 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFine-Grained Image Style Transfer with Visual Transformers
Oct 11, 2022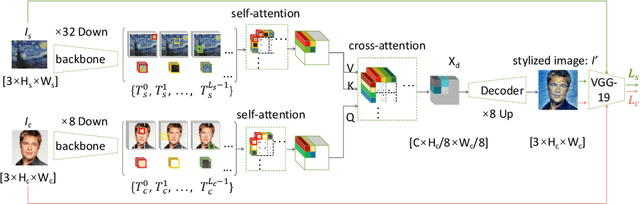
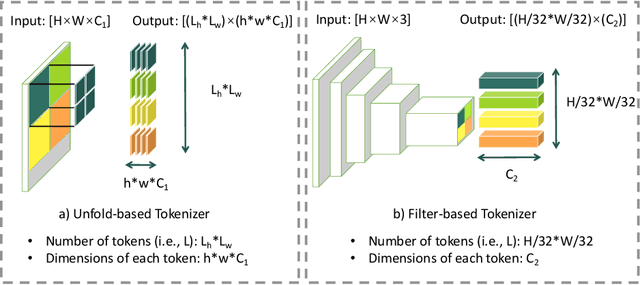

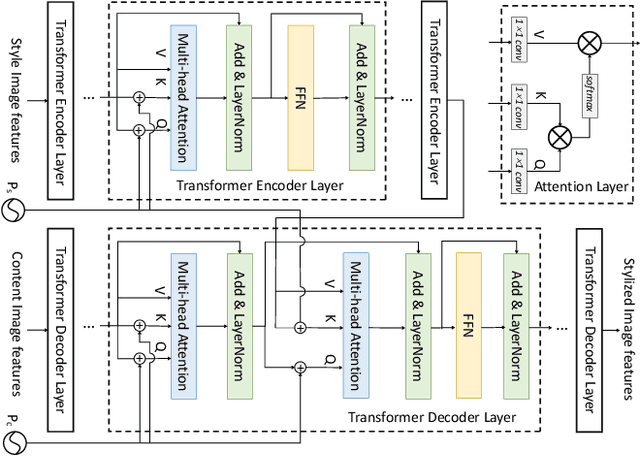
With the development of the convolutional neural network, image style transfer has drawn increasing attention. However, most existing approaches adopt a global feature transformation to transfer style patterns into content images (e.g., AdaIN and WCT). Such a design usually destroys the spatial information of the input images and fails to transfer fine-grained style patterns into style transfer results. To solve this problem, we propose a novel STyle TRansformer (STTR) network which breaks both content and style images into visual tokens to achieve a fine-grained style transformation. Specifically, two attention mechanisms are adopted in our STTR. We first propose to use self-attention to encode content and style tokens such that similar tokens can be grouped and learned together. We then adopt cross-attention between content and style tokens that encourages fine-grained style transformations. To compare STTR with existing approaches, we conduct user studies on Amazon Mechanical Turk (AMT), which are carried out with 50 human subjects with 1,000 votes in total. Extensive evaluations demonstrate the effectiveness and efficiency of the proposed STTR in generating visually pleasing style transfer results.
