 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMathematics of Digital Hyperspace
Mar 28, 2021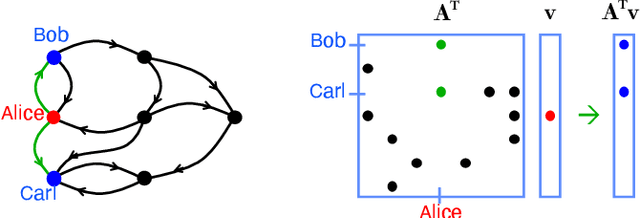
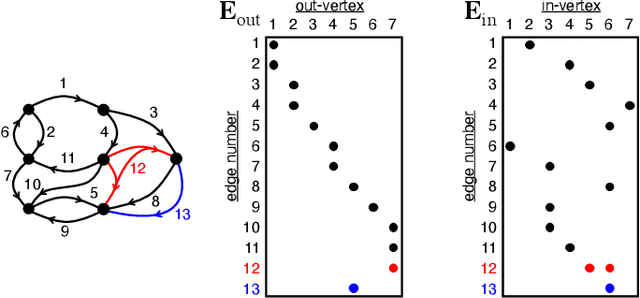
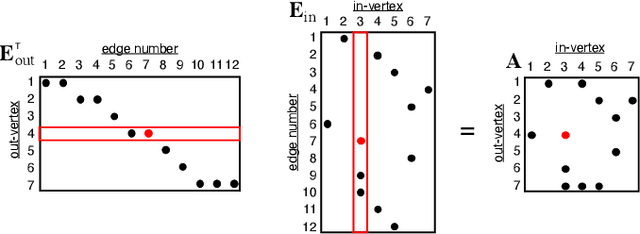
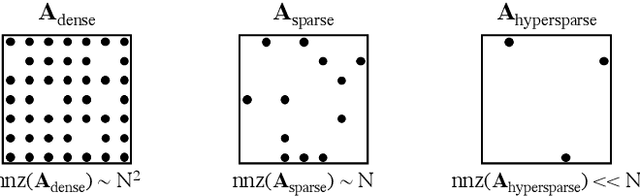
Social media, e-commerce, streaming video, e-mail, cloud documents, web pages, traffic flows, and network packets fill vast digital lakes, rivers, and oceans that we each navigate daily. This digital hyperspace is an amorphous flow of data supported by continuous streams that stretch standard concepts of type and dimension. The unstructured data of digital hyperspace can be elegantly represented, traversed, and transformed via the mathematics of hypergraphs, hypersparse matrices, and associative array algebra. This paper explores a novel mathematical concept, the semilink, that combines pairs of semirings to provide the essential operations for graph analytics, database operations, and machine learning. The GraphBLAS standard currently supports hypergraphs, hypersparse matrices, the mathematics required for semilinks, and seamlessly performs graph, network, and matrix operations. With the addition of key based indices (such as pointers to strings) and semilinks, GraphBLAS can become a richer associative array algebra and be a plug-in replacement for spreadsheets, database tables, and data centric operating systems, enhancing the navigation of unstructured data found in digital hyperspace.
