 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultiregion Bilinear Convolutional Neural Networks for Person Re-Identification
Sep 06, 2017
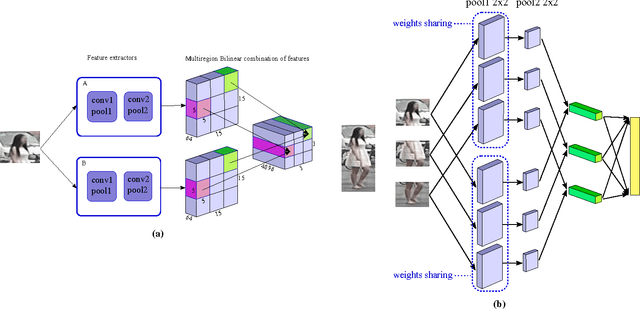
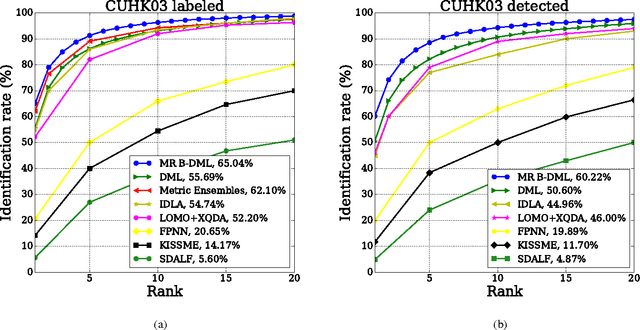
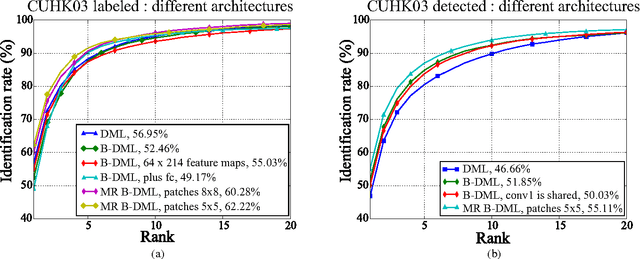
In this work we propose a new architecture for person re-identification. As the task of re-identification is inherently associated with embedding learning and non-rigid appearance description, our architecture is based on the deep bilinear convolutional network (Bilinear-CNN) that has been proposed recently for fine-grained classification of highly non-rigid objects. While the last stages of the original Bilinear-CNN architecture completely removes the geometric information from consideration by performing orderless pooling, we observe that a better embedding can be learned by performing bilinear pooling in a more local way, where each pooling is confined to a predefined region. Our architecture thus represents a compromise between traditional convolutional networks and bilinear CNNs and strikes a balance between rigid matching and completely ignoring spatial information. We perform the experimental validation of the new architecture on the three popular benchmark datasets (Market-1501, CUHK01, CUHK03), comparing it to baselines that include Bilinear-CNN as well as prior art. The new architecture outperforms the baseline on all three datasets, while performing better than state-of-the-art on two out of three. The code and the pretrained models of the approach can be found at https://github.com/madkn/MultiregionBilinearCNN-ReId.