Improving Robustness to Out-of-Distribution Data by Frequency-based Augmentation
Sep 06, 2022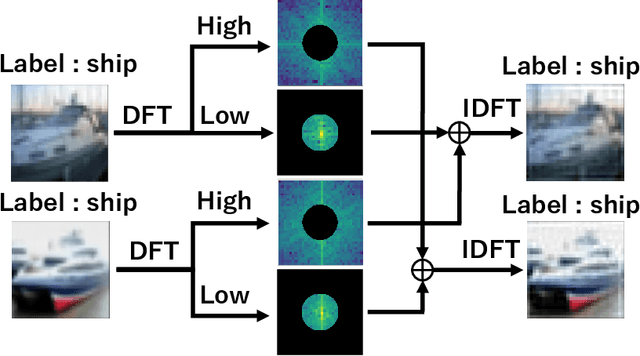
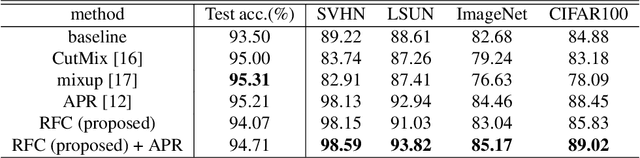
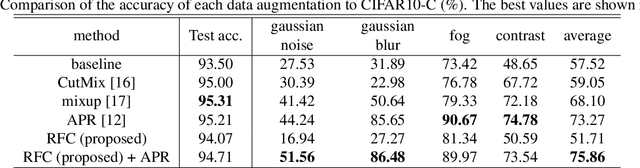
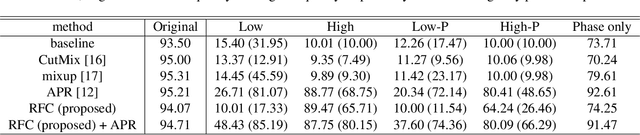
Although Convolutional Neural Networks (CNNs) have high accuracy in image recognition, they are vulnerable to adversarial examples and out-of-distribution data, and the difference from human recognition has been pointed out. In order to improve the robustness against out-of-distribution data, we present a frequency-based data augmentation technique that replaces the frequency components with other images of the same class. When the training data are CIFAR10 and the out-of-distribution data are SVHN, the Area Under Receiver Operating Characteristic (AUROC) curve of the model trained with the proposed method increases from 89.22\% to 98.15\%, and further increased to 98.59\% when combined with another data augmentation method. Furthermore, we experimentally demonstrate that the robust model for out-of-distribution data uses a lot of high-frequency components of the image.
Prediction of Seismic Intensity Distributions Using Neural Networks
Aug 16, 2022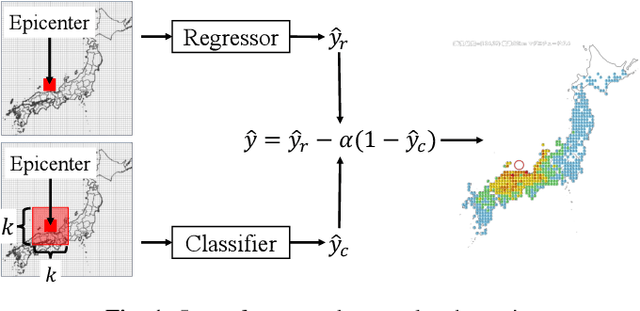
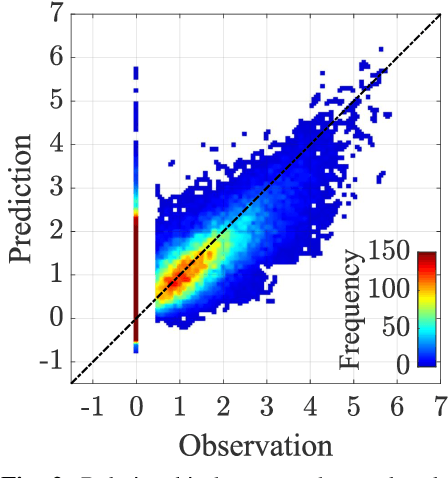
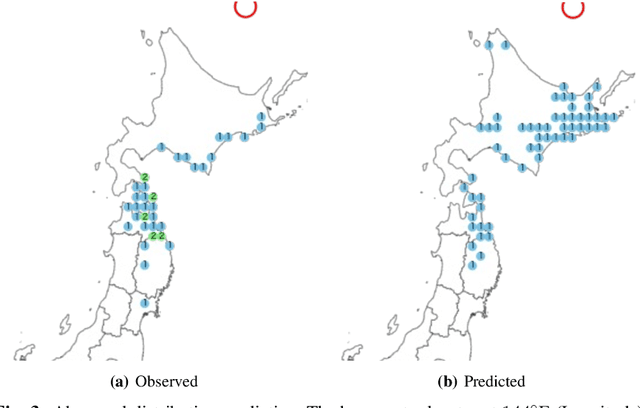
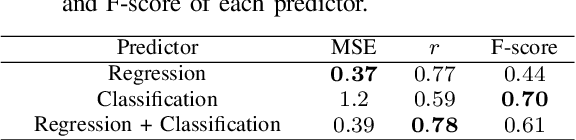
The ground motion prediction equation is commonly used to predict the seismic intensity distribution. However, it is not easy to apply this method to seismic distributions affected by underground plate structures, which are commonly known as abnormal seismic distributions. This study proposes a hybrid of regression and classification approaches using neural networks. The proposed model treats the distributions as 2-dimensional data like an image. Our method can accurately predict seismic intensity distributions, even abnormal distributions.
