 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBlock Pruning For Faster Transformers
Sep 10, 2021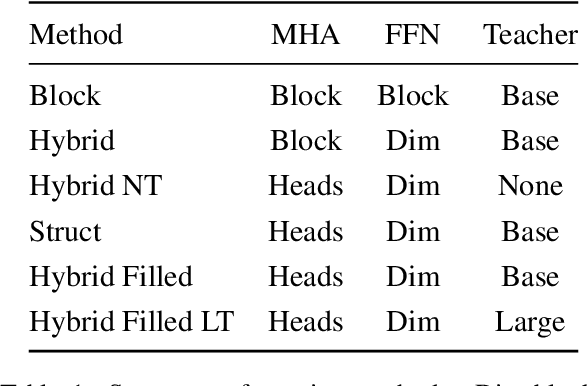
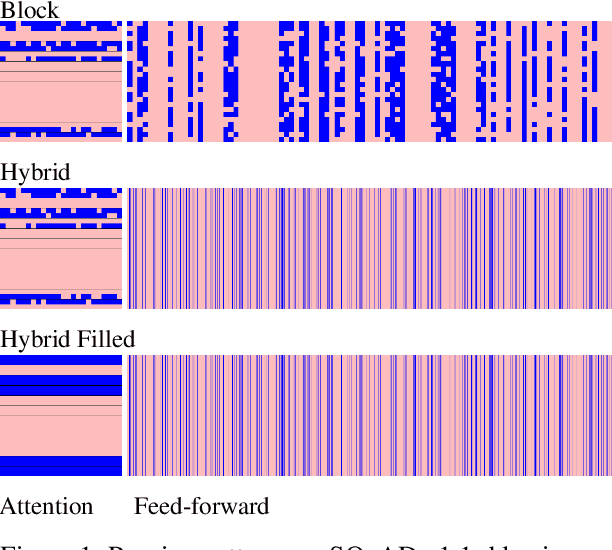
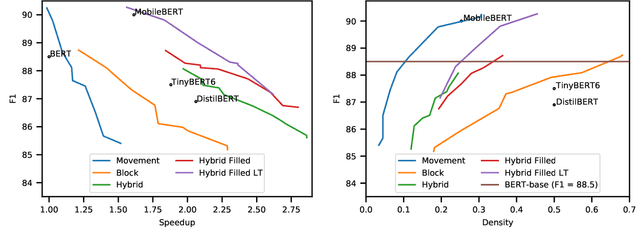
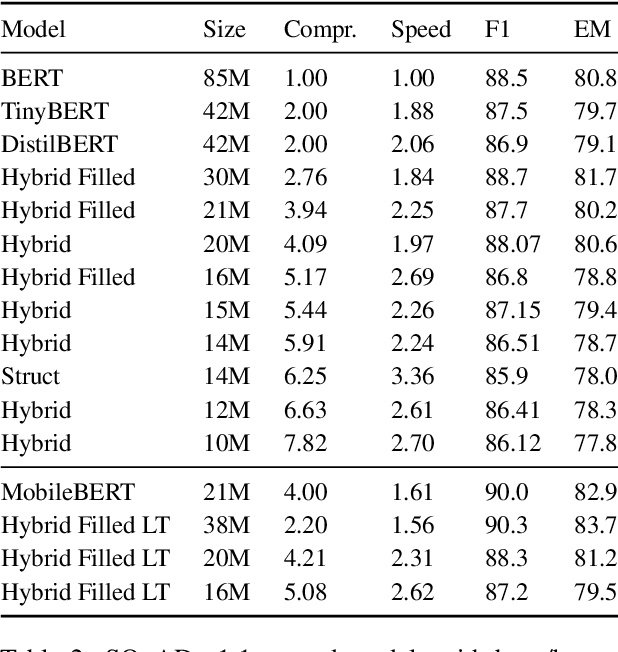
Pre-training has improved model accuracy for both classification and generation tasks at the cost of introducing much larger and slower models. Pruning methods have proven to be an effective way of reducing model size, whereas distillation methods are proven for speeding up inference. We introduce a block pruning approach targeting both small and fast models. Our approach extends structured methods by considering blocks of any size and integrates this structure into the movement pruning paradigm for fine-tuning. We find that this approach learns to prune out full components of the underlying model, such as attention heads. Experiments consider classification and generation tasks, yielding among other results a pruned model that is a 2.4x faster, 74% smaller BERT on SQuAD v1, with a 1% drop on F1, competitive both with distilled models in speed and pruned models in size.