Parsing Images of Overlapping Organisms with Deep Singling-Out Networks
Dec 19, 2016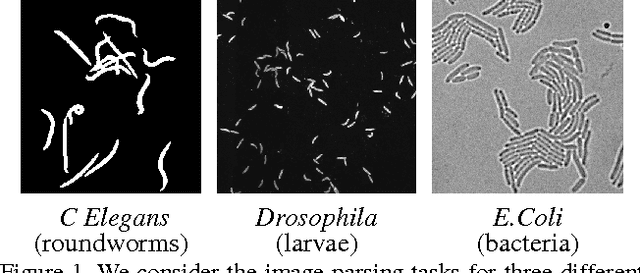
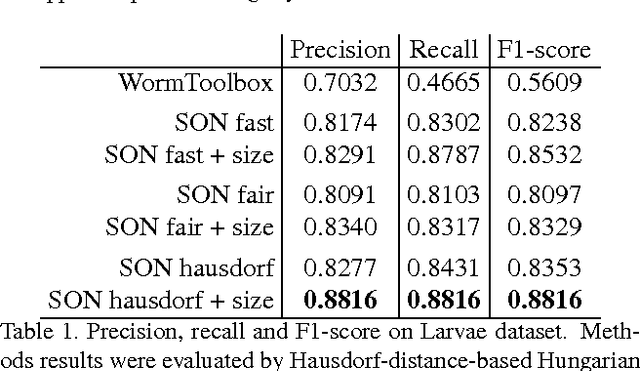


This work is motivated by the mostly unsolved task of parsing biological images with multiple overlapping articulated model organisms (such as worms or larvae). We present a general approach that separates the two main challenges associated with such data, individual object shape estimation and object groups disentangling. At the core of the approach is a deep feed-forward singling-out network (SON) that is trained to map each local patch to a vectorial descriptor that is sensitive to the characteristics (e.g. shape) of a central object, while being invariant to the variability of all other surrounding elements. Given a SON, a local image patch can be matched to a gallery of isolated elements using their SON-descriptors, thus producing a hypothesis about the shape of the central element in that patch. The image-level optimization based on integer programming can then pick a subset of the hypotheses to explain (parse) the whole image and disentangle groups of organisms. While sharing many similarities with existing "analysis-by-synthesis" approaches, our method avoids the need for stochastic search in the high-dimensional configuration space and numerous rendering operations at test-time. We show that our approach can parse microscopy images of three popular model organisms (the C.Elegans roundworms, the Drosophila larvae, and the E.Coli bacteria) even under significant crowding and overlaps between organisms. We speculate that the overall approach is applicable to a wider class of image parsing problems concerned with crowded articulated objects, for which rendering training images is possible.
End-to-end Learning of Cost-Volume Aggregation for Real-time Dense Stereo
Nov 17, 2016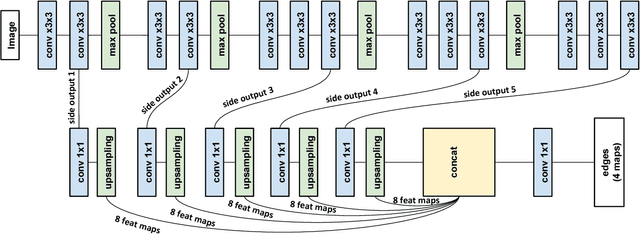

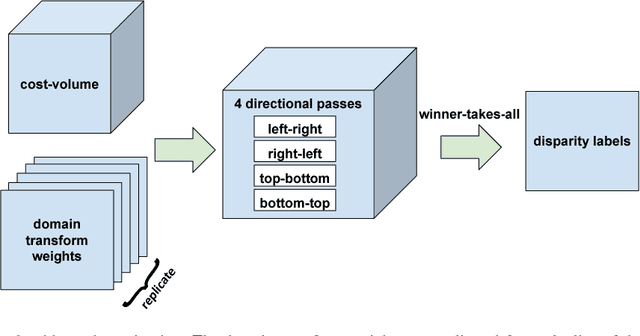

We present a new deep learning-based approach for dense stereo matching. Compared to previous works, our approach does not use deep learning of pixel appearance descriptors, employing very fast classical matching scores instead. At the same time, our approach uses a deep convolutional network to predict the local parameters of cost volume aggregation process, which in this paper we implement using differentiable domain transform. By treating such transform as a recurrent neural network, we are able to train our whole system that includes cost volume computation, cost-volume aggregation (smoothing), and winner-takes-all disparity selection end-to-end. The resulting method is highly efficient at test time, while achieving good matching accuracy. On the KITTI 2015 benchmark, it achieves a result of 6.34\% error rate while running at 29 frames per second rate on a modern GPU.