SAT: Self-adaptive training for fashion compatibility prediction
Jun 25, 2022
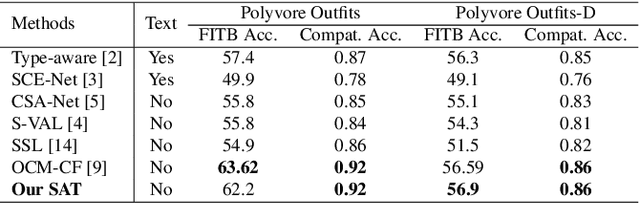
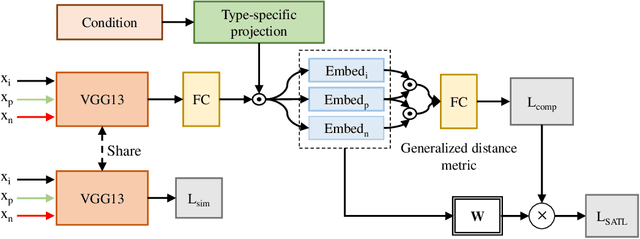

This paper presents a self-adaptive training (SAT) model for fashion compatibility prediction. It focuses on the learning of some hard items, such as those that share similar color, texture, and pattern features but are considered incompatible due to the aesthetics or temporal shifts. Specifically, we first design a method to define hard outfits and a difficulty score (DS) is defined and assigned to each outfit based on the difficulty in recommending an item for it. Then, we propose a self-adaptive triplet loss (SATL), where the DS of the outfit is considered. Finally, we propose a very simple conditional similarity network combining the proposed SATL to achieve the learning of hard items in the fashion compatibility prediction. Experiments on the publicly available Polyvore Outfits and Polyvore Outfits-D datasets demonstrate our SAT's effectiveness in fashion compatibility prediction. Besides, our SATL can be easily extended to other conditional similarity networks to improve their performance.
Superclass Adversarial Attack
May 29, 2022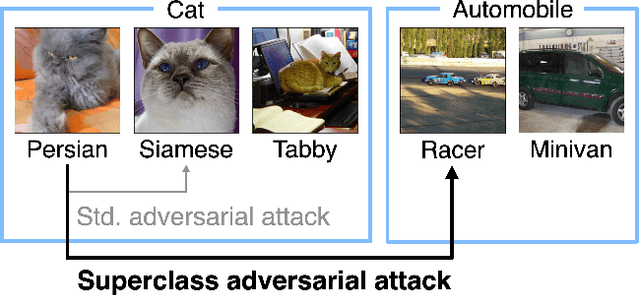
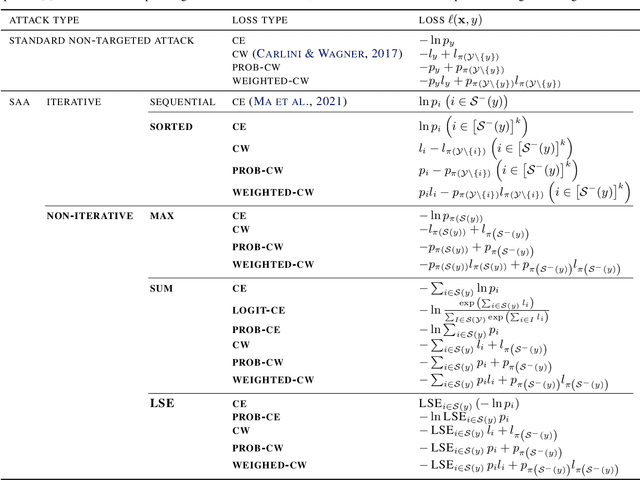

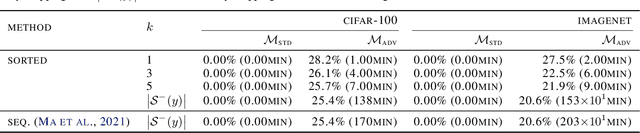
Adversarial attacks have only focused on changing the predictions of the classifier, but their danger greatly depends on how the class is mistaken. For example, when an automatic driving system mistakes a Persian cat for a Siamese cat, it is hardly a problem. However, if it mistakes a cat for a 120km/h minimum speed sign, serious problems can arise. As a stepping stone to more threatening adversarial attacks, we consider the superclass adversarial attack, which causes misclassification of not only fine classes, but also superclasses. We conducted the first comprehensive analysis of superclass adversarial attacks (an existing and 19 new methods) in terms of accuracy, speed, and stability, and identified several strategies to achieve better performance. Although this study is aimed at superclass misclassification, the findings can be applied to other problem settings involving multiple classes, such as top-k and multi-label classification attacks.
