 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDVFL-Net: A Lightweight Distilled Video Focal Modulation Network for Spatio-Temporal Action Recognition
Jul 16, 2025The landscape of video recognition has evolved significantly, shifting from traditional Convolutional Neural Networks (CNNs) to Transformer-based architectures for improved accuracy. While 3D CNNs have been effective at capturing spatiotemporal dynamics, recent Transformer models leverage self-attention to model long-range spatial and temporal dependencies. Despite achieving state-of-the-art performance on major benchmarks, Transformers remain computationally expensive, particularly with dense video data. To address this, we propose a lightweight Video Focal Modulation Network, DVFL-Net, which distills spatiotemporal knowledge from a large pre-trained teacher into a compact nano student model, enabling efficient on-device deployment. DVFL-Net utilizes knowledge distillation and spatial-temporal feature modulation to significantly reduce computation while preserving high recognition performance. We employ forward Kullback-Leibler (KL) divergence alongside spatio-temporal focal modulation to effectively transfer both local and global context from the Video-FocalNet Base (teacher) to the proposed VFL-Net (student). We evaluate DVFL-Net on UCF50, UCF101, HMDB51, SSV2, and Kinetics-400, benchmarking it against recent state-of-the-art methods in Human Action Recognition (HAR). Additionally, we conduct a detailed ablation study analyzing the impact of forward KL divergence. The results confirm the superiority of DVFL-Net in achieving an optimal balance between performance and efficiency, demonstrating lower memory usage, reduced GFLOPs, and strong accuracy, making it a practical solution for real-time HAR applications.
OD-VIRAT: A Large-Scale Benchmark for Object Detection in Realistic Surveillance Environments
Jul 16, 2025Realistic human surveillance datasets are crucial for training and evaluating computer vision models under real-world conditions, facilitating the development of robust algorithms for human and human-interacting object detection in complex environments. These datasets need to offer diverse and challenging data to enable a comprehensive assessment of model performance and the creation of more reliable surveillance systems for public safety. To this end, we present two visual object detection benchmarks named OD-VIRAT Large and OD-VIRAT Tiny, aiming at advancing visual understanding tasks in surveillance imagery. The video sequences in both benchmarks cover 10 different scenes of human surveillance recorded from significant height and distance. The proposed benchmarks offer rich annotations of bounding boxes and categories, where OD-VIRAT Large has 8.7 million annotated instances in 599,996 images and OD-VIRAT Tiny has 288,901 annotated instances in 19,860 images. This work also focuses on benchmarking state-of-the-art object detection architectures, including RETMDET, YOLOX, RetinaNet, DETR, and Deformable-DETR on this object detection-specific variant of VIRAT dataset. To the best of our knowledge, it is the first work to examine the performance of these recently published state-of-the-art object detection architectures on realistic surveillance imagery under challenging conditions such as complex backgrounds, occluded objects, and small-scale objects. The proposed benchmarking and experimental settings will help in providing insights concerning the performance of selected object detection models and set the base for developing more efficient and robust object detection architectures.
Hierarchical Multi-Stage Transformer Architecture for Context-Aware Temporal Action Localization
Jul 08, 2025Inspired by the recent success of transformers and multi-stage architectures in video recognition and object detection domains. We thoroughly explore the rich spatio-temporal properties of transformers within a multi-stage architecture paradigm for the temporal action localization (TAL) task. This exploration led to the development of a hierarchical multi-stage transformer architecture called PCL-Former, where each subtask is handled by a dedicated transformer module with a specialized loss function. Specifically, the Proposal-Former identifies candidate segments in an untrimmed video that may contain actions, the Classification-Former classifies the action categories within those segments, and the Localization-Former precisely predicts the temporal boundaries (i.e., start and end) of the action instances. To evaluate the performance of our method, we have conducted extensive experiments on three challenging benchmark datasets: THUMOS-14, ActivityNet-1.3, and HACS Segments. We also conducted detailed ablation experiments to assess the impact of each individual module of our PCL-Former. The obtained quantitative results validate the effectiveness of the proposed PCL-Former, outperforming state-of-the-art TAL approaches by 2.8%, 1.2%, and 4.8% on THUMOS14, ActivityNet-1.3, and HACS datasets, respectively.
