 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding the Vulnerability of CLIP to Image Compression
Nov 23, 2023CLIP is a widely used foundational vision-language model that is used for zero-shot image recognition and other image-text alignment tasks. We demonstrate that CLIP is vulnerable to change in image quality under compression. This surprising result is further analysed using an attribution method-Integrated Gradients. Using this attribution method, we are able to better understand both quantitatively and qualitatively exactly the nature in which the compression affects the zero-shot recognition accuracy of this model. We evaluate this extensively on CIFAR-10 and STL-10. Our work provides the basis to understand this vulnerability of CLIP and can help us develop more effective methods to improve the robustness of CLIP and other vision-language models.
VERSE: Virtual-Gradient Aware Streaming Lifelong Learning with Anytime Inference
Sep 15, 2023



Lifelong learning, also referred to as continual learning, is the problem of training an AI agent continuously while also preventing it from forgetting its previously acquired knowledge. Most of the existing methods primarily focus on lifelong learning within a static environment and lack the ability to mitigate forgetting in a quickly-changing dynamic environment. Streaming lifelong learning is a challenging setting of lifelong learning with the goal of continuous learning in a dynamic non-stationary environment without forgetting. We introduce a novel approach to lifelong learning, which is streaming, requires a single pass over the data, can learn in a class-incremental manner, and can be evaluated on-the-fly (anytime inference). To accomplish these, we propose virtual gradients for continual representation learning to prevent catastrophic forgetting and leverage an exponential-moving-average-based semantic memory to further enhance performance. Extensive experiments on diverse datasets demonstrate our method's efficacy and superior performance over existing methods.
SpectFormer: Frequency and Attention is what you need in a Vision Transformer
Apr 14, 2023



Vision transformers have been applied successfully for image recognition tasks. There have been either multi-headed self-attention based (ViT \cite{dosovitskiy2020image}, DeIT, \cite{touvron2021training}) similar to the original work in textual models or more recently based on spectral layers (Fnet\cite{lee2021fnet}, GFNet\cite{rao2021global}, AFNO\cite{guibas2021efficient}). We hypothesize that both spectral and multi-headed attention plays a major role. We investigate this hypothesis through this work and observe that indeed combining spectral and multi-headed attention layers provides a better transformer architecture. We thus propose the novel Spectformer architecture for transformers that combines spectral and multi-headed attention layers. We believe that the resulting representation allows the transformer to capture the feature representation appropriately and it yields improved performance over other transformer representations. For instance, it improves the top-1 accuracy by 2\% on ImageNet compared to both GFNet-H and LiT. SpectFormer-S reaches 84.25\% top-1 accuracy on ImageNet-1K (state of the art for small version). Further, Spectformer-L achieves 85.7\% that is the state of the art for the comparable base version of the transformers. We further ensure that we obtain reasonable results in other scenarios such as transfer learning on standard datasets such as CIFAR-10, CIFAR-100, Oxford-IIIT-flower, and Standford Car datasets. We then investigate its use in downstream tasks such of object detection and instance segmentation on the MS-COCO dataset and observe that Spectformer shows consistent performance that is comparable to the best backbones and can be further optimized and improved. Hence, we believe that combined spectral and attention layers are what are needed for vision transformers.
Streaming LifeLong Learning With Any-Time Inference
Jan 27, 2023Despite rapid advancements in lifelong learning (LLL) research, a large body of research mainly focuses on improving the performance in the existing \textit{static} continual learning (CL) setups. These methods lack the ability to succeed in a rapidly changing \textit{dynamic} environment, where an AI agent needs to quickly learn new instances in a `single pass' from the non-i.i.d (also possibly temporally contiguous/coherent) data streams without suffering from catastrophic forgetting. For practical applicability, we propose a novel lifelong learning approach, which is streaming, i.e., a single input sample arrives in each time step, single pass, class-incremental, and subject to be evaluated at any moment. To address this challenging setup and various evaluation protocols, we propose a Bayesian framework, that enables fast parameter update, given a single training example, and enables any-time inference. We additionally propose an implicit regularizer in the form of snap-shot self-distillation, which effectively minimizes the forgetting further. We further propose an effective method that efficiently selects a subset of samples for online memory rehearsal and employs a new replay buffer management scheme that significantly boosts the overall performance. Our empirical evaluations and ablations demonstrate that the proposed method outperforms the prior works by large margins.
