 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdversarial Poisoning Attacks and Defense for General Multi-Class Models Based On Synthetic Reduced Nearest Neighbors
Feb 11, 2021
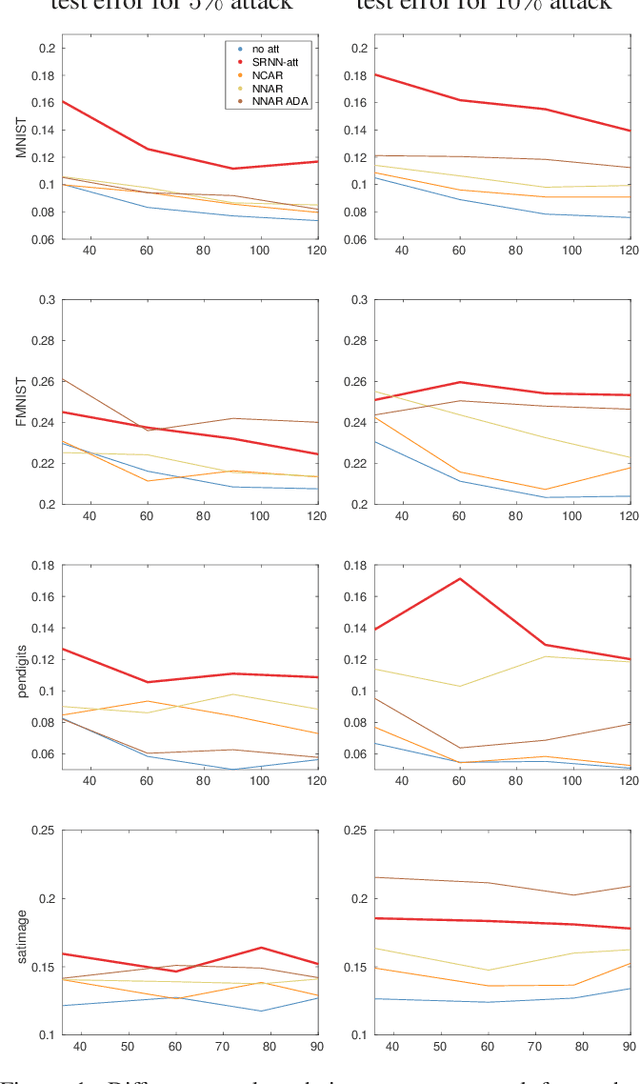
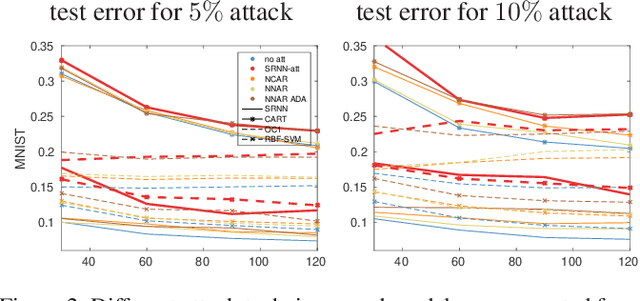
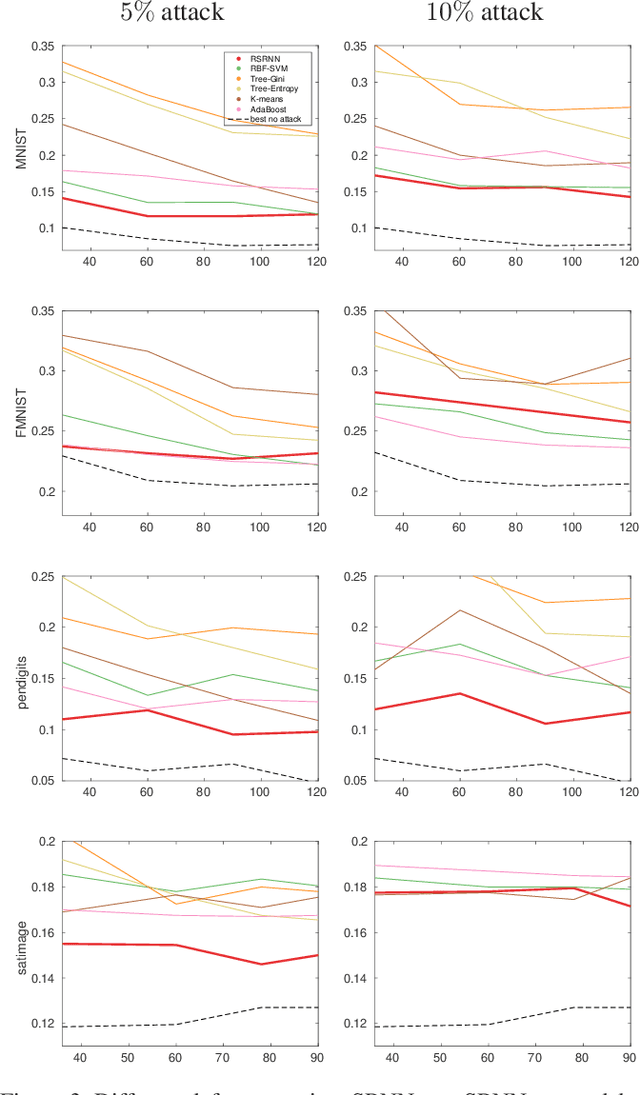
State-of-the-art machine learning models are vulnerable to data poisoning attacks whose purpose is to undermine the integrity of the model. However, the current literature on data poisoning attacks is mainly focused on ad hoc techniques that are only applicable to specific machine learning models. Additionally, the existing data poisoning attacks in the literature are limited to either binary classifiers or to gradient-based algorithms. To address these limitations, this paper first proposes a novel model-free label-flipping attack based on the multi-modality of the data, in which the adversary targets the clusters of classes while constrained by a label-flipping budget. The complexity of our proposed attack algorithm is linear in time over the size of the dataset. Also, the proposed attack can increase the error up to two times for the same attack