Technical Report on Data Integration and Preparation
Mar 02, 2021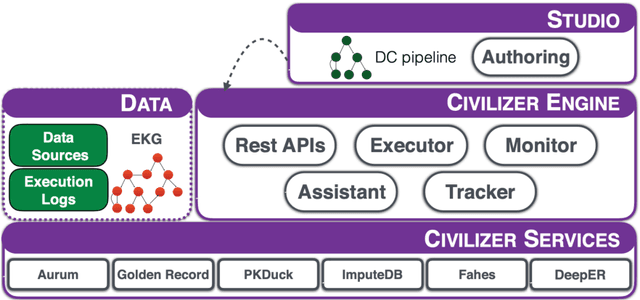
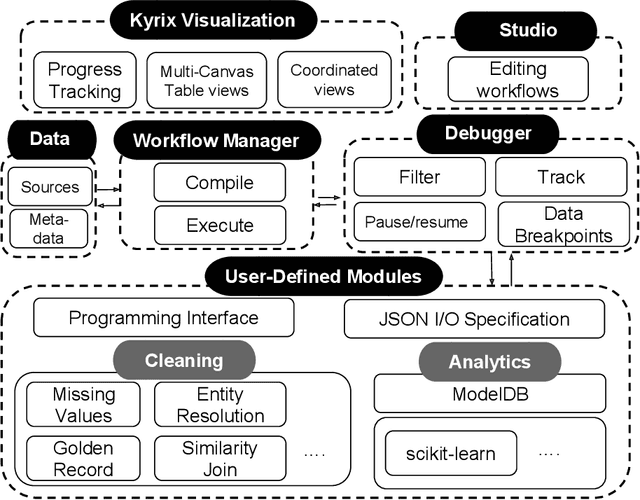
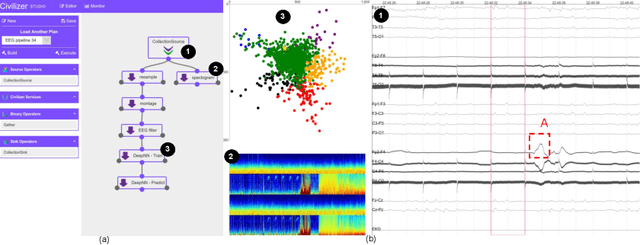
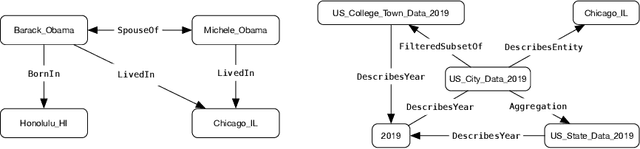
AI application developers typically begin with a dataset of interest and a vision of the end analytic or insight they wish to gain from the data at hand. Although these are two very important components of an AI workflow, one often spends the first few weeks (sometimes months) in the phase we refer to as data conditioning. This step typically includes tasks such as figuring out how to prepare data for analytics, dealing with inconsistencies in the dataset, and determining which algorithm (or set of algorithms) will be best suited for the application. Larger, faster, and messier datasets such as those from Internet of Things sensors, medical devices or autonomous vehicles only amplify these issues. These challenges, often referred to as the three Vs (volume, velocity, variety) of Big Data, require low-level tools for data management, preparation and integration. In most applications, data can come from structured and/or unstructured sources and often includes inconsistencies, formatting differences, and a lack of ground-truth labels. In this report, we highlight a number of tools that can be used to simplify data integration and preparation steps. Specifically, we focus on data integration tools and techniques, a deep dive into an exemplar data integration tool, and a deep-dive in the evolving field of knowledge graphs. Finally, we provide readers with a list of practical steps and considerations that they can use to simplify the data integration challenge. The goal of this report is to provide readers with a view of state-of-the-art as well as practical tips that can be used by data creators that make data integration more seamless.
Video Action Understanding: A Tutorial
Oct 13, 2020
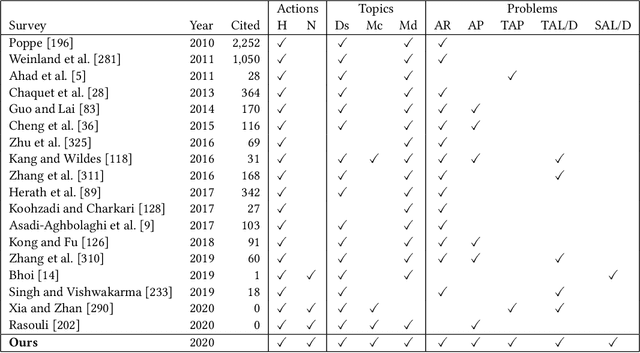
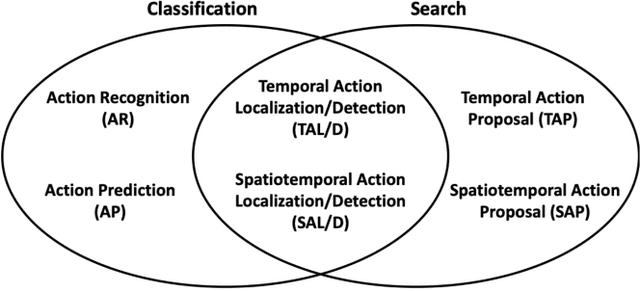
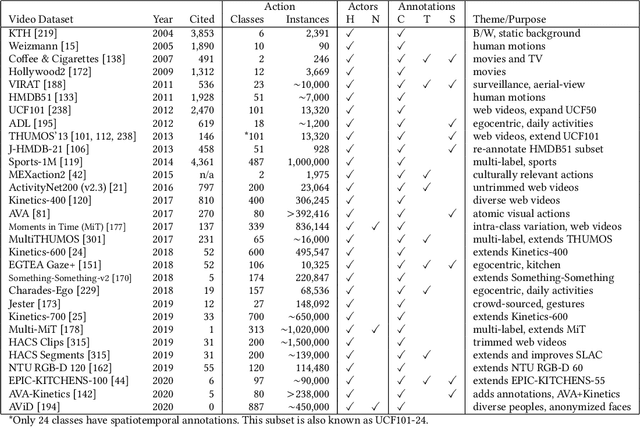
Many believe that the successes of deep learning on image understanding problems can be replicated in the realm of video understanding. However, the span of video action problems and the set of proposed deep learning solutions is arguably wider and more diverse than those of their 2D image siblings. Finding, identifying, and predicting actions are a few of the most salient tasks in video action understanding. This tutorial clarifies a taxonomy of video action problems, highlights datasets and metrics used to baseline each problem, describes common data preparation methods, and presents the building blocks of state-of-the-art deep learning model architectures.
