 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan Unsupervised Segmentation Reduce Annotation Costs for Video Semantic Segmentation?
Mar 29, 2026Present-day deep neural networks for video semantic segmentation require a large number of fine-grained pixel-level annotations to achieve the best possible results. Obtaining such annotations, however, is very expensive. On the other hand, raw, unannotated video frames are practically free to obtain. Similarly, coarse annotations, which do not require precise boundaries, are also much cheaper. This paper investigates approaches to reduce the annotation cost required for video segmentation datasets by utilising such resources. We show that using state-of-the-art segmentation foundation models, Segment Anything Model (SAM) and Segment Anything Model 2 (SAM 2), we can utilise both unannotated frames as well as coarse annotations to alleviate the effort required for manual annotation of video segmentation datasets by automating mask generation. Our investigation suggests that if used appropriately, we can reduce the need for annotation by a third with similar performance for video semantic segmentation. More significantly, our analysis suggests that the variety of frames in the dataset is more important than the number of frames for obtaining the best performance.
Trusting Semantic Segmentation Networks
Jun 20, 2024Semantic segmentation has become an important task in computer vision with the growth of self-driving cars, medical image segmentation, etc. Although current models provide excellent results, they are still far from perfect and while there has been significant work in trying to improve the performance, both with respect to accuracy and speed of segmentation, there has been little work which analyses the failure cases of such systems. In this work, we aim to provide an analysis of how segmentation fails across different models and consider the question of whether these can be predicted reasonably at test time. To do so, we explore existing uncertainty-based metrics and see how well they correlate with misclassifications, allowing us to define the degree of trust we put in the output of our prediction models. Through several experiments on three different models across three datasets, we show that simple measures such as entropy can be used to capture misclassification with high recall rates.
Determinantal Point Process as an alternative to NMS
Aug 26, 2020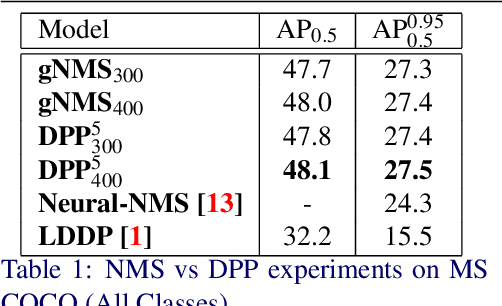
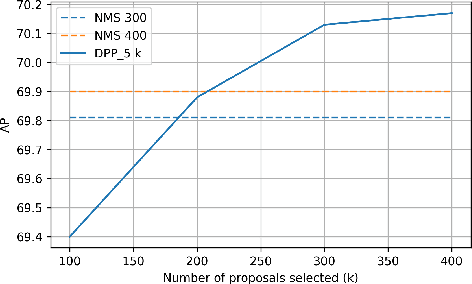
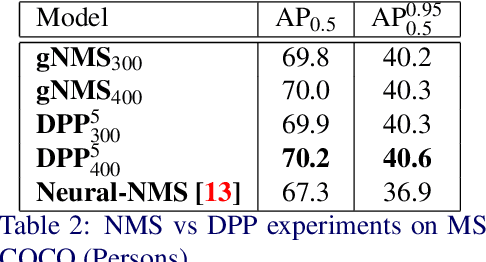
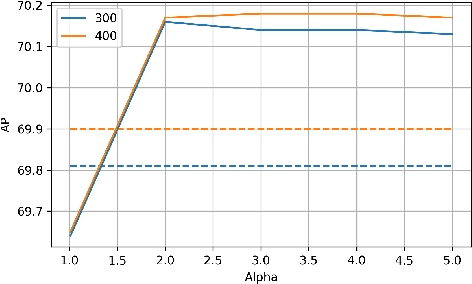
We present a determinantal point process (DPP) inspired alternative to non-maximum suppression (NMS) which has become an integral step in all state-of-the-art object detection frameworks. DPPs have been shown to encourage diversity in subset selection problems. We pose NMS as a subset selection problem and posit that directly incorporating DPP like framework can improve the overall performance of the object detection system. We propose an optimization problem which takes the same inputs as NMS, but introduces a novel sub-modularity based diverse subset selection functional. Our results strongly indicate that the modifications proposed in this paper can provide consistent improvements to state-of-the-art object detection pipelines.