Green Hierarchical Vision Transformer for Masked Image Modeling
May 26, 2022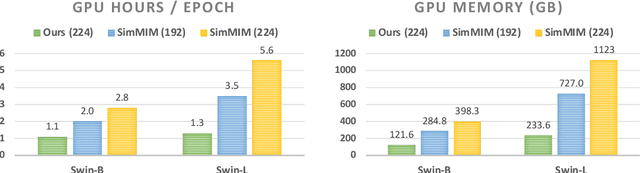
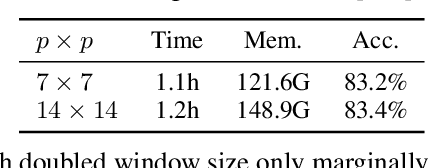
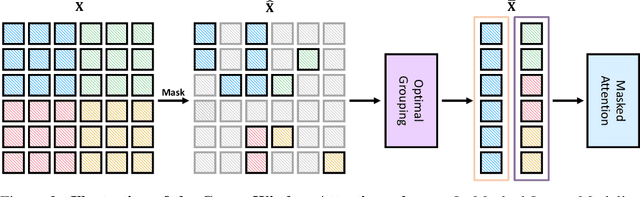
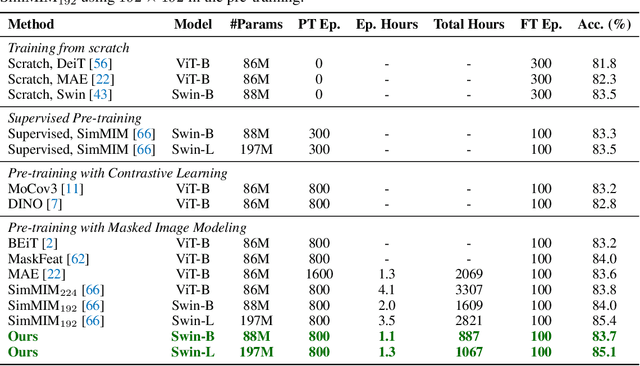
We present an efficient approach for Masked Image Modeling (MIM) with hierarchical Vision Transformers (ViTs), e.g., Swin Transformer, allowing the hierarchical ViTs to discard masked patches and operate only on the visible ones. Our approach consists of two key components. First, for the window attention, we design a Group Window Attention scheme following the Divide-and-Conquer strategy. To mitigate the quadratic complexity of the self-attention w.r.t. the number of patches, group attention encourages a uniform partition that visible patches within each local window of arbitrary size can be grouped with equal size, where masked self-attention is then performed within each group. Second, we further improve the grouping strategy via the Dynamic Programming algorithm to minimize the overall computation cost of the attention on the grouped patches. As a result, MIM now can work on hierarchical ViTs in a green and efficient way. For example, we can train the hierarchical ViTs about 2.7$\times$ faster and reduce the GPU memory usage by 70%, while still enjoying competitive performance on ImageNet classification and the superiority on downstream COCO object detection benchmarks. Code and pre-trained models have been made publicly available at https://github.com/LayneH/GreenMIM.
