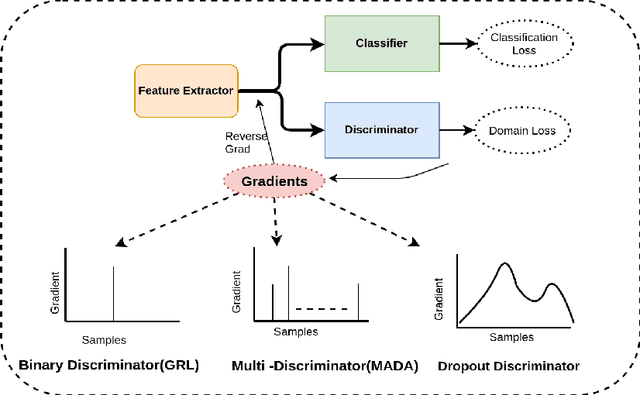
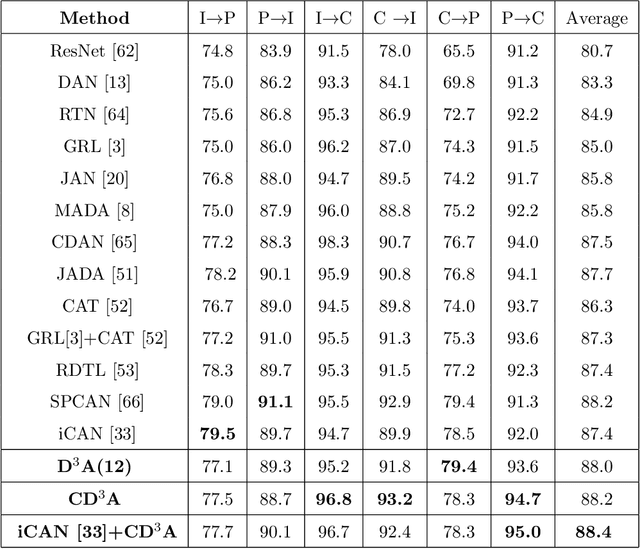
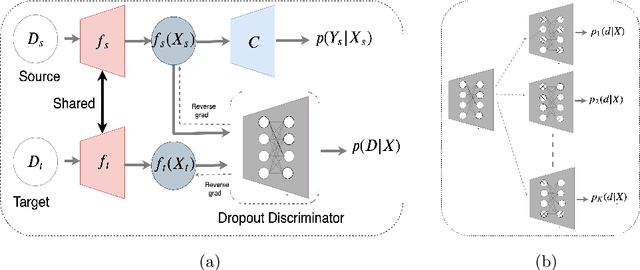
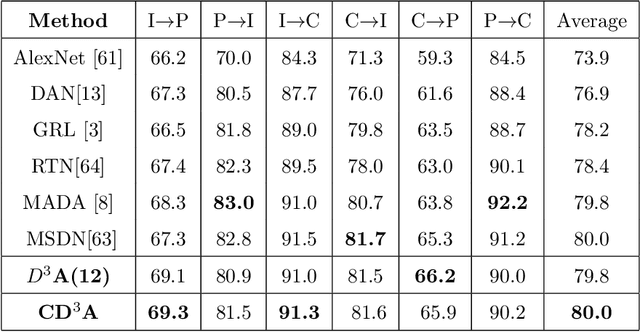
Adaptation of a classifier to new domains is one of the challenging problems in machine learning. This has been addressed using many deep and non-deep learning based methods. Among the methodologies used, that of adversarial learning is widely applied to solve many deep learning problems along with domain adaptation. These methods are based on a discriminator that ensures source and target distributions are close. However, here we suggest that rather than using a point estimate obtaining by a single discriminator, it would be useful if a distribution based on ensembles of discriminators could be used to bridge this gap. This could be achieved using multiple classifiers or using traditional ensemble methods. In contrast, we suggest that a Monte Carlo dropout based ensemble discriminator could suffice to obtain the distribution based discriminator. Specifically, we propose a curriculum based dropout discriminator that gradually increases the variance of the sample based distribution and the corresponding reverse gradients are used to align the source and target feature representations. An ensemble of discriminators helps the model to learn the data distribution efficiently. It also provides a better gradient estimates to train the feature extractor. The detailed results and thorough ablation analysis show that our model outperforms state-of-the-art results.
