 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIncentivizing Compliance with Algorithmic Instruments
Jul 28, 2021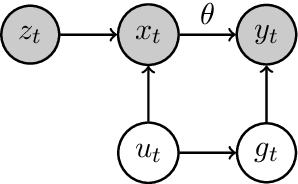
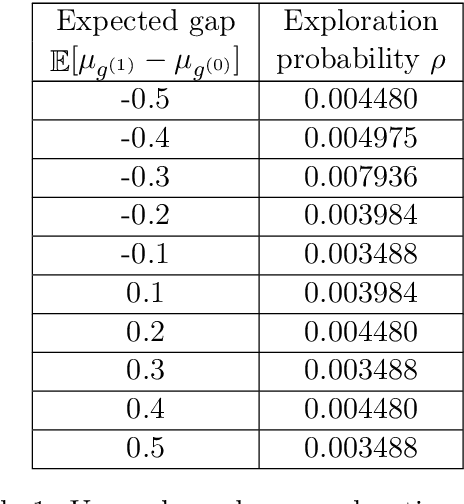
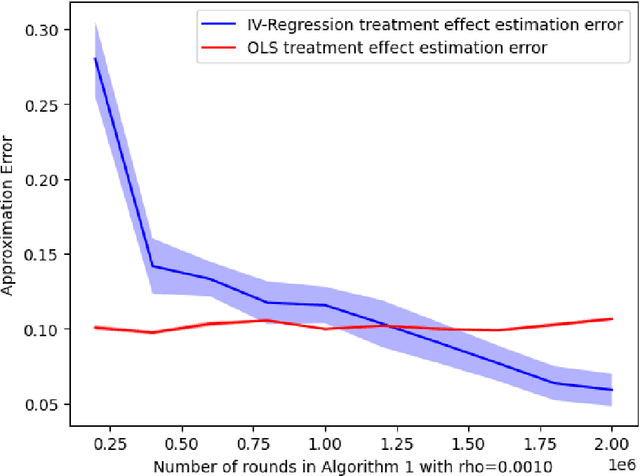
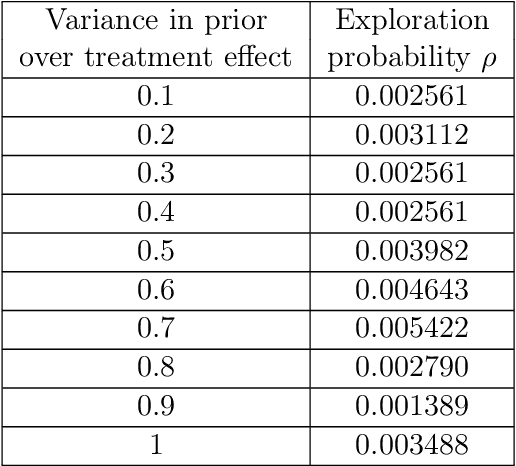
Randomized experiments can be susceptible to selection bias due to potential non-compliance by the participants. While much of the existing work has studied compliance as a static behavior, we propose a game-theoretic model to study compliance as dynamic behavior that may change over time. In rounds, a social planner interacts with a sequence of heterogeneous agents who arrive with their unobserved private type that determines both their prior preferences across the actions (e.g., control and treatment) and their baseline rewards without taking any treatment. The planner provides each agent with a randomized recommendation that may alter their beliefs and their action selection. We develop a novel recommendation mechanism that views the planner's recommendation as a form of instrumental variable (IV) that only affects an agents' action selection, but not the observed rewards. We construct such IVs by carefully mapping the history -- the interactions between the planner and the previous agents -- to a random recommendation. Even though the initial agents may be completely non-compliant, our mechanism can incentivize compliance over time, thereby enabling the estimation of the treatment effect of each treatment, and minimizing the cumulative regret of the planner whose goal is to identify the optimal treatment.