budget. Second, a novel defense technique based on the Synthetic Reduced Nearest Neighbor (SRNN) model is proposed. The defense technique can detect and exclude flipped samples on the fly during the training procedure. Through extensive experimental analysis, we demonstrate that (i) the proposed attack technique can deteriorate the accuracy of several models drastically, and (ii) under the proposed attack, the proposed defense technique significantly outperforms other conventional machine learning models in recovering the accuracy of the targeted model.
Adversarial Attacks on Deep Algorithmic Trading Policies
Oct 22, 2020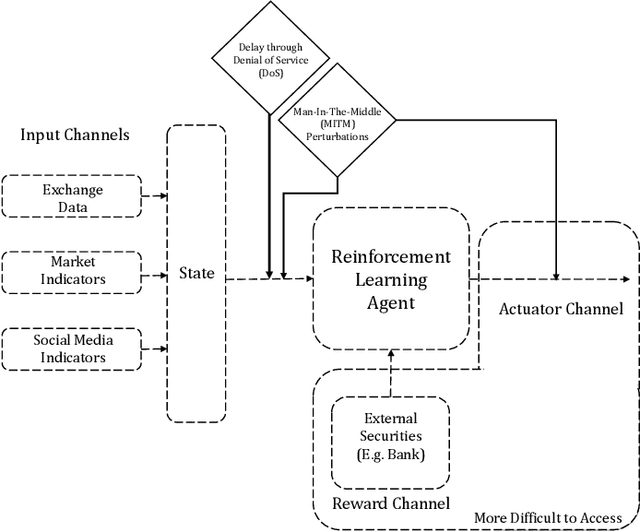

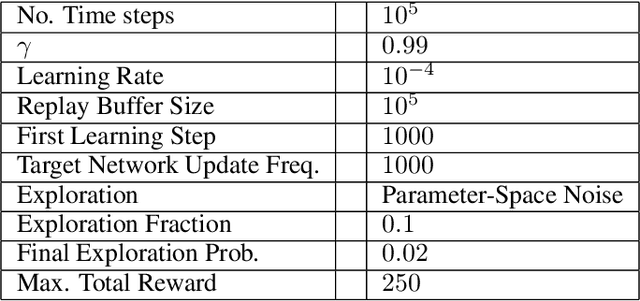
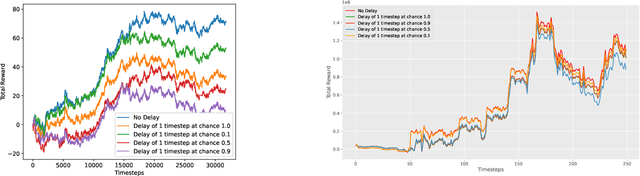
Deep Reinforcement Learning (DRL) has become an appealing solution to algorithmic trading such as high frequency trading of stocks and cyptocurrencies. However, DRL have been shown to be susceptible to adversarial attacks. It follows that algorithmic trading DRL agents may also be compromised by such adversarial techniques, leading to policy manipulation. In this paper, we develop a threat model for deep trading policies, and