Detecting Deepfakes with Self-Blended Images
Apr 18, 2022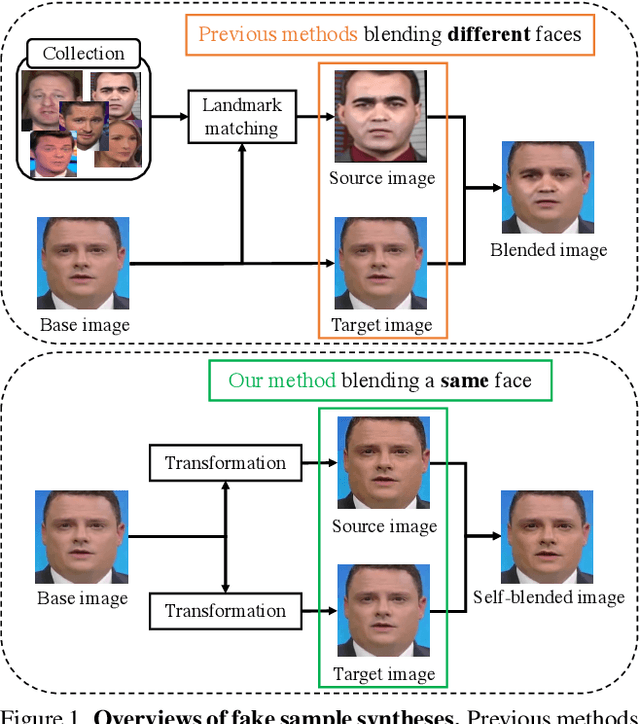
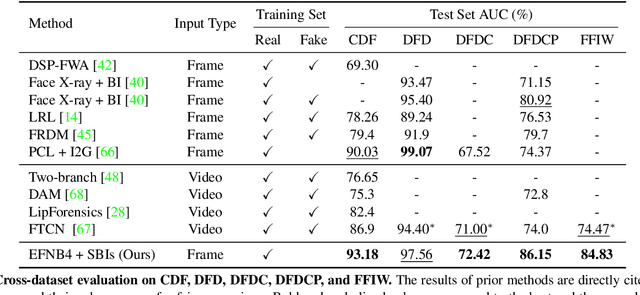

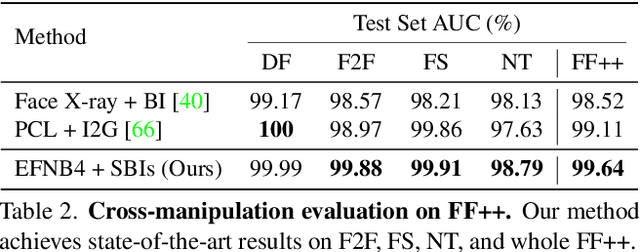
In this paper, we present novel synthetic training data called self-blended images (SBIs) to detect deepfakes. SBIs are generated by blending pseudo source and target images from single pristine images, reproducing common forgery artifacts (e.g., blending boundaries and statistical inconsistencies between source and target images). The key idea behind SBIs is that more general and hardly recognizable fake samples encourage classifiers to learn generic and robust representations without overfitting to manipulation-specific artifacts. We compare our approach with state-of-the-art methods on FF++, CDF, DFD, DFDC, DFDCP, and FFIW datasets by following the standard cross-dataset and cross-manipulation protocols. Extensive experiments show that our method improves the model generalization to unknown manipulations and scenes. In particular, on DFDC and DFDCP where existing methods suffer from the domain gap between the training and test sets, our approach outperforms the baseline by 4.90% and 11.78% points in the cross-dataset evaluation, respectively.
Learning Where to Learn in Cross-View Self-Supervised Learning
Mar 28, 2022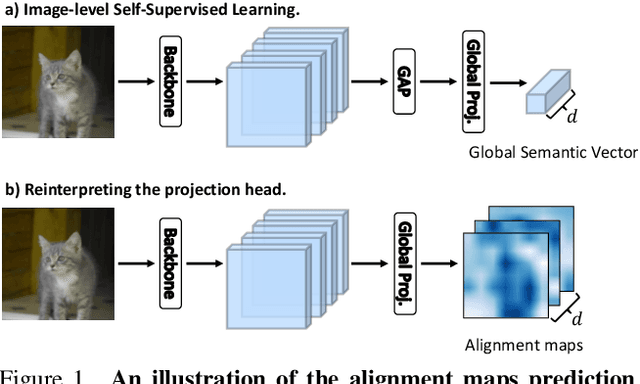
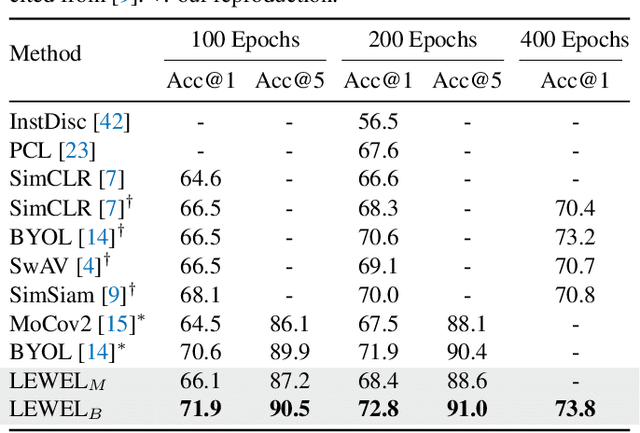
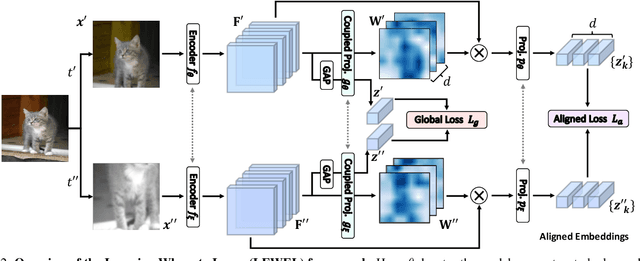
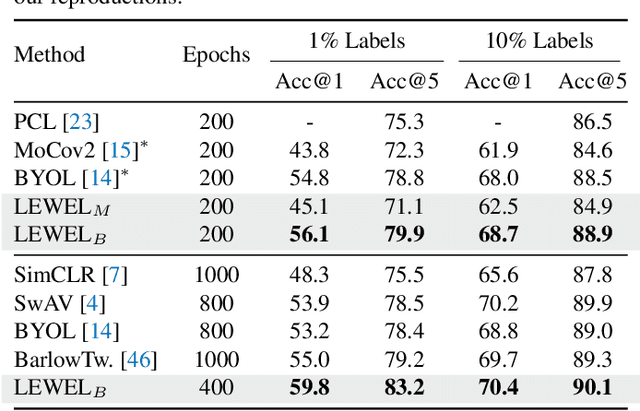
Self-supervised learning (SSL) has made enormous progress and largely narrowed the gap with the supervised ones, where the representation learning is mainly guided by a projection into an embedding space. During the projection, current methods simply adopt uniform aggregation of pixels for embedding; however, this risks involving object-irrelevant nuisances and spatial misalignment for different augmentations. In this paper, we present a new approach, Learning Where