Knowledge Distillation as Semiparametric Inference
Apr 20, 2021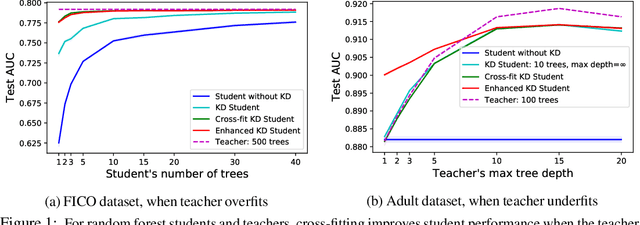

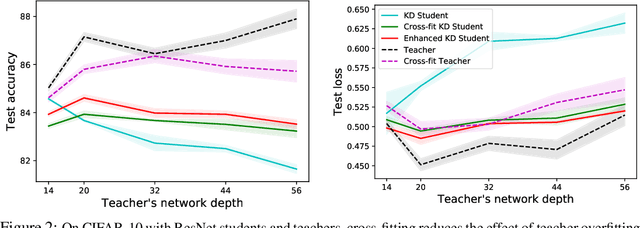
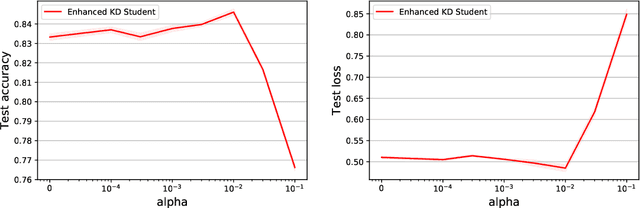
A popular approach to model compression is to train an inexpensive student model to mimic the class probabilities of a highly accurate but cumbersome teacher model. Surprisingly, this two-step knowledge distillation process often leads to higher accuracy than training the student directly on labeled data. To explain and enhance this phenomenon, we cast knowledge distillation as a semiparametric inference problem with the optimal student model as the target, the unknown Bayes class probabilities as nuisance, and the teacher probabilities as a plug-in nuisance estimate. By adapting modern semiparametric tools, we derive new guarantees for the prediction error of standard distillation and develop two enhancements -- cross-fitting and loss correction -- to mitigate the impact of teacher overfitting and underfitting on student performance. We validate our findings empirically on both tabular and image data and observe consistent improvements from our knowledge distillation enhancements.
Estimating the Long-Term Effects of Novel Treatments
Mar 15, 2021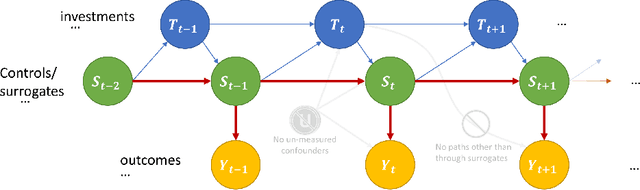
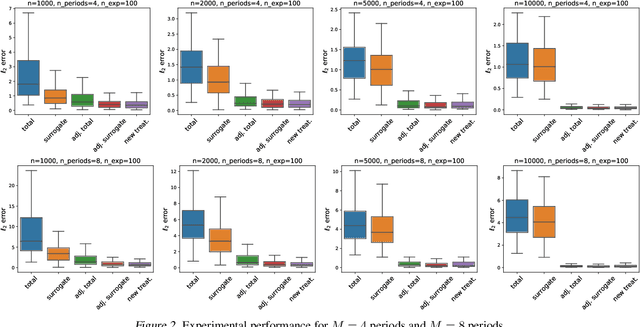


Policy makers typically face the problem of wanting to estimate the long-term effects of novel treatments, while only having historical data of older treatment options. We assume access to a long-term dataset where only past treatments were administered and a short-term dataset where novel treatments have been administered. We propose a surrogate based approach where we assume that the long-term effect is channeled through a multitude of available short-term proxies. Our work combines three major recent techniques in the causal machine learning literature: surrogate indices, dynamic treatment effect estimation and double machine learning, in a unified pipeline. We show that our method is consistent and provides root-n asymptotically normal estimates under a Markovian assumption on the data and the observational policy. We use a data-set from a major corporation that includes customer investments over a three year period to create a semi-synthetic data distribution where the major qualitative properties of the real dataset are preserved. We evaluate the performance of our method and discuss practical challenges of deploying our formal methodology and how to address them.