Survey of Machine Learning Accelerators
Sep 01, 2020
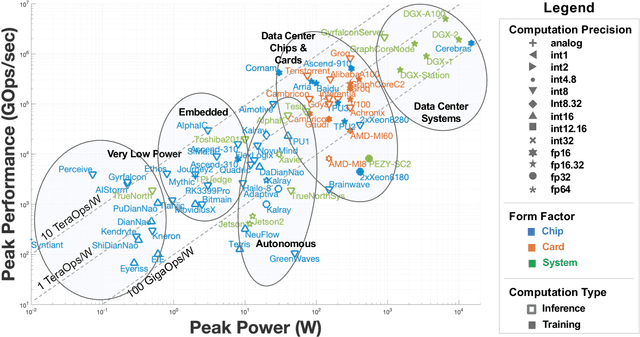
New machine learning accelerators are being announced and released each month for a variety of applications from speech recognition, video object detection, assisted driving, and many data center applications. This paper updates the survey of of AI accelerators and processors from last year's IEEE-HPEC paper. This paper collects and summarizes the current accelerators that have been publicly announced with performance and power consumption numbers. The performance and power values are plotted on a scatter graph and a number of dimensions and observations from the trends on this plot are discussed and analyzed. For instance, there are interesting trends in the plot regarding power consumption, numerical precision, and inference versus training. This year, there are many more announced accelerators that are implemented with many more architectures and technologies from vector engines, dataflow engines, neuromorphic designs, flash-based analog memory processing, and photonic-based processing.