ViT-ReT: Vision and Recurrent Transformer Neural Networks for Human Activity Recognition in Videos
Aug 25, 2022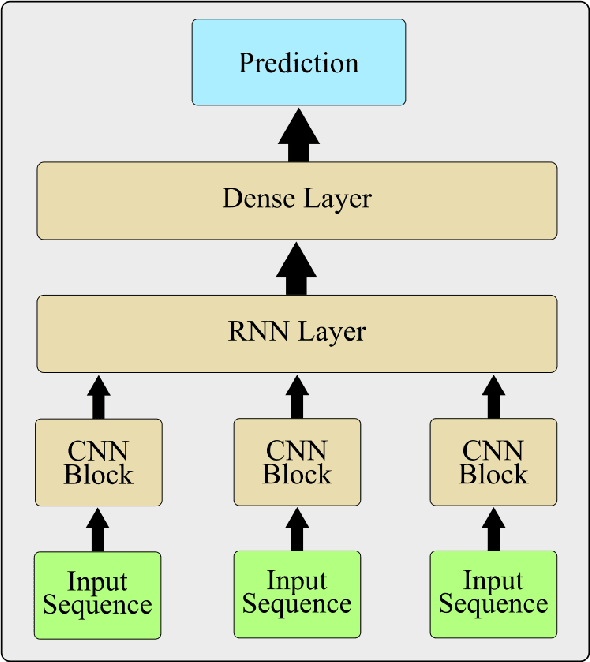
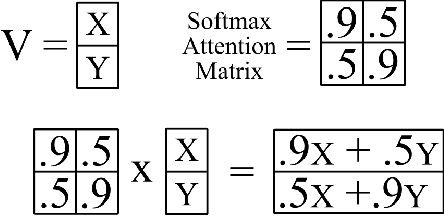
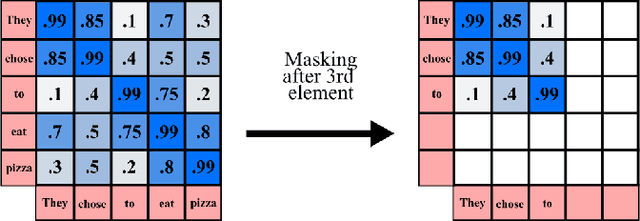
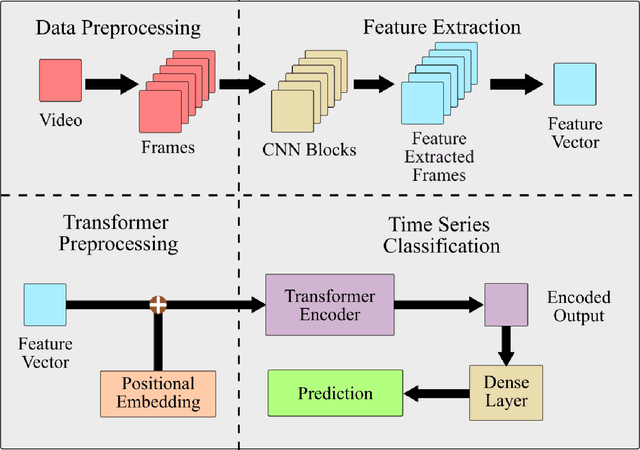
Human activity recognition is an emerging and important area in computer vision which seeks to determine the activity an individual or group of individuals are performing. The applications of this field ranges from generating highlight videos in sports, to intelligent surveillance and gesture recognition. Most activity recognition systems rely on a combination of convolutional neural networks (CNNs) to perform feature extraction from the data and recurrent neural networks (RNNs) to determine the time dependent nature of the data. This paper proposes and designs two transformer neural networks for human activity recognition: a recurrent transformer (ReT), a specialized neural network used to make predictions on sequences of data, as well as a vision transformer (ViT), a transformer optimized for extracting salient features from images, to improve speed and scalability of activity recognition. We have provided an extensive comparison of the proposed transformer neural networks with the contemporary CNN and RNN-based human activity recognition models in terms of speed and accuracy.