Learning Deep Embeddings with Histogram Loss
Nov 02, 2016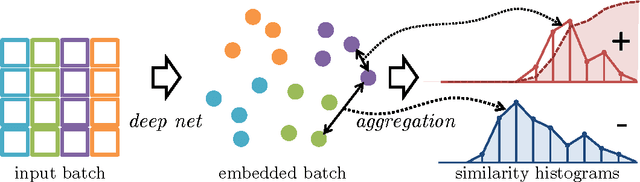
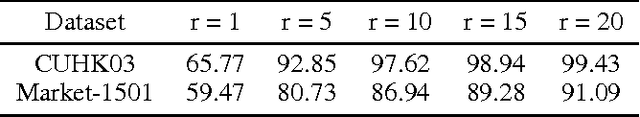
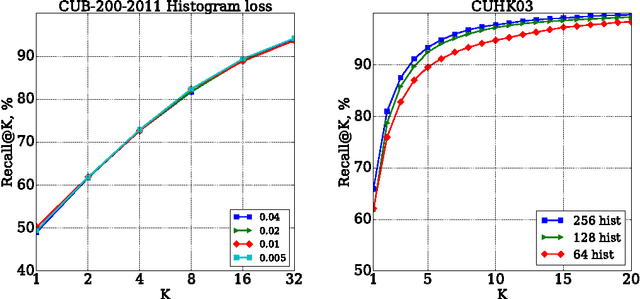
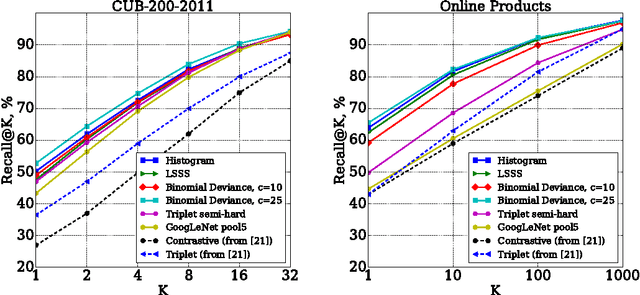
We suggest a loss for learning deep embeddings. The new loss does not introduce parameters that need to be tuned and results in very good embeddings across a range of datasets and problems. The loss is computed by estimating two distribution of similarities for positive (matching) and negative (non-matching) sample pairs, and then computing the probability of a positive pair to have a lower similarity score than a negative pair based on the estimated similarity distributions. We show that such operations can be performed in a simple and piecewise-differentiable manner using 1D histograms with soft assignment operations. This makes the proposed loss suitable for learning deep embeddings using stochastic optimization. In the experiments, the new loss performs favourably compared to recently proposed alternatives.
Learnable Visual Markers
Oct 28, 2016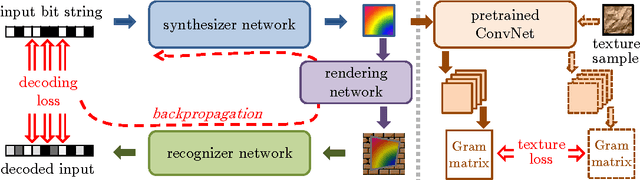

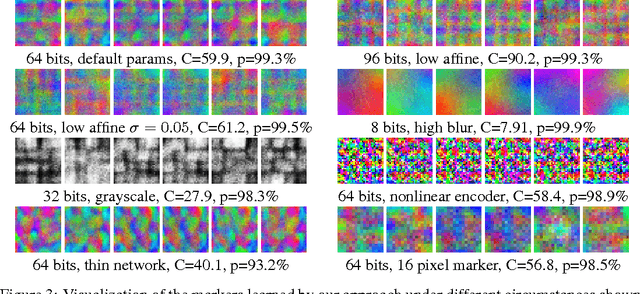
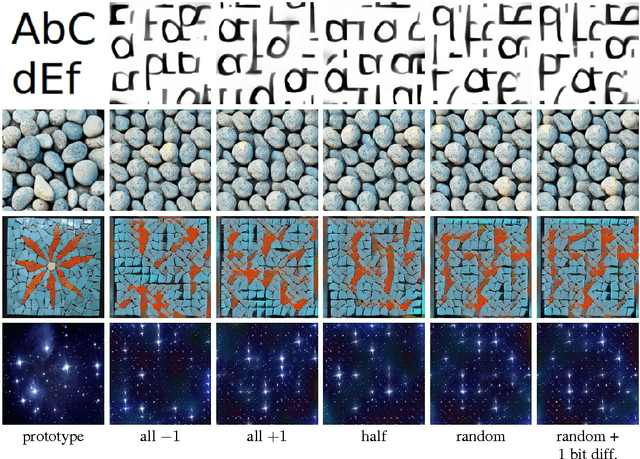
We propose a new approach to designing visual markers (analogous to QR-codes, markers for augmented reality, and robotic fiducial tags) based on the advances in deep generative networks. In our approach, the markers are obtained as color images synthesized by a deep network from input bit strings, whereas another deep network is trained to recover the bit strings back from the photos of these markers. The two networks are trained simultaneously in a joint backpropagation process that takes characteristic photometric and geometric distortions associated with marker fabrication and marker scanning into account. Additionally, a stylization loss based on statistics of activations in a pretrained classification network can be inserted into the learning in order to shift the marker appearance towards some texture prototype. In the experiments, we demonstrate that the markers obtained using our approach are capable of retaining bit strings that are long enough to be practical. The ability to automatically adapt markers according to the usage scenario and the desired capacity as well as the ability to combine information encoding with artistic stylization are the unique properties of our approach. As a byproduct, our approach provides an insight on the structure of patterns that are most suitable for recognition by ConvNets and on their ability to distinguish composite patterns.
