 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Embedded Real-Time License Plate Recognition System for Complex Traffic Scenes
Jun 26, 2026Vehicle license plate recognition is an integral component of intelligent transportation systems. In this work, we present an embedded real-time license plate recognition system customized for developing countries. We address the challenge of handling complex, unstructured traffic scenes with diverse vehicle types while implementing the system on an embedded platform for low-cost deployment. Our method consists of license plate detection on a multi-vehicle image, followed by character recognition on the detected license plates. Both steps use lightweight convolutional neural networks to balance accuracy and efficiency. We also introduce the SL-LPR dataset of Sri Lankan road images, which contains a variety of vehicle types and traffic conditions typically seen in developing countries. On this dataset, the license plate detection and character recognition models achieved 93.6% mAP and 87.88% accuracy, respectively, and were competitive against larger models on several public datasets. To achieve real-time performance in a resource-constrained embedded environment, we applied low-bitwidth quantization using the Brevitas library and implemented FPGA acceleration for the models using the FINN framework. The end-to-end system can operate at 11.5~FPS when implemented on the Xilinx Kria KV260 platform. These results demonstrate that our system is effective for real-time license plate recognition on an embedded device, even in complex traffic scenarios. The SL-LPR dataset is available for research use at: https://github.com/sl-lpr-uom/SL-LPR.git.
* Accepted at IEEE Intelligent Transportation Systems Conference (ITSC) 2026
VideoPulse: Neonatal heart rate and peripheral capillary oxygen saturation (SpO2) estimation from contact free video
Feb 27, 2026Remote photoplethysmography (rPPG) enables contact free monitoring of vital signs and is especially valuable for neonates, since conventional methods often require sustained skin contact with adhesive probes that can irritate fragile skin and increase infection control burden. We present VideoPulse, a neonatal dataset and an end to end pipeline that estimates neonatal heart rate and peripheral capillary oxygen saturation (SpO2) from facial video. VideoPulse contains 157 recordings totaling 2.6 hours from 52 neonates with diverse face orientations. Our pipeline performs face alignment and artifact aware supervision using denoised pulse oximeter signals, then applies 3D CNN backbones for heart rate and SpO2 regression with label distribution smoothing and weighted regression for SpO2. Predictions are produced in 2 second windows. On the NBHR neonatal dataset, we obtain heart rate MAE 2.97 bpm using 2 second windows (2.80 bpm at 6 second windows) and SpO2 MAE 1.69 percent. Under cross dataset evaluation, the NBHR trained heart rate model attains 5.34 bpm MAE on VideoPulse, and fine tuning an NBHR pretrained SpO2 model on VideoPulse yields MAE 1.68 percent. These results indicate that short unaligned neonatal video segments can support accurate heart rate and SpO2 estimation, enabling low cost non invasive monitoring in neonatal intensive care.
A-TPT: Angular Diversity Calibration Properties for Test-Time Prompt Tuning of Vision-Language Models
Oct 30, 2025Test-time prompt tuning (TPT) has emerged as a promising technique for adapting large vision-language models (VLMs) to unseen tasks without relying on labeled data. However, the lack of dispersion between textual features can hurt calibration performance, which raises concerns about VLMs' reliability, trustworthiness, and safety. Current TPT approaches primarily focus on improving prompt calibration by either maximizing average textual feature dispersion or enforcing orthogonality constraints to encourage angular separation. However, these methods may not always have optimal angular separation between class-wise textual features, which implies overlooking the critical role of angular diversity. To address this, we propose A-TPT, a novel TPT framework that introduces angular diversity to encourage uniformity in the distribution of normalized textual features induced by corresponding learnable prompts. This uniformity is achieved by maximizing the minimum pairwise angular distance between features on the unit hypersphere. We show that our approach consistently surpasses state-of-the-art TPT methods in reducing the aggregate average calibration error while maintaining comparable accuracy through extensive experiments with various backbones on different datasets. Notably, our approach exhibits superior zero-shot calibration performance on natural distribution shifts and generalizes well to medical datasets. We provide extensive analyses, including theoretical aspects, to establish the grounding of A-TPT. These results highlight the potency of promoting angular diversity to achieve well-dispersed textual features, significantly improving VLM calibration during test-time adaptation. Our code will be made publicly available.