Human Activity Recognition Using Cascaded Dual Attention CNN and Bi-Directional GRU Framework
Aug 09, 2022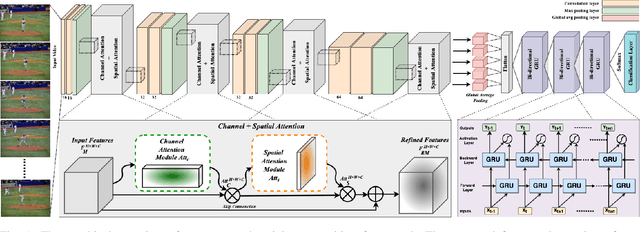
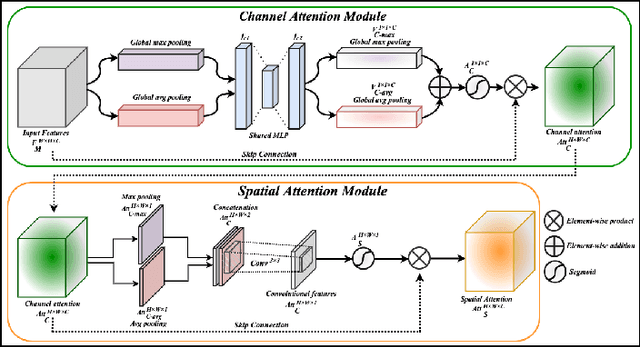

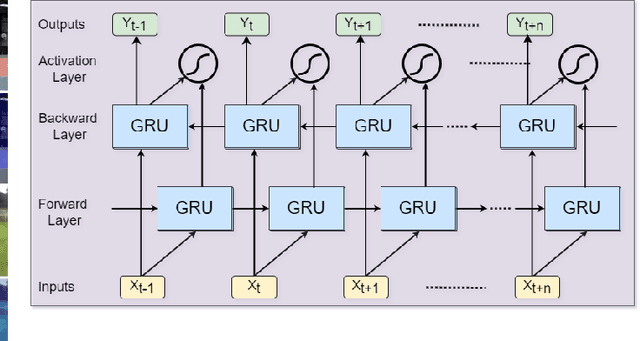
Vision-based human activity recognition has emerged as one of the essential research areas in video analytics domain. Over the last decade, numerous advanced deep learning algorithms have been introduced to recognize complex human actions from video streams. These deep learning algorithms have shown impressive performance for the human activity recognition task. However, these newly introduced methods either exclusively focus on model performance or the effectiveness of these models in terms of computational efficiency and robustness, resulting in a biased tradeoff in their proposals to deal with challenging human activity recognition problem. To overcome the limitations of contemporary deep learning models for human activity recognition, this paper presents a computationally efficient yet generic spatial-temporal cascaded framework that exploits the deep discriminative spatial and temporal features for human activity recognition. For efficient representation of human actions, we have proposed an efficient dual attentional convolutional neural network (CNN) architecture that leverages a unified channel-spatial attention mechanism to extract human-centric salient features in video frames. The dual channel-spatial attention layers together with the convolutional layers learn to be more attentive in the spatial receptive fields having objects over the number of feature maps. The extracted discriminative salient features are then forwarded to stacked bi-directional gated recurrent unit (Bi-GRU) for long-term temporal modeling and recognition of human actions using both forward and backward pass gradient learning. Extensive experiments are conducted, where the obtained results show that the proposed framework attains an improvement in execution time up to 167 times in terms of frames per second as compared to most of the contemporary action recognition methods.
Phantom: A High-Performance Computational Core for Sparse Convolutional Neural Networks
Nov 09, 2021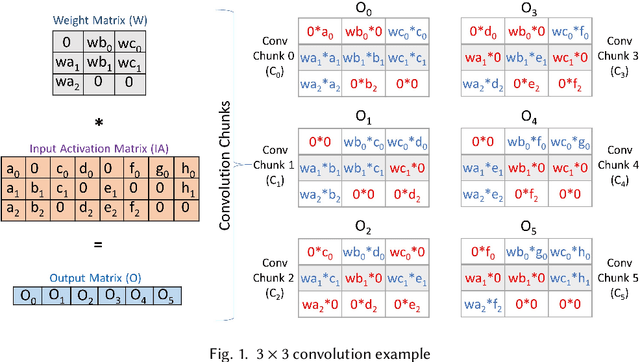
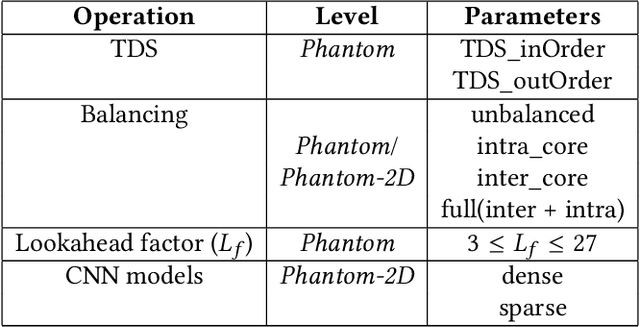

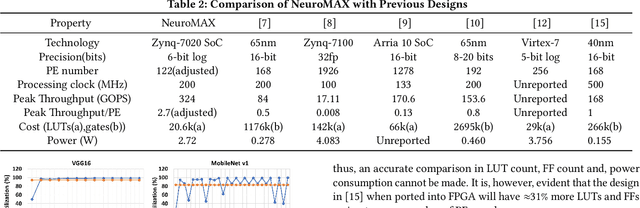
Sparse convolutional neural networks (CNNs) have gained significant traction over the past few years as sparse CNNs can drastically decrease the model size and computations, if exploited befittingly, as compared to their dense counterparts. Sparse CNNs often introduce variations in the layer shapes and sizes, which can prevent dense accelerators from performing well on sparse CNN models. Recently proposed sparse accelerators like SCNN, Eyeriss v2, and SparTen, actively exploit the two-sided or full sparsity, that is, sparsity in both