Avoiding Inference Heuristics in Few-shot Prompt-based Finetuning
Sep 09, 2021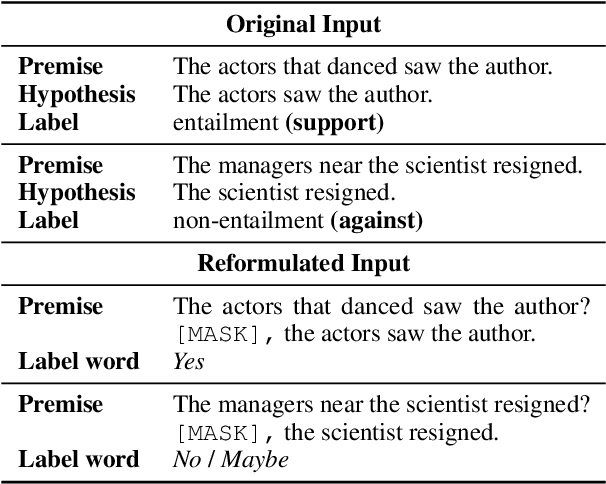
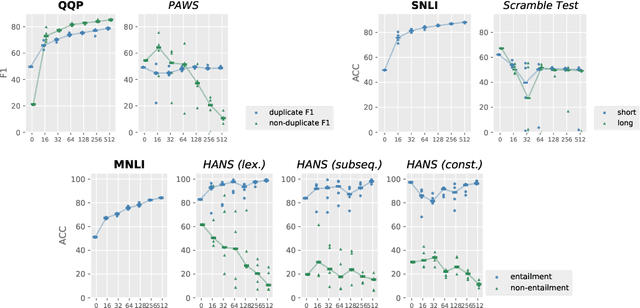
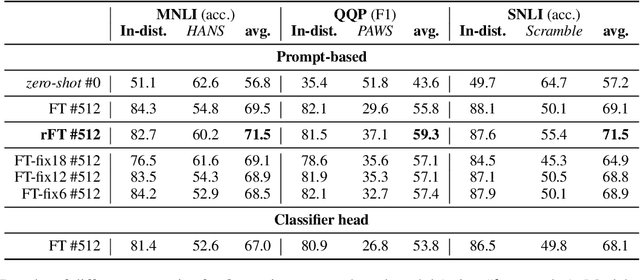
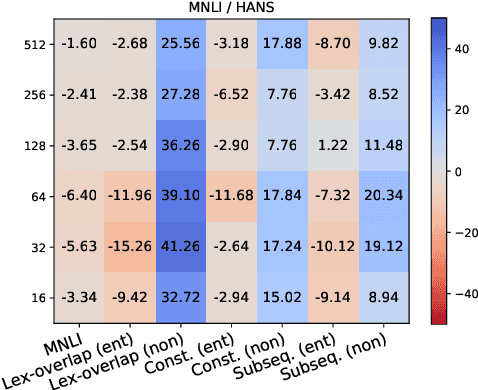
Recent prompt-based approaches allow pretrained language models to achieve strong performances on few-shot finetuning by reformulating downstream tasks as a language modeling problem. In this work, we demonstrate that, despite its advantages on low data regimes, finetuned prompt-based models for sentence pair classification tasks still suffer from a common pitfall of adopting inference heuristics based on lexical overlap, e.g., models incorrectly assuming a sentence pair is of the same meaning because they consist of the same set of words. Interestingly, we find that this particular inference heuristic is significantly less present in the zero-shot evaluation of the prompt-based model, indicating how finetuning can be destructive to useful knowledge learned during the pretraining. We then show that adding a regularization that preserves pretraining weights is effective in mitigating this destructive tendency of few-shot finetuning. Our evaluation on three datasets demonstrates promising improvements on the three corresponding challenge datasets used to diagnose the inference heuristics.