Resilient Sparse Array Radar with the Aid of Deep Learning
Jun 21, 2023



In this paper, we address the problem of direction of arrival (DOA) estimation for multiple targets in the presence of sensor failures in a sparse array. Generally, sparse arrays are known with very high-resolution capabilities, where N physical sensors can resolve up to $\mathcal{O}(N^2)$ uncorrelated sources. However, among the many configurations introduced in the literature, the arrays that provide the largest hole-free co-array are the most susceptible to sensor failures. We propose here two machine learning (ML) methods to mitigate the effect of sensor failures and maintain the DOA estimation performance and resolution. The first method enhances the conventional spatial smoothing using deep neural network (DNN), while the second one is an end-to-end data-driven method. Numerical results show that both approaches can significantly improve the performance of MRA with two failed sensors. The data-driven method can maintain the performance of the array with no failures at high signal-tonoise ratio (SNR). Moreover, both approaches can even perform better than the original array at low SNR thanks to the denoising effect of the proposed DNN
* Accepted to be published in 2023 IEEE 97th Vehicular Technology Conference: VTC2023-Spring, 2023
Deep Unfolding of Iteratively Reweighted ADMM for Wireless RF Sensing
Jun 07, 2021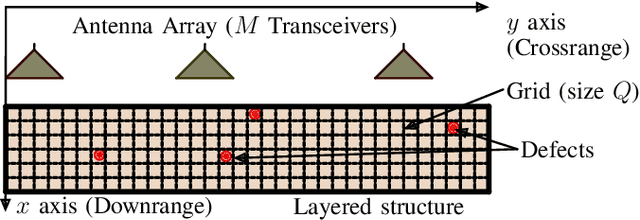
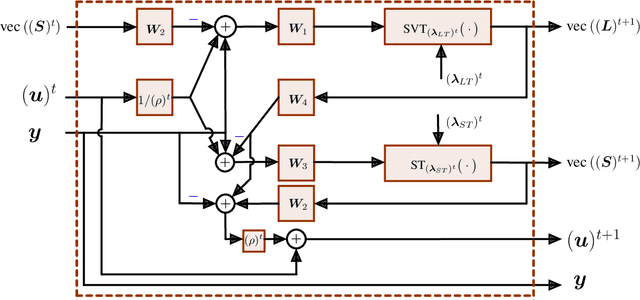
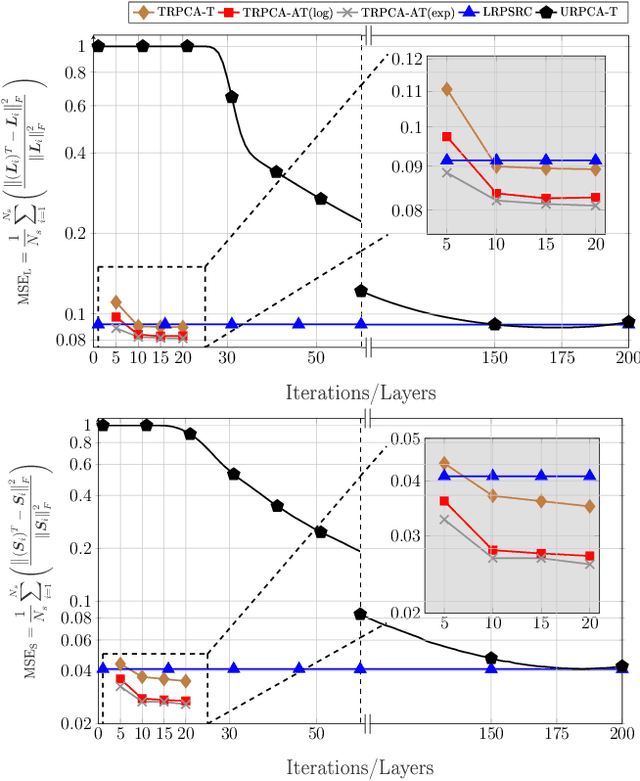
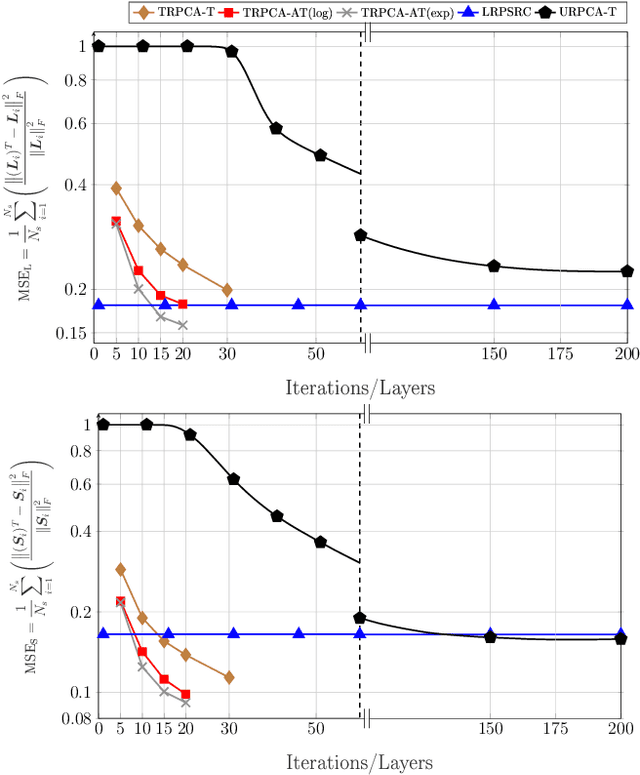
We address the detection of material defects, which are inside a layered material structure using compressive sensing based multiple-output (MIMO) wireless radar. Here, the strong clutter due to the reflection of the layered structure's surface often makes the detection of the defects challenging. Thus, sophisticated signal separation methods are required for improved defect detection. In many scenarios, the number of defects that we are interested in is limited and the signaling response of the layered structure can be modeled as a low-rank structure. Therefore, we propose joint rank and sparsity minimization for defect detection. In particular, we propose a non-convex approach based on the iteratively reweighted nuclear and $\ell_1-$norm (a double-reweighted approach) to obtain a higher accuracy compared to the conventional nuclear norm and $\ell_1-$norm minimization. To this end, an iterative algorithm is designed to estimate the low-rank and sparse contributions. Further, we propose deep learning to learn the parameters of the algorithm (i.e., algorithm unfolding) to improve the accuracy and the speed of convergence of the algorithm. Our numerical results show that the proposed approach outperforms the conventional approaches in terms of mean square errors of the recovered low-rank and sparse components and the speed of convergence.