propose two attack techniques for manipulating the performance of such policies at test-time. Furthermore, we demonstrate the effectiveness of the proposed attacks against benchmark and real-world DQN trading agents.
Sentimental LIAR: Extended Corpus and Deep Learning Models for Fake Claim Classification
Sep 01, 2020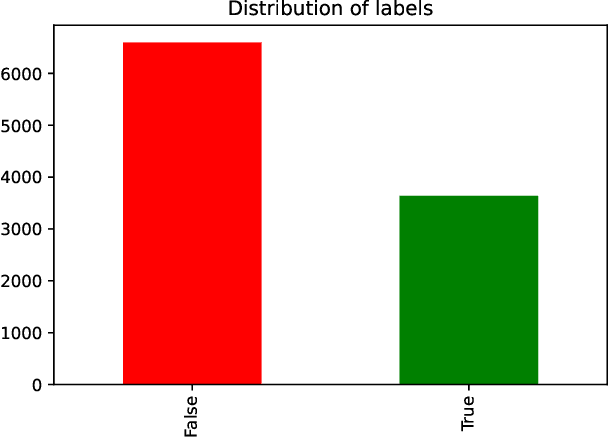
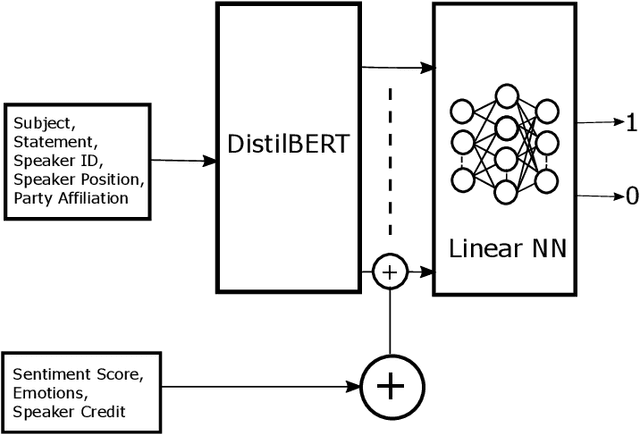
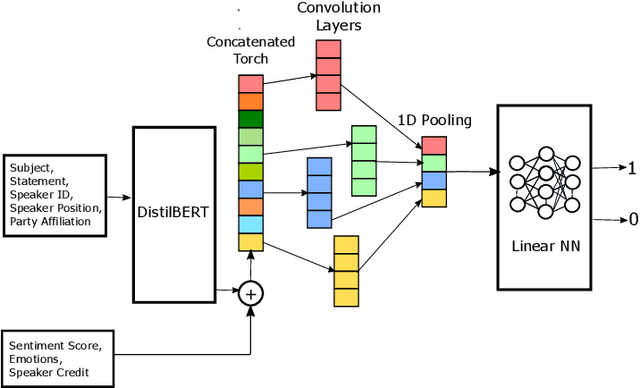
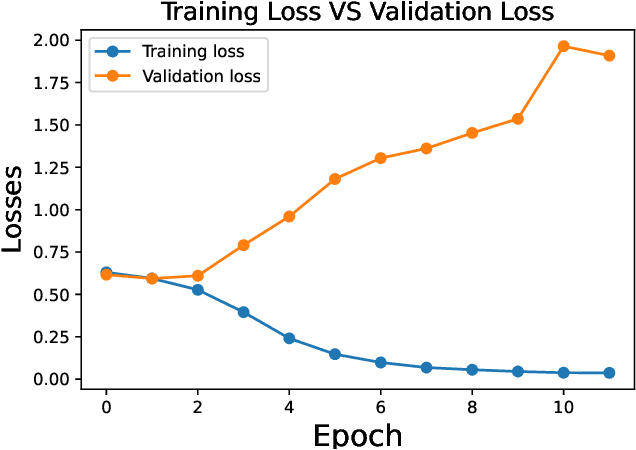
The rampant integration of social media in our every day lives and culture has given rise to fast and easier access to the flow of information than ever in human history. However, the inherently unsupervised nature of social media platforms has also made it easier to spread false information and fake news. Furthermore, the high volume and velocity of information flow in such platforms make manual supervision and control of information propagation infeasible. This paper aims to address this issue by proposing a novel deep learning approach for automated detection of false short-text claims on social media. We first introduce Sentimental LIAR, which extends the LIAR dataset of short claims