Evidence-Based Policy Learning
Mar 12, 2021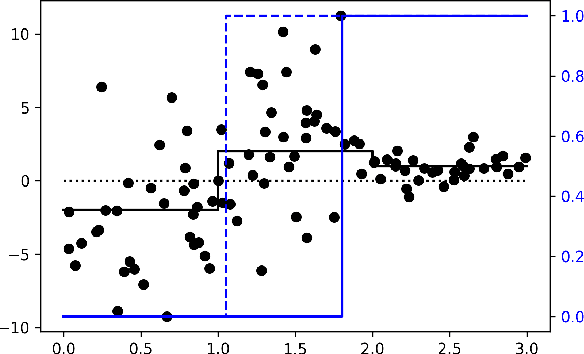
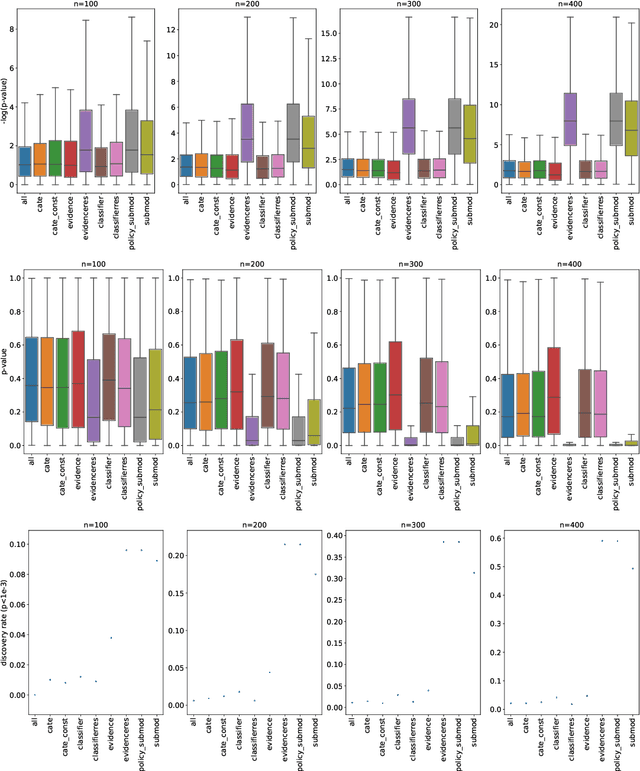
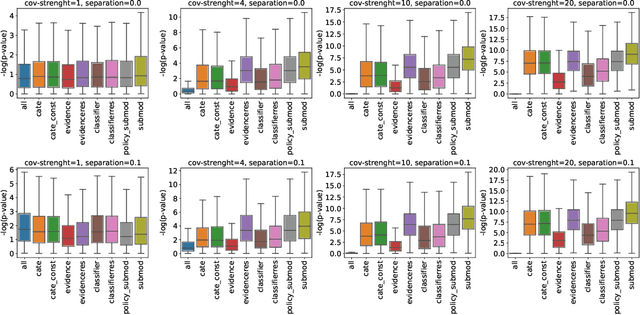
The past years have seen seen the development and deployment of machine-learning algorithms to estimate personalized treatment-assignment policies from randomized controlled trials. Yet such algorithms for the assignment of treatment typically optimize expected outcomes without taking into account that treatment assignments are frequently subject to hypothesis testing. In this article, we explicitly take significance testing of the effect of treatment-assignment policies into account, and consider assignments that optimize the probability of finding a subset of individuals with a statistically significant positive treatment effect. We provide an efficient implementation using decision trees, and demonstrate its gain over selecting subsets based on positive (estimated) treatment effects. Compared to standard tree-based regression and classification tools, this approach tends to yield substantially higher power in detecting subgroups with positive treatment effects.