Accuracy and Performance Comparison of Video Action Recognition Approaches
Aug 20, 2020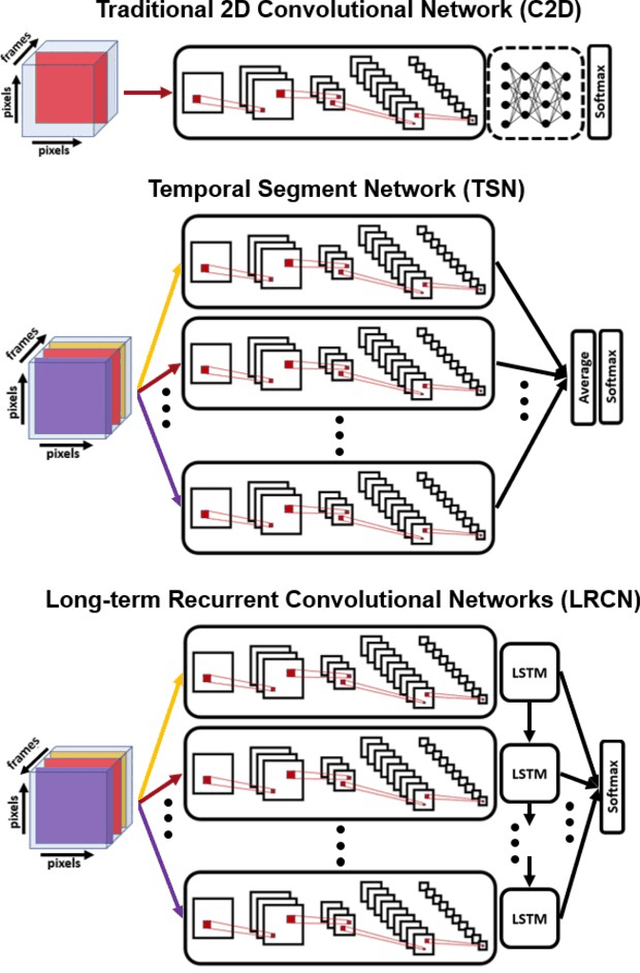
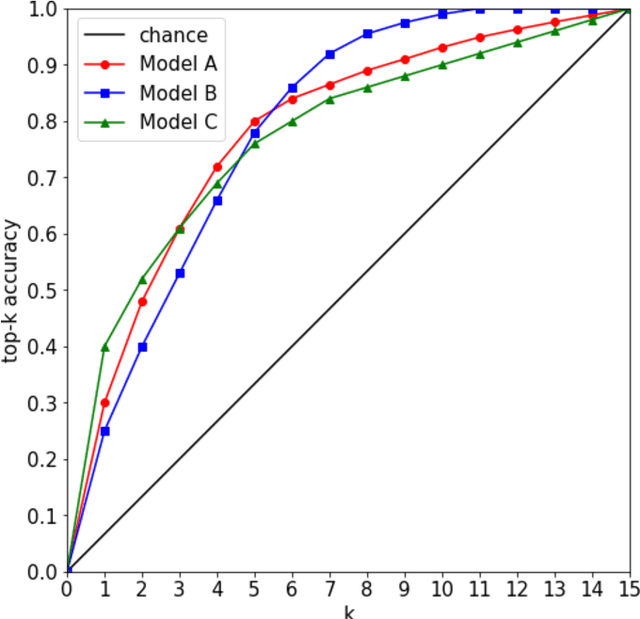
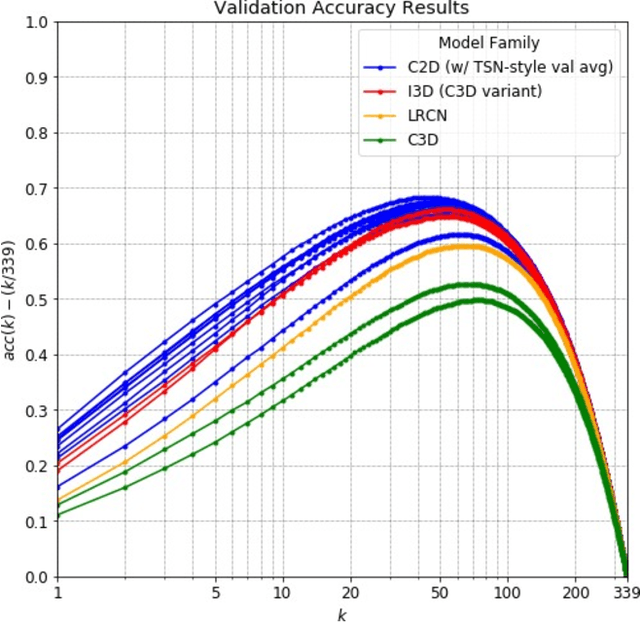
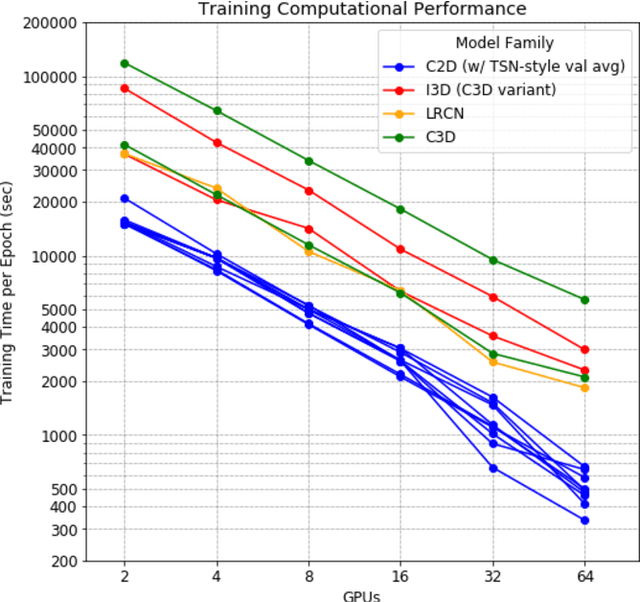
Over the past few years, there has been significant interest in video action recognition systems and models. However, direct comparison of accuracy and computational performance results remain clouded by differing training environments, hardware specifications, hyperparameters, pipelines, and inference methods. This article provides a direct comparison between fourteen off-the-shelf and state-of-the-art models by ensuring consistency in these training characteristics in order to provide readers with a meaningful comparison across different types of video action recognition algorithms. Accuracy of the models is evaluated using standard Top-1 and Top-5 accuracy metrics in addition to a proposed new accuracy metric. Additionally, we compare computational performance of distributed training from two to sixty-four GPUs on a state-of-the-art HPC system.
