 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData-driven End-to-end Learning of Pole Placement Control for Nonlinear Dynamics via Koopman Invariant Subspaces
Aug 16, 2022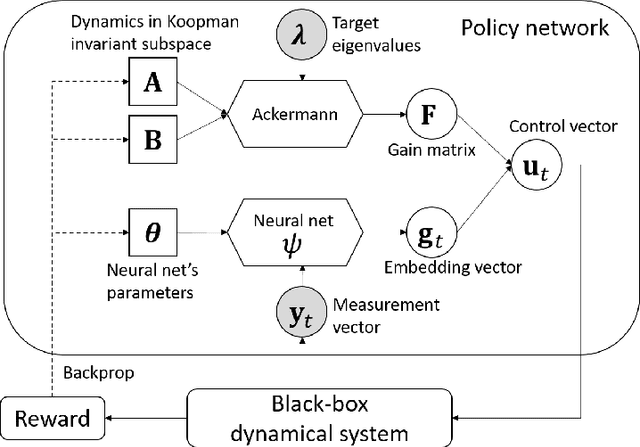

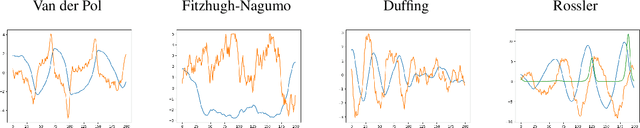
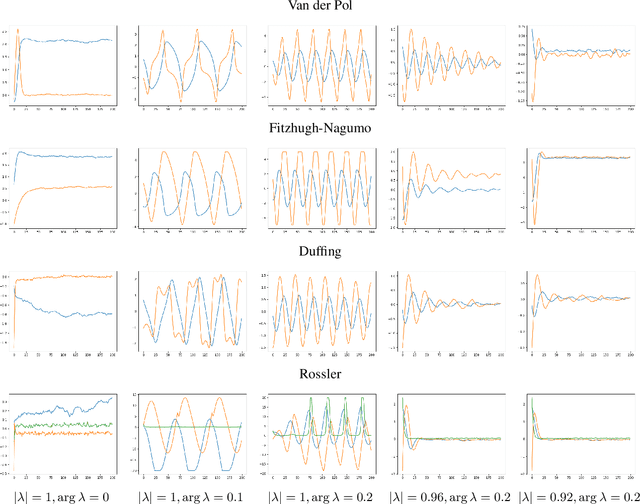
We propose a data-driven method for controlling the frequency and convergence rate of black-box nonlinear dynamical systems based on the Koopman operator theory. With the proposed method, a policy network is trained such that the eigenvalues of a Koopman operator of controlled dynamics are close to the target eigenvalues. The policy network consists of a neural network to find a Koopman invariant subspace, and a pole placement module to adjust the eigenvalues of the Koopman operator. Since the policy network is differentiable, we can train it in an end-to-end fashion using reinforcement learning. We demonstrate that the proposed method achieves better performance than model-free reinforcement learning and model-based control with system identification.