DeepWarp: Photorealistic Image Resynthesis for Gaze Manipulation
Jul 26, 2016
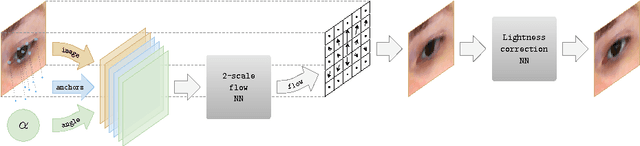
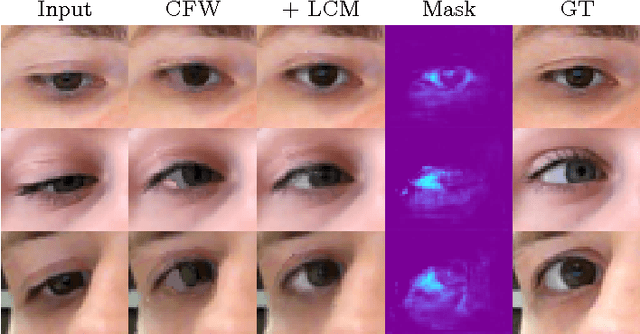
In this work, we consider the task of generating highly-realistic images of a given face with a redirected gaze. We treat this problem as a specific instance of conditional image generation and suggest a new deep architecture that can handle this task very well as revealed by numerical comparison with prior art and a user study. Our deep architecture performs coarse-to-fine warping with an additional intensity correction of individual pixels. All these operations are performed in a feed-forward manner, and the parameters associated with different operations are learned jointly in the end-to-end fashion. After learning, the resulting neural network can synthesize images with manipulated gaze, while the redirection angle can be selected arbitrarily from a certain range and provided as an input to the network.
Pairwise Quantization
Jun 05, 2016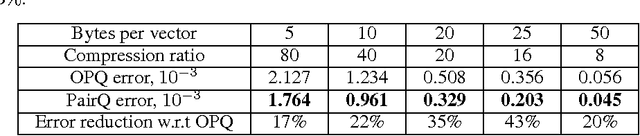
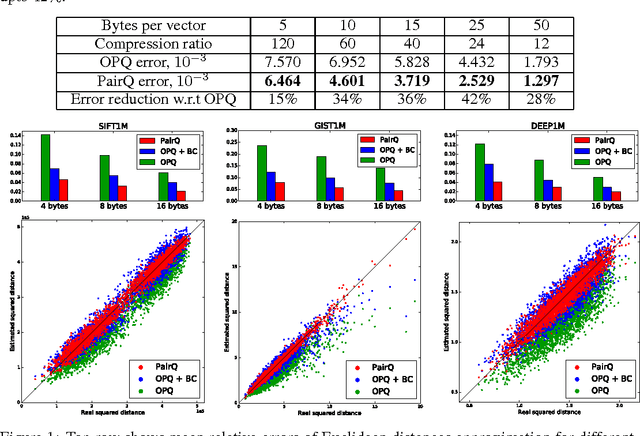
We consider the task of lossy compression of high-dimensional vectors through quantization. We propose the approach that learns quantization parameters by minimizing the distortion of scalar products and squared distances between pairs of points. This is in contrast to previous works that obtain these parameters through the minimization of the reconstruction error of individual points. The proposed approach proceeds by finding a linear transformation of the data that effectively reduces the minimization of the pairwise distortions to the minimization of individual reconstruction errors. After such transformation, any of the previously-proposed quantization approaches can be used. Despite the simplicity of this transformation, the experiments demonstrate that it achieves considerable reduction of the pairwise distortions compared to applying quantization directly to the untransformed data.