Benchmarking network fabrics for data distributed training of deep neural networks
Aug 18, 2020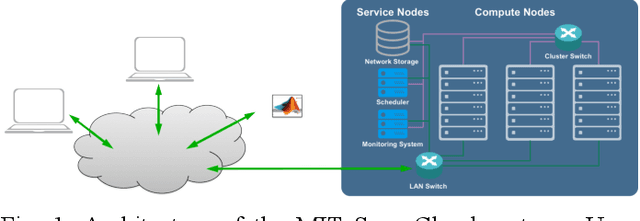
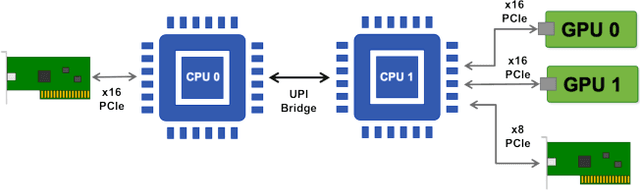
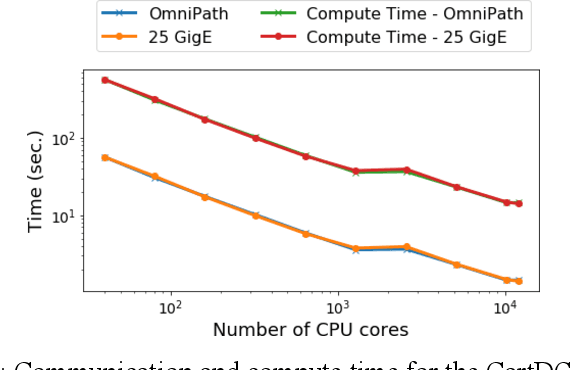

Artificial Intelligence/Machine Learning applications require the training of complex models on large amounts of labelled data. The large computational requirements for training deep models have necessitated the development of new methods for faster training. One such approach is the data parallel approach, where the training data is distributed across multiple compute nodes. This approach is simple to implement and supported by most of the commonly used machine learning frameworks. The data parallel approach leverages MPI for communicating gradients across all nodes. In this paper, we examine the effects of using different physical hardware interconnects and network-related software primitives for enabling data distributed deep learning. We compare the effect of using GPUDirect and NCCL on Ethernet and OmniPath fabrics. Our results show that using Ethernet-based networking in shared HPC systems does not have a significant effect on the training times for commonly used deep neural network architectures or traditional HPC applications such as Computational Fluid Dynamics.
