 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Theory of Mind via Dynamic Traits Attribution
Apr 17, 2022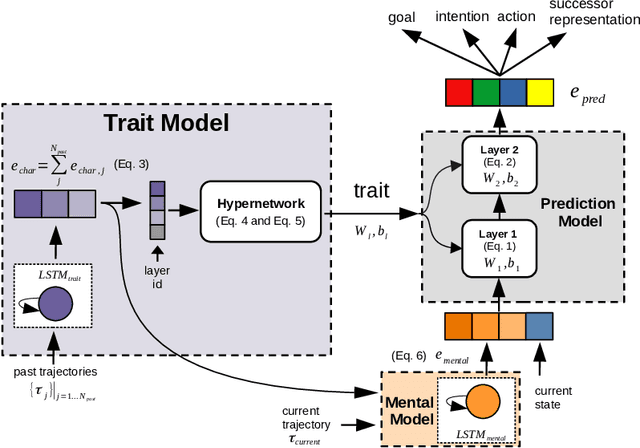
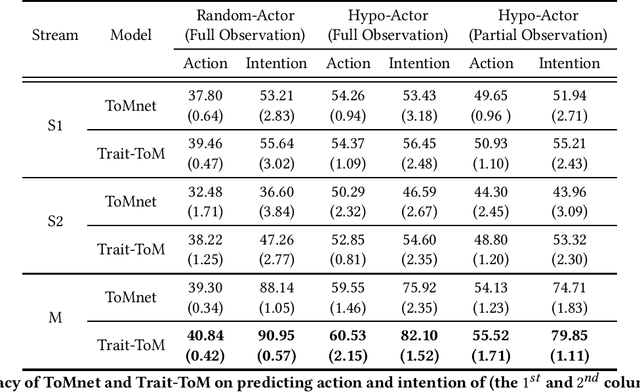
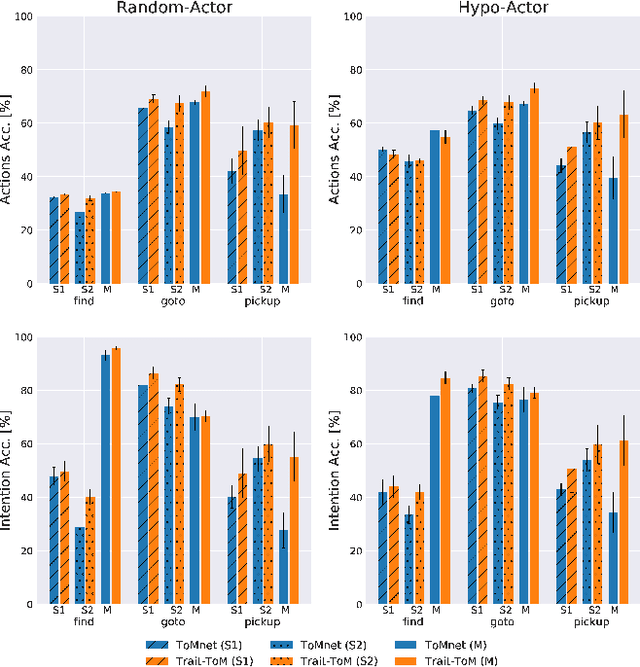
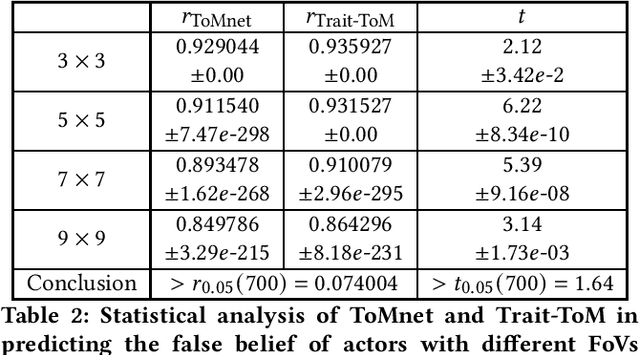
Machine learning of Theory of Mind (ToM) is essential to build social agents that co-live with humans and other agents. This capacity, once acquired, will help machines infer the mental states of others from observed contextual action trajectories, enabling future prediction of goals, intention, actions and successor representations. The underlying mechanism for such a prediction remains unclear, however. Inspired by the observation that humans often infer the character traits of others, then use it to explain behaviour, we propose a new neural ToM architecture that learns to generate a latent trait vector of an actor from the past trajectories. This trait vector then multiplicatively modulates the prediction mechanism via a `fast weights' scheme in the prediction neural network, which reads the current context and predicts the behaviour. We empirically show that the fast weights provide a good inductive bias to model the character traits of agents and hence improves mindreading ability. On the indirect assessment of false-belief understanding, the new ToM model enables more efficient helping behaviours.