Compressing Video Calls using Synthetic Talking Heads
Oct 07, 2022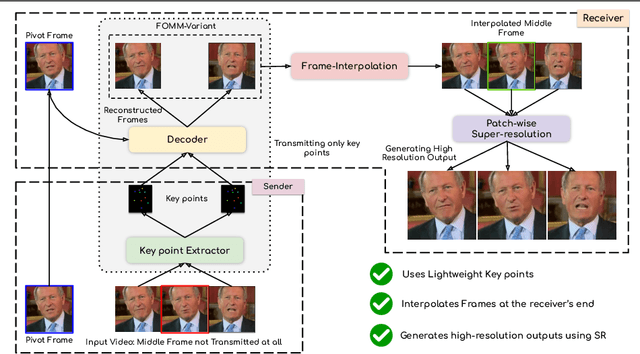
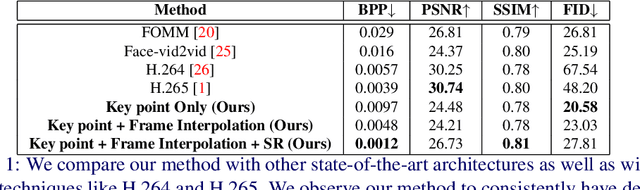
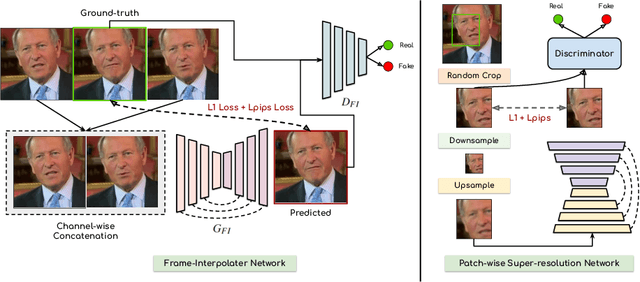
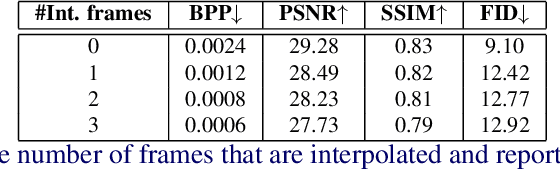
We leverage the modern advancements in talking head generation to propose an end-to-end system for talking head video compression. Our algorithm transmits pivot frames intermittently while the rest of the talking head video is generated by animating them. We use a state-of-the-art face reenactment network to detect key points in the non-pivot frames and transmit them to the receiver. A dense flow is then calculated to warp a pivot frame to reconstruct the non-pivot ones. Transmitting key points instead of full frames leads to significant compression. We propose a novel algorithm to adaptively select the best-suited pivot frames at regular intervals to provide a smooth experience. We also propose a frame-interpolater at the receiver's end to improve the compression levels further. Finally, a face enhancement network improves reconstruction quality, significantly improving several aspects like the sharpness of the generations. We evaluate our method both qualitatively and quantitatively on benchmark datasets and compare it with multiple compression techniques. We release a demo video and additional information at https://cvit.iiit.ac.in/research/projects/cvit-projects/talking-video-compression.