weights and activations, for performance gains. These accelerators, however, either have inefficient micro-architecture, which limits their performance, have no support for non-unit stride convolutions and fully-connected (FC) layers, or suffer massively from systematic load imbalance. To circumvent these issues and support both sparse and dense models, we propose Phantom, a multi-threaded, dynamic, and flexible neural computational core. Phantom uses sparse binary mask representation to actively lookahead into sparse computations, and dynamically schedule its computational threads to maximize the thread utilization and throughput. We also generate a two-dimensional (2D) mesh architecture of Phantom neural computational cores, which we refer to as Phantom-2D accelerator, and propose a novel dataflow that supports all layers of a CNN, including unit and non-unit stride convolutions, and FC layers. In addition, Phantom-2D uses a two-level load balancing strategy to minimize the computational idling, thereby, further improving the hardware utilization. To show support for different types of layers, we evaluate the performance of the Phantom architecture on VGG16 and MobileNet. Our simulations show that the Phantom-2D accelerator attains a performance gain of 12x, 4.1x, 1.98x, and 2.36x, over dense architectures, SCNN, SparTen, and Eyeriss v2, respectively.
NeuroMAX: A High Throughput, Multi-Threaded, Log-Based Accelerator for Convolutional Neural Networks
Jul 19, 2020
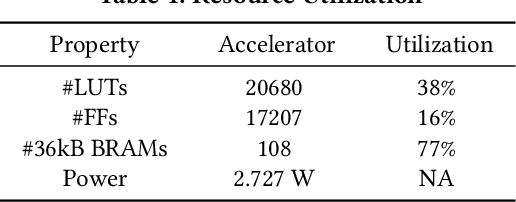
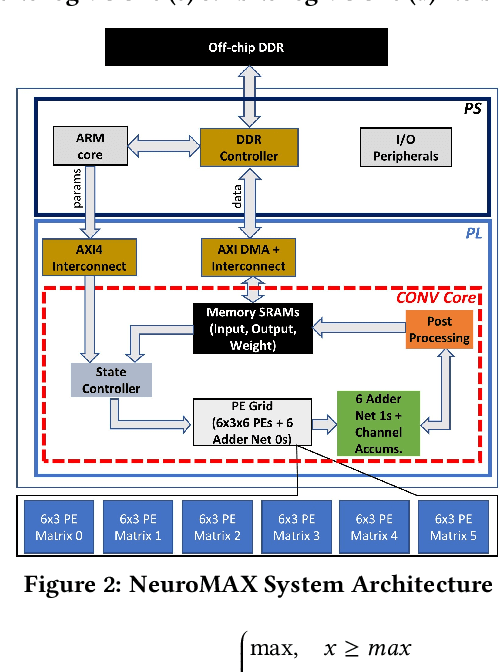
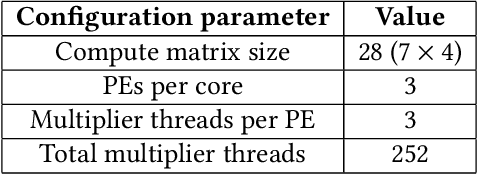
Convolutional neural networks (CNNs) require high throughput hardware accelerators for real time applications owing to their huge computational cost. Most traditional CNN accelerators rely on single core, linear processing elements (PEs) in conjunction with 1D dataflows for accelerating convolution operations. This limits the maximum achievable ratio of peak throughput per PE count to unity. Most of the past works optimize their dataflows to attain close to a 100% hardware utilization to reach this ratio. In this paper, we introduce a high throughput, multi-threaded, log-based PE core. The designed core provides a 200% increase in peak throughput per PE count while only incurring a 6% increase in area overhead compared to a single, linear multiplier PE core with same output bit precision. We also present a 2D weight broadcast dataflow which exploits the multi-threaded nature of the PE cores to achieve a high hardware utilization per layer for various CNNs. The entire architecture, which we refer to as NeuroMAX, is implemented on Xilinx Zynq 7020 SoC at 200 MHz processing clock. Detailed analysis is performed on throughput, hardware utilization, area and power breakdown, and latency to show performance improvement compared to previous FPGA and ASIC designs.