by adding features based on sentiment and emotion analysis of claims. Furthermore, we propose a novel deep learning architecture based on the DistilBERT language model for classification of claims as genuine or fake. Our results demonstrate that the proposed architecture trained on Sentimental LIAR can achieve an accuracy of 70\%, which is an improvement of ~30\% over previously reported results for the LIAR benchmark.
Founding The Domain of AI Forensics
Dec 11, 2019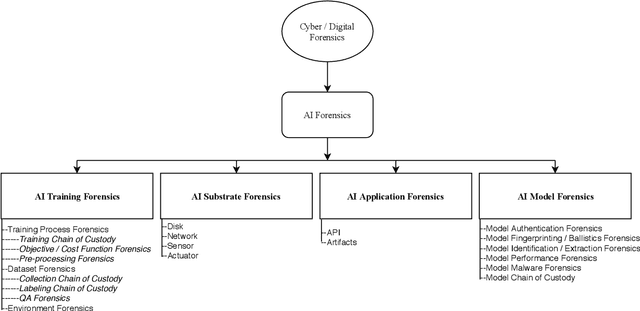
With the widespread integration of AI in everyday and critical technologies, it seems inevitable to witness increasing instances of failure in AI systems. In such cases, there arises a need for technical investigations that produce legally acceptable and scientifically indisputable findings and conclusions on the causes of such failures. Inspired by the domain of cyber forensics, this paper introduces the need for the establishment of AI Forensics as a new discipline under AI safety. Furthermore, we propose a taxonomy of the subfields under this discipline, and present a discussion on the foundational challenges that lay ahead of this new research area.