Predicting Opinion Dynamics via Sociologically-Informed Neural Networks
Jul 07, 2022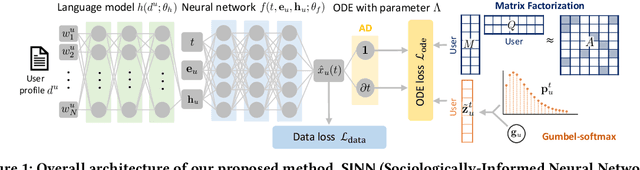

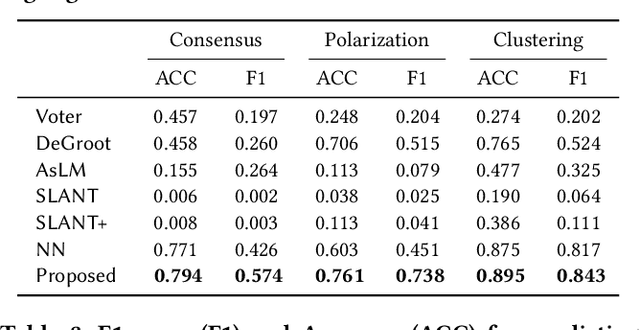
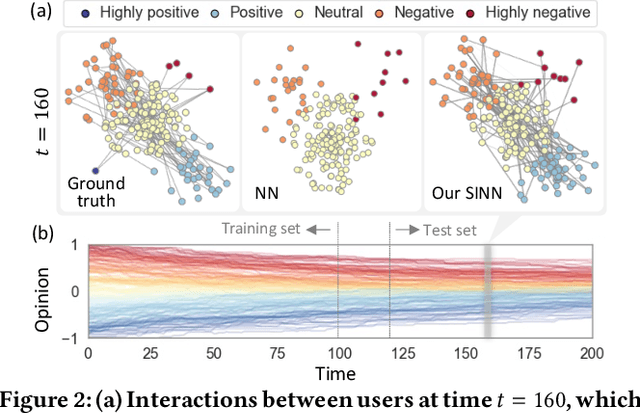
Opinion formation and propagation are crucial phenomena in social networks and have been extensively studied across several disciplines. Traditionally, theoretical models of opinion dynamics have been proposed to describe the interactions between individuals (i.e., social interaction) and their impact on the evolution of collective opinions. Although these models can incorporate sociological and psychological knowledge on the mechanisms of social interaction, they demand extensive calibration with real data to make reliable predictions, requiring much time and effort. Recently, the widespread use of social media platforms provides new paradigms to learn deep learning models from a large volume of social media data. However, these methods ignore any scientific knowledge about the mechanism of social interaction. In this work, we present the first hybrid method called Sociologically-Informed Neural Network (SINN), which integrates theoretical models and social media data by transporting the concepts of physics-informed neural networks (PINNs) from natural science (i.e., physics) into social science (i.e., sociology and social psychology). In particular, we recast theoretical models as ordinary differential equations (ODEs). Then we train a neural network that simultaneously approximates the data and conforms to the ODEs that represent the social scientific knowledge. In addition, we extend PINNs by integrating matrix factorization and a language model to incorporate rich side information (e.g., user profiles) and structural knowledge (e.g., cluster structure of the social interaction network). Moreover, we develop an end-to-end training procedure for SINN, which involves Gumbel-Softmax approximation to include stochastic mechanisms of social interaction. Extensive experiments on real-world and synthetic datasets show SINN outperforms six baseline methods in predicting opinion dynamics.