Adversarial Estimation of Riesz Representers
Dec 30, 2020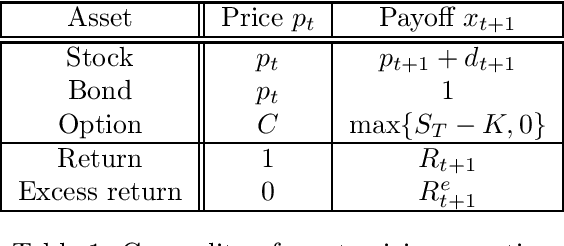
We provide an adversarial approach to estimating Riesz representers of linear functionals within arbitrary function spaces. We prove oracle inequalities based on the localized Rademacher complexity of the function space used to approximate the Riesz representer and the approximation error. These inequalities imply fast finite sample mean-squared-error rates for many function spaces of interest, such as high-dimensional sparse linear functions, neural networks and reproducing kernel Hilbert spaces. Our approach offers a new way of estimating Riesz representers with a plethora of recently introduced machine learning techniques. We show how our estimator can be used in the context of de-biasing structural/causal parameters in semi-parametric models, for automated orthogonalization of moment equations and for estimating the stochastic discount factor in the context of asset pricing.
Asymptotics of the Empirical Bootstrap Method Beyond Asymptotic Normality
Nov 23, 2020One of the most commonly used methods for forming confidence intervals for statistical inference is the empirical bootstrap, which is especially expedient when the limiting distribution of the estimator is unknown. However, despite its ubiquitous role, its theoretical properties are still not well understood for non-asymptotically normal estimators. In this paper, under stability conditions, we establish the limiting distribution of the empirical bootstrap estimator, derive tight conditions for it to be asymptotically consistent, and quantify the speed of convergence. Moreover, we propose three alternative ways to use the bootstrap method to build confidence intervals with coverage guarantees. Finally, we illustrate the generality and tightness of our results by a series of examples, including uniform confidence bands, two-sample kernel tests, minmax stochastic programs and the empirical risk of stacked estimators.
Bid Prediction in Repeated Auctions with Learning
Jul 26, 2020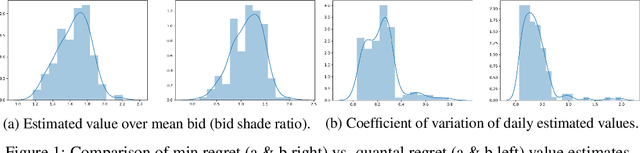
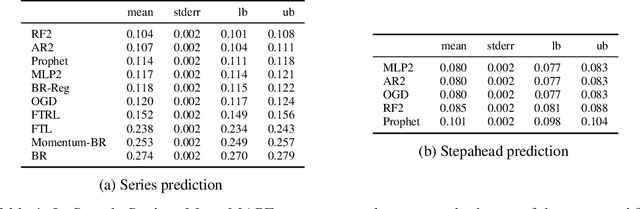
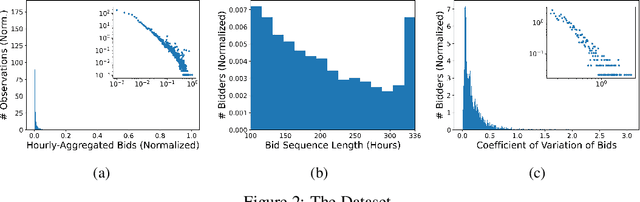
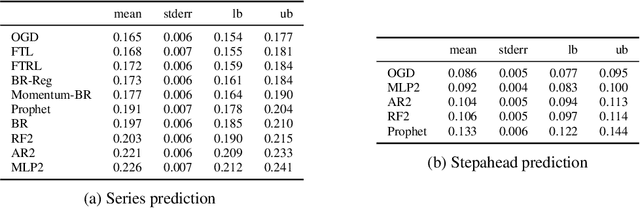
We consider the problem of bid prediction in repeated auctions and evaluate the performance of econometric methods for learning agents using a dataset from a mainstream sponsored search auction marketplace. Sponsored search auctions is a billion dollar industry and the main source of revenue of several tech giants. A critical problem in optimizing such marketplaces is understanding how bidders will react to changes in the auction design. We propose the use of no-regret based econometrics for bid prediction, modelling players as no-regret learners with respect to a utility function, unknown to the