Learning Speaker-specific Lip-to-Speech Generation
Jun 04, 2022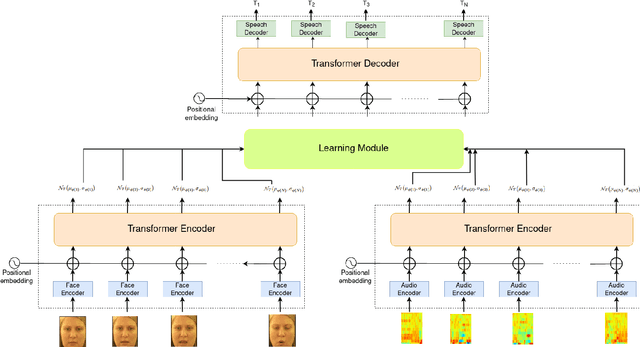
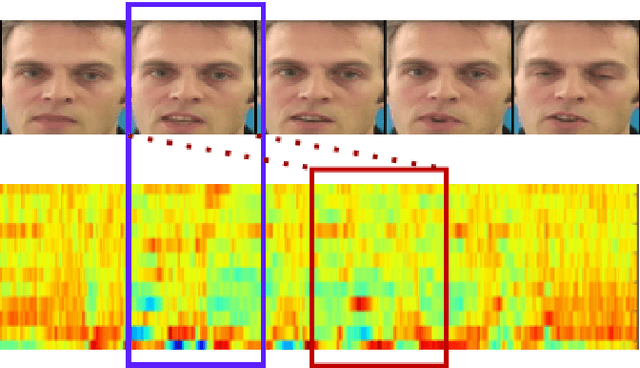
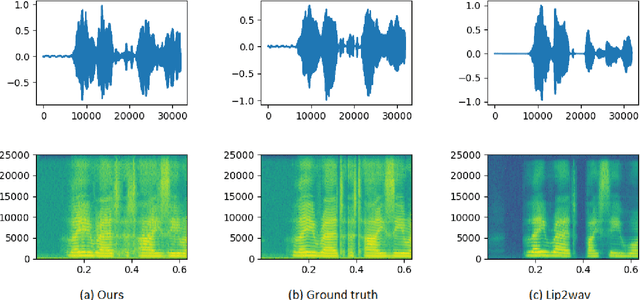
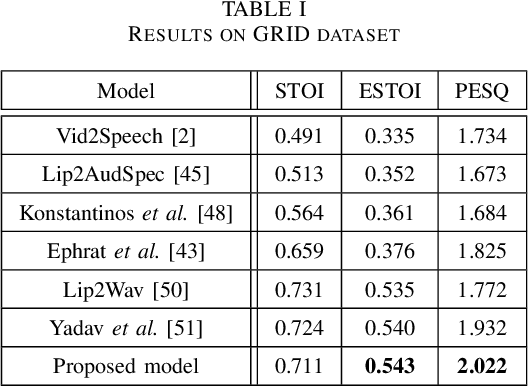
Understanding the lip movement and inferring the speech from it is notoriously difficult for the common person. The task of accurate lip-reading gets help from various cues of the speaker and its contextual or environmental setting. Every speaker has a different accent and speaking style, which can be inferred from their visual and speech features. This work aims to understand the correlation/mapping between speech and the sequence of lip movement of individual speakers in an unconstrained and large vocabulary. We model the frame sequence as a prior to the transformer in an auto-encoder setting and learned a joint embedding that exploits temporal properties of both audio and video. We learn temporal synchronization using deep metric learning, which guides the decoder to generate speech in sync with input lip movements. The predictive posterior thus gives us the generated speech in speaker speaking style. We have trained our model on the Grid and Lip2Wav Chemistry lecture dataset to evaluate single speaker natural speech generation tasks from lip movement in an unconstrained natural setting. Extensive evaluation using various qualitative and quantitative metrics with human evaluation also shows that our method outperforms the Lip2Wav Chemistry dataset(large vocabulary in an unconstrained setting) by a good margin across almost all evaluation metrics and marginally outperforms the state-of-the-art on GRID dataset.
Gradient Based Activations for Accurate Bias-Free Learning
Feb 17, 2022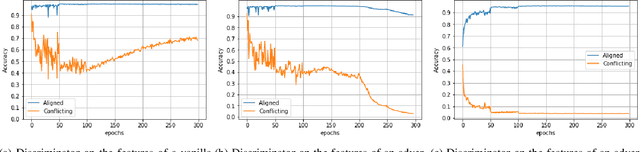

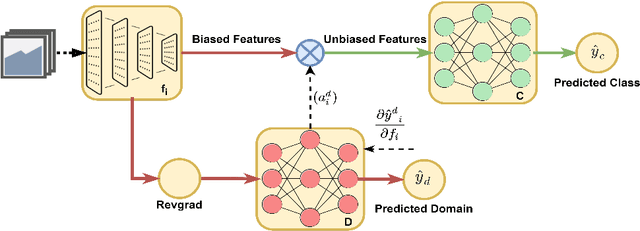

Bias mitigation in machine learning models is imperative, yet challenging. While several approaches have been proposed, one view towards mitigating bias is through adversarial learning. A discriminator is used to identify the bias attributes such as gender, age or race in question. This discriminator is used adversarially to ensure that it cannot distinguish the bias attributes. The main drawback in such a model is that it directly introduces a trade-off with accuracy as the features that the discriminator deems to be sensitive for discrimination of bias could be correlated with classification. In this work we solve the problem. We show that a biased discriminator can actually be used to improve this bias-accuracy tradeoff. Specifically, this is achieved by using a feature masking approach using the discriminator's gradients. We ensure that the features favoured for the bias discrimination are de-emphasized and the unbiased features are enhanced during classification. We show that this simple approach works well to reduce bias as well as improve accuracy significantly. We evaluate the proposed model on standard benchmarks. We improve the accuracy of the adversarial methods while maintaining or even improving the unbiasness and also outperform several other recent methods.