Fair Visual Recognition in Limited Data Regime using Self-Supervision and Self-Distillation
Jun 30, 2021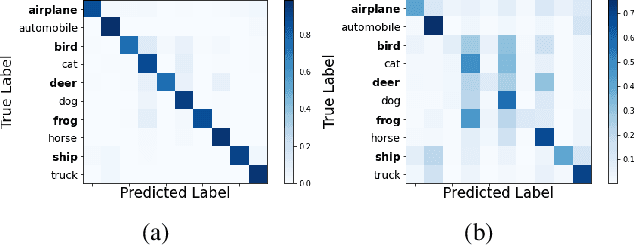
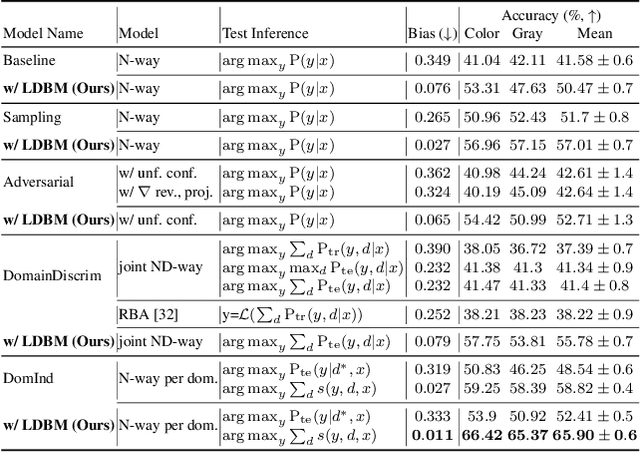
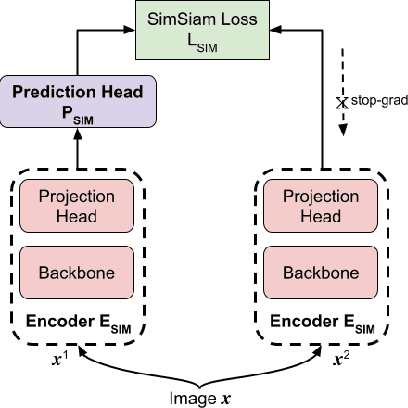
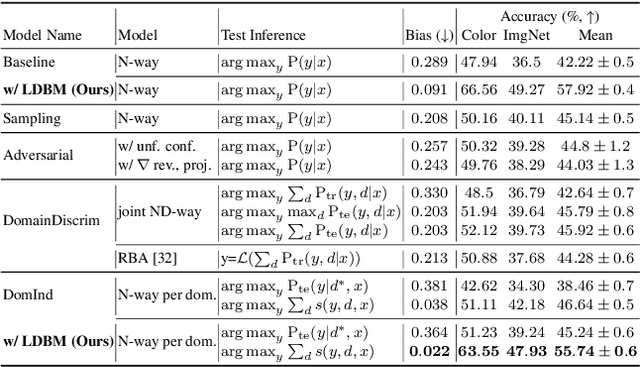
Deep learning models generally learn the biases present in the training data. Researchers have proposed several approaches to mitigate such biases and make the model fair. Bias mitigation techniques assume that a sufficiently large number of training examples are present. However, we observe that if the training data is limited, then the effectiveness of bias mitigation methods is severely degraded. In this paper, we propose a novel approach to address this problem. Specifically, we adapt self-supervision and self-distillation to reduce the impact of biases on the model in this setting. Self-supervision and self-distillation are not used for bias mitigation. However, through this work, we demonstrate for the first time that these techniques are very effective in bias mitigation. We empirically show that our approach can significantly reduce the biases learned by the model. Further, we experimentally demonstrate that our approach is complementary to other bias mitigation strategies. Our approach significantly improves their performance and further reduces the model biases in the limited data regime. Specifically, on the L-CIFAR-10S skewed dataset, our approach significantly reduces the bias score of the baseline model by 78.22% and outperforms it in terms of accuracy by a significant absolute margin of 8.89%. It also significantly reduces the bias score for the state-of-the-art domain independent bias mitigation method by 59.26% and improves its performance by a significant absolute margin of 7.08%.