A Novel Approach for Detection and Ranking of Trendy and Emerging Cyber Threat Events in Twitter Streams
Jul 12, 2019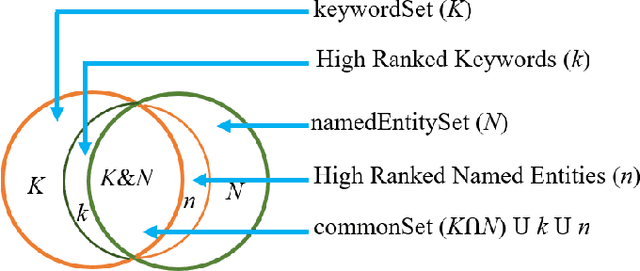
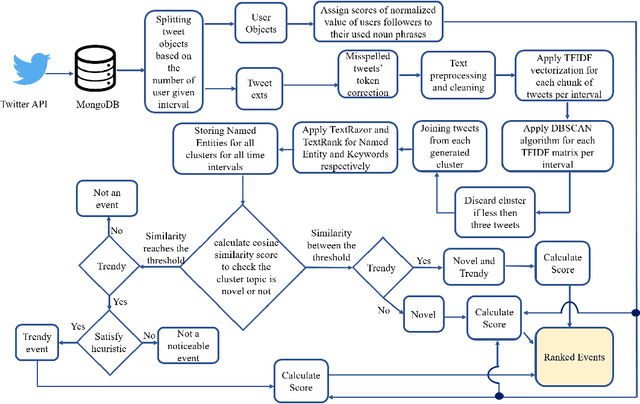
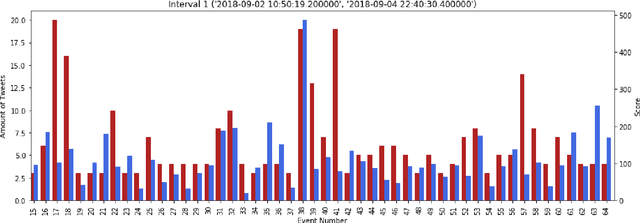
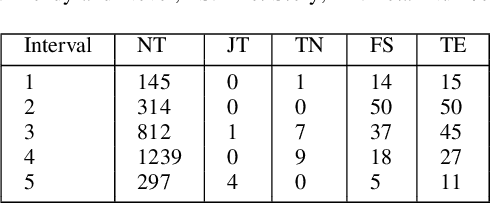
We present a new machine learning and text information extraction approach to detection of cyber threat events in Twitter that are novel (previously non-extant) and developing (marked by significance with respect to similarity with a previously detected event). While some existing approaches to event detection measure novelty and trendiness, typically as independent criteria and occasionally as a holistic measure, this work focuses on detecting both novel and developing events using an unsupervised machine learning approach. Furthermore, our proposed approach enables the ranking of cyber threat events based on an importance score by extracting the tweet terms that are characterized as named entities, keywords, or both. We also impute influence to users in order to assign a weighted score to noun phrases in proportion to user influence and the corresponding event scores for named entities and keywords. To evaluate the performance of our proposed approach, we measure the efficiency and detection error rate for events over a specified time interval, relative to human annotator ground truth.
Sequential Triggers for Watermarking of Deep Reinforcement Learning Policies
Jun 03, 2019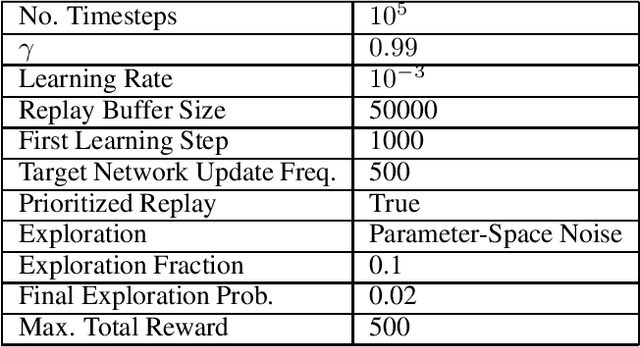
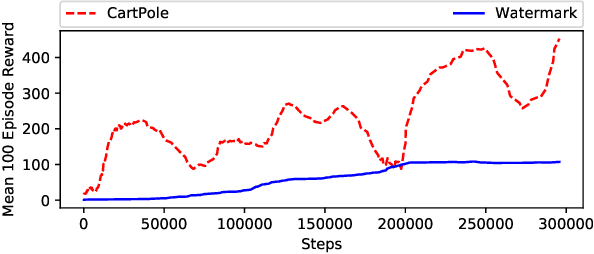
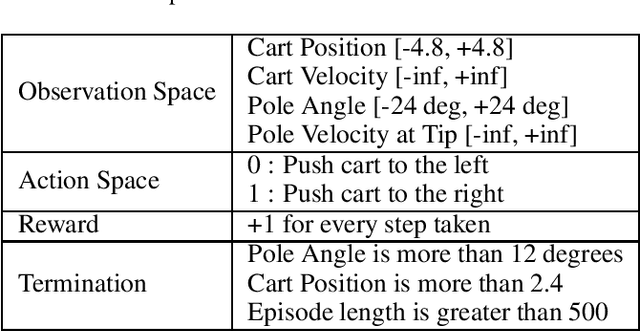
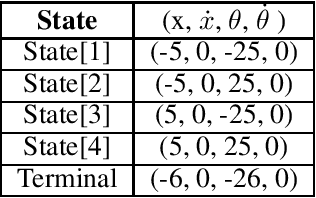