Datasets: A Community Library for Natural Language Processing
Sep 07, 2021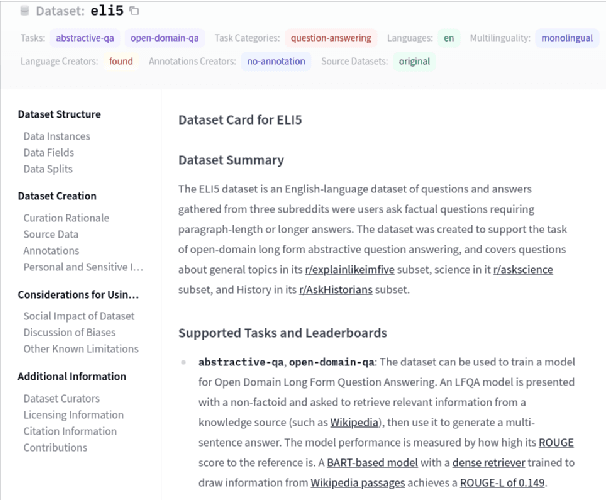
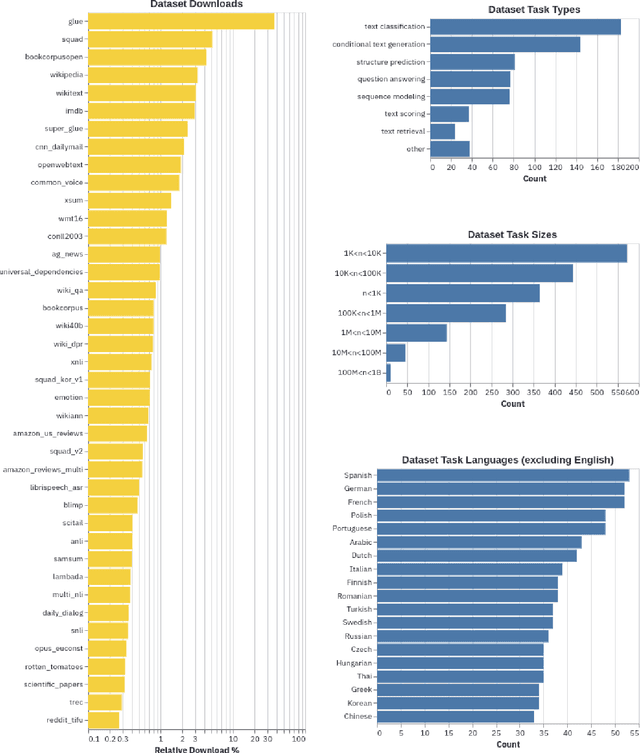
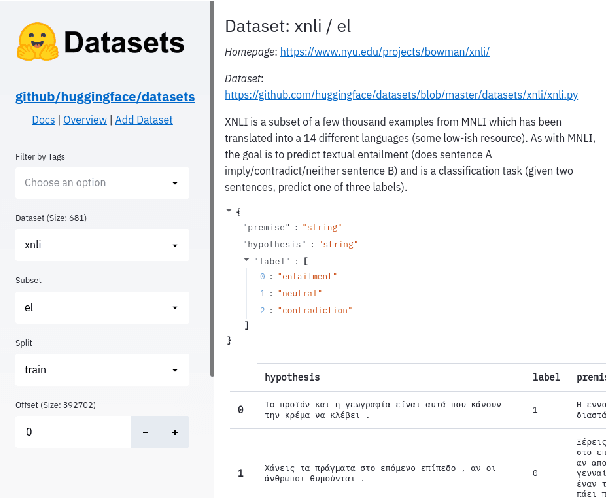
The scale, variety, and quantity of publicly-available NLP datasets has grown rapidly as researchers propose new tasks, larger models, and novel benchmarks. Datasets is a community library for contemporary NLP designed to support this ecosystem. Datasets aims to standardize end-user interfaces, versioning, and documentation, while providing a lightweight front-end that behaves similarly for small datasets as for internet-scale corpora. The design of the library incorporates a distributed, community-driven approach to adding datasets and documenting usage. After a year of development, the library now includes more than 650 unique datasets, has more than 250 contributors, and has helped support a variety of novel cross-dataset research projects and shared tasks. The library is available at https://github.com/huggingface/datasets.