Rectification-based Knowledge Retention for Continual Learning
Mar 30, 2021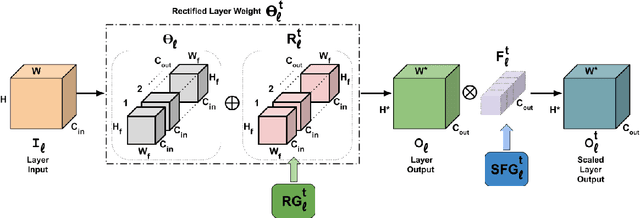
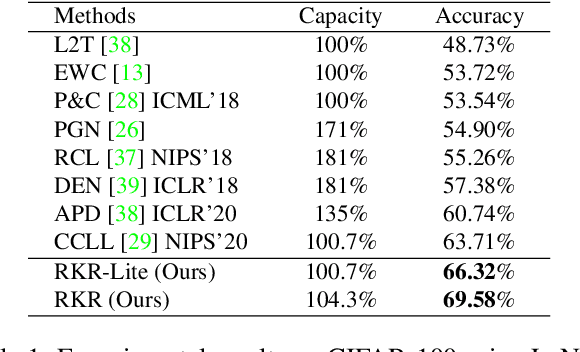
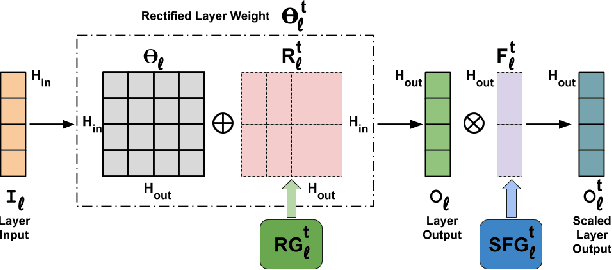

Deep learning models suffer from catastrophic forgetting when trained in an incremental learning setting. In this work, we propose a novel approach to address the task incremental learning problem, which involves training a model on new tasks that arrive in an incremental manner. The task incremental learning problem becomes even more challenging when the test set contains classes that are not part of the train set, i.e., a task incremental generalized zero-shot learning problem. Our approach can be used in both the zero-shot and non zero-shot task incremental learning settings. Our proposed method uses weight rectifications and affine transformations in order to adapt the model to different tasks that arrive sequentially. Specifically, we adapt the network weights to work for new tasks by "rectifying" the weights learned from the previous task. We learn these weight rectifications using very few parameters. We additionally learn affine transformations on the outputs generated by the network in order to better adapt them for the new task. We perform experiments on several datasets in both zero-shot and non zero-shot task incremental learning settings and empirically show that our approach achieves state-of-the-art results. Specifically, our approach outperforms the state-of-the-art non zero-shot task incremental learning method by over 5% on the CIFAR-100 dataset. Our approach also significantly outperforms the state-of-the-art task incremental generalized zero-shot learning method by absolute margins of 6.91% and 6.33% for the AWA1 and CUB datasets, respectively. We validate our approach using various ablation studies.