This paper proposes a novel scheme for the watermarking of Deep Reinforcement Learning (DRL) policies. This scheme provides a mechanism for the integration of a unique identifier within the policy in the form of its response to a designated sequence of state transitions, while incurring minimal impact on the nominal performance of the policy. The applications of this watermarking scheme include detection of unauthorized replications of proprietary policies, as well as enabling the graceful interruption or termination of DRL activities by authorized entities. We demonstrate the feasibility of our proposal via experimental evaluation of watermarking a DQN policy trained in the Cartpole environment.
Adversarial Exploitation of Policy Imitation
Jun 03, 2019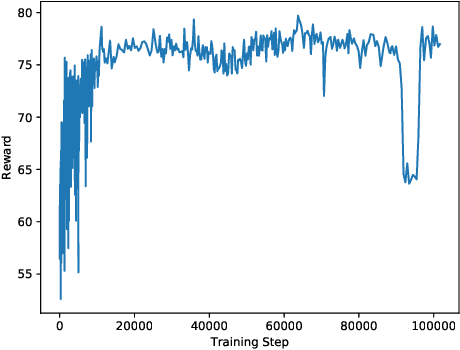

This paper investigates a class of attacks targeting the confidentiality aspect of security in Deep Reinforcement Learning (DRL) policies. Recent research have established the vulnerability of supervised machine learning models (e.g., classifiers) to model extraction attacks. Such attacks leverage the loosely-restricted ability of the attacker to iteratively query the model for labels, thereby allowing for the forging of a labeled dataset which can be used to train a replica of the original model. In this work, we demonstrate the feasibility of exploiting imitation learning techniques in launching model extraction attacks on DRL agents. Furthermore, we develop proof-of-concept attacks that leverage such techniques for black-box attacks against the integrity of DRL policies. We also present a discussion on potential solution concepts for mitigation techniques.