Towards Effective and Robust Neural Trojan Defenses via Input Filtering
Mar 08, 2022


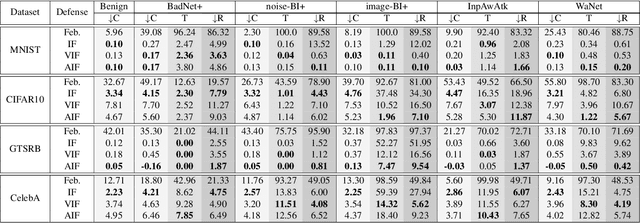
Trojan attacks on deep neural networks are both dangerous and surreptitious. Over the past few years, Trojan attacks have advanced from using only a single input-agnostic trigger and targeting only one class to using multiple, input-specific triggers and targeting multiple classes. However, Trojan defenses have not caught up with this development. Most defense methods still make out-of-date assumptions about Trojan triggers and target classes, thus, can be easily circumvented by modern Trojan attacks. To deal with this problem, we propose two novel "filtering" defenses called Variational Input Filtering (VIF) and Adversarial Input Filtering (AIF) which leverage lossy data compression and adversarial learning respectively to effectively purify all potential Trojan triggers in the input at run time without making assumptions about the number of triggers/target classes or the input dependence property of triggers. In addition, we introduce a new defense mechanism called "Filtering-then-Contrasting" (FtC) which helps avoid the drop in classification accuracy on clean data caused by "filtering", and combine it with VIF/AIF to derive new defenses of this kind. Extensive experimental results and ablation studies show that our proposed defenses significantly outperform well-known baseline defenses in mitigating five advanced Trojan attacks including two recent state-of-the-art while being quite robust to small amounts of training data and large-norm triggers.
Learning to Discover Medicines
Feb 14, 2022Discovering new medicines is the hallmark of human endeavor to live a better and longer life. Yet the pace of discovery has slowed down as we need to venture into more wildly unexplored biomedical space to find one that matches today's high standard. Modern AI-enabled by powerful computing, large biomedical databases, and breakthroughs in deep learning-offers a new hope to break this loop as AI is rapidly maturing, ready to make a huge impact in the area. In this paper we review recent advances in AI methodologies that aim to crack this challenge. We organize the vast and rapidly growing literature of AI for drug discovery into three relatively stable sub-areas: (a) representation learning over molecular sequences and geometric graphs; (b) data-driven reasoning where we predict molecular properties and their binding, optimize existing compounds, generate de novo molecules, and plan the synthesis of target molecules; and (c) knowledge-based reasoning where we discuss the construction and reasoning over biomedical knowledge graphs. We will also identify open challenges and chart possible research directions for the years to come.