Aggregated Multi-output Gaussian Processes with Knowledge Transfer Across Domains
Jun 24, 2022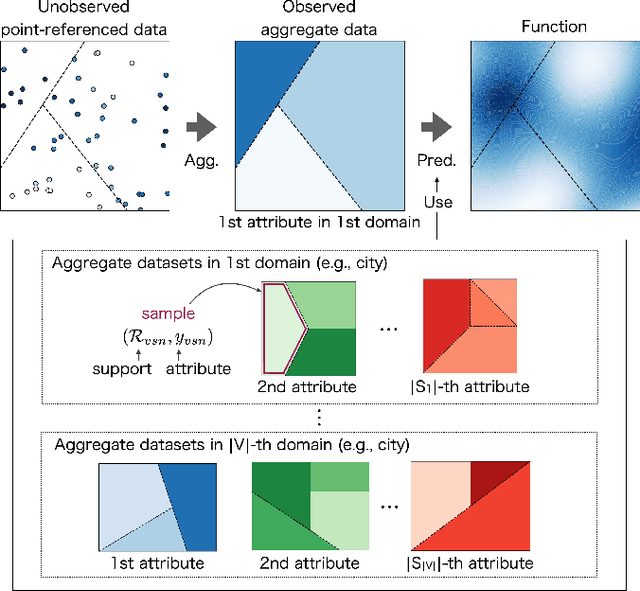

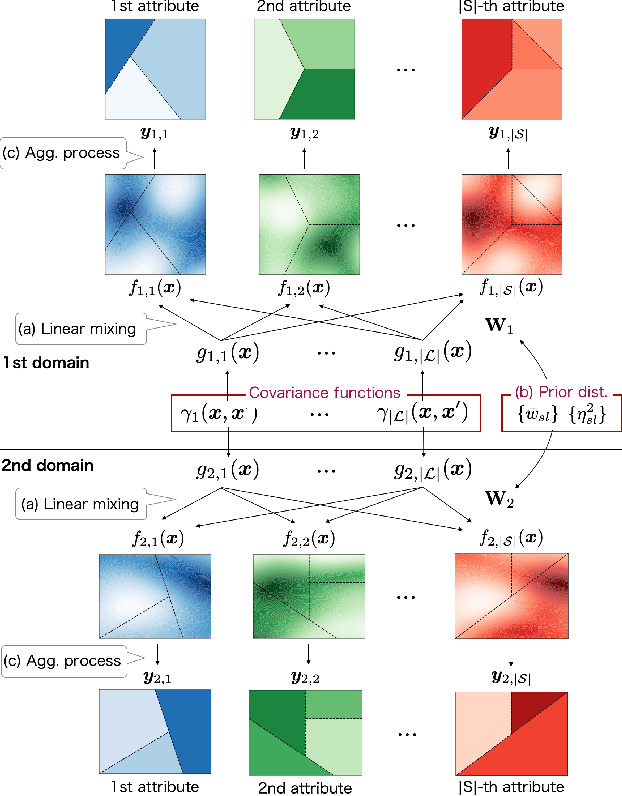
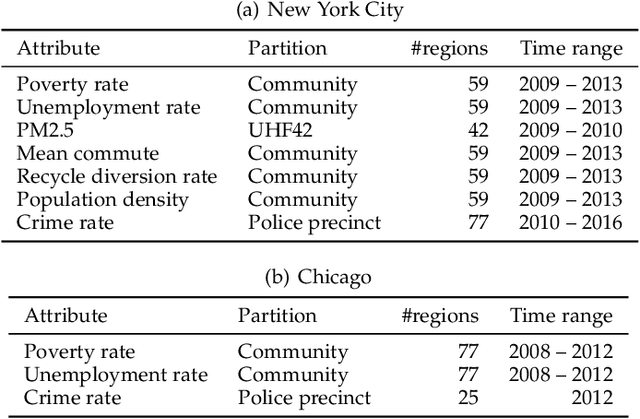
Aggregate data often appear in various fields such as socio-economics and public security. The aggregate data are associated not with points but with supports (e.g., spatial regions in a city). Since the supports may have various granularities depending on attributes (e.g., poverty rate and crime rate), modeling such data is not straightforward. This article offers a multi-output Gaussian process (MoGP) model that infers functions for attributes using multiple aggregate datasets of respective granularities. In the proposed model, the function for each attribute is assumed to be a dependent GP modeled as a linear mixing of independent latent GPs. We design an observation model with an aggregation process for each attribute; the process is an integral of the GP over the corresponding support. We also introduce a prior distribution of the mixing weights, which allows a knowledge transfer across domains (e.g., cities) by sharing the prior. This is advantageous in such a situation where the spatially aggregated dataset in a city is too coarse to interpolate; the proposed model can still make accurate predictions of attributes by utilizing aggregate datasets in other cities. The inference of the proposed model is based on variational Bayes, which enables one to learn the model parameters using the aggregate datasets from multiple domains. The experiments demonstrate that the proposed model outperforms in the task of refining coarse-grained aggregate data on real-world datasets: Time series of air pollutants in Beijing and various kinds of spatial datasets from New York City and Chicago.