Low-Complexity Probing via Finding Subnetworks
Apr 08, 2021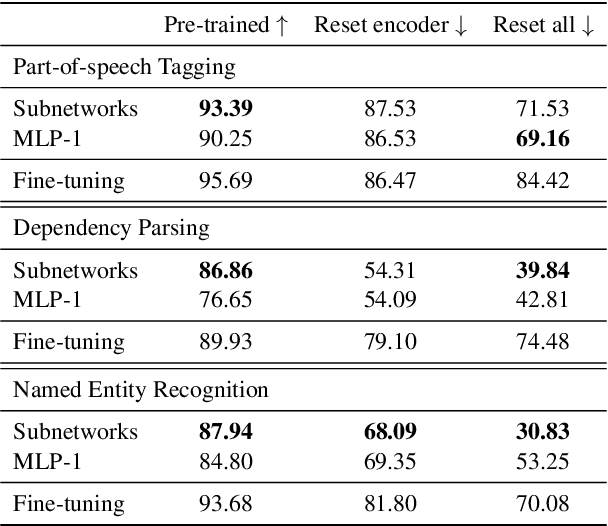
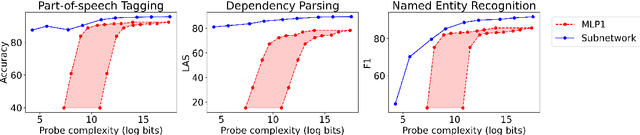
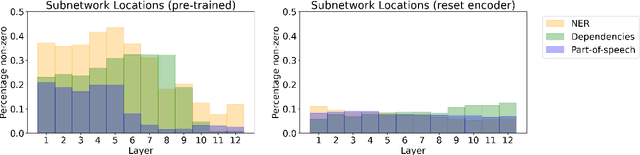
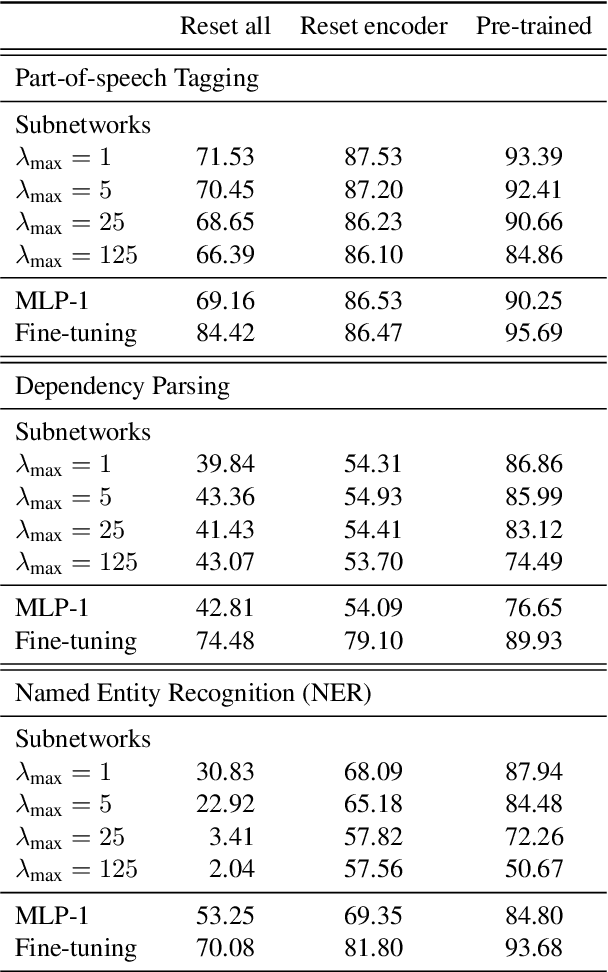
The dominant approach in probing neural networks for linguistic properties is to train a new shallow multi-layer perceptron (MLP) on top of the model's internal representations. This approach can detect properties encoded in the model, but at the cost of adding new parameters that may learn the task directly. We instead propose a subtractive pruning-based probe, where we find an existing subnetwork that performs the linguistic task of interest. Compared to an MLP, the subnetwork probe achieves both higher accuracy on pre-trained models and lower accuracy on random models, so it is both better at finding properties of interest and worse at learning on its own. Next, by varying the complexity of each probe, we show that subnetwork probing Pareto-dominates MLP probing in that it achieves higher accuracy given any budget of probe complexity. Finally, we analyze the resulting subnetworks across various tasks to locate where each task is encoded, and we find that lower-level tasks are captured in lower layers, reproducing similar findings in past work.