Mitigating cold start problems in drug-target affinity prediction with interaction knowledge transferring
Jan 16, 2022
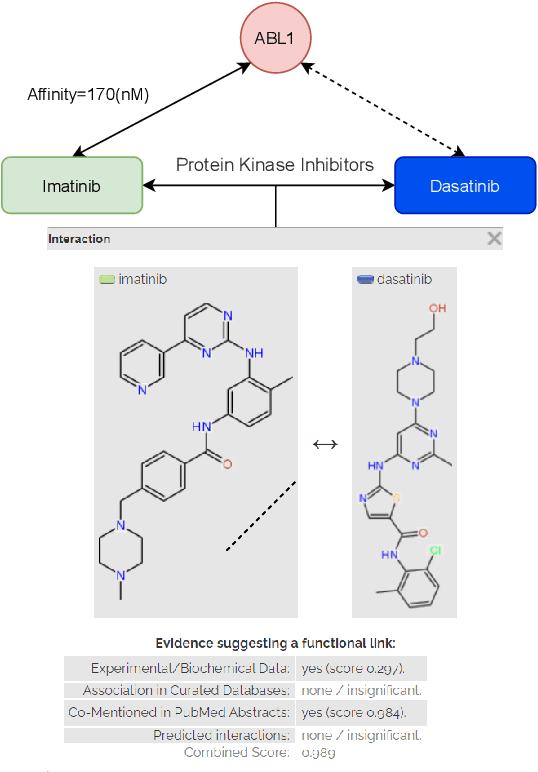
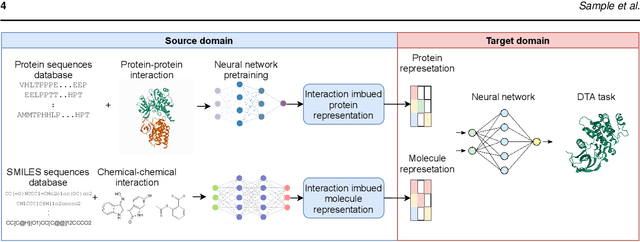
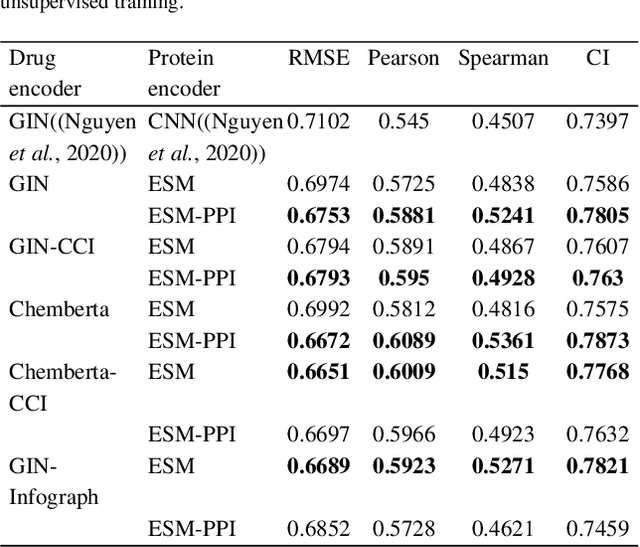
Motivation: Predicting the drug-target interaction is crucial for drug discovery as well as drug repurposing. Machine learning is commonly used in drug-target affinity (DTA) problem. However, machine learning model faces the cold-start problem where the model performance drops when predicting the interaction of a novel drug or target. Previous works try to solve the cold start problem by learning the drug or target representation using unsupervised learning. While the drug or target representation can be learned in an unsupervised manner, it still lacks the interaction information, which is critical in drug-target interaction. Results: To incorporate the interaction information into the drug and protein interaction, we proposed using transfer learning from chemical-chemical interaction (CCI) and protein-protein interaction (PPI) task to drug-target interaction task. The representation learned by CCI and PPI tasks can be transferred smoothly to the DTA task due to the similar nature of the tasks. The result on the drug-target affinity datasets shows that our proposed method has advantages compared to other pretraining methods in the DTA task.