Layer-Parallel Training with GPU Concurrency of Deep Residual Neural Networks Via Nonlinear Multigrid
Jul 14, 2020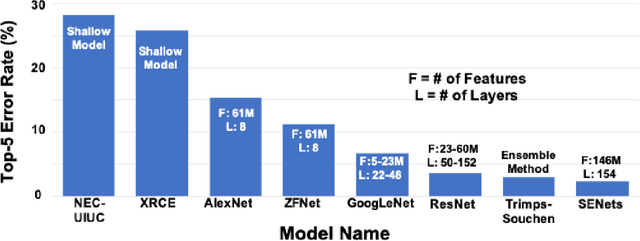
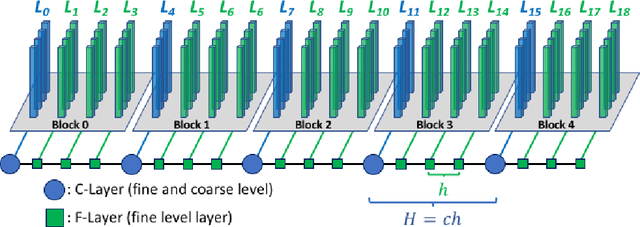

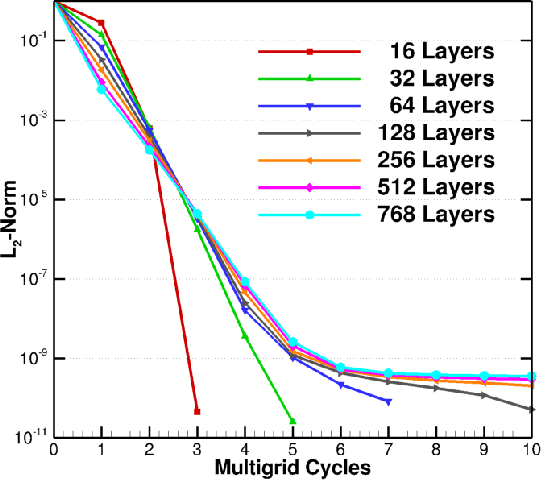
A Multigrid Full Approximation Storage algorithm for solving Deep Residual Networks is developed to enable neural network parallelized layer-wise training and concurrent computational kernel execution on GPUs. This work demonstrates a 10.2x speedup over traditional layer-wise model parallelism techniques using the same number of compute units.
GraphChallenge.org Sparse Deep Neural Network Performance
Apr 06, 2020
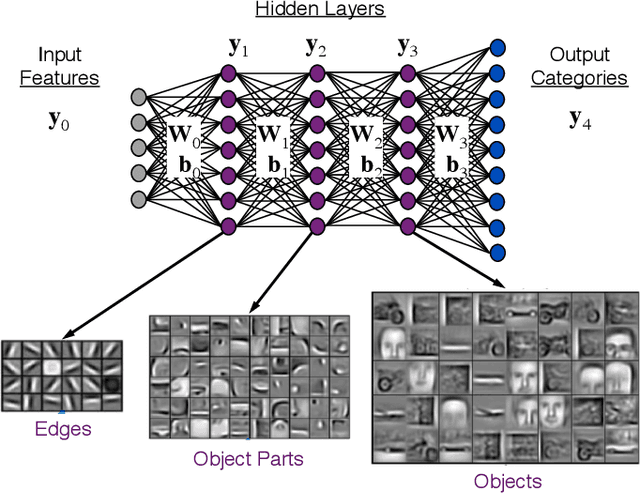
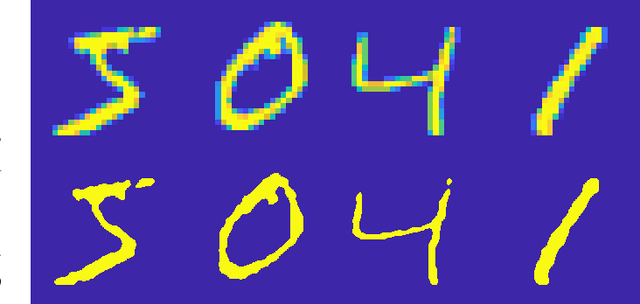
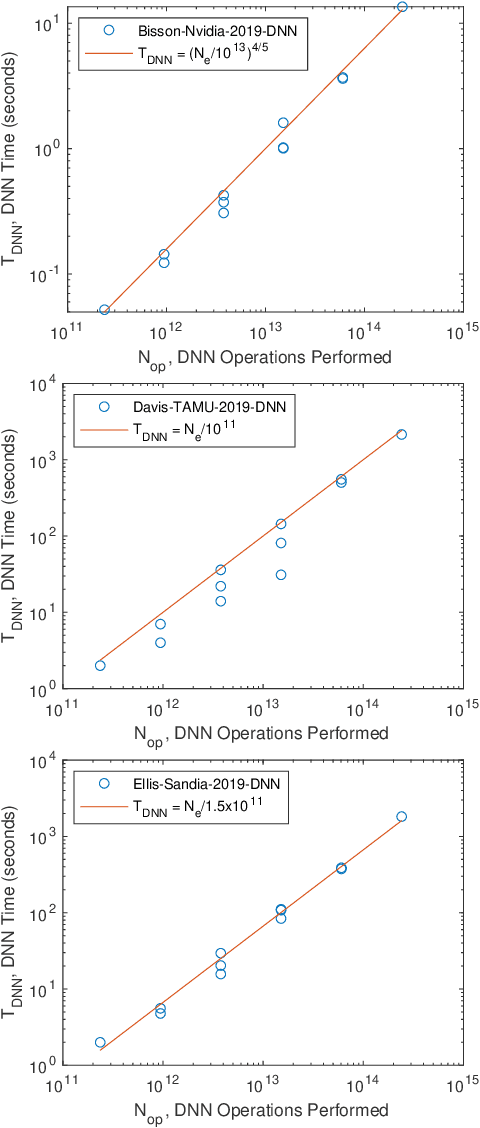
The MIT/IEEE/Amazon GraphChallenge.org encourages community approaches to developing new solutions for analyzing graphs and sparse data. Sparse AI analytics present unique scalability difficulties. The Sparse Deep Neural Network (DNN) Challenge draws upon prior challenges from machine learning, high performance computing, and visual analytics to create a challenge that is reflective of emerging sparse AI systems. The sparse DNN challenge is based on a mathematically well-defined DNN inference computation and can be implemented in any programming environment. In 2019 several sparse DNN challenge submissions were received from a wide range of authors and organizations. This paper presents a performance analysis of the best performers of these submissions. These submissions show that their state-of-the-art sparse DNN execution time, $T_{\rm DNN}$, is a strong function of the number of DNN operations performed, $N_{\rm op}$. The sparse DNN challenge provides a clear picture of current sparse DNN systems and underscores the need for new innovations to achieve high performance on very large sparse DNNs.
