 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGaslight, Gatekeep, V1-V3: Early Visual Cortex Alignment Shields Vision-Language Models from Sycophantic Manipulation
Apr 15, 2026Vision-language models are increasingly deployed in high-stakes settings, yet their susceptibility to sycophantic manipulation remains poorly understood, particularly in relation to how these models represent visual information internally. Whether models whose visual representations more closely mirror human neural processing are also more resistant to adversarial pressure is an open question with implications for both neuroscience and AI safety. We investigate this question by evaluating 12 open-weight vision-language models spanning 6 architecture families and a 40$\times$ parameter range (256M--10B) along two axes: brain alignment, measured by predicting fMRI responses from the Natural Scenes Dataset across 8 human subjects and 6 visual cortex regions of interest, and sycophancy, measured through 76,800 two-turn gaslighting prompts spanning 5 categories and 10 difficulty levels. Region-of-interest analysis reveals that alignment specifically in early visual cortex (V1--V3) is a reliable negative predictor of sycophancy ($r = -0.441$, BCa 95\% CI $[-0.740, -0.031]$), with all 12 leave-one-out correlations negative and the strongest effect for existence denial attacks ($r = -0.597$, $p = 0.040$). This anatomically specific relationship is absent in higher-order category-selective regions, suggesting that faithful low-level visual encoding provides a measurable anchor against adversarial linguistic override in vision-language models. We release our code on \href{https://github.com/aryashah2k/Gaslight-Gatekeep-Sycophantic-Manipulation}{GitHub} and dataset on \href{https://huggingface.co/datasets/aryashah00/Gaslight-Gatekeep-V1-V3}{Hugging Face}
Are Word Embedding-based Features Useful for Sarcasm Detection?
Oct 04, 2016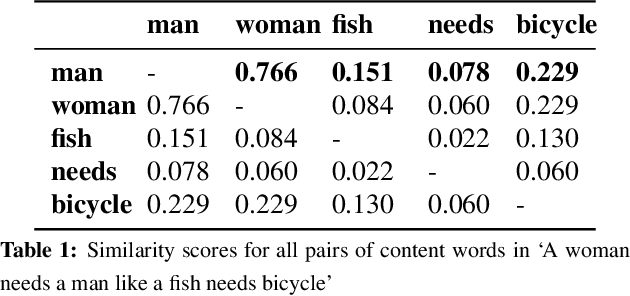
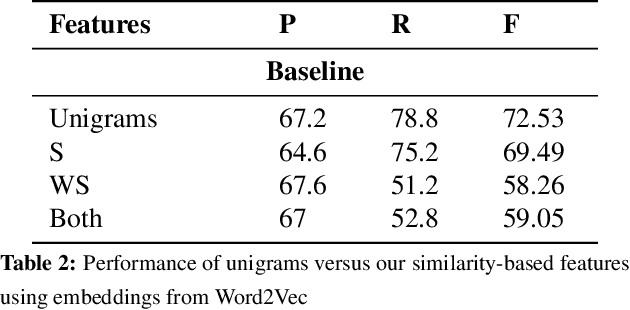
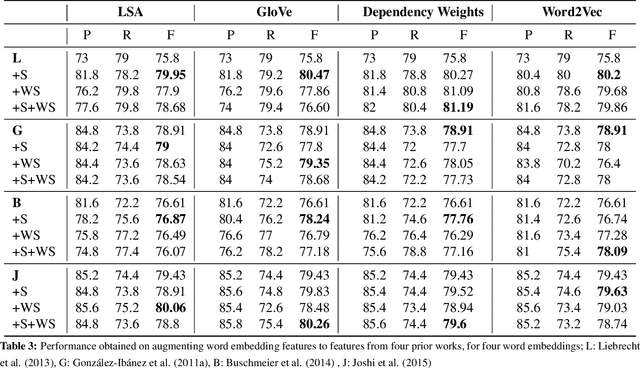
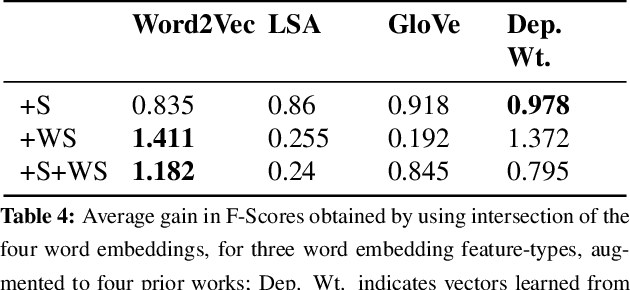
This paper makes a simple increment to state-of-the-art in sarcasm detection research. Existing approaches are unable to capture subtle forms of context incongruity which lies at the heart of sarcasm. We explore if prior work can be enhanced using semantic similarity/discordance between word embeddings. We augment word embedding-based features to four feature sets reported in the past. We also experiment with four types of word embeddings. We observe an improvement in sarcasm detection, irrespective of the word embedding used or the original feature set to which our features are augmented. For example, this augmentation results in an improvement in F-score of around 4\% for three out of these four feature sets, and a minor degradation in case of the fourth, when Word2Vec embeddings are used. Finally, a comparison of the four embeddings shows that Word2Vec and dependency weight-based features outperform LSA and GloVe, in terms of their benefit to sarcasm detection.