Model-Based Episodic Memory Induces Dynamic Hybrid Controls
Nov 06, 2021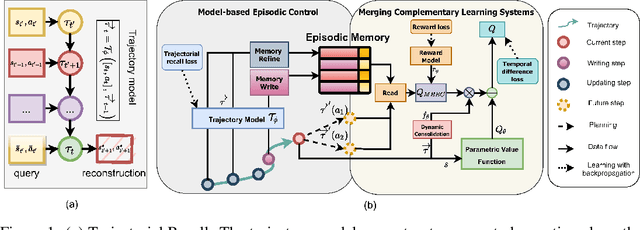
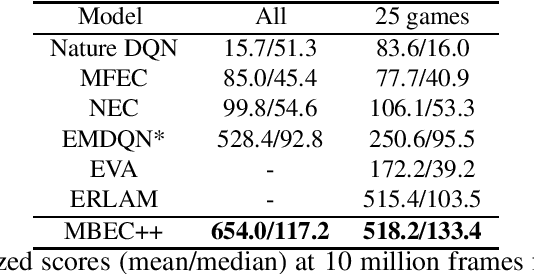
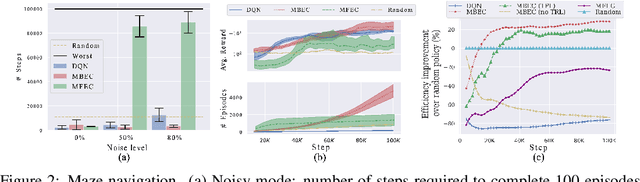
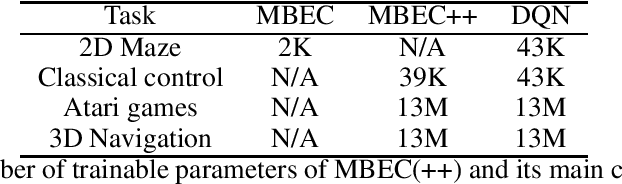
Episodic control enables sample efficiency in reinforcement learning by recalling past experiences from an episodic memory. We propose a new model-based episodic memory of trajectories addressing current limitations of episodic control. Our memory estimates trajectory values, guiding the agent towards good policies. Built upon the memory, we construct a complementary learning model via a dynamic hybrid control unifying model-based, episodic and habitual learning into a single architecture. Experiments demonstrate that our model allows significantly faster and better learning than other strong reinforcement learning agents across a variety of environments including stochastic and non-Markovian settings.
Balanced Q-learning: Combining the Influence of Optimistic and Pessimistic Targets
Nov 03, 2021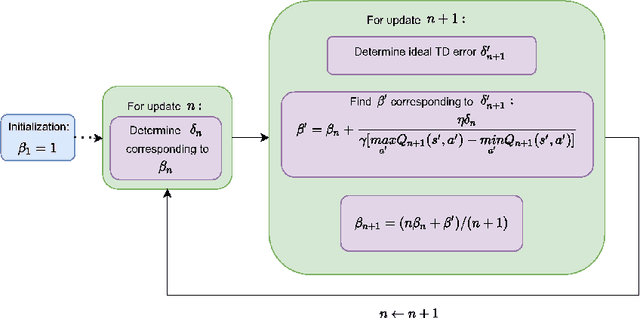
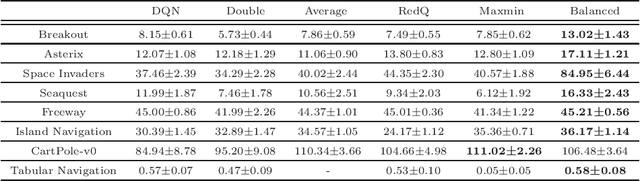
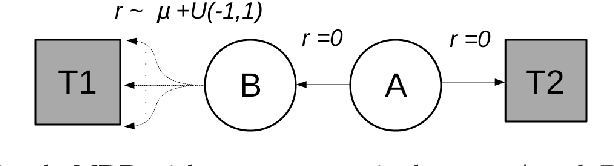
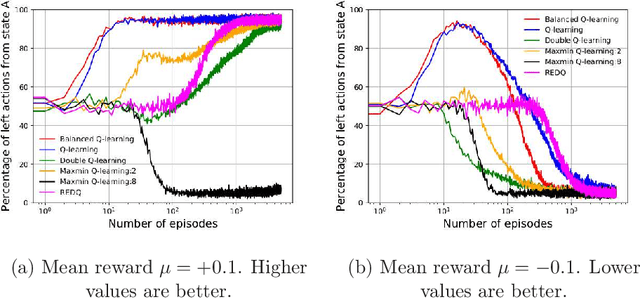
The optimistic nature of the Q-learning target leads to an overestimation bias, which is an inherent problem associated with standard $Q-$learning. Such a bias fails to account for the possibility of low returns, particularly in risky scenarios. However, the existence of biases, whether overestimation or underestimation, need not necessarily be undesirable. In this paper, we analytically examine the utility of biased learning, and show that specific types of biases may be preferable, depending on the scenario. Based on this finding, we design a novel reinforcement learning algorithm, Balanced Q-learning, in which the target is modified to be a convex combination of a pessimistic and an optimistic term, whose associated weights are determined online, analytically. We prove the convergence of this algorithm in a tabular setting, and empirically demonstrate its superior learning performance in various environments.