TrolleyMod v1.0: An Open-Source Simulation and Data-Collection Platform for Ethical Decision Making in Autonomous Vehicles
Nov 14, 2018

This paper presents TrolleyMod v1.0, an open-source platform based on the CARLA simulator for the collection of ethical decision-making data for autonomous vehicles. This platform is designed to facilitate experiments aiming to observe and record human decisions and actions in high-fidelity simulations of ethical dilemmas that occur in the context of driving. Targeting experiments in the class of trolley problems, TrolleyMod provides a seamless approach to creating new experimental settings and environments with the realistic physics-engine and the high-quality graphical capabilities of CARLA and the Unreal Engine. Also, TrolleyMod provides a straightforward interface between the CARLA environment and Python to enable the implementation of custom controllers, such as deep reinforcement learning agents. The results of such experiments can be used for sociological analyses, as well as the training and tuning of value-aligned autonomous vehicles based on social values that are inferred from observations.
Emergence of Addictive Behaviors in Reinforcement Learning Agents
Nov 14, 2018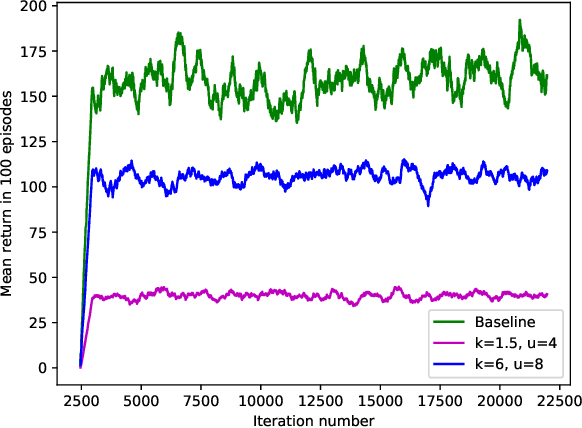
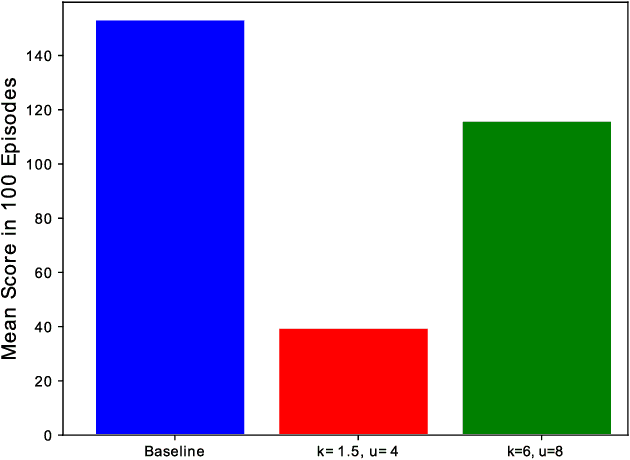
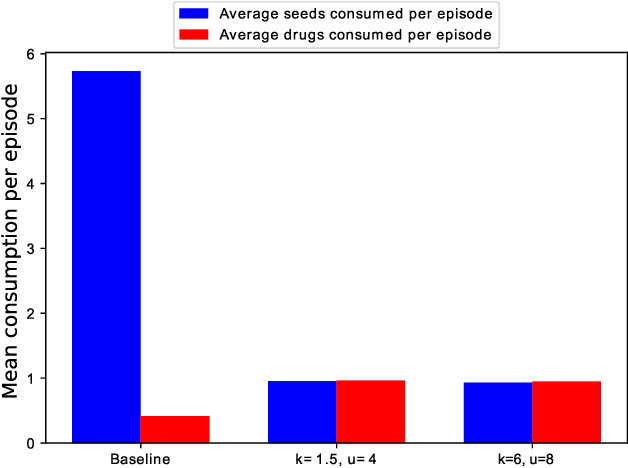
This paper presents a novel approach to the technical analysis of wireheading in intelligent agents. Inspired by the natural analogues of wireheading and their prevalent manifestations, we propose the modeling of such phenomenon in Reinforcement Learning (RL) agents as psychological disorders. In a preliminary step towards evaluating this proposal, we study the feasibility and dynamics of emergent addictive policies in Q-learning agents in the tractable environment of the game of Snake. We consider a slightly modified settings for this game, in which the environment provides a "drug" seed alongside the original "healthy" seed for the consumption of the snake. We adopt and extend an RL-based model of natural addiction to Q-learning agents in this settings, and derive sufficient parametric conditions for the emergence of addictive behaviors in such agents. Furthermore, we evaluate our theoretical analysis with three sets of simulation-based experiments. The results demonstrate the feasibility of addictive wireheading in RL agents, and provide promising venues of further research on the psychopathological modeling of complex AI safety problems.