to Learn (LEWEL), to adaptively aggregate spatial information of features, so that the projected embeddings could be exactly aligned and thus guide the feature learning better. Concretely, we reinterpret the projection head in SSL as a per-pixel projection and predict a set of spatial alignment maps from the original features by this weight-sharing projection head. A spectrum of aligned embeddings is thus obtained by aggregating the features with spatial weighting according to these alignment maps. As a result of this adaptive alignment, we observe substantial improvements on both image-level prediction and dense prediction at the same time: LEWEL improves MoCov2 by 1.6%/1.3%/0.5%/0.4% points, improves BYOL by 1.3%/1.3%/0.7%/0.6% points, on ImageNet linear/semi-supervised classification, Pascal VOC semantic segmentation, and object detection, respectively.
Edge-Level Explanations for Graph Neural Networks by Extending Explainability Methods for Convolutional Neural Networks
Nov 01, 2021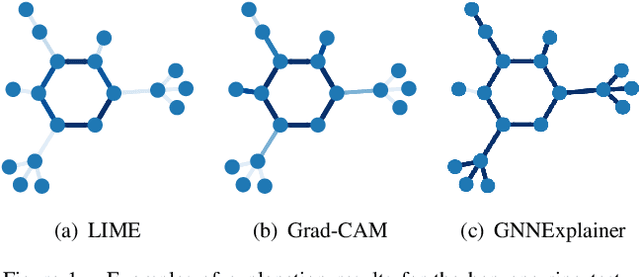
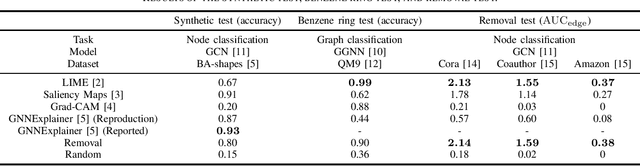

Graph Neural Networks (GNNs) are deep learning models that take graph data as inputs, and they are applied to various tasks such as traffic prediction and molecular property prediction. However, owing to the complexity of the GNNs, it has been difficult to analyze which parts of inputs affect the GNN model's outputs. In this study, we extend explainability methods for Convolutional Neural Networks (CNNs), such as Local Interpretable Model-Agnostic Explanations (LIME), Gradient-Based Saliency Maps, and Gradient-Weighted Class Activation Mapping (Grad-CAM) to GNNs, and predict which edges in the input graphs are important for GNN decisions. The experimental results indicate that the LIME-based approach is the most efficient explainability method for multiple tasks in the real-world situation, outperforming even the state-of-the-art method in GNN explainability.