Survey of Attacks and Defenses on Edge-Deployed Neural Networks
Nov 27, 2019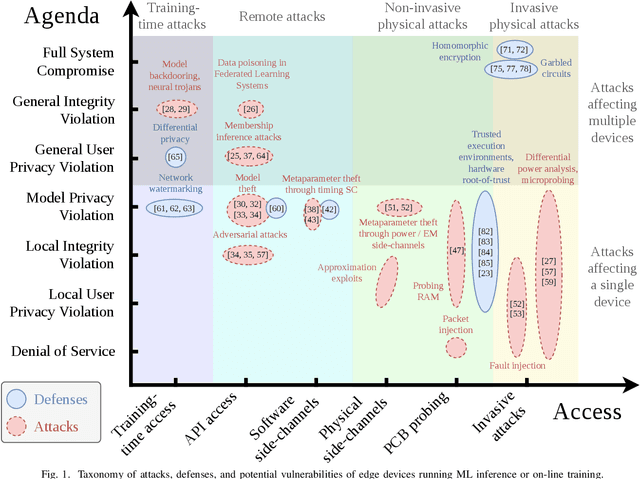
Deep Neural Network (DNN) workloads are quickly moving from datacenters onto edge devices, for latency, privacy, or energy reasons. While datacenter networks can be protected using conventional cybersecurity measures, edge neural networks bring a host of new security challenges. Unlike classic IoT applications, edge neural networks are typically very compute and memory intensive, their execution is data-independent, and they are robust to noise and faults. Neural network models may be very expensive to develop, and can potentially reveal information about the private data they were trained on, requiring special care in distribution. The hidden states and outputs of the network can also be used in reconstructing user inputs, potentially violating users' privacy. Furthermore, neural networks are vulnerable to adversarial attacks, which may cause misclassifications and violate the integrity of the output. These properties add challenges when securing edge-deployed DNNs, requiring new considerations, threat models, priorities, and approaches in securely and privately deploying DNNs to the edge. In this work, we cover the landscape of attacks on, and defenses, of neural networks deployed in edge devices and provide a taxonomy of attacks and defenses targeting edge DNNs.