Do Not Forget to Attend to Uncertainty while Mitigating Catastrophic Forgetting
Feb 03, 2021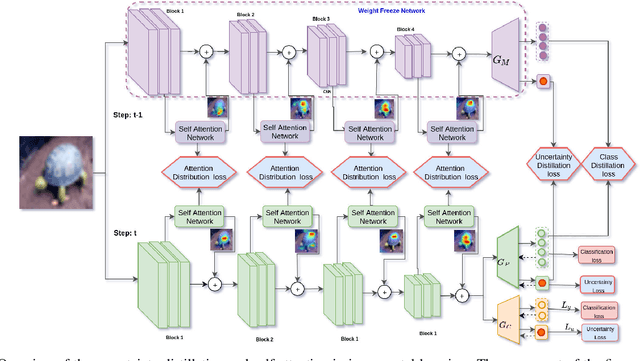
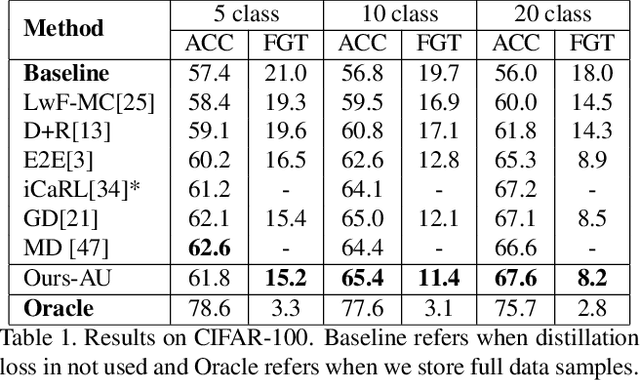
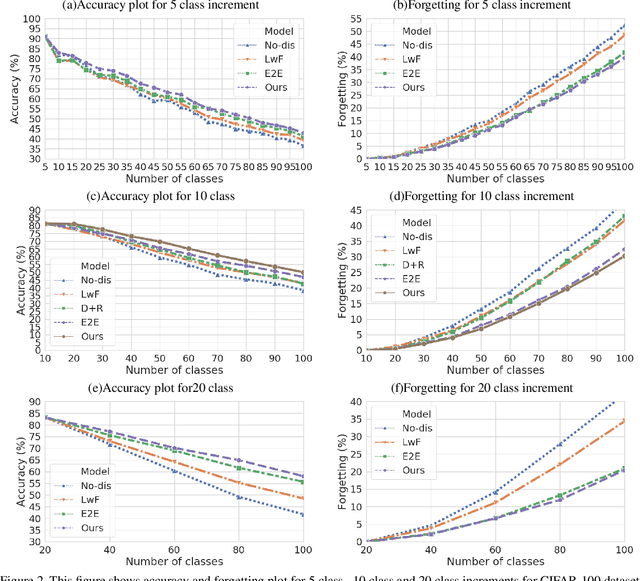
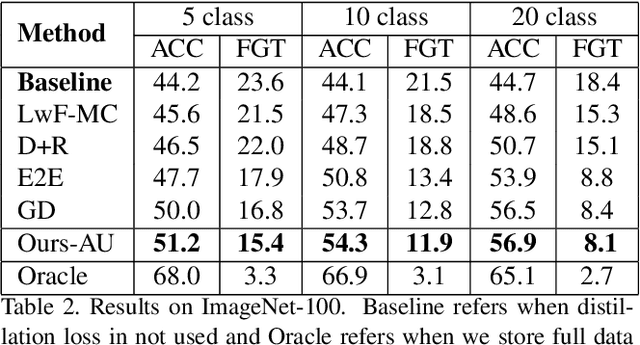
One of the major limitations of deep learning models is that they face catastrophic forgetting in an incremental learning scenario. There have been several approaches proposed to tackle the problem of incremental learning. Most of these methods are based on knowledge distillation and do not adequately utilize the information provided by older task models, such as uncertainty estimation in predictions. The predictive uncertainty provides the distributional information can be applied to mitigate catastrophic forgetting in a deep learning framework. In the proposed work, we consider a Bayesian formulation to obtain the data and model uncertainties. We also incorporate self-attention framework to address the incremental learning problem. We define distillation losses in terms of aleatoric uncertainty and self-attention. In the proposed work, we investigate different ablation analyses on these losses. Furthermore, we are able to obtain better results in terms of accuracy on standard benchmarks.