Analysis and Improvement of Adversarial Training in DQN Agents With Adversarially-Guided Exploration (AGE)
Jun 03, 2019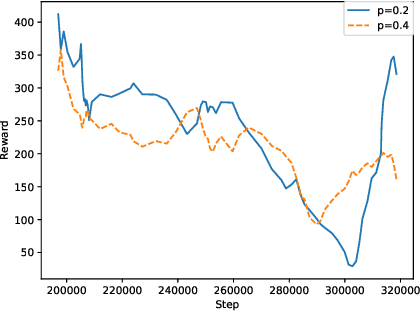
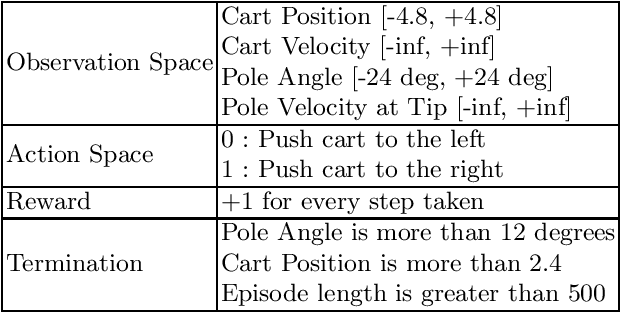
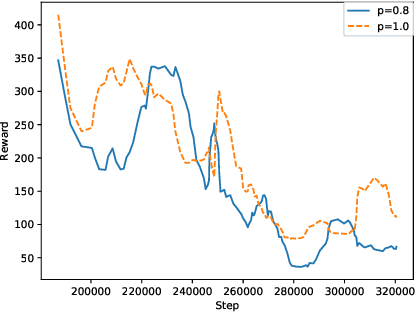
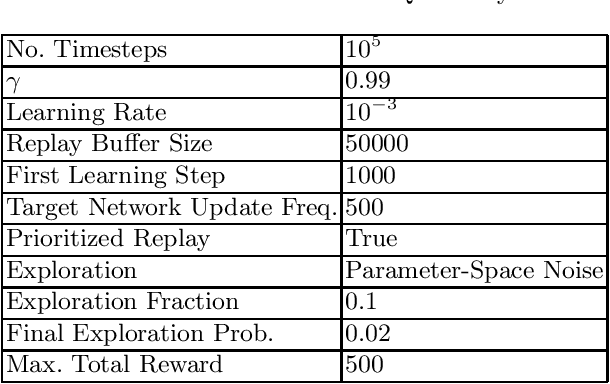
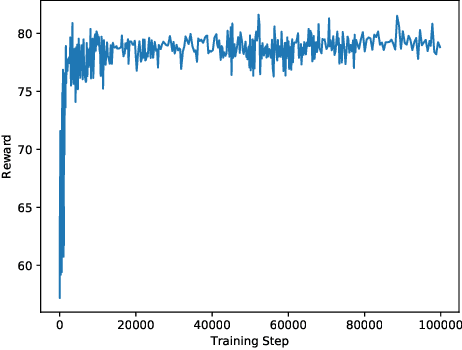
This paper investigates the effectiveness of adversarial training in enhancing the robustness of Deep Q-Network (DQN) policies to state-space perturbations. We first present a formal analysis of adversarial training in DQN agents and its performance with respect to the proportion of adversarial perturbations to nominal observations used for training. Next, we consider the sample-inefficiency of current adversarial training techniques, and propose a novel Adversarially-Guided Exploration (AGE) mechanism based on a modified hybrid of the $\epsilon$-greedy algorithm and Boltzmann exploration. We verify the feasibility of this exploration mechanism through experimental evaluation of its performance in comparison with the traditional decaying $\epsilon$-greedy and parameter-space noise exploration algorithms.