Clustering by Maximizing Mutual Information Across Views
Jul 24, 2021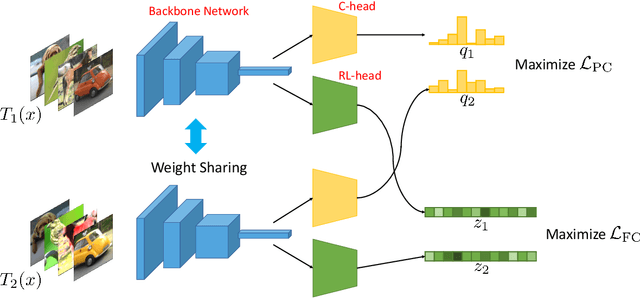
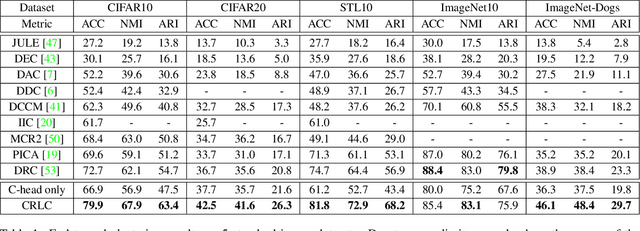


We propose a novel framework for image clustering that incorporates joint representation learning and clustering. Our method consists of two heads that share the same backbone network - a "representation learning" head and a "clustering" head. The "representation learning" head captures fine-grained patterns of objects at the instance level which serve as clues for the "clustering" head to extract coarse-grain information that separates objects into clusters. The whole model is trained in an end-to-end manner by minimizing the weighted sum of two sample-oriented contrastive losses applied to the outputs of the two heads. To ensure that the contrastive loss corresponding to the "clustering" head is optimal, we introduce a novel critic function called "log-of-dot-product". Extensive experimental results demonstrate that our method significantly outperforms state-of-the-art single-stage clustering methods across a variety of image datasets, improving over the best baseline by about 5-7% in accuracy on CIFAR10/20, STL10, and ImageNet-Dogs. Further, the "two-stage" variant of our method also achieves better results than baselines on three challenging ImageNet subsets.
Hierarchical Object-oriented Spatio-Temporal Reasoning for Video Question Answering
Jun 25, 2021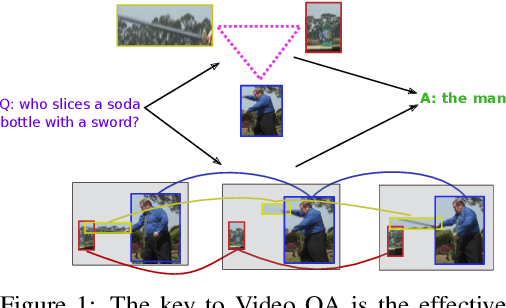
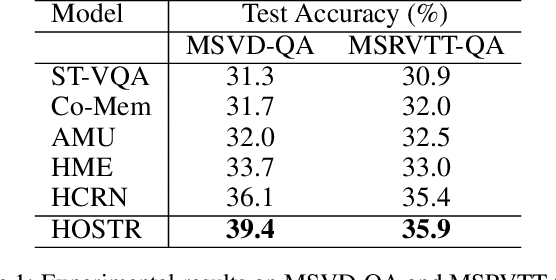
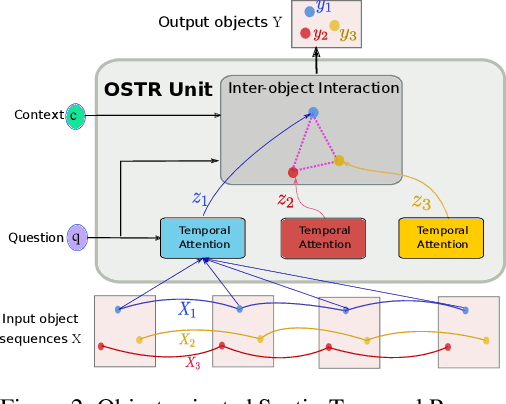
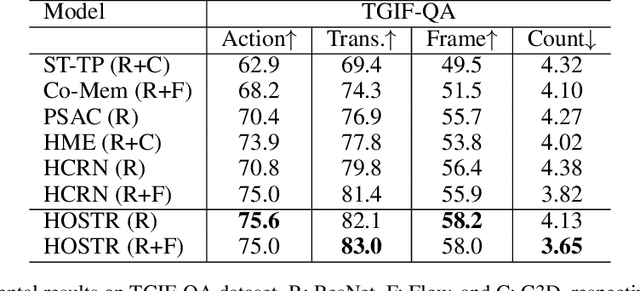
Video Question Answering (Video QA) is a powerful testbed to develop new AI capabilities. This task necessitates learning to reason about objects, relations, and events across visual and linguistic domains in space-time. High-level reasoning demands lifting from associative visual pattern recognition to symbol-like manipulation over objects, their behavior and interactions. Toward reaching this goal we propose an object-oriented reasoning approach in that video is abstracted as a dynamic stream of interacting objects. At each stage of the video event flow, these objects interact with each other, and their interactions are reasoned about with respect to the query and under the overall context of a video. This mechanism is materialized into a family of general-purpose neural units and their