analyst. We apply these methods in a real-world dataset from the BingAds sponsored search auction marketplace and show that no-regret econometric methods perform comparable to state-of-the-art time-series machine learning methods when there is no co-variate shift, but significantly out-perform machine learning methods when there is a co-variate shift between the training and test periods. This portrays the importance of using structural econometric approaches in predicting how players will respond to changes in the market. Moreover, we show that among structural econometric methods, approaches based on no-regret learning out-perform more traditional, equilibrium-based, econometric methods that assume that players continuously best-respond to competition.
Minimax Estimation of Conditional Moment Models
Jun 12, 2020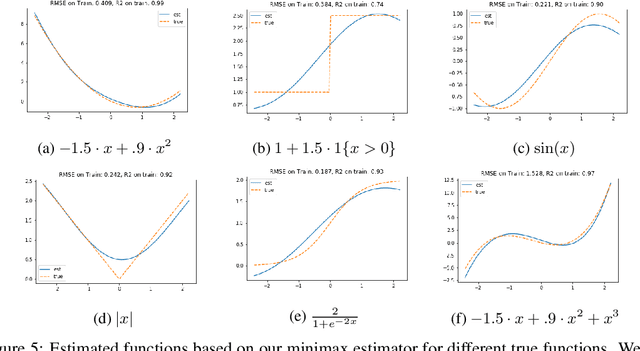
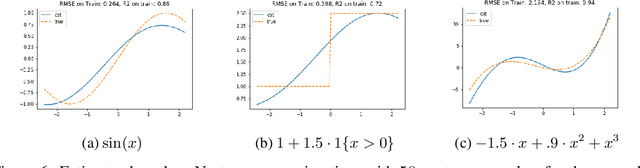
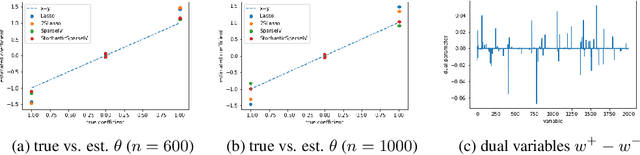
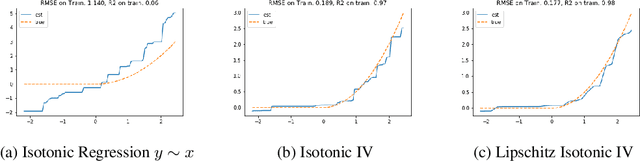
We develop an approach for estimating models described via conditional moment restrictions, with a prototypical application being non-parametric instrumental variable regression. We introduce a min-max criterion function, under which the estimation problem can be thought of as solving a zero-sum game between a modeler who is optimizing over the hypothesis space of the target model and an adversary who identifies violating moments over a test function space. We analyze the statistical estimation rate of the resulting estimator for arbitrary hypothesis spaces, with respect to an appropriate analogue of the mean squared error metric, for ill-posed inverse problems. We show that when the minimax criterion is regularized with a second moment penalty on the test function and the test function space is sufficiently rich, then the estimation rate scales with the critical radius of the hypothesis and test function spaces, a quantity which typically gives tight fast rates. Our main result follows from a novel localized Rademacher analysis of statistical learning problems defined via minimax objectives. We provide applications of our main results for several hypothesis spaces used in practice such as: reproducing kernel Hilbert spaces, high dimensional sparse linear functions, spaces defined via shape constraints, ensemble estimators such as random forests, and neural networks. For each of these applications we provide computationally efficient optimization methods for solving the corresponding minimax problem (e.g. stochastic first-order heuristics for neural networks). In several applications, we show how our modified mean squared error rate, combined with conditions that bound the ill-posedness of the inverse problem, lead to mean squared error rates. We conclude with an extensive experimental analysis of the proposed methods.