Meta-learning for Out-of-Distribution Detection via Density Estimation in Latent Space
Jun 20, 2022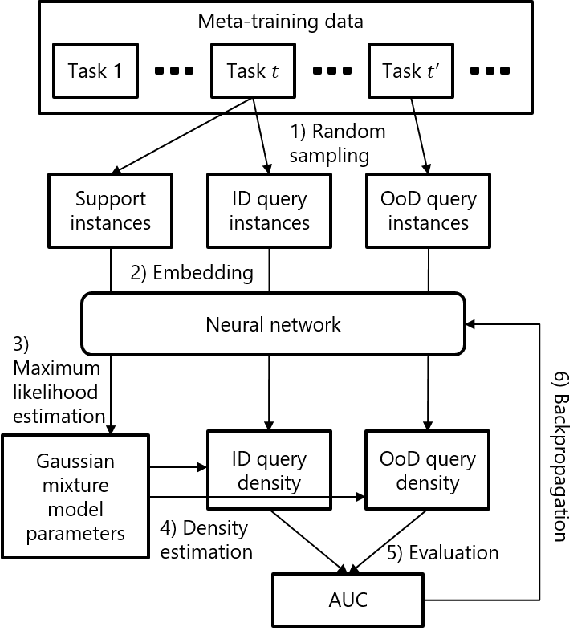
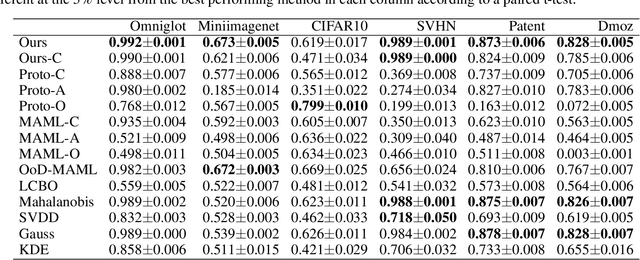
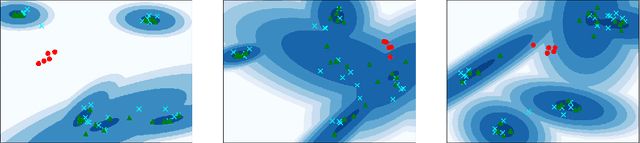
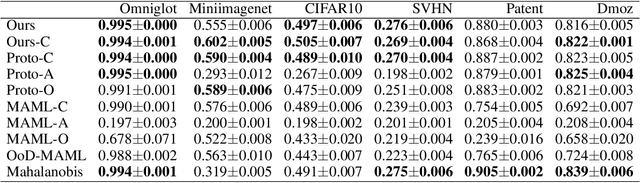
Many neural network-based out-of-distribution (OoD) detection methods have been proposed. However, they require many training data for each target task. We propose a simple yet effective meta-learning method to detect OoD with small in-distribution data in a target task. With the proposed method, the OoD detection is performed by density estimation in a latent space. A neural network shared among all tasks is used to flexibly map instances in the original space to the latent space. The neural network is meta-learned such that the expected OoD detection performance is improved by using various tasks that are different from the target tasks. This meta-learning procedure enables us to obtain appropriate representations in the latent space for OoD detection. For density estimation, we use a Gaussian mixture model (GMM) with full covariance for each class. We can adapt the GMM parameters to in-distribution data in each task in a closed form by maximizing the likelihood. Since the closed form solution is differentiable, we can meta-learn the neural network efficiently with a stochastic gradient descent method by incorporating the solution into the meta-learning objective function. In experiments using six datasets, we demonstrate that the proposed method achieves better performance than existing meta-learning and OoD detection methods.