multi-level architecture called Hierarchical Object-oriented Spatio-Temporal Reasoning (HOSTR) networks. This neural model maintains the objects' consistent lifelines in the form of a hierarchically nested spatio-temporal graph. Within this graph, the dynamic interactive object-oriented representations are built up along the video sequence, hierarchically abstracted in a bottom-up manner, and converge toward the key information for the correct answer. The method is evaluated on multiple major Video QA datasets and establishes new state-of-the-arts in these tasks. Analysis into the model's behavior indicates that object-oriented reasoning is a reliable, interpretable and efficient approach to Video QA.
A Spatio-temporal Attention-based Model for Infant Movement Assessment from Videos
May 20, 2021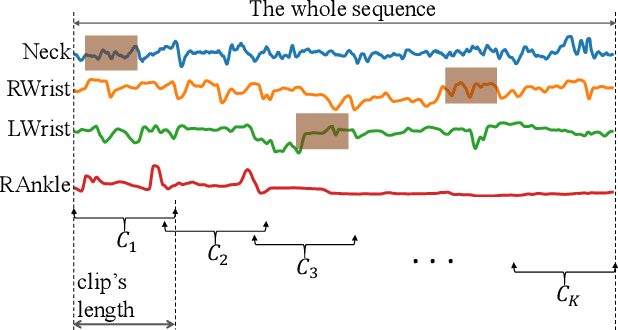
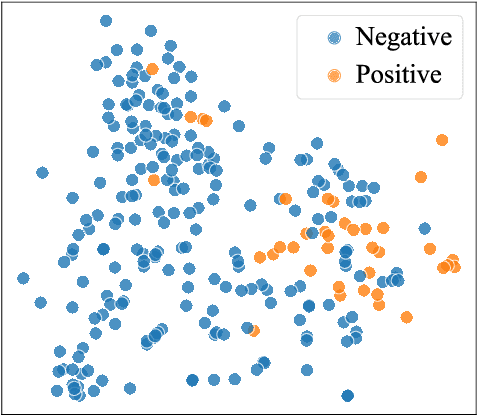
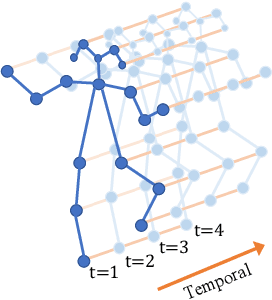

The absence or abnormality of fidgety movements of joints or limbs is strongly indicative of cerebral palsy in infants. Developing computer-based methods for assessing infant movements in videos is pivotal for improved cerebral palsy screening. Most existing methods use appearance-based features and are thus sensitive to strong but irrelevant signals caused by background clutter or a moving camera. Moreover, these features are computed over the whole frame, thus they measure gross whole body movements rather than specific joint/limb motion. Addressing these challenges, we develop and validate a new method for fidgety movement assessment from consumer-grade videos using human poses extracted from short clips. Human poses capture only relevant motion profiles of joints and limbs and are thus free from irrelevant appearance artifacts. The dynamics and coordination between joints are modeled using spatio-temporal graph convolutional networks. Frames and body parts that contain discriminative information about fidgety movements are selected through a spatio-temporal attention mechanism. We validate the proposed model on the cerebral palsy screening task using a real-life consumer-grade video dataset collected at an Australian hospital through the Cerebral Palsy Alliance, Australia. Our experiments show that the proposed method achieves the ROC-AUC score of 81.87%, significantly outperforming existing competing methods with better interpretability.