* Accepted WACV 2021
Exploring Pair-Wise NMT for Indian Languages
Dec 10, 2020
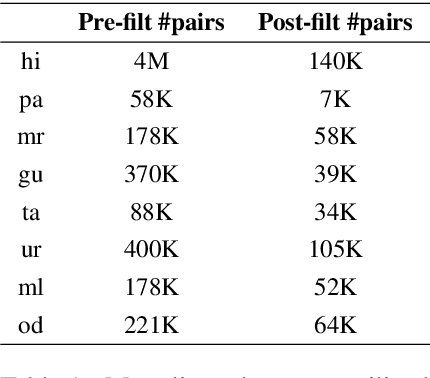
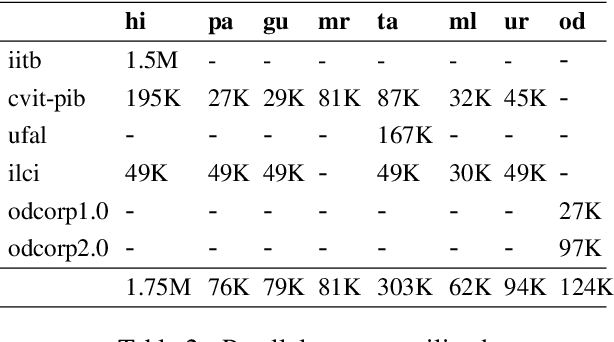
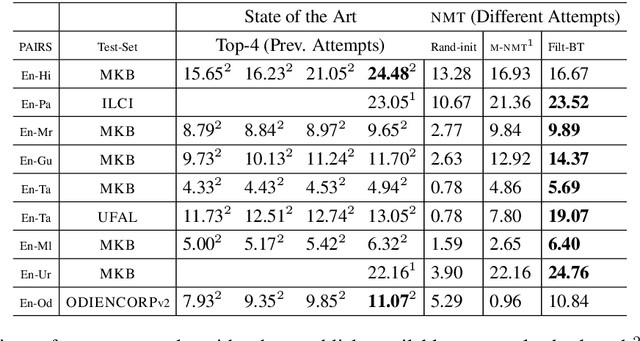
In this paper, we address the task of improving pair-wise machine translation for specific low resource Indian languages. Multilingual NMT models have demonstrated a reasonable amount of effectiveness on resource-poor languages. In this work, we show that the performance of these models can be significantly improved upon by using back-translation through a filtered back-translation process and subsequent fine-tuning on the limited pair-wise language corpora. The analysis in this paper suggests that this method can significantly improve a multilingual model's performance over its baseline, yielding state-of-the-art results for various Indian languages.
RNNP: A Robust Few-Shot Learning Approach
Nov 22, 2020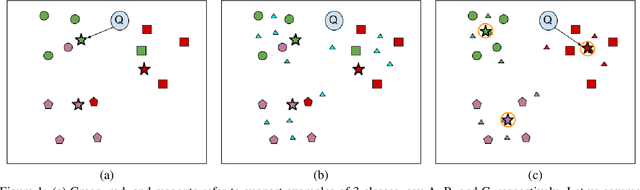
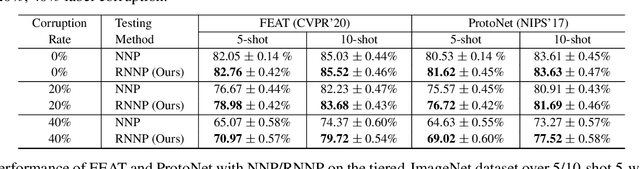

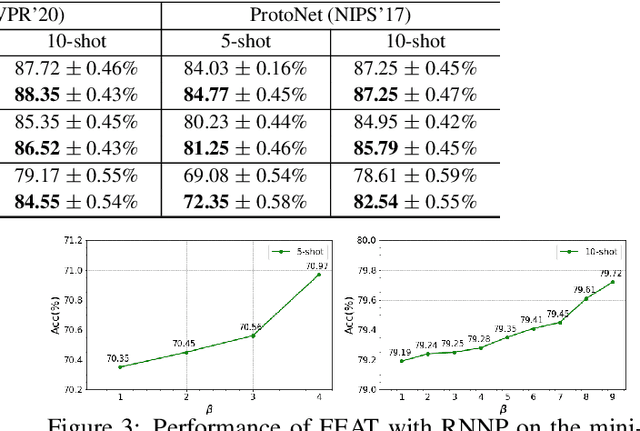
Learning from a few examples is an important practical aspect of training classifiers. Various works have examined this aspect quite well. However, all existing approaches assume that the few examples provided are always correctly labeled. This is a strong assumption, especially if one considers the current techniques for labeling using crowd-based labeling services. We address this issue by proposing a novel robust few-shot learning approach. Our method relies on generating robust prototypes from a set of few examples. Specifically, our method refines the class prototypes by producing hybrid features from the support examples of each class. The refined prototypes help to classify the query images better. Our method can replace the evaluation phase of any few-shot learning method that uses a nearest neighbor prototype-based evaluation procedure to make them robust. We evaluate our method on standard mini-ImageNet and tiered-ImageNet datasets. We perform experiments with various label corruption rates in the support examples of the few-shot classes. We obtain significant improvement over widely used few-shot learning methods that suffer significant performance degeneration in the presence of label noise. We finally provide extensive ablation experiments to validate our method.
