 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDetecting (Un)answerability in Large Language Models with Linear Directions
Sep 26, 2025



Large language models (LLMs) often respond confidently to questions even when they lack the necessary information, leading to hallucinated answers. In this work, we study the problem of (un)answerability detection, focusing on extractive question answering (QA) where the model should determine if a passage contains sufficient information to answer a given question. We propose a simple approach for identifying a direction in the model's activation space that captures unanswerability and uses it for classification. This direction is selected by applying activation additions during inference and measuring their impact on the model's abstention behavior. We show that projecting hidden activations onto this direction yields a reliable score for (un)answerability classification. Experiments on two open-weight LLMs and four extractive QA benchmarks show that our method effectively detects unanswerable questions and generalizes better across datasets than existing prompt-based and classifier-based approaches. Moreover, the obtained directions extend beyond extractive QA to unanswerability that stems from factors, such as lack of scientific consensus and subjectivity. Last, causal interventions show that adding or ablating the directions effectively controls the abstention behavior of the model.
Explaining Queries over Web Tables to Non-Experts
Aug 14, 2018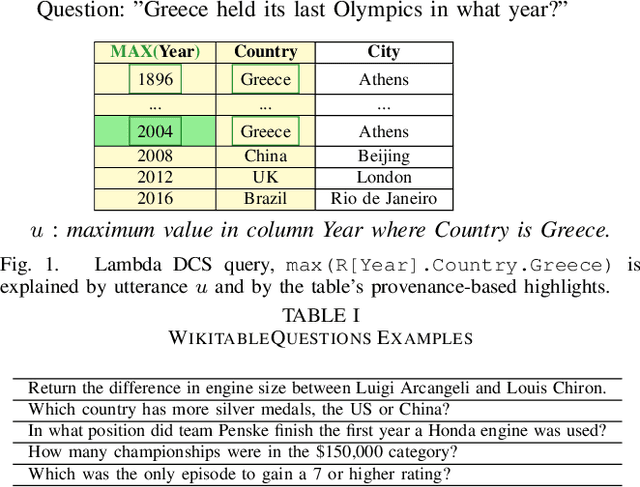
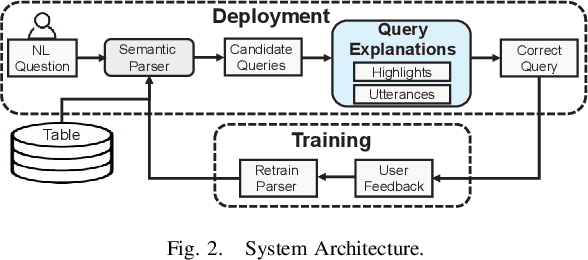
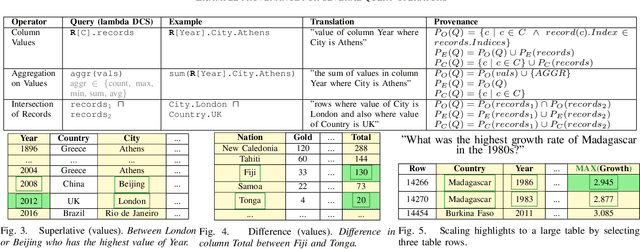
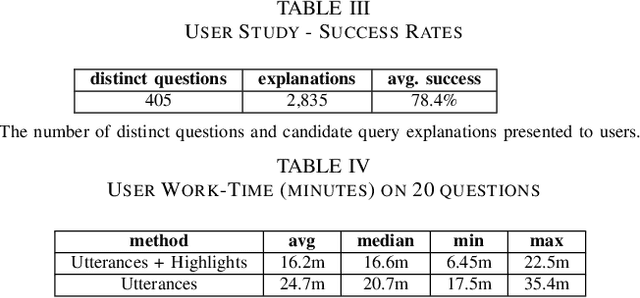
Designing a reliable natural language (NL) interface for querying tables has been a longtime goal of researchers in both the data management and natural language processing (NLP) communities. Such an interface receives as input an NL question, translates it into a formal query, executes the query and returns the results. Errors in the translation process are not uncommon, and users typically struggle to understand whether their query has been mapped correctly. We address this problem by explaining the obtained formal queries to non-expert users. Two methods for query explanations are presented: the first translates queries into NL, while the second method provides a graphic representation of the query cell-based provenance (in its execution on a given table). Our solution augments a state-of-the-art NL interface over web tables, enhancing it in both its training and deployment phase. Experiments, including a user study conducted on Amazon Mechanical Turk, show our solution to improve both the correctness and reliability of an NL interface.