Object-Centric Representation Learning for Video Question Answering
Apr 13, 2021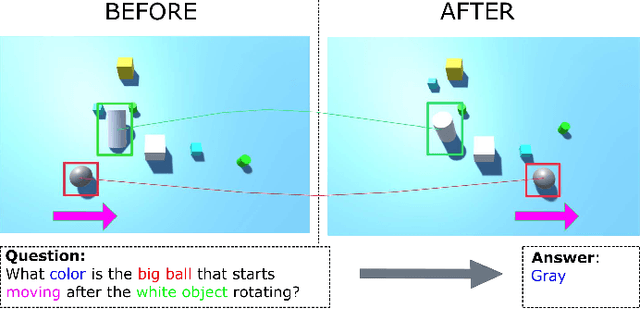
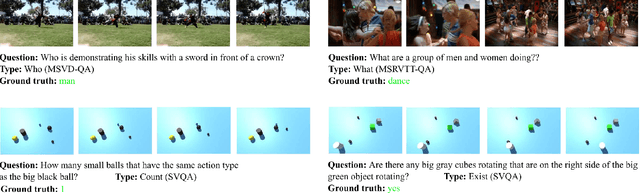
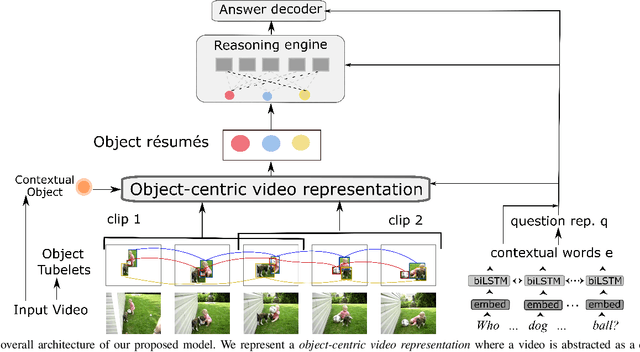
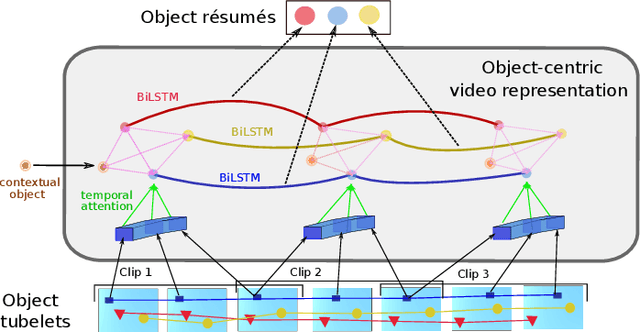
Video question answering (Video QA) presents a powerful testbed for human-like intelligent behaviors. The task demands new capabilities to integrate video processing, language understanding, binding abstract linguistic concepts to concrete visual artifacts, and deliberative reasoning over spacetime. Neural networks offer a promising approach to reach this potential through learning from examples rather than handcrafting features and rules. However, neural networks are predominantly feature-based - they map data to unstructured vectorial representation and thus can fall into the trap of exploiting shortcuts through surface statistics instead of true systematic reasoning seen in symbolic systems. To tackle this issue, we advocate for object-centric representation as a basis for constructing spatio-temporal structures from videos, essentially bridging the semantic gap between low-level pattern recognition and high-level symbolic algebra. To this end, we propose a new query-guided representation framework to turn a video into an evolving relational graph of objects, whose features and interactions are dynamically and conditionally inferred. The object lives are then summarized into resumes, lending naturally for deliberative relational reasoning that produces an answer to the query. The framework is evaluated on major Video QA datasets, demonstrating clear benefits of the object-centric approach to video reasoning.