 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptivity, Variance and Separation for Adversarial Bandits
Mar 19, 2019
We make three contributions to the theory of k-armed adversarial bandits. First, we prove a first-order bound for a modified variant of the INF strategy by Audibert and Bubeck [2009], without sacrificing worst case optimality or modifying the loss estimators. Second, we provide a variance analysis for algorithms based on follow the regularised leader, showing that without adaptation the variance of the regret is typically {\Omega}(n^2) where n is the horizon. Finally, we study bounds that depend on the degree of separation of the arms, generalising the results by Cowan and Katehakis [2015] from the stochastic setting to the adversarial and improving the result of Seldin and Slivkins [2014] by a factor of log(n)/log(log(n)).
An Information-Theoretic Approach to Minimax Regret in Partial Monitoring
Feb 01, 2019
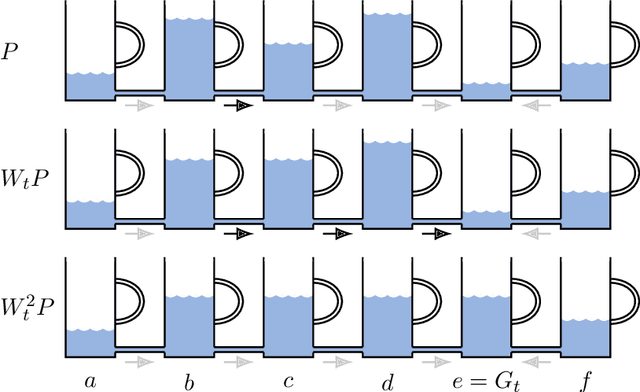

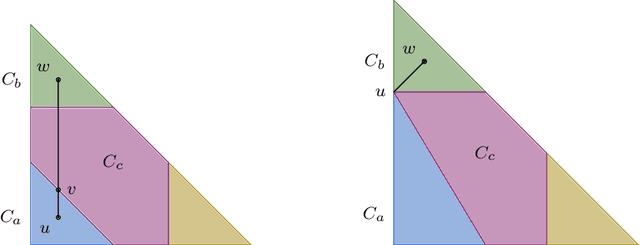
We prove a new minimax theorem connecting the worst-case Bayesian regret and minimax regret under partial monitoring with no assumptions on the space of signals or decisions of the adversary. We then generalise the information-theoretic tools of Russo and Van Roy (2016) for proving Bayesian regret bounds and combine them with the minimax theorem to derive minimax regret bounds for various partial monitoring settings. The highlight is a clean analysis of `non-degenerate easy' and `hard' finite partial monitoring, with new regret bounds that are independent of arbitrarily large game-dependent constants. The power of the generalised machinery is further demonstrated by proving that the minimax regret for k-armed adversarial bandits is at most sqrt{2kn}, improving on existing results by a factor of 2. Finally, we provide a simple analysis of the cops and robbers game, also improving best known constants.
A Geometric Perspective on Optimal Representations for Reinforcement Learning
Jan 31, 2019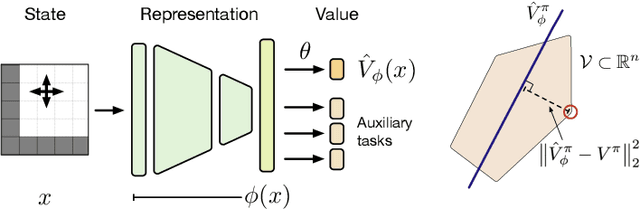
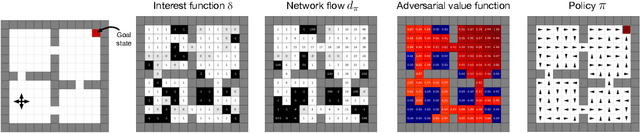
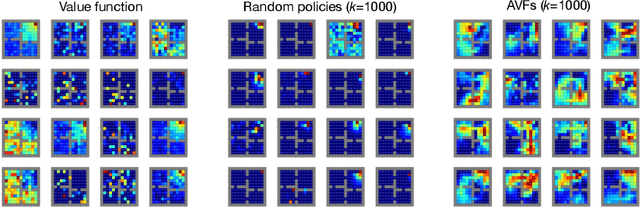
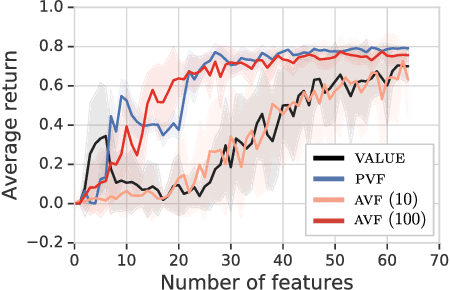
This paper proposes a new approach to representation learning based on geometric properties of the space of value functions. We study a two-part approximation of the value function: a nonlinear map from states to vectors, or representation, followed by a linear map from vectors to values. Our formulation considers adapting the representation to minimize the (linear) approximation of the value function of all stationary policies for a given environment. We show that this optimization reduces to making accurate predictions regarding a special class of value functions which we call adversarial value functions (AVFs). We argue that these AVFs make excellent auxiliary tasks, and use them to construct a loss which can be efficiently minimized to find a near-optimal representation for reinforcement learning. We highlight characteristics of the method in a series of experiments on the four-room domain.
Soft-Bayes: Prod for Mixtures of Experts with Log-Loss
Jan 08, 2019We consider prediction with expert advice under the log-loss with the goal of deriving efficient and robust algorithms. We argue that existing algorithms such as exponentiated gradient, online gradient descent and online Newton step do not adequately satisfy both requirements. Our main contribution is an analysis of the Prod algorithm that is robust to any data sequence and runs in linear time relative to the number of experts in each round. Despite the unbounded nature of the log-loss, we derive a bound that is independent of the largest loss and of the largest gradient, and depends only on the number of experts and the time horizon. Furthermore we give a Bayesian interpretation of Prod and adapt the algorithm to derive a tracking regret.
Single-Agent Policy Tree Search With Guarantees
Nov 28, 2018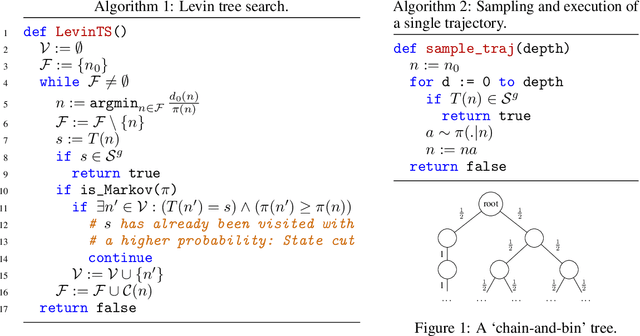
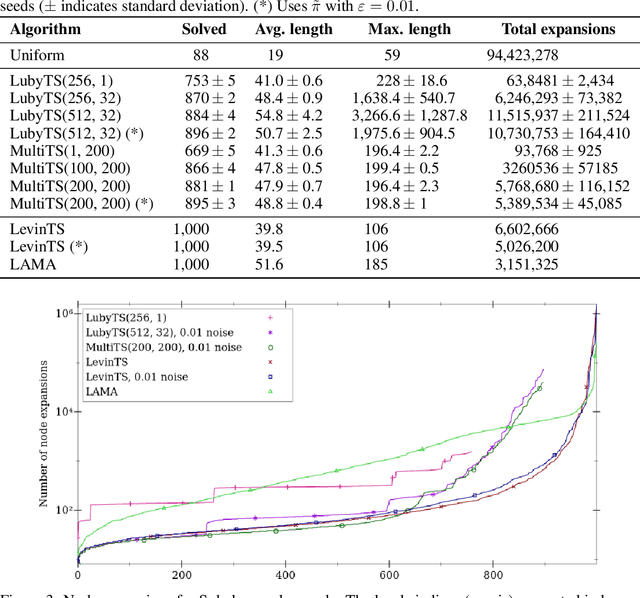
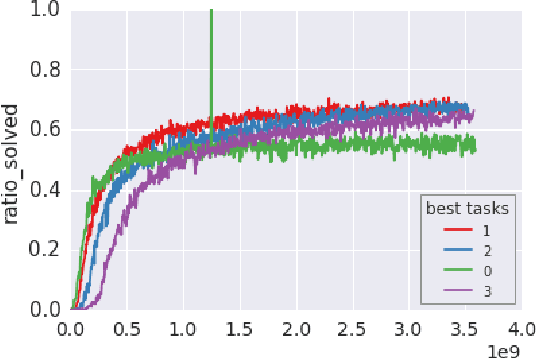
We introduce two novel tree search algorithms that use a policy to guide search. The first algorithm is a best-first enumeration that uses a cost function that allows us to prove an upper bound on the number of nodes to be expanded before reaching a goal state. We show that this best-first algorithm is particularly well suited for `needle-in-a-haystack' problems. The second algorithm is based on sampling and we prove an upper bound on the expected number of nodes it expands before reaching a set of goal states. We show that this algorithm is better suited for problems where many paths lead to a goal. We validate these tree search algorithms on 1,000 computer-generated levels of Sokoban, where the policy used to guide the search comes from a neural network trained using A3C. Our results show that the policy tree search algorithms we introduce are competitive with a state-of-the-art domain-independent planner that uses heuristic search.
Garbage In, Reward Out: Bootstrapping Exploration in Multi-Armed Bandits
Nov 13, 2018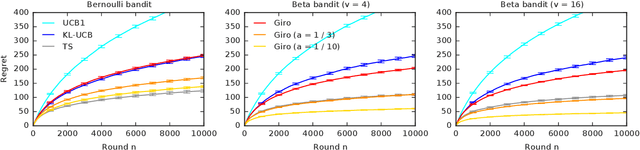
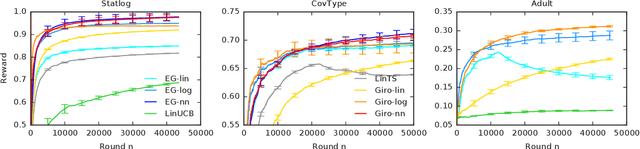
We propose a multi-armed bandit algorithm that explores based on randomizing its history. The key idea is to estimate the value of the arm from the bootstrap sample of its history, where we add pseudo observations after each pull of the arm. The pseudo observations seem to be harmful. But on the contrary, they guarantee that the bootstrap sample is optimistic with a high probability. Because of this, we call our algorithm Giro, which is an abbreviation for garbage in, reward out. We analyze Giro in a $K$-armed Bernoulli bandit and prove a $O(K \Delta^{-1} \log n)$ bound on its $n$-round regret, where $\Delta$ denotes the difference in the expected rewards of the optimal and best suboptimal arms. The main advantage of our exploration strategy is that it can be applied to any reward function generalization, such as neural networks. We evaluate Giro and its contextual variant on multiple synthetic and real-world problems, and observe that Giro is comparable to or better than state-of-the-art algorithms.
BubbleRank: Safe Online Learning to Rerank
Jun 15, 2018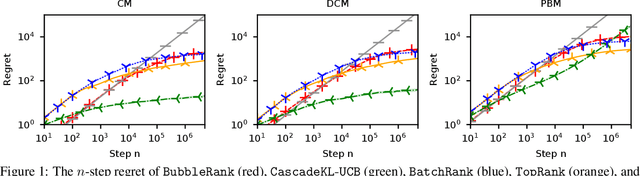
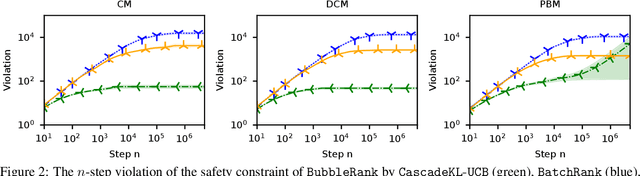
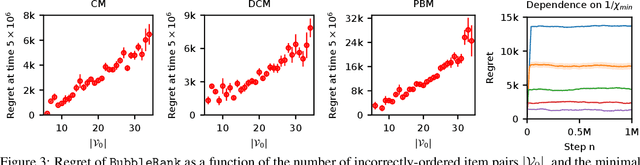
We study the problem of online learning to re-rank, where users provide feedback to improve the quality of displayed lists. Learning to rank has been traditionally studied in two settings. In the offline setting, rankers are typically learned from relevance labels of judges. These approaches have become the industry standard. However, they lack exploration, and thus are limited by the information content of offline data. In the online setting, an algorithm can propose a list and learn from the feedback on it in a sequential fashion. Bandit algorithms developed for this setting actively experiment, and in this way overcome the biases of offline data. But they also tend to ignore offline data, which results in a high initial cost of exploration. We propose BubbleRank, a bandit algorithm for re-ranking that combines the strengths of both settings. The algorithm starts with an initial base list and improves it gradually by swapping higher-ranked less attractive items for lower-ranked more attractive items. We prove an upper bound on the n-step regret of BubbleRank that degrades gracefully with the quality of the initial base list. Our theoretical findings are supported by extensive numerical experiments on a large real-world click dataset.
TopRank: A practical algorithm for online stochastic ranking
Jun 06, 2018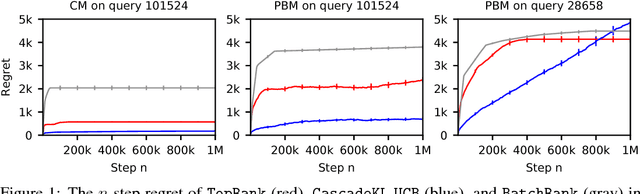
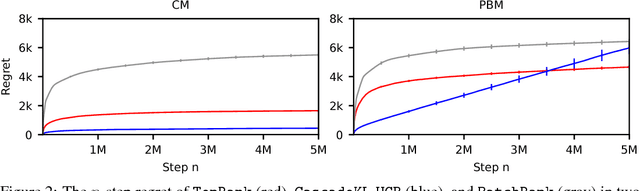
Online learning to rank is a sequential decision-making problem where in each round the learning agent chooses a list of items and receives feedback in the form of clicks from the user. Many sample-efficient algorithms have been proposed for this problem that assume a specific click model connecting rankings and user behavior. We propose a generalized click model that encompasses many existing models, including the position-based and cascade models. Our generalization motivates a novel online learning algorithm based on topological sort, which we call TopRank. TopRank is (a) more natural than existing algorithms, (b) has stronger regret guarantees than existing algorithms with comparable generality, (c) has a more insightful proof that leaves the door open to many generalizations, (d) outperforms existing algorithms empirically.
Cleaning up the neighborhood: A full classification for adversarial partial monitoring
May 23, 2018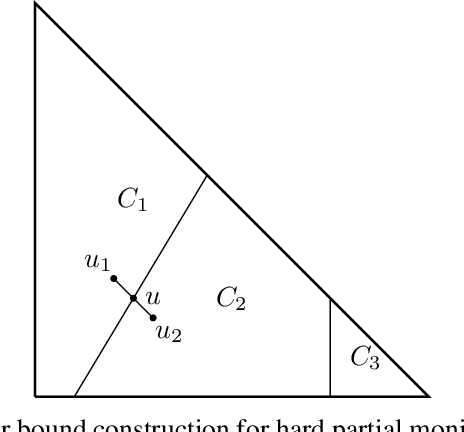
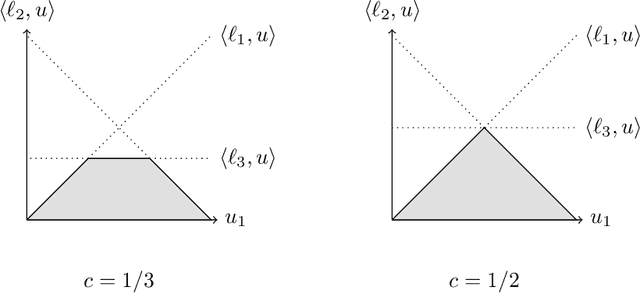
Partial monitoring is a generalization of the well-known multi-armed bandit framework where the loss is not directly observed by the learner. We complete the classification of finite adversarial partial monitoring to include all games, solving an open problem posed by Bartok et al. [2014]. Along the way we simplify and improve existing algorithms and correct errors in previous analyses. Our second contribution is a new algorithm for the class of games studied by Bartok [2013] where we prove upper and lower regret bounds that shed more light on the dependence of the regret on the game structure.
Unifying PAC and Regret: Uniform PAC Bounds for Episodic Reinforcement Learning
Jan 02, 2018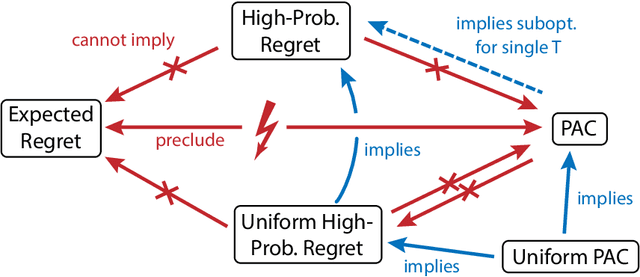
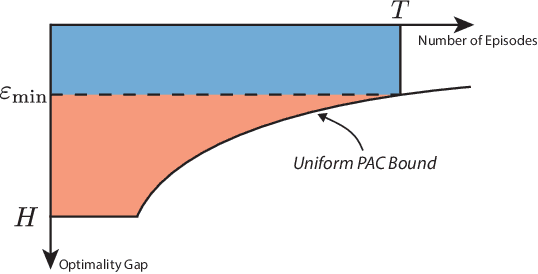
Statistical performance bounds for reinforcement learning (RL) algorithms can be critical for high-stakes applications like healthcare. This paper introduces a new framework for theoretically measuring the performance of such algorithms called Uniform-PAC, which is a strengthening of the classical Probably Approximately Correct (PAC) framework. In contrast to the PAC framework, the uniform version may be used to derive high probability regret guarantees and so forms a bridge between the two setups that has been missing in the literature. We demonstrate the benefits of the new framework for finite-state episodic MDPs with a new algorithm that is Uniform-PAC and simultaneously achieves optimal regret and PAC guarantees except for a factor of the horizon.