 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExplaining Autonomous Vehicles with Intention-aware Policy Graphs
May 13, 2025



The potential to improve road safety, reduce human driving error, and promote environmental sustainability have enabled the field of autonomous driving to progress rapidly over recent decades. The performance of autonomous vehicles has significantly improved thanks to advancements in Artificial Intelligence, particularly Deep Learning. Nevertheless, the opacity of their decision-making, rooted in the use of accurate yet complex AI models, has created barriers to their societal trust and regulatory acceptance, raising the need for explainability. We propose a post-hoc, model-agnostic solution to provide teleological explanations for the behaviour of an autonomous vehicle in urban environments. Building on Intention-aware Policy Graphs, our approach enables the extraction of interpretable and reliable explanations of vehicle behaviour in the nuScenes dataset from global and local perspectives. We demonstrate the potential of these explanations to assess whether the vehicle operates within acceptable legal boundaries and to identify possible vulnerabilities in autonomous driving datasets and models.
Intention-aware policy graphs: answering what, how, and why in opaque agents
Sep 27, 2024



Agents are a special kind of AI-based software in that they interact in complex environments and have increased potential for emergent behaviour. Explaining such emergent behaviour is key to deploying trustworthy AI, but the increasing complexity and opaque nature of many agent implementations makes this hard. In this work, we propose a Probabilistic Graphical Model along with a pipeline for designing such model -- by which the behaviour of an agent can be deliberated about -- and for computing a robust numerical value for the intentions the agent has at any moment. We contribute measurements that evaluate the interpretability and reliability of explanations provided, and enables explainability questions such as `what do you want to do now?' (e.g. deliver soup) `how do you plan to do it?' (e.g. returning a plan that considers its skills and the world), and `why would you take this action at this state?' (e.g. explaining how that furthers or hinders its own goals). This model can be constructed by taking partial observations of the agent's actions and world states, and we provide an iterative workflow for increasing the proposed measurements through better design and/or pointing out irrational agent behaviour.
Padding Aware Neurons
Sep 14, 2023



Convolutional layers are a fundamental component of most image-related models. These layers often implement by default a static padding policy (\eg zero padding), to control the scale of the internal representations, and to allow kernel activations centered on the border regions. In this work we identify Padding Aware Neurons (PANs), a type of filter that is found in most (if not all) convolutional models trained with static padding. PANs focus on the characterization and recognition of input border location, introducing a spatial inductive bias into the model (e.g., how close to the input's border a pattern typically is). We propose a method to identify PANs through their activations, and explore their presence in several popular pre-trained models, finding PANs on all models explored, from dozens to hundreds. We discuss and illustrate different types of PANs, their kernels and behaviour. To understand their relevance, we test their impact on model performance, and find padding and PANs to induce strong and characteristic biases in the data. Finally, we discuss whether or not PANs are desirable, as well as the potential side effects of their presence in the context of model performance, generalisation, efficiency and safety.
When & How to Transfer with Transfer Learning
Nov 08, 2022



In deep learning, transfer learning (TL) has become the de facto approach when dealing with image related tasks. Visual features learnt for one task have been shown to be reusable for other tasks, improving performance significantly. By reusing deep representations, TL enables the use of deep models in domains with limited data availability, limited computational resources and/or limited access to human experts. Domains which include the vast majority of real-life applications. This paper conducts an experimental evaluation of TL, exploring its trade-offs with respect to performance, environmental footprint, human hours and computational requirements. Results highlight the cases were a cheap feature extraction approach is preferable, and the situations where an expensive fine-tuning effort may be worth the added cost. Finally, a set of guidelines on the use of TL are proposed.
Feature discriminativity estimation in CNNs for transfer learning
Nov 08, 2019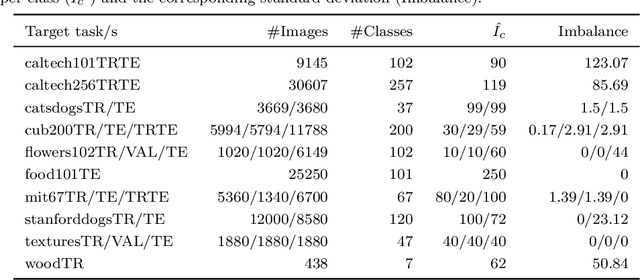
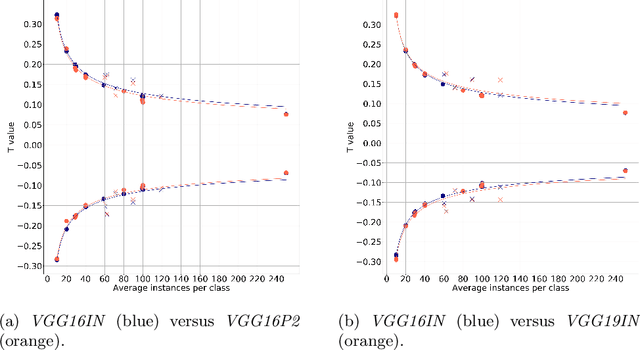
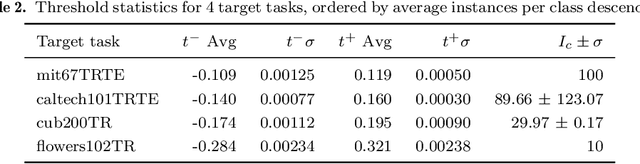
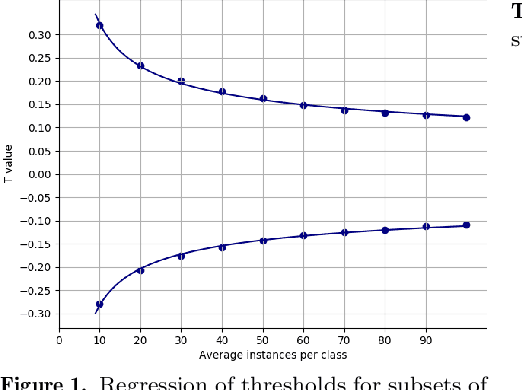
The purpose of feature extraction on convolutional neural networks is to reuse deep representations learnt for a pre-trained model to solve a new, potentially unrelated problem. However, raw feature extraction from all layers is unfeasible given the massive size of these networks. Recently, a supervised method using complexity reduction was proposed, resulting in significant improvements in performance for transfer learning tasks. This approach first computes the discriminative power of features, and then discretises them using thresholds computed for the task. In this paper, we analyse the behaviour of these thresholds, with the purpose of finding a methodology for their estimation. After a comprehensive study, we find a very strong correlation between problem size and threshold value, with coefficient of determination above 90%. These results allow us to propose a unified model for threshold estimation, with potential application to transfer learning tasks.
* Presented in the 22nd International Conference of the Catalan Association for Artificial Intelligence (CCIA 19)