 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBootstrapping Monte Carlo Tree Search with an Imperfect Heuristic
Jun 26, 2012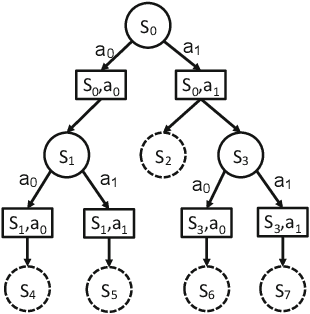
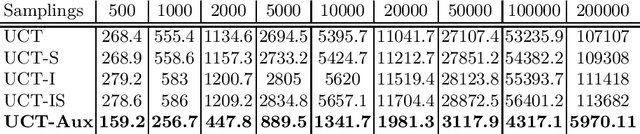
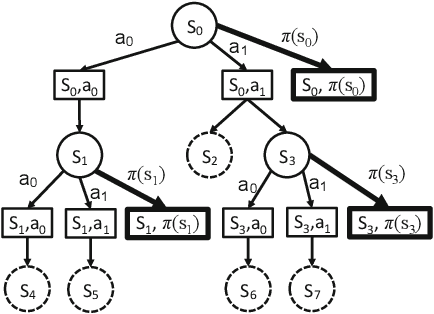
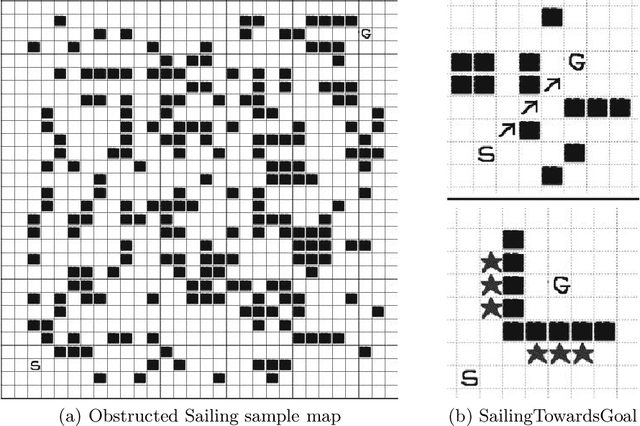
We consider the problem of using a heuristic policy to improve the value approximation by the Upper Confidence Bound applied in Trees (UCT) algorithm in non-adversarial settings such as planning with large-state space Markov Decision Processes. Current improvements to UCT focus on either changing the action selection formula at the internal nodes or the rollout policy at the leaf nodes of the search tree. In this work, we propose to add an auxiliary arm to each of the internal nodes, and always use the heuristic policy to roll out simulations at the auxiliary arms. The method aims to get fast convergence to optimal values at states where the heuristic policy is optimal, while retaining similar approximation as the original UCT in other states. We show that bootstrapping with the proposed method in the new algorithm, UCT-Aux, performs better compared to the original UCT algorithm and its variants in two benchmark experiment settings. We also examine conditions under which UCT-Aux works well.
CAPIR: Collaborative Action Planning with Intention Recognition
Jun 26, 2012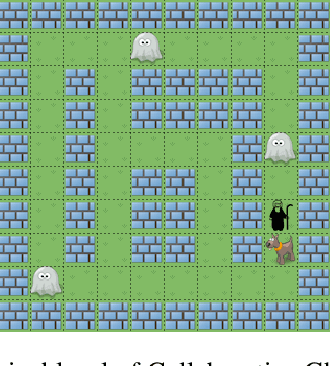
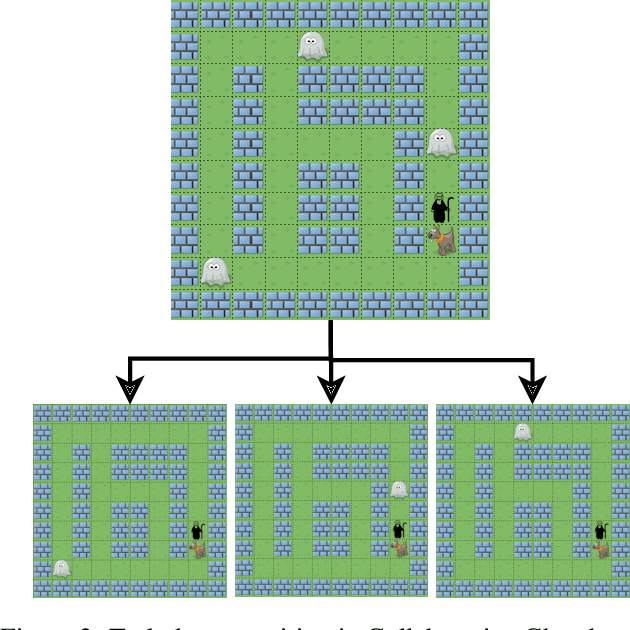
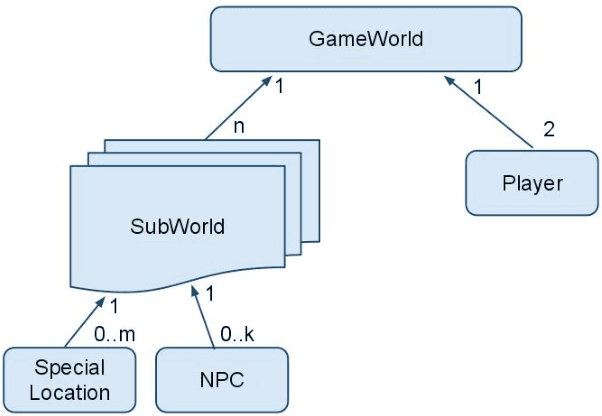
We apply decision theoretic techniques to construct non-player characters that are able to assist a human player in collaborative games. The method is based on solving Markov decision processes, which can be difficult when the game state is described by many variables. To scale to more complex games, the method allows decomposition of a game task into subtasks, each of which can be modelled by a Markov decision process. Intention recognition is used to infer the subtask that the human is currently performing, allowing the helper to assist the human in performing the correct task. Experiments show that the method can be effective, giving near-human level performance in helping a human in a collaborative game.