RL-Based Method for Benchmarking the Adversarial Resilience and Robustness of Deep Reinforcement Learning Policies
Jun 03, 2019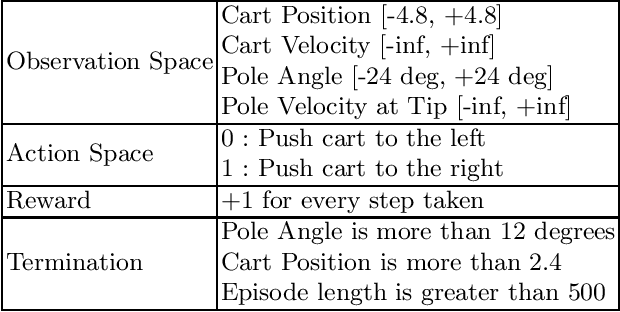
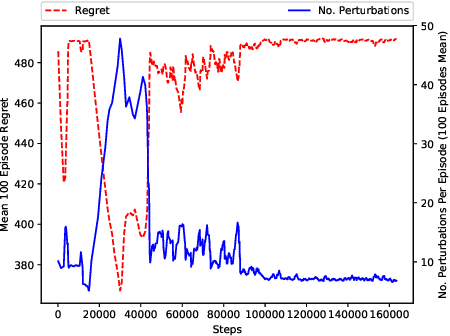
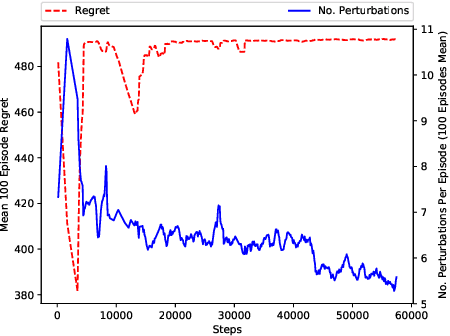
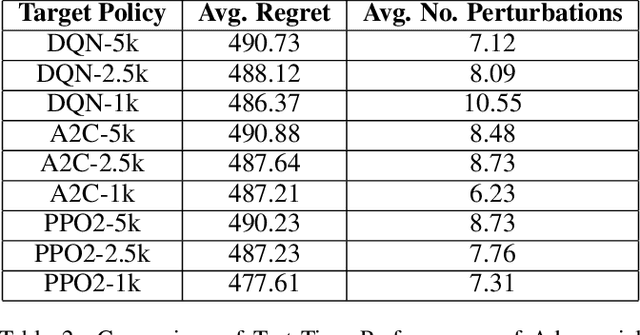
This paper investigates the resilience and robustness of Deep Reinforcement Learning (DRL) policies to adversarial perturbations in the state space. We first present an approach for the disentanglement of vulnerabilities caused by representation learning of DRL agents from those that stem from the sensitivity of the DRL policies to distributional shifts in state transitions. Building on this approach, we propose two RL-based techniques for quantitative benchmarking of adversarial resilience and robustness in DRL policies against perturbations of state transitions. We demonstrate the feasibility of our proposals through experimental evaluation of resilience and robustness in DQN, A2C, and PPO2 policies trained in the Cartpole environment.
TrolleyMod v1.0: An Open-Source Simulation and Data-Collection Platform for Ethical Decision Making in Autonomous Vehicles
Nov 14, 2018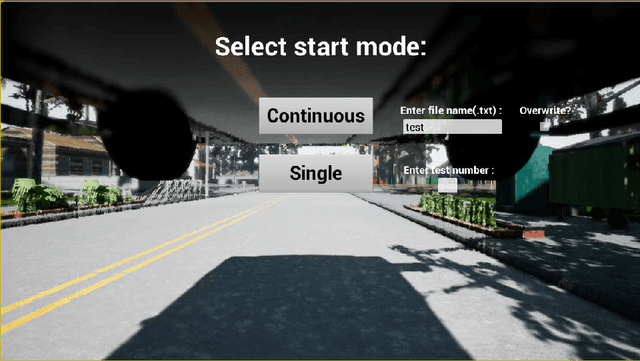

This paper presents TrolleyMod v1.0, an open-source platform based on the CARLA simulator for the collection of ethical decision-making data for autonomous vehicles. This platform is designed to facilitate experiments aiming to observe and record human decisions and actions in high-fidelity simulations of ethical dilemmas that occur in the context of driving. Targeting experiments in the class of trolley problems, TrolleyMod provides a seamless approach to creating new experimental settings and environments with the realistic physics-engine and the high-quality graphical capabilities of CARLA and the Unreal Engine. Also, TrolleyMod provides a straightforward interface between the CARLA environment and Python to enable the implementation of custom controllers, such as deep reinforcement learning agents. The results of such experiments can be used for sociological analyses, as well as the training and tuning of value-aligned autonomous vehicles based on social values that are inferred from observations.