Domain-Adversarial Training of Neural Networks
May 26, 2016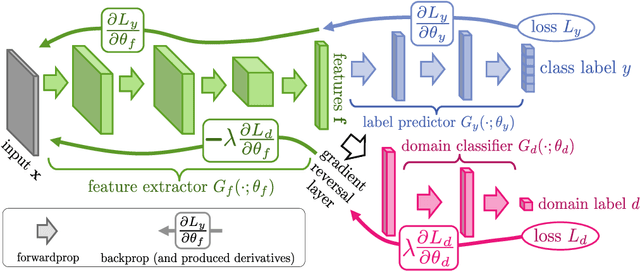
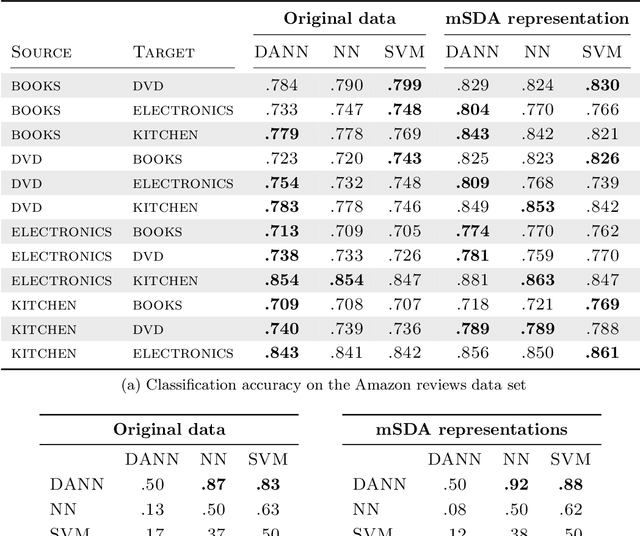
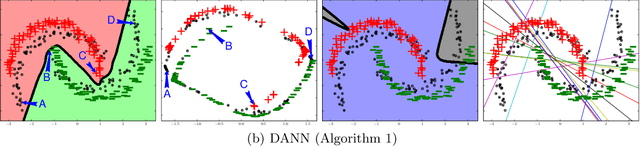
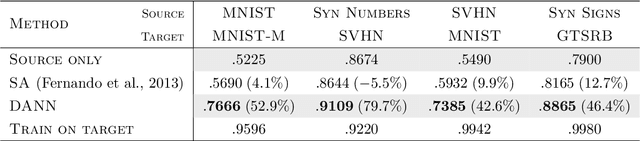
We introduce a new representation learning approach for domain adaptation, in which data at training and test time come from similar but different distributions. Our approach is directly inspired by the theory on domain adaptation suggesting that, for effective domain transfer to be achieved, predictions must be made based on features that cannot discriminate between the training (source) and test (target) domains. The approach implements this idea in the context of neural network architectures that are trained on labeled data from the source domain and unlabeled data from the target domain (no labeled target-domain data is necessary). As the training progresses, the approach promotes the emergence of features that are (i) discriminative for the main learning task on the source domain and (ii) indiscriminate with respect to the shift between the domains. We show that this adaptation behaviour can be achieved in almost any feed-forward model by augmenting it with few standard layers and a new gradient reversal layer. The resulting augmented architecture can be trained using standard backpropagation and stochastic gradient descent, and can thus be implemented with little effort using any of the deep learning packages. We demonstrate the success of our approach for two distinct classification problems (document sentiment analysis and image classification), where state-of-the-art domain adaptation performance on standard benchmarks is achieved. We also validate the approach for descriptor learning task in the context of person re-identification application.
* Published in JMLR: http://jmlr.org/papers/v17/15-239.html
Texture Networks: Feed-forward Synthesis of Textures and Stylized Images
Mar 10, 2016
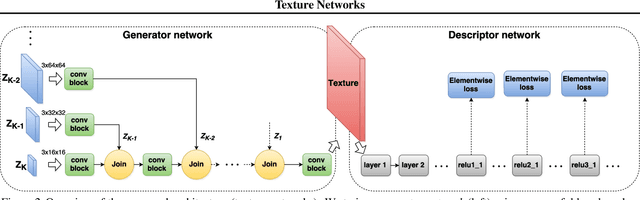


Gatys et al. recently demonstrated that deep networks can generate beautiful textures and stylized images from a single texture example. However, their methods requires a slow and memory-consuming optimization process. We propose here an alternative approach that moves the computational burden to a learning stage. Given a single example of a texture, our approach trains compact feed-forward convolutional networks to generate multiple samples of the same texture of arbitrary size and to transfer artistic style from a given image to any other image. The resulting networks are remarkably light-weight and can generate textures of quality comparable to Gatys~et~al., but hundreds of times faster. More generally, our approach highlights the power and flexibility of generative feed-forward models trained with complex and expressive loss functions.