Class Incremental Online Streaming Learning
Oct 20, 2021
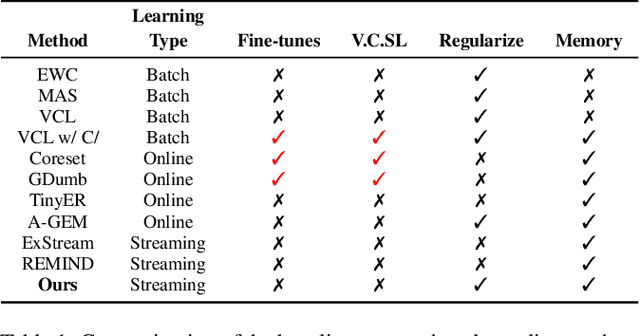

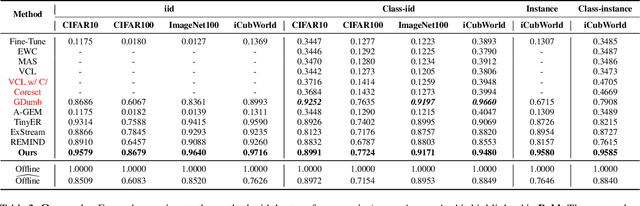
A wide variety of methods have been developed to enable lifelong learning in conventional deep neural networks. However, to succeed, these methods require a `batch' of samples to be available and visited multiple times during training. While this works well in a static setting, these methods continue to suffer in a more realistic situation where data arrives in \emph{online streaming manner}. We empirically demonstrate that the performance of current approaches degrades if the input is obtained as a stream of data with the following restrictions: $(i)$ each instance comes one at a time and can be seen only once, and $(ii)$ the input data violates the i.i.d assumption, i.e., there can be a class-based correlation. We propose a novel approach (CIOSL) for the class-incremental learning in an \emph{online streaming setting} to address these challenges. The proposed approach leverages implicit and explicit dual weight regularization and experience replay. The implicit regularization is leveraged via the knowledge distillation, while the explicit regularization incorporates a novel approach for parameter regularization by learning the joint distribution of the buffer replay and the current sample. Also, we propose an efficient online memory replay and replacement buffer strategy that significantly boosts the model's performance. Extensive experiments and ablation on challenging datasets show the efficacy of the proposed method.
Intelligent Video Editing: Incorporating Modern Talking Face Generation Algorithms in a Video Editor
Oct 16, 2021
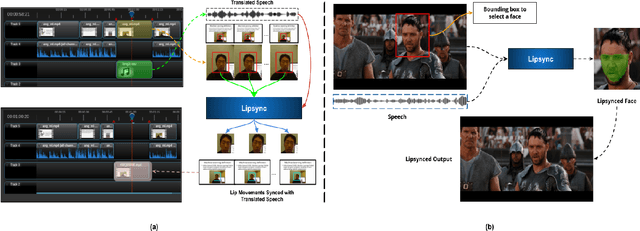

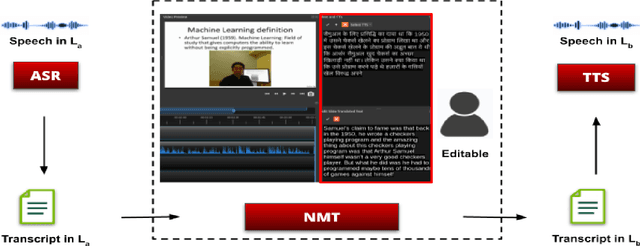
This paper proposes a video editor based on OpenShot with several state-of-the-art facial video editing algorithms as added functionalities. Our editor provides an easy-to-use interface to apply modern lip-syncing algorithms interactively. Apart from lip-syncing, the editor also uses audio and facial re-enactment to generate expressive talking faces. The manual control improves the overall experience of video editing without missing out on the benefits of modern synthetic video generation algorithms. This control enables us to lip-sync complex dubbed movie scenes, interviews, television shows, and other visual content. Furthermore, our editor provides features that automatically translate lectures from spoken content, lip-sync of the professor, and background content like slides. While doing so, we also tackle the critical aspect of synchronizing background content with the translated speech. We qualitatively evaluate the usefulness of the proposed editor by conducting human evaluations. Our evaluations show a clear improvement in the efficiency of using human editors and an improved video generation quality. We attach demo videos with the supplementary material clearly explaining the tool and also showcasing multiple results.
