 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiagnosing Error in Temporal Action Detectors
Jul 27, 2018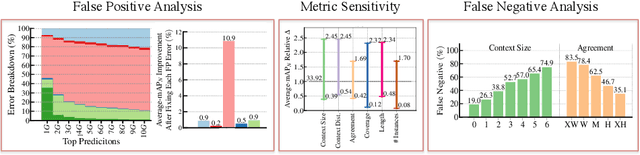


Despite the recent progress in video understanding and the continuous rate of improvement in temporal action localization throughout the years, it is still unclear how far (or close?) we are to solving the problem. To this end, we introduce a new diagnostic tool to analyze the performance of temporal action detectors in videos and compare different methods beyond a single scalar metric. We exemplify the use of our tool by analyzing the performance of the top rewarded entries in the latest ActivityNet action localization challenge. Our analysis shows that the most impactful areas to work on are: strategies to better handle temporal context around the instances, improving the robustness w.r.t. the instance absolute and relative size, and strategies to reduce the localization errors. Moreover, our experimental analysis finds the lack of agreement among annotator is not a major roadblock to attain progress in the field. Our diagnostic tool is publicly available to keep fueling the minds of other researchers with additional insights about their algorithms.
Guess Where? Actor-Supervision for Spatiotemporal Action Localization
Apr 05, 2018
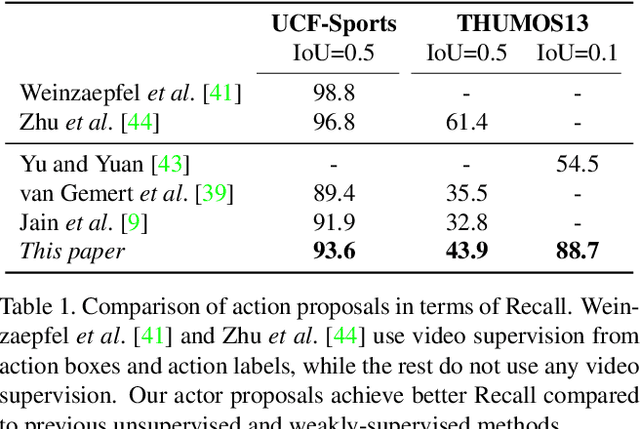
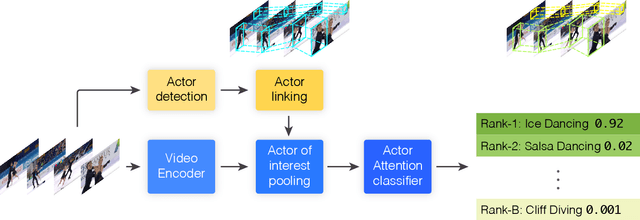

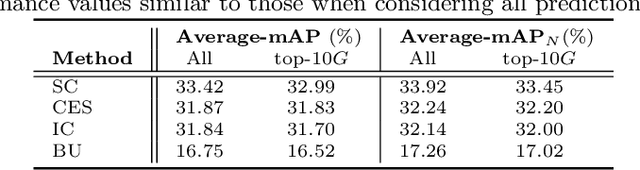
This paper addresses the problem of spatiotemporal localization of actions in videos. Compared to leading approaches, which all learn to localize based on carefully annotated boxes on training video frames, we adhere to a weakly-supervised solution that only requires a video class label. We introduce an actor-supervised architecture that exploits the inherent compositionality of actions in terms of actor transformations, to localize actions. We make two contributions. First, we propose actor proposals derived from a detector for human and non-human actors intended for images, which is linked over time by Siamese similarity matching to account for actor deformations. Second, we propose an actor-based attention mechanism that enables the localization of the actions from action class labels and actor proposals and is end-to-end trainable. Experiments on three human and non-human action datasets show actor supervision is state-of-the-art for weakly-supervised action localization and is even competitive to some fully-supervised alternatives.
ActivityNet Challenge 2017 Summary
Oct 22, 2017

The ActivityNet Large Scale Activity Recognition Challenge 2017 Summary: results and challenge participants papers.