The Faults in Our Pi Stars: Security Issues and Open Challenges in Deep Reinforcement Learning
Oct 23, 2018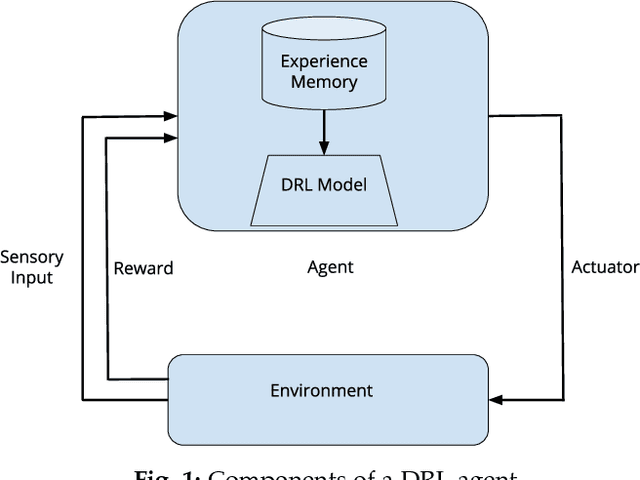
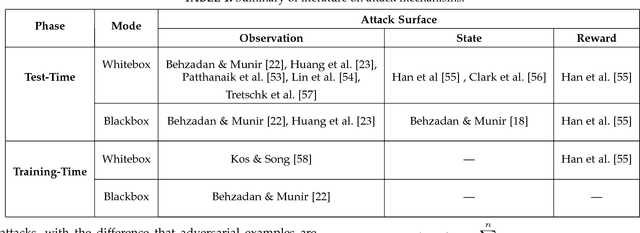
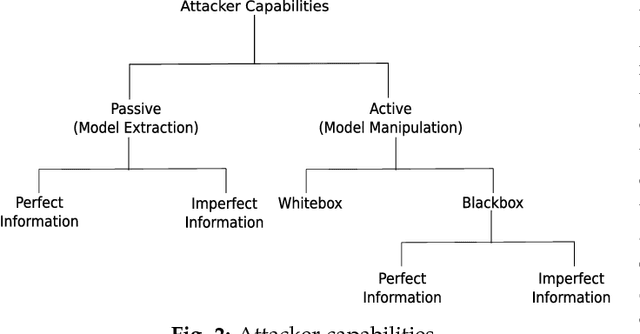
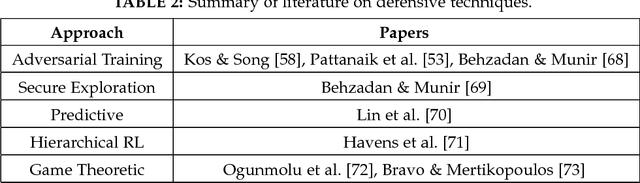
Since the inception of Deep Reinforcement Learning (DRL) algorithms, there has been a growing interest in both research and industrial communities in the promising potentials of this paradigm. The list of current and envisioned applications of deep RL ranges from autonomous navigation and robotics to control applications in the critical infrastructure, air traffic control, defense technologies, and cybersecurity. While the landscape of opportunities and the advantages of deep RL algorithms are justifiably vast, the security risks and issues in such algorithms remain largely unexplored. To facilitate and motivate further research on these critical challenges, this paper presents a foundational treatment of the security problem in DRL. We formulate the security requirements of DRL, and provide a high-level threat model through the classification and identification of vulnerabilities, attack vectors, and adversarial capabilities. Furthermore, we present a review of current literature on security of deep RL from both offensive and defensive perspectives. Lastly, we enumerate critical research venues and open problems in mitigation and prevention of intentional attacks against deep RL as a roadmap for further research in this area.