Excess risk analysis for epistemic uncertainty with application to variational inference
Jun 02, 2022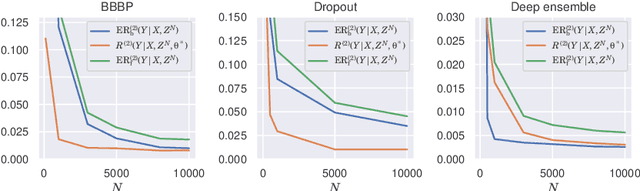
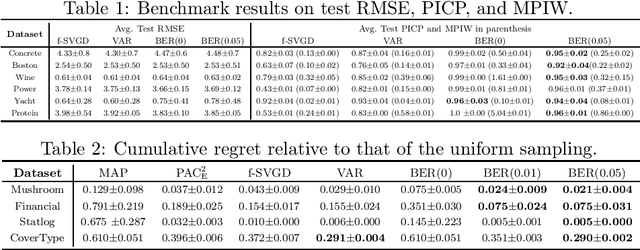
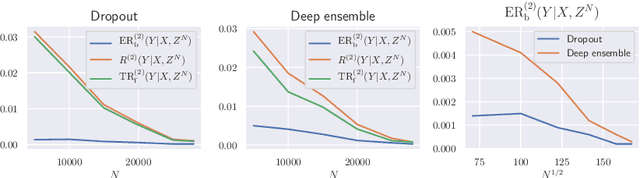
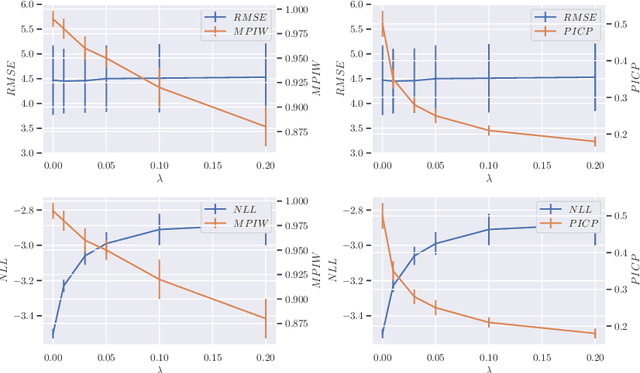
We analyze the epistemic uncertainty (EU) of supervised learning in Bayesian inference by focusing on the excess risk. Existing analysis is limited to the Bayesian setting, which assumes a correct model and exact Bayesian posterior distribution. Thus we cannot apply the existing theory to modern Bayesian algorithms, such as variational inference. To address this, we present a novel EU analysis in the frequentist setting, where data is generated from an unknown distribution. We show a relation between the generalization ability and the widely used EU measurements, such as the variance and entropy of the predictive distribution. Then we show their convergence behaviors theoretically. Finally, we propose new variational inference that directly controls the prediction and EU evaluation performances based on the PAC-Bayesian theory. Numerical experiments show that our algorithm significantly improves the EU evaluation over the existing methods.
Tight integration of neural- and clustering-based diarization through deep unfolding of infinite Gaussian mixture model
Feb 14, 2022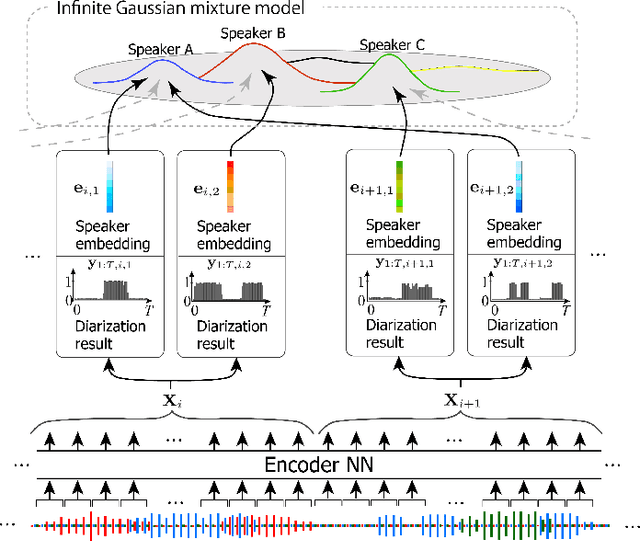

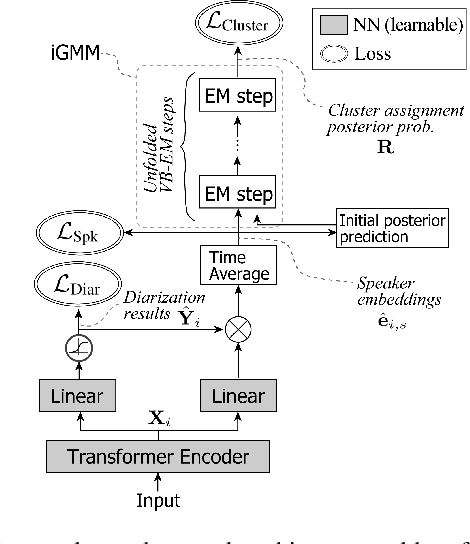
Speaker diarization has been investigated extensively as an important central task for meeting analysis. Recent trend shows that integration of end-to-end neural (EEND)-and clustering-based diarization is a promising approach to handle realistic conversational data containing overlapped speech with an arbitrarily large number of speakers, and achieved state-of-the-art results on various tasks. However, the approaches proposed so far have not realized {\it tight} integration yet, because the clustering employed therein was not optimal in any sense for clustering the speaker embeddings estimated by the EEND module. To address this problem, this paper introduces a {\it trainable} clustering algorithm into the