Unsupervised Video Person Re-identification via Noise and Hard frame Aware Clustering
Jun 10, 2021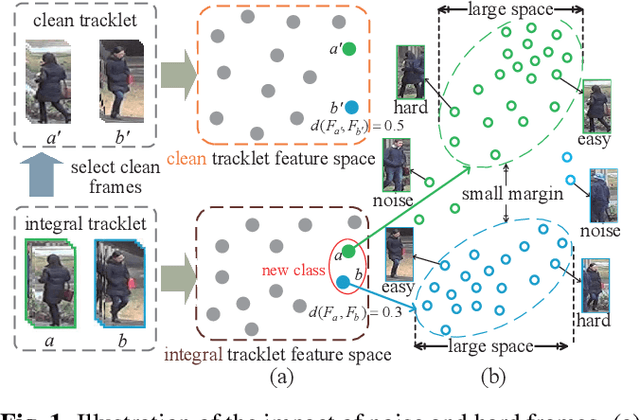
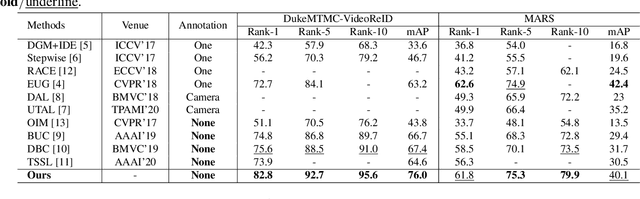
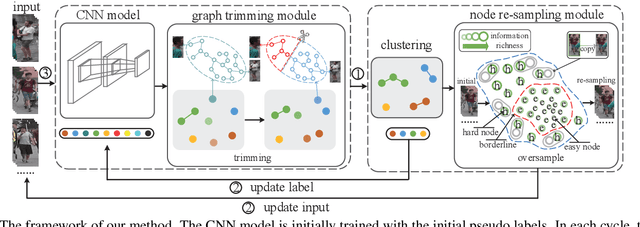
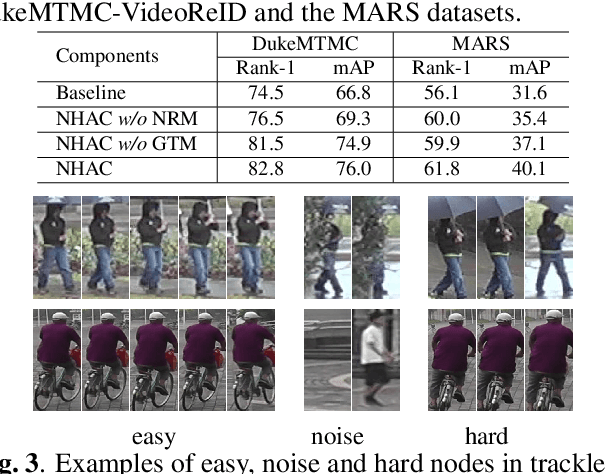
Unsupervised video-based person re-identification (re-ID) methods extract richer features from video tracklets than image-based ones. The state-of-the-art methods utilize clustering to obtain pseudo-labels and train the models iteratively. However, they underestimate the influence of two kinds of frames in the tracklet: 1) noise frames caused by detection errors or heavy occlusions exist in the tracklet, which may be allocated with unreliable labels during clustering; 2) the tracklet also contains hard frames caused by pose changes or partial occlusions, which are difficult to distinguish but informative. This paper proposes a Noise and Hard frame Aware Clustering (NHAC) method. NHAC consists of a graph trimming module and a node re-sampling module. The graph trimming module obtains stable graphs by removing noise frame nodes to improve the clustering accuracy. The node re-sampling module enhances the training of hard frame nodes to learn rich tracklet information. Experiments conducted on two video-based datasets demonstrate the effectiveness of the proposed NHAC under the unsupervised re-ID setting.