Sparse Deep Neural Network Graph Challenge
Sep 02, 2019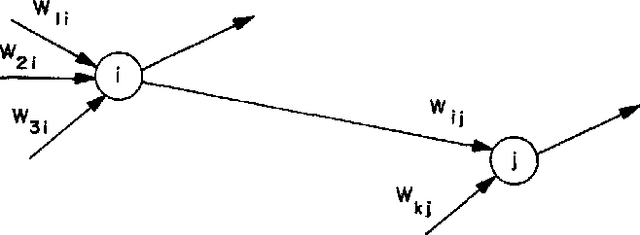
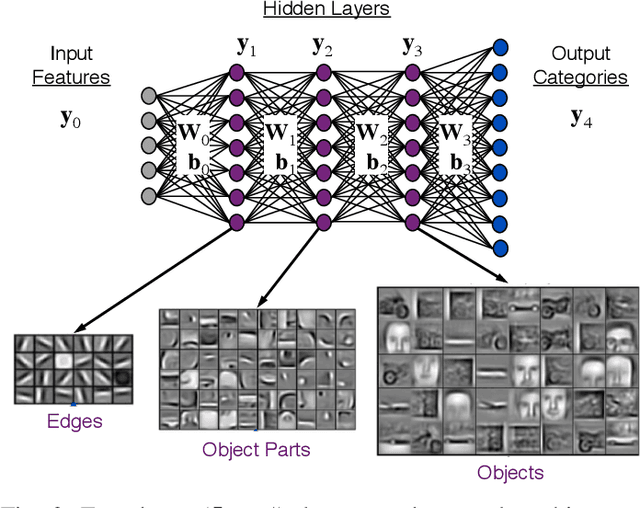
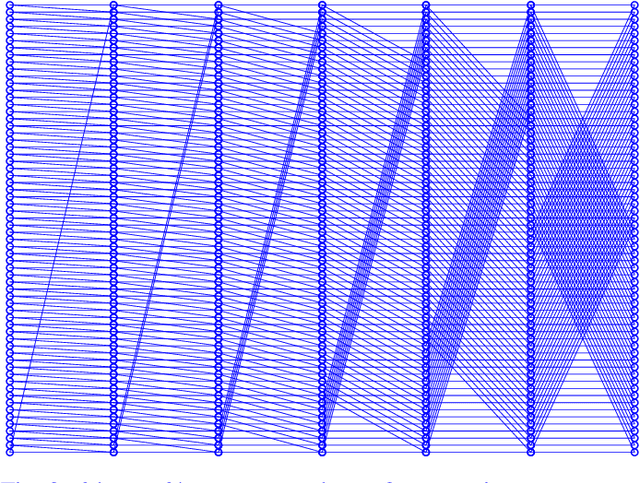
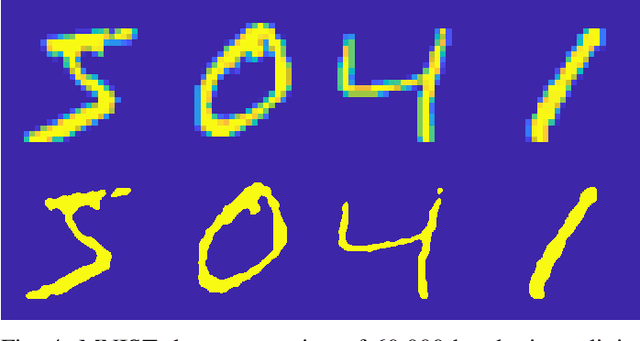
The MIT/IEEE/Amazon GraphChallenge.org encourages community approaches to developing new solutions for analyzing graphs and sparse data. Sparse AI analytics present unique scalability difficulties. The proposed Sparse Deep Neural Network (DNN) Challenge draws upon prior challenges from machine learning, high performance computing, and visual analytics to create a challenge that is reflective of emerging sparse AI systems. The Sparse DNN Challenge is based on a mathematically well-defined DNN inference computation and can be implemented in any programming environment. Sparse DNN inference is amenable to both vertex-centric implementations and array-based implementations (e.g., using the GraphBLAS.org standard). The computations are simple enough that performance predictions can be made based on simple computing hardware models. The input data sets are derived from the MNIST handwritten letters. The surrounding I/O and verification provide the context for each sparse DNN inference that allows rigorous definition of both the input and the output. Furthermore, since the proposed sparse DNN challenge is scalable in both problem size and hardware, it can be used to measure and quantitatively compare a wide range of present day and future systems. Reference implementations have been implemented and their serial and parallel performance have been measured. Specifications, data, and software are publicly available at GraphChallenge.org