Fast ConvNets Using Group-wise Brain Damage
Dec 07, 2015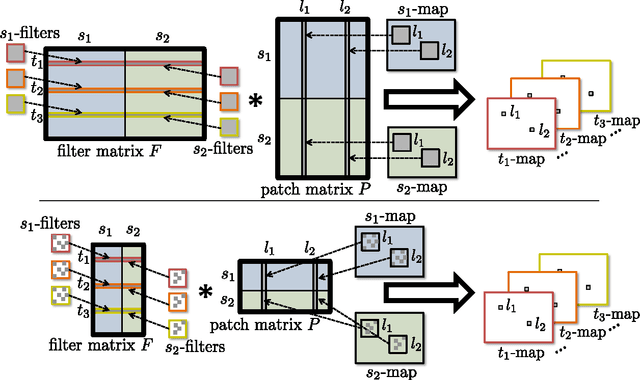
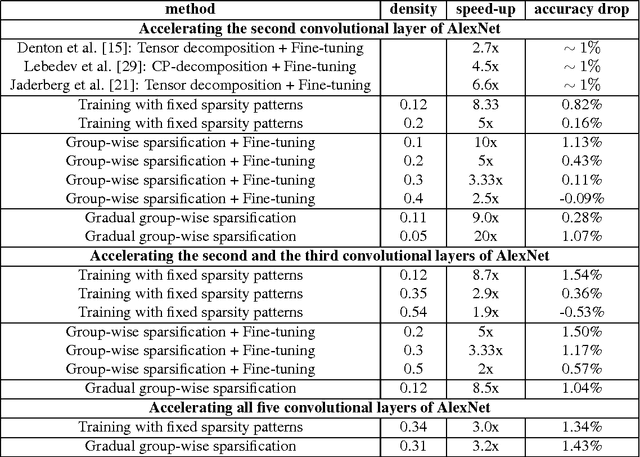
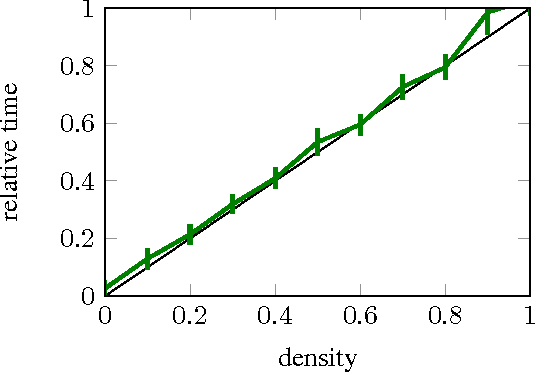
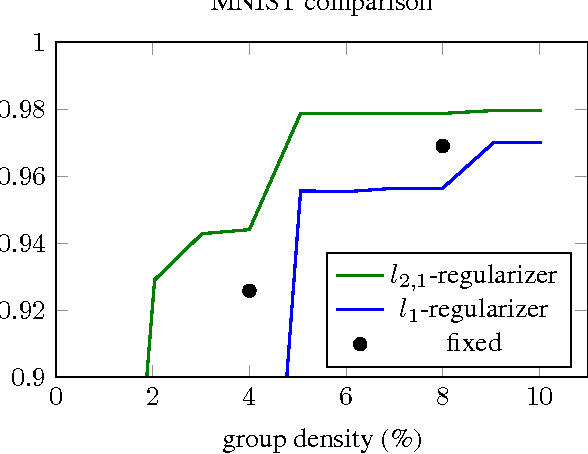
We revisit the idea of brain damage, i.e. the pruning of the coefficients of a neural network, and suggest how brain damage can be modified and used to speedup convolutional layers. The approach uses the fact that many efficient implementations reduce generalized convolutions to matrix multiplications. The suggested brain damage process prunes the convolutional kernel tensor in a group-wise fashion by adding group-sparsity regularization to the standard training process. After such group-wise pruning, convolutions can be reduced to multiplications of thinned dense matrices, which leads to speedup. In the comparison on AlexNet, the method achieves very competitive performance.