integration framework, by deep-unfolding a non-parametric Bayesian model called the infinite Gaussian mixture model (iGMM). Specifically, the speaker embeddings are optimized during training such that it better fits iGMM clustering, based on a novel clustering loss based on Adjusted Rand Index (ARI). Experimental results based on CALLHOME data show that the proposed approach outperforms the conventional approach in terms of diarization error rate (DER), especially by substantially reducing speaker confusion errors, that indeed reflects the effectiveness of the proposed iGMM integration.
Training Deep Models to be Explained with Fewer Examples
Dec 07, 2021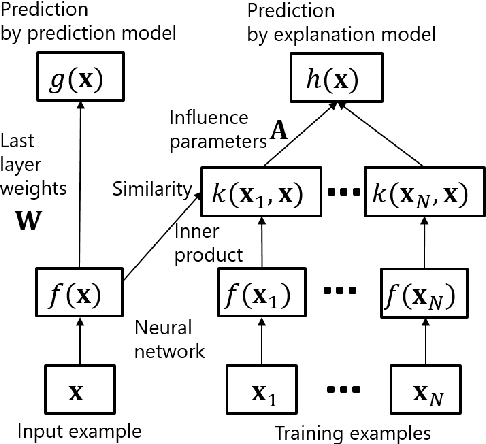
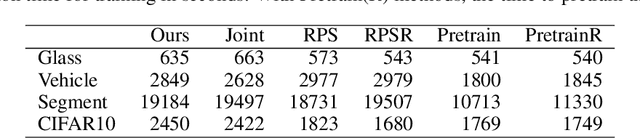
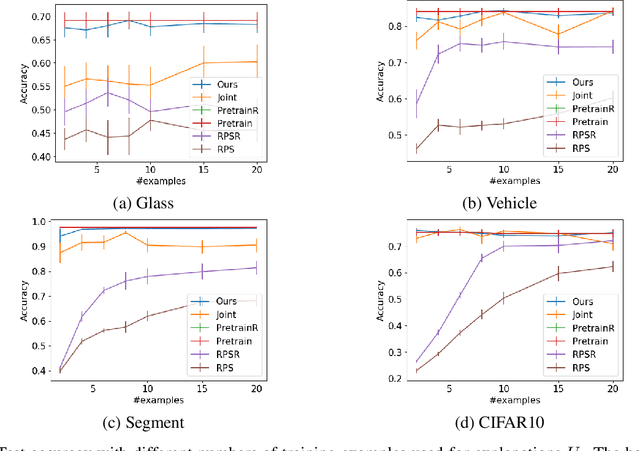
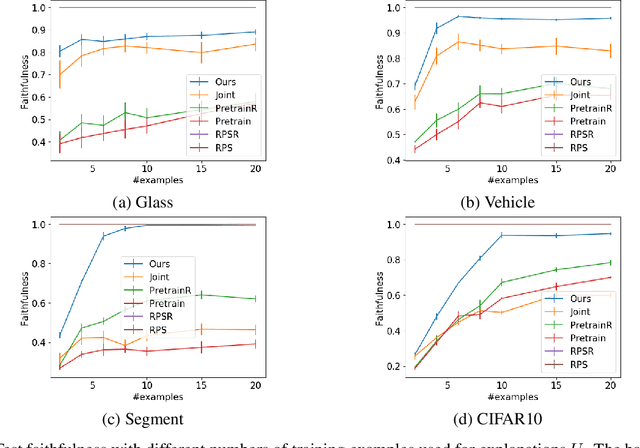
Although deep models achieve high predictive performance, it is difficult for humans to understand the predictions they made. Explainability is important for real-world applications to justify their reliability. Many example-based explanation methods have been proposed, such as representer point selection, where an explanation model defined by a set of training examples is used for explaining a prediction model. For improving the interpretability, reducing the number of examples in the explanation model is important. However, the explanations with fewer examples can be unfaithful since it is difficult to approximate prediction models well by such example-based explanation models. The unfaithful explanations mean that the predictions by the explainable model are different from those by the prediction model. We propose a method for training deep models such that their predictions are faithfully explained by explanation models with a small number of examples. We train the prediction and explanation models simultaneously with a sparse regularizer for reducing the number of examples. The proposed method can be incorporated into any neural network-based prediction models. Experiments using several datasets demonstrate that the proposed method improves faithfulness while keeping the predictive performance.
