 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNLP Service APIs and Models for Efficient Registration of New Clients
Oct 04, 2020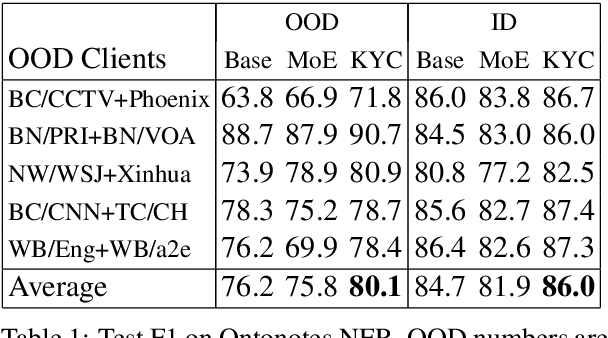
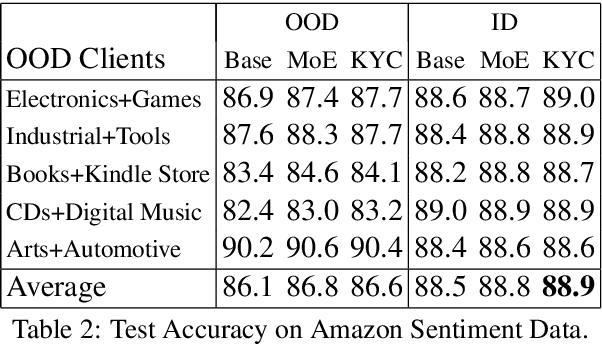
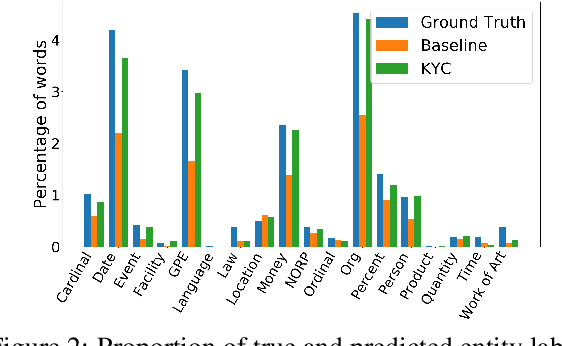
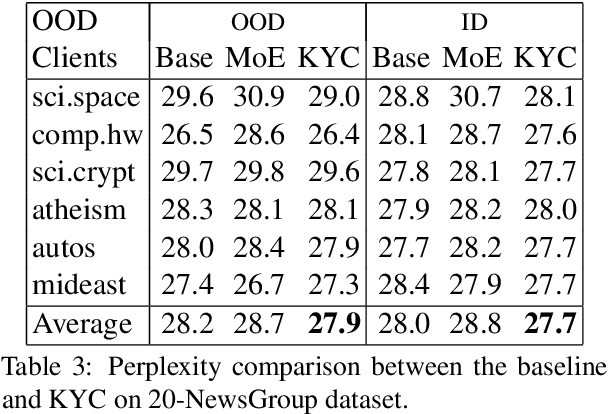
State-of-the-art NLP inference uses enormous neural architectures and models trained for GPU-months, well beyond the reach of most consumers of NLP. This has led to one-size-fits-all public API-based NLP service models by major AI companies, serving large numbers of clients. Neither (hardware deficient) clients nor (heavily subscribed) servers can afford traditional fine tuning. Many clients own little or no labeled data. We initiate a study of adaptation of centralized NLP services to clients, and present one practical and lightweight approach. Each client uses an unsupervised, corpus-based sketch to register to the service. The server uses an auxiliary network to map the sketch to an abstract vector representation, which then informs the main labeling network. When a new client registers with its sketch, it gets immediate accuracy benefits. We demonstrate the success of the proposed architecture using sentiment labeling, NER, and predictive language modeling
Untapped Potential of Data Augmentation: A Domain Generalization Viewpoint
Jul 09, 2020
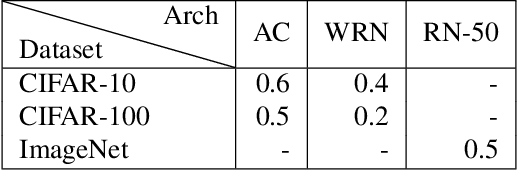
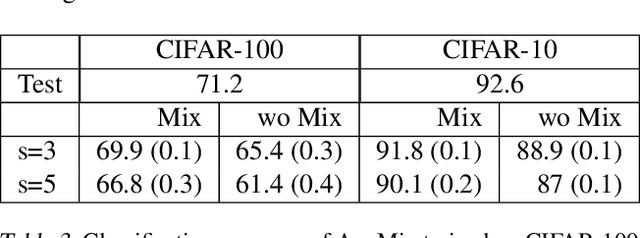
Data augmentation is a popular pre-processing trick to improve generalization accuracy. It is believed that by processing augmented inputs in tandem with the original ones, the model learns a more robust set of features which are shared between the original and augmented counterparts. However, we show that is not the case even for the best augmentation technique. In this work, we take a Domain Generalization viewpoint of augmentation based methods. This new perspective allowed for probing overfitting and delineating avenues for improvement. Our exploration with the state-of-art augmentation method provides evidence that the learned representations are not as robust even towards distortions used during training. This suggests evidence for the untapped potential of augmented examples.
Efficient Domain Generalization via Common-Specific Low-Rank Decomposition
Apr 07, 2020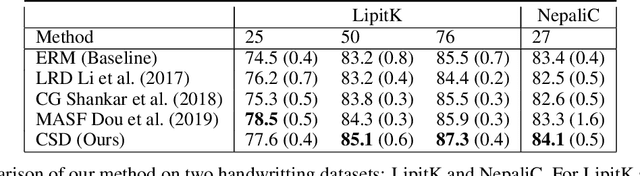
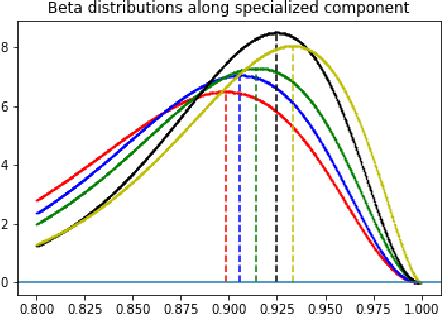


Domain generalization refers to the task of training a model which generalizes to new domains that are not seen during training. We present CSD (Common Specific Decomposition), for this setting,which jointly learns a common component (which generalizes to new domains) and a domain specific component (which overfits on training domains). The domain specific components are discarded after training and only the common component is retained. The algorithm is extremely simple and involves only modifying the final linear classification layer of any given neural network architecture. We present a principled analysis to understand existing approaches, provide identifiability results of CSD,and study effect of low-rank on domain generalization. We show that CSD either matches or beats state of the art approaches for domain generalization based on domain erasure, domain perturbed data augmentation, and meta-learning. Further diagnostics on rotated MNIST, where domains are interpretable, confirm the hypothesis that CSD successfully disentangles common and domain specific components and hence leads to better domain generalization.
Parallel Iterative Edit Models for Local Sequence Transduction
Oct 07, 2019

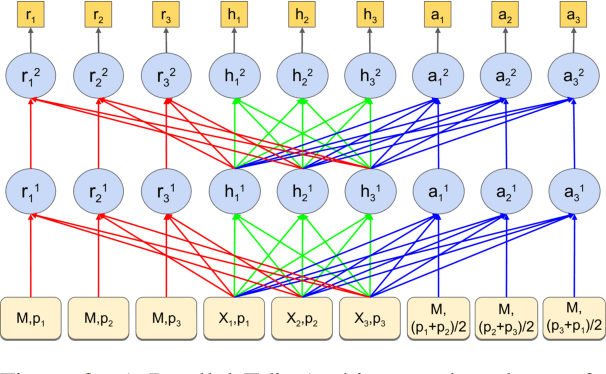
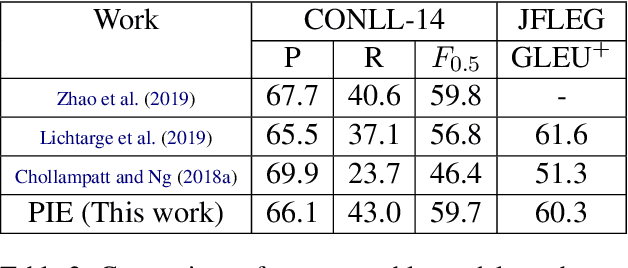
We present a Parallel Iterative Edit (PIE) model for the problem of local sequence transduction arising in tasks like Grammatical error correction (GEC). Recent approaches are based on the popular encoder-decoder (ED) model for sequence to sequence learning. The ED model auto-regressively captures full dependency among output tokens but is slow due to sequential decoding. The PIE model does parallel decoding, giving up the advantage of modelling full dependency in the output, yet it achieves accuracy competitive with the ED model for four reasons: 1.~predicting edits instead of tokens, 2.~labeling sequences instead of generating sequences, 3.~iteratively refining predictions to capture dependencies, and 4.~factorizing logits over edits and their token argument to harness pre-trained language models like BERT. Experiments on tasks spanning GEC, OCR correction and spell correction demonstrate that the PIE model is an accurate and significantly faster alternative for local sequence transduction.
Topic Sensitive Attention on Generic Corpora Corrects Sense Bias in Pretrained Embeddings
Jul 24, 2019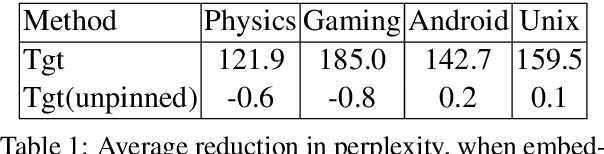
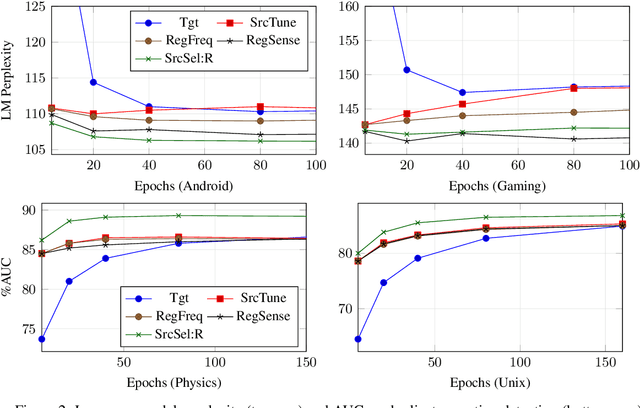
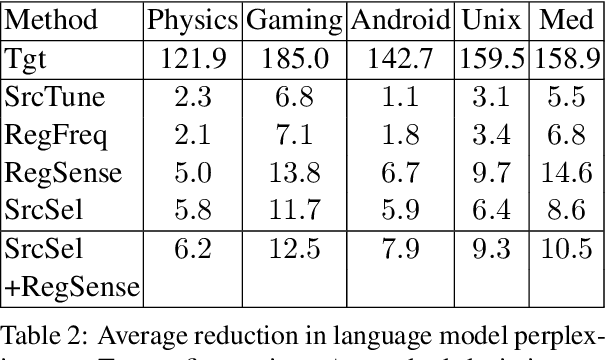
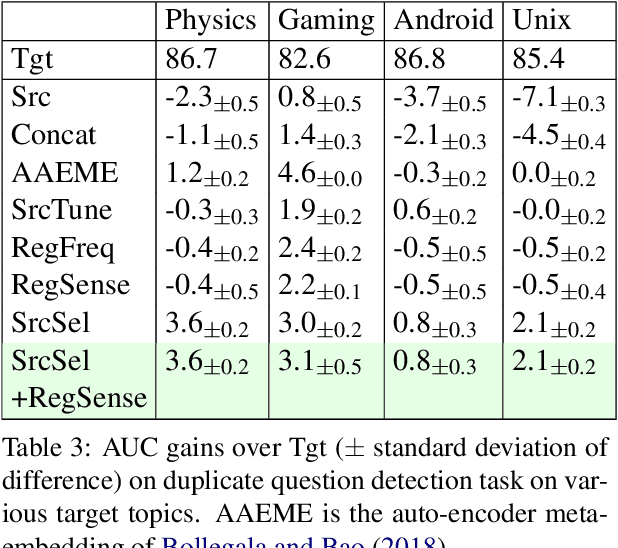
Given a small corpus $\mathcal D_T$ pertaining to a limited set of focused topics, our goal is to train embeddings that accurately capture the sense of words in the topic in spite of the limited size of $\mathcal D_T$. These embeddings may be used in various tasks involving $\mathcal D_T$. A popular strategy in limited data settings is to adapt pre-trained embeddings $\mathcal E$ trained on a large corpus. To correct for sense drift, fine-tuning, regularization, projection, and pivoting have been proposed recently. Among these, regularization informed by a word's corpus frequency performed well, but we improve upon it using a new regularizer based on the stability of its cooccurrence with other words. However, a thorough comparison across ten topics, spanning three tasks, with standardized settings of hyper-parameters, reveals that even the best embedding adaptation strategies provide small gains beyond well-tuned baselines, which many earlier comparisons ignored. In a bold departure from adapting pretrained embeddings, we propose using $\mathcal D_T$ to probe, attend to, and borrow fragments from any large, topic-rich source corpus (such as Wikipedia), which need not be the corpus used to pretrain embeddings. This step is made scalable and practical by suitable indexing. We reach the surprising conclusion that even limited corpus augmentation is more useful than adapting embeddings, which suggests that non-dominant sense information may be irrevocably obliterated from pretrained embeddings and cannot be salvaged by adaptation.
Generalizing Across Domains via Cross-Gradient Training
May 01, 2018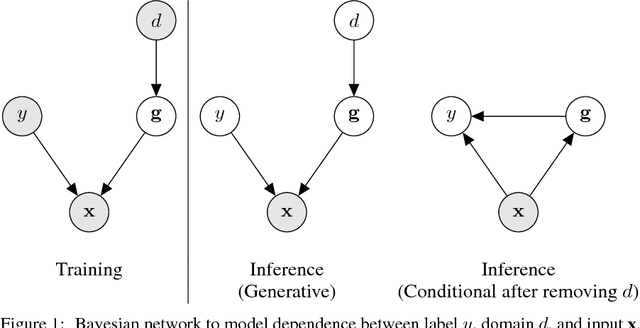
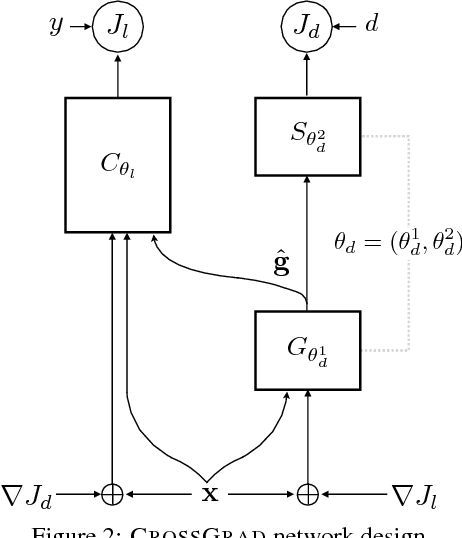

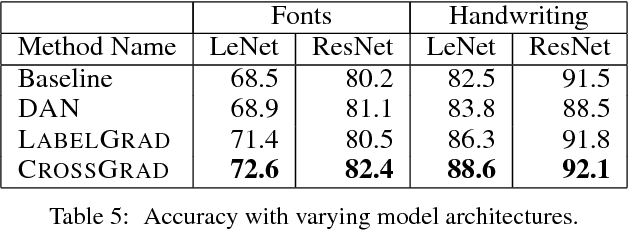
We present CROSSGRAD, a method to use multi-domain training data to learn a classifier that generalizes to new domains. CROSSGRAD does not need an adaptation phase via labeled or unlabeled data, or domain features in the new domain. Most existing domain adaptation methods attempt to erase domain signals using techniques like domain adversarial training. In contrast, CROSSGRAD is free to use domain signals for predicting labels, if it can prevent overfitting on training domains. We conceptualize the task in a Bayesian setting, in which a sampling step is implemented as data augmentation, based on domain-guided perturbations of input instances. CROSSGRAD parallelly trains a label and a domain classifier on examples perturbed by loss gradients of each other's objectives. This enables us to directly perturb inputs, without separating and re-mixing domain signals while making various distributional assumptions. Empirical evaluation on three different applications where this setting is natural establishes that (1) domain-guided perturbation provides consistently better generalization to unseen domains, compared to generic instance perturbation methods, and that (2) data augmentation is a more stable and accurate method than domain adversarial training.