Attentive Contractive Flow: Improved Contractive Flows with Lipschitz-constrained Self-Attention
Sep 24, 2021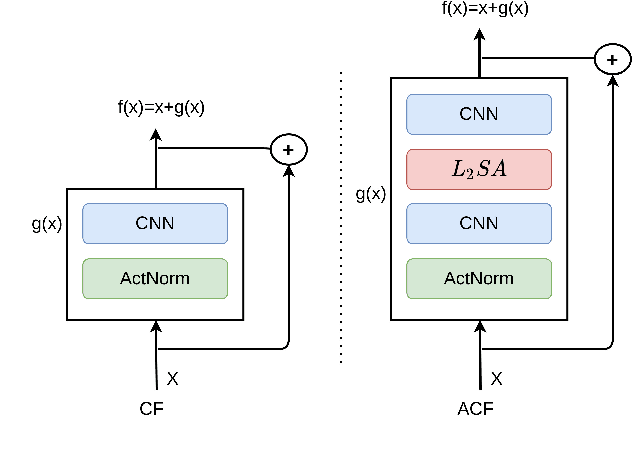

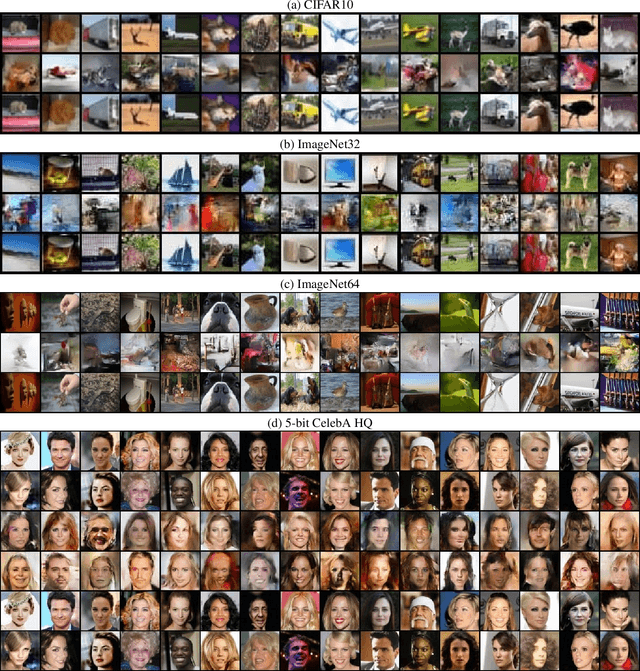
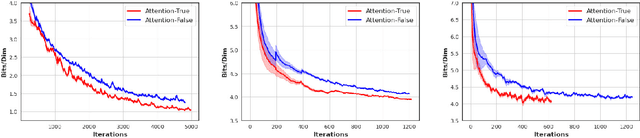
Normalizing flows provide an elegant method for obtaining tractable density estimates from distributions by using invertible transformations. The main challenge is to improve the expressivity of the models while keeping the invertibility constraints intact. We propose to do so via the incorporation of localized self-attention. However, conventional self-attention mechanisms don't satisfy the requirements to obtain invertible flows and can't be naively incorporated into normalizing flows. To address this, we introduce a novel approach called Attentive Contractive Flow (ACF) which utilizes a special category of flow-based generative models - contractive flows. We demonstrate that ACF can be introduced into a variety of state of the art flow models in a plug-and-play manner. This is demonstrated to not only improve the representation power of these models (improving on the bits per dim metric), but also to results in significantly faster convergence in training them. Qualitative results, including interpolations between test images, demonstrate that samples are more realistic and capture local correlations in the data well. We evaluate the results further by performing perturbation analysis using AWGN demonstrating that ACF models (especially the dot-product variant) show better and more consistent resilience to additive noise.