Learning from others' mistakes: Avoiding dataset biases without modeling them
Dec 02, 2020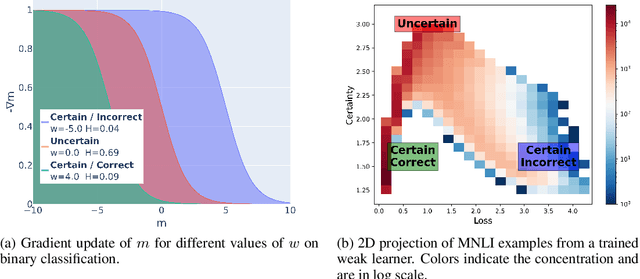

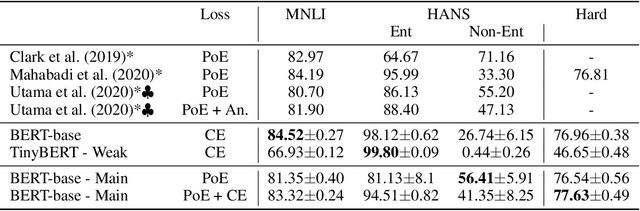
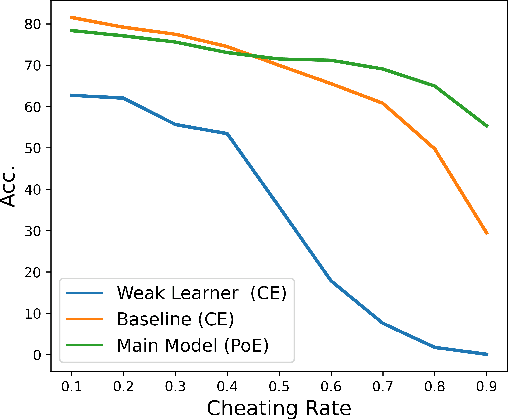
State-of-the-art natural language processing (NLP) models often learn to model dataset biases and surface form correlations instead of features that target the intended underlying task. Previous work has demonstrated effective methods to circumvent these issues when knowledge of the bias is available. We consider cases where the bias issues may not be explicitly identified, and show a method for training models that learn to ignore these problematic correlations. Our approach relies on the observation that models with limited capacity primarily learn to exploit biases in the dataset. We can leverage the errors of such limited capacity models to train a more robust model in a product of experts, thus bypassing the need to hand-craft a biased model. We show the effectiveness of this method to retain improvements in out-of-distribution settings even if no particular bias is targeted by the biased model.
EdgeBERT: Optimizing On-Chip Inference for Multi-Task NLP
Dec 01, 2020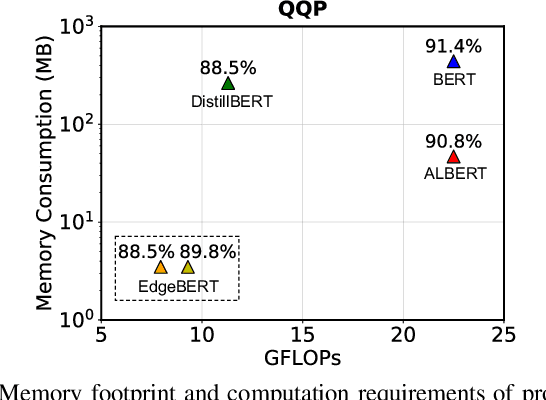
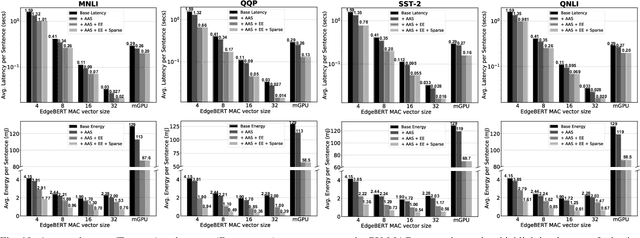
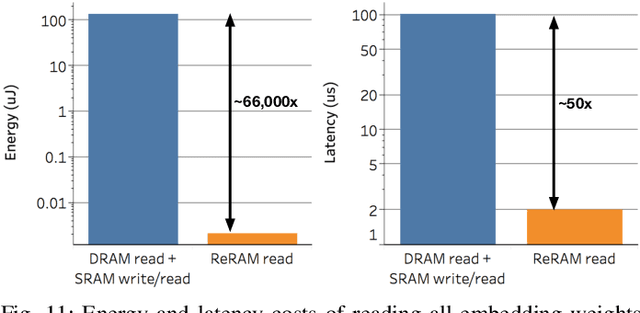
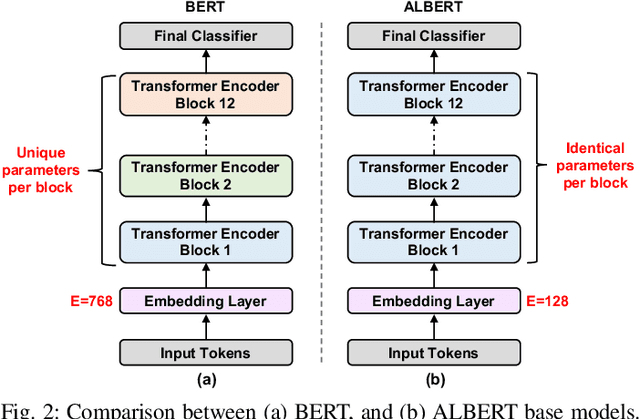
Transformer-based language models such as BERT provide significant accuracy improvement to a multitude of natural language processing (NLP) tasks. However, their hefty computational and memory demands make them challenging to deploy to resource-constrained edge platforms with strict latency requirements. We present EdgeBERT an in-depth and principled algorithm and hardware design methodology to achieve minimal latency and energy consumption on multi-task NLP inference. Compared to the ALBERT baseline, we achieve up to 2.4x and 13.4x inference latency and memory savings, respectively, with less than 1%-pt drop in accuracy on several GLUE benchmarks by employing a calibrated combination of 1) entropy-based early stopping, 2) adaptive attention span, 3) movement and magnitude pruning, and 4) floating-point quantization. Furthermore, in order to maximize the benefits of these algorithms in always-on and intermediate edge computing settings, we specialize a scalable hardware architecture wherein floating-point bit encodings of the shareable multi-task embedding parameters are stored in high-density non-volatile memory. Altogether, EdgeBERT enables fully on-chip inference acceleration of NLP workloads with 5.2x, and 157x lower energy than that of an un-optimized accelerator and CUDA adaptations on an Nvidia Jetson Tegra X2 mobile GPU, respectively.
