 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIrregularly Sampled Time Series Interpolation for Binary Evolution Simulations Using Dynamic Time Warping
Apr 15, 2026Binary stellar evolution simulations are computationally expensive. Stellar population synthesis relies on these detailed evolution models at a fundamental level. Producing thousands of such models requires hundreds of CPU hours, but stellar track interpolation provides one approach to significantly reduce this computational cost. Although single-star track interpolation is straightforward, stellar interactions in binary systems introduce significant complexity to binary evolution, making traditional single-track interpolation methods inapplicable. Binary tracks present fundamentally different challenges compared to single stars, which possess relatively straightforward evolutionary phases identifiable through distinct physical properties. Binary systems are complicated by mutual interactions that can dramatically alter evolutionary trajectories and introduce discontinuities difficult to capture through standard interpolation. In this work, we introduce a novel approach for track alignment and iterative track averaging based on Dynamic Time Warping to address misalignments between neighboring tracks. Our method computes a single shared warping path across all physical parameters simultaneously, placing them on a consistent temporal grid that preserves the causal relationships between parameters. We demonstrate that this joint-alignment strategy maintains key physical relationships such as the Stefan-Boltzmann law in the interpolated tracks. Our comprehensive evaluation across multiple binary configurations demonstrates that proper temporal alignment is crucial for track interpolation methods. The proposed method consistently outperforms existing approaches and enables the efficient generation of more accurate binary population samples for astrophysical studies.
Learning the Stellar Structure Equations via Self-supervised Physics-Informed Neural Networks
Apr 06, 2026Stellar astrophysics relies critically on accurate descriptions of the physical conditions inside stars. Traditional solvers such as \texttt{MESA} (Modules for Experiments in Stellar Astrophysics), which employ adaptive finite-difference methods, can become computationally expensive and challenging to scale for large stellar population synthesis ($>10^9$ stars). In this work, we present an self-supervised physics-informed neural network (PINN) framework that provides a mesh-free and fully differentiable approach to solving the stellar structure equations under hydrostatic and thermal equilibrium. The model takes as input the stellar boundary conditions (at the center and surface) together with the chemical composition, and learns continuous radial profiles for mass $M_r(r)$, pressure $P(r)$, density $ρ(r)$, temperature $T(r)$, and luminosity $L_r(r)$ by enforcing the governing structure equations through physics-based loss terms. To incorporate realistic microphysics, we introduce auxiliary neural networks that approximate the equation of state and opacity tables as smooth, differentiable functions of the local thermodynamic state. These surrogates replace traditional tabulated inputs and enable end-to-end training. Once trained for a given star, the model produces continuous solutions across the entire radial domain without requiring discretization or interpolation. Validation against benchmark \texttt{MESA} models across a range of stellar masses yields a Mean Relative Absolute Error of $3.06\%$ and an average $R^2$ score of $99.98\%$. To our knowledge, this is the first demonstration that the stellar structure equations can be solved in a fully self-supervised and data-free fashion employing PINNs. This work establishes a foundation for scalable, physics-informed emulation of stellar interiors and opens the door to future extensions toward time-dependent stellar evolution.
Emulators for stellar profiles in binary population modeling
Oct 14, 2024



Knowledge about the internal physical structure of stars is crucial to understanding their evolution. The novel binary population synthesis code POSYDON includes a module for interpolating the stellar and binary properties of any system at the end of binary MESA evolution based on a pre-computed set of models. In this work, we present a new emulation method for predicting stellar profiles, i.e., the internal stellar structure along the radial axis, using machine learning techniques. We use principal component analysis for dimensionality reduction and fully-connected feed-forward neural networks for making predictions. We find accuracy to be comparable to that of nearest neighbor approximation, with a strong advantage in terms of memory and storage efficiency. By delivering more information about the evolution of stellar internal structure, these emulators will enable faster simulations of higher physical fidelity with large-scale simulations of binary star population synthesis possible with POSYDON and other population synthesis codes.
Advancing Glitch Classification in Gravity Spy: Multi-view Fusion with Attention-based Machine Learning for Advanced LIGO's Fourth Observing Run
Jan 23, 2024The first successful detection of gravitational waves by ground-based observatories, such as the Laser Interferometer Gravitational-Wave Observatory (LIGO), marked a revolutionary breakthrough in our comprehension of the Universe. However, due to the unprecedented sensitivity required to make such observations, gravitational-wave detectors also capture disruptive noise sources called glitches, potentially masking or appearing as gravitational-wave signals themselves. To address this problem, a community-science project, Gravity Spy, incorporates human insight and machine learning to classify glitches in LIGO data. The machine learning classifier, integrated into the project since 2017, has evolved over time to accommodate increasing numbers of glitch classes. Despite its success, limitations have arisen in the ongoing LIGO fourth observing run (O4) due to its architecture's simplicity, which led to poor generalization and inability to handle multi-time window inputs effectively. We propose an advanced classifier for O4 glitches. Our contributions include evaluating fusion strategies for multi-time window inputs, using label smoothing to counter noisy labels, and enhancing interpretability through attention module-generated weights. This development seeks to enhance glitch classification, aiding in the ongoing exploration of gravitational-wave phenomena.
Active Learning for Computationally Efficient Distribution of Binary Evolution Simulations
Mar 30, 2022