Double/Debiased Machine Learning for Dynamic Treatment Effects
Feb 17, 2020
We consider the estimation of treatment effects in settings when multiple treatments are assigned over time and treatments can have a causal effect on future outcomes. We formulate the problem as a linear state space Markov process with a high dimensional state and propose an extension of the double/debiased machine learning framework to estimate the dynamic effects of treatments. Our method allows the use of arbitrary machine learning methods to control for the high dimensional state, subject to a mean square error guarantee, while still allowing parametric estimation and construction of confidence intervals for the dynamic treatment effect parameters of interest. Our method is based on a sequential regression peeling process, which we show can be equivalently interpreted as a Neyman orthogonal moment estimator. This allows us to show root-n asymptotic normality of the estimated causal effects.
Machine Learning Estimation of Heterogeneous Treatment Effects with Instruments
Jun 06, 2019
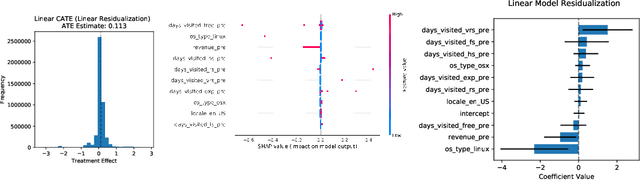
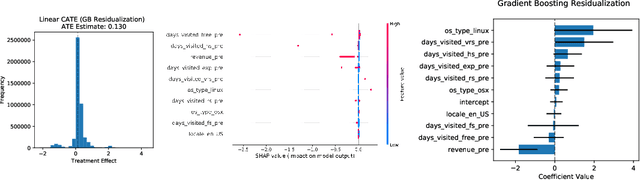
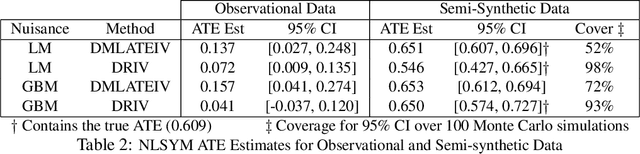
We consider the estimation of heterogeneous treatment effects with arbitrary machine learning methods in the presence of unobserved confounders with the aid of a valid instrument. Such settings arise in A/B tests with an intent-to-treat structure, where the experimenter randomizes over which user will receive a recommendation to take an action, and we are interested in the effect of the downstream action. We develop a statistical learning approach to the estimation of heterogeneous effects, reducing the problem to the minimization of an appropriate loss function that depends on a set of auxiliary models (each corresponding to a separate prediction task). The reduction enables the use of all recent algorithmic advances (e.g. neural nets, forests). We show that the estimated effect model is robust to estimation errors in the auxiliary models, by showing that the loss satisfies a Neyman orthogonality criterion. Our approach can be used to estimate projections of the true effect model on simpler hypothesis spaces. When these spaces are parametric, then the parameter estimates are asymptotically normal, which enables construction of confidence sets. We applied our method to estimate the effect of membership on downstream webpage engagement on TripAdvisor, using as an instrument an intent-to-treat A/B test among 4 million TripAdvisor users, where some users received an easier membership sign-up process. We also validate our method on synthetic data and on public datasets for the effects of schooling on income.