Movement Pruning: Adaptive Sparsity by Fine-Tuning
May 15, 2020
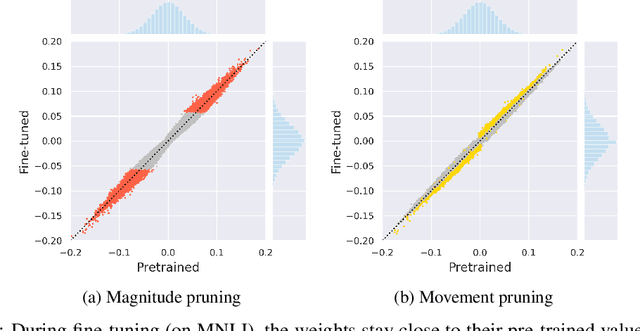
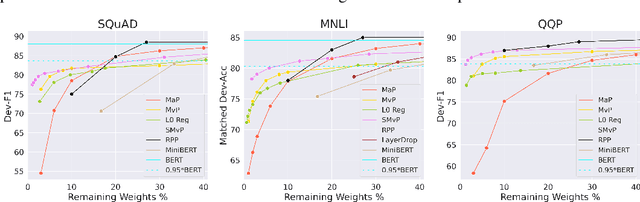
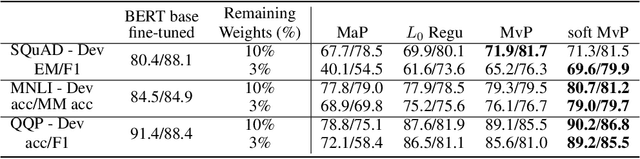
Magnitude pruning is a widely used strategy for reducing model size in pure supervised learning; however, it is less effective in the transfer learning regime that has become standard for state-of-the-art natural language processing applications. We propose the use of movement pruning, a simple, deterministic first-order weight pruning method that is more adaptive to pretrained model fine-tuning. We give mathematical foundations to the method and compare it to existing zeroth- and first-order pruning methods. Experiments show that when pruning large pretrained language models, movement pruning shows significant improvements in high-sparsity regimes. When combined with distillation, the approach achieves minimal accuracy loss with down to only 3% of the model parameters.
HuggingFace's Transformers: State-of-the-art Natural Language Processing
Oct 16, 2019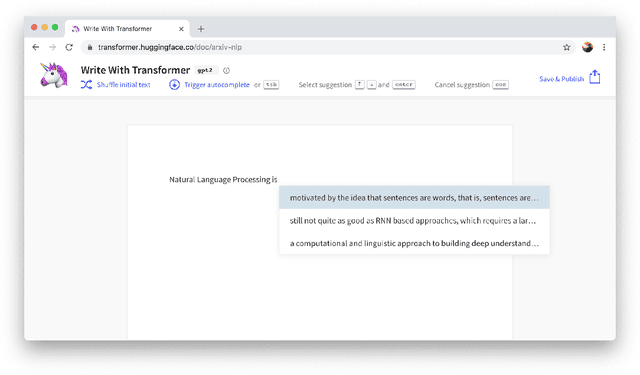
Recent advances in modern Natural Language Processing (NLP) research have been dominated by the combination of Transfer Learning methods with large-scale language models, in particular based on the Transformer architecture. With them came a paradigm shift in NLP with the starting point for training a model on a downstream task moving from a blank specific model to a general-purpose pretrained architecture. Still, creating these general-purpose models remains an expensive and time-consuming process restricting the use of these methods to a small sub-set of the wider NLP community. In this paper, we present HuggingFace's Transformers library, a library for state-of-the-art NLP, making these developments available to the community by gathering state-of-the-art general-purpose pretrained models under a unified API together with an ecosystem of libraries, examples, tutorials and scripts targeting many downstream NLP tasks. HuggingFace's Transformers library features carefully crafted model implementations and high-performance pretrained weights for two main deep learning frameworks, PyTorch and TensorFlow, while supporting all the necessary tools to analyze, evaluate and use these models in downstream tasks such as text/token classification, questions answering and language generation among others. The library has gained significant organic traction and adoption among both the researcher and practitioner communities. We are committed at HuggingFace to pursue the efforts to develop this toolkit with the ambition of creating the standard library for building NLP systems.
DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter
Oct 16, 2019
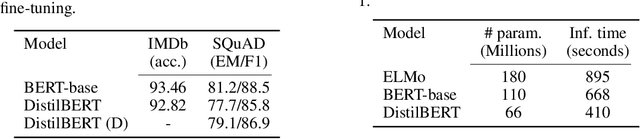

As Transfer Learning from large-scale pre-trained models becomes more prevalent in Natural Language Processing (NLP), operating these large models in on-the-edge and/or under constrained computational training or inference budgets remains challenging. In this work, we propose a method to pre-train a smaller general-purpose language representation model, called DistilBERT, which can then be fine-tuned with good performances on a wide range of tasks like its larger counterparts. While most prior work investigated the use of distillation for building task-specific models, we leverage knowledge distillation during the pre-training phase and show that it is possible to reduce the size of a BERT model by 40%, while retaining 97% of its language understanding capabilities and being 60% faster. To leverage the inductive biases learned by larger models during pre-training, we introduce a triple loss combining language modeling, distillation and cosine-distance losses. Our smaller, faster and lighter model is cheaper to pre-train and we demonstrate its capabilities for on-device computations in a proof-of-concept experiment and a comparative on-device study.
TransferTransfo: A Transfer Learning Approach for Neural Network Based Conversational Agents
Feb 04, 2019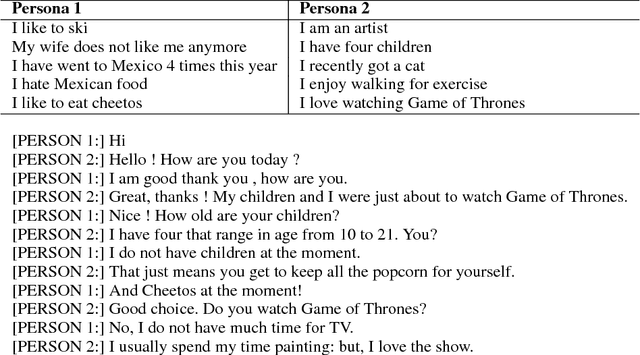

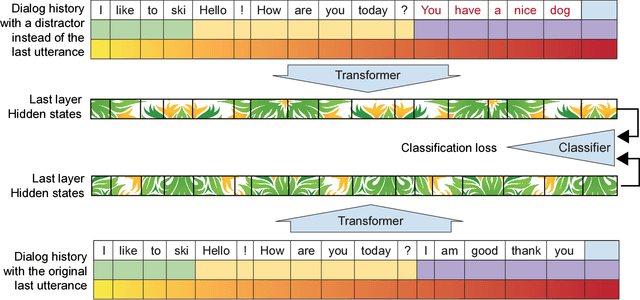
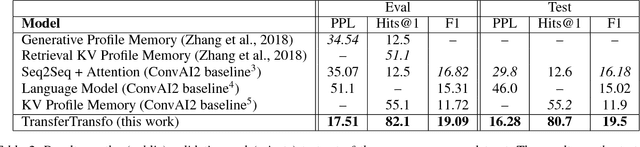
We introduce a new approach to generative data-driven dialogue systems (e.g. chatbots) called TransferTransfo which is a combination of a Transfer learning based training scheme and a high-capacity Transformer model. Fine-tuning is performed by using a multi-task objective which combines several unsupervised prediction tasks. The resulting fine-tuned model shows strong improvements over the current state-of-the-art end-to-end conversational models like memory augmented seq2seq and information-retrieval models. On the privately held PERSONA-CHAT dataset of the Conversational Intelligence Challenge 2, this approach obtains a new state-of-the-art, with respective perplexity, Hits@1 and F1 metrics of 16.28 (45 % absolute improvement), 80.7 (46 % absolute improvement) and 19.5 (20 % absolute improvement).