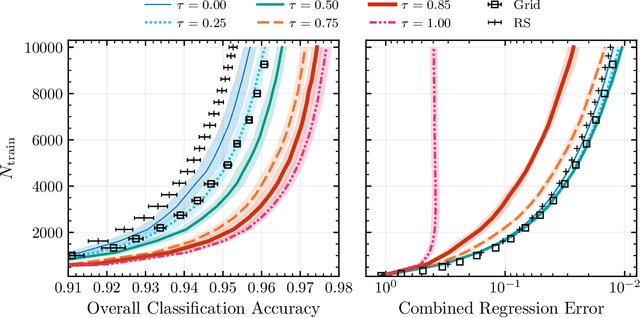

Binary stars undergo a variety of interactions and evolutionary phases, critical for predicting and explaining observed properties. Binary population synthesis with full stellar-structure and evolution simulations are computationally expensive requiring a large number of mass-transfer sequences. The recently developed binary population synthesis code POSYDON incorporates grids of MESA binary star simulations which are then interpolated to model large-scale populations of massive binaries. The traditional method of computing a high-density rectilinear grid of simulations is not scalable for higher-dimension grids, accounting for a range of metallicities, rotation, and eccentricity. We present a new active learning algorithm, psy-cris, which uses machine learning in the data-gathering process to adaptively and iteratively select targeted simulations to run, resulting in a custom, high-performance training set. We test psy-cris on a toy problem and find the resulting training sets require fewer simulations for accurate classification and regression than either regular or randomly sampled grids. We further apply psy-cris to the target problem of building a dynamic grid of MESA simulations, and we demonstrate that, even without fine tuning, a simulation set of only $\sim 1/4$ the size of a rectilinear grid is sufficient to achieve the same classification accuracy. We anticipate further gains when algorithmic parameters are optimized for the targeted application. We find that optimizing for classification only may lead to performance losses in regression, and vice versa. Lowering the computational cost of producing grids will enable future versions of POSYDON to cover more input parameters while preserving interpolation accuracies.
Deep Multi-view Models for Glitch Classification
Apr 28, 2017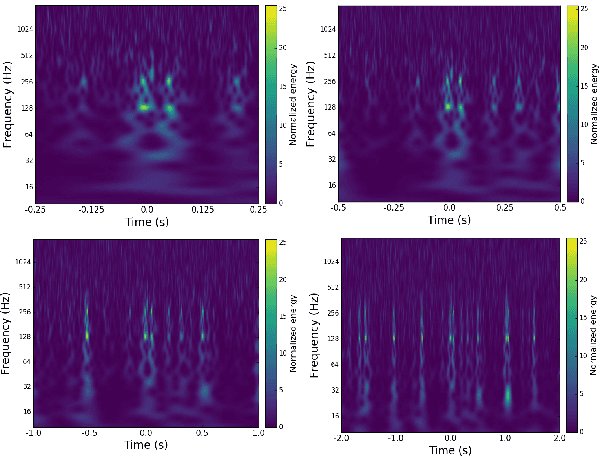

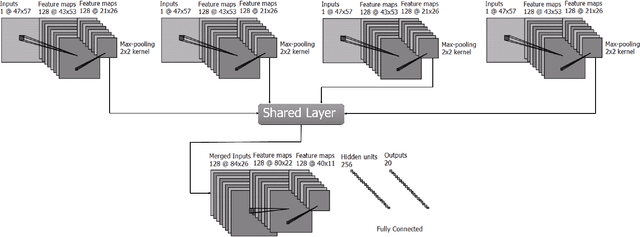
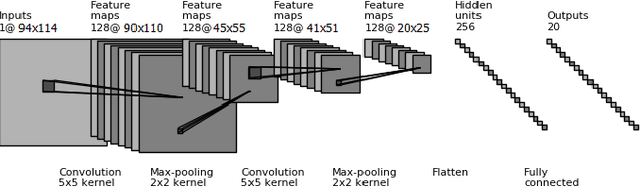
Non-cosmic, non-Gaussian disturbances known as "glitches", show up in gravitational-wave data of the Advanced Laser Interferometer Gravitational-wave Observatory, or aLIGO. In this paper, we propose a deep multi-view convolutional neural network to classify glitches automatically. The primary purpose of classifying glitches is to understand their characteristics and origin, which facilitates their removal from the data or from the detector entirely. We visualize glitches as spectrograms and leverage the state-of-the-art image classification techniques in our model. The suggested classifier is a multi-view deep neural network that exploits four different views for classification. The experimental results demonstrate that the proposed model improves the overall accuracy of the classification compared to traditional single view algorithms.