Evacuation Shelter Scheduling Problem
Nov 26, 2021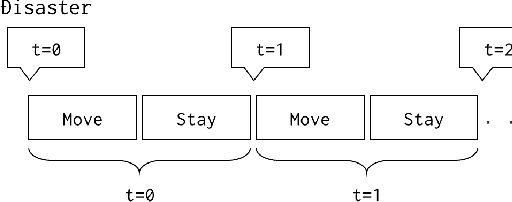

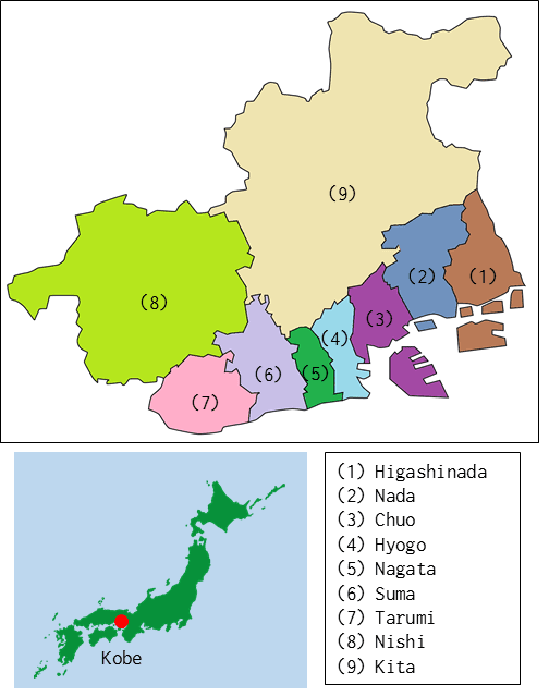
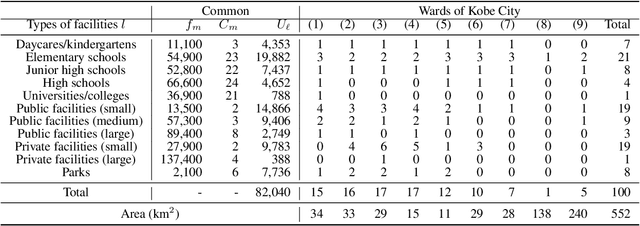
Evacuation shelters, which are urgently required during natural disasters, are designed to minimize the burden of evacuation on human survivors. However, the larger the scale of the disaster, the more costly it becomes to operate shelters. When the number of evacuees decreases, the operation costs can be reduced by moving the remaining evacuees to other shelters and closing shelters as quickly as possible. On the other hand, relocation between shelters imposes a huge emotional burden on evacuees. In this study, we formulate the "Evacuation Shelter Scheduling Problem," which allocates evacuees to shelters in such a way to minimize the movement costs of the evacuees and the operation costs of the shelters. Since it is difficult to solve this quadratic programming problem directly, we show its transformation into a 0-1 integer programming problem. In addition, such a formulation struggles to calculate the burden of relocating them from historical data because no payments are actually made. To solve this issue, we propose a method that estimates movement costs based on the numbers of evacuees and shelters during an actual disaster. Simulation experiments with records from the Kobe earthquake (Great Hanshin-Awaji Earthquake) showed that our proposed method reduced operation costs by 33.7 million dollars: 32%.