SHAD3S: A model to Sketch, Shade and Shadow
Nov 19, 2020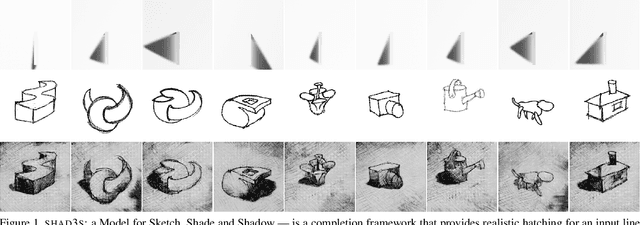

Hatching is a common method used by artists to accentuate the third dimension of a sketch, and to illuminate the scene. Our system SHAD3S attempts to compete with a human at hatching generic three-dimensional (3D) shapes, and also tries to assist her in a form exploration exercise. The novelty of our approach lies in the fact that we make no assumptions about the input other than that it represents a 3D shape, and yet, given a contextual information of illumination and texture, we synthesise an accurate hatch pattern over the sketch, without access to 3D or pseudo 3D. In the process, we contribute towards a) a cheap yet effective method to synthesise a sufficiently large high fidelity dataset, pertinent to task; b) creating a pipeline with conditional generative adversarial network (CGAN); and c) creating an interactive utility with GIMP, that is a tool for artists to engage with automated hatching or a form-exploration exercise. User evaluation of the tool suggests that the model performance does generalise satisfactorily over diverse input, both in terms of style as well as shape. A simple comparison of inception scores suggest that the generated distribution is as diverse as the ground truth.
Determinantal Point Process as an alternative to NMS
Aug 26, 2020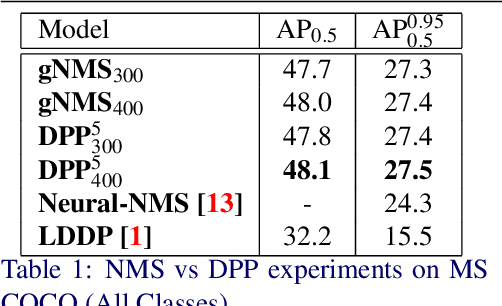
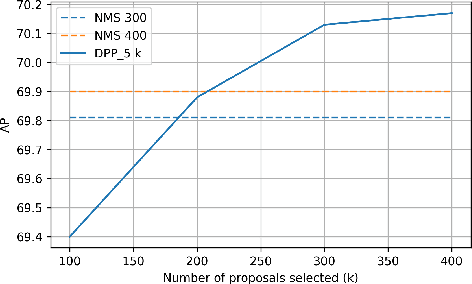
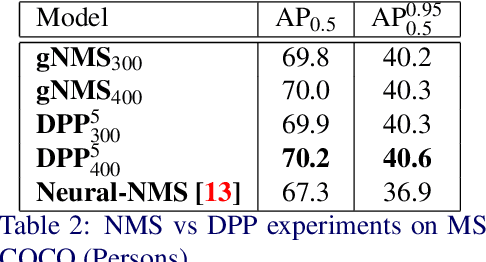
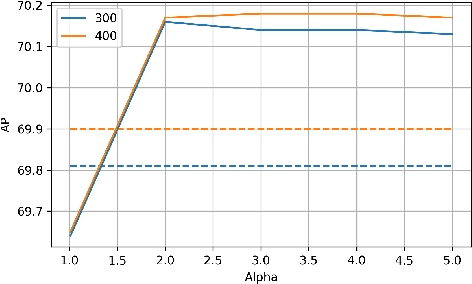
We present a determinantal point process (DPP) inspired alternative to non-maximum suppression (NMS) which has become an integral step in all state-of-the-art object detection frameworks. DPPs have been shown to encourage diversity in subset selection problems. We pose NMS as a subset selection problem and posit that directly incorporating DPP like framework can improve the overall performance of the object detection system. We propose an optimization problem which takes the same inputs as NMS, but introduces a novel sub-modularity based diverse subset selection functional. Our results strongly indicate that the modifications proposed in this paper can provide consistent improvements to state-of-the-art object detection pipelines.