End-to-End Learning of Deep Kernel Acquisition Functions for Bayesian Optimization
Nov 01, 2021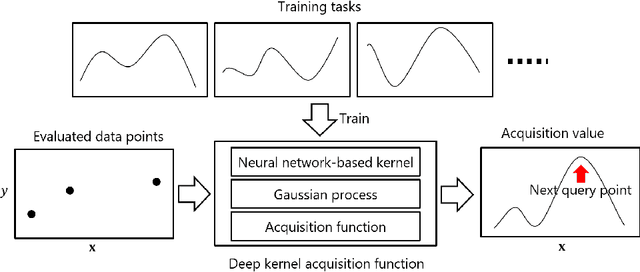
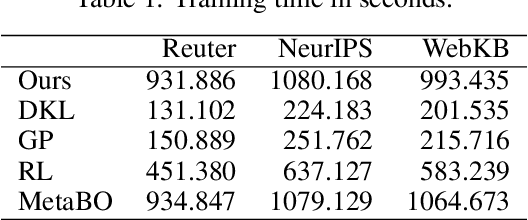
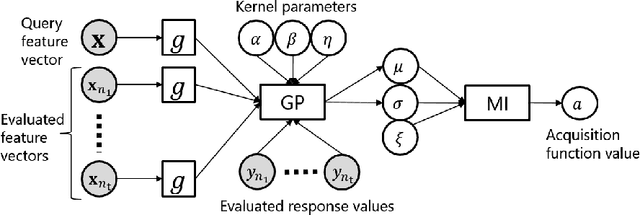
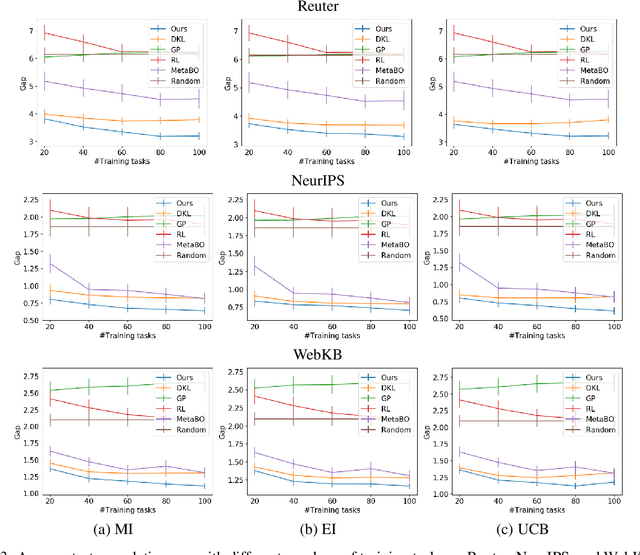
For Bayesian optimization (BO) on high-dimensional data with complex structure, neural network-based kernels for Gaussian processes (GPs) have been used to learn flexible surrogate functions by the high representation power of deep learning. However, existing methods train neural networks by maximizing the marginal likelihood, which do not directly improve the BO performance. In this paper, we propose a meta-learning method for BO with neural network-based kernels that minimizes the expected gap between the true optimum value and the best value found by BO. We model a policy, which takes the current evaluated data points as input and outputs the next data point to be evaluated, by a neural network, where neural network-based kernels, GPs, and mutual information-based acquisition functions are used as its layers. With our model, the neural network-based kernel is trained to be appropriate for the acquisition function by backpropagating the gap through the acquisition function and GP. Our model is trained by a reinforcement learning framework from multiple tasks. Since the neural network is shared across different tasks, we can gather knowledge on BO from multiple training tasks, and use the knowledge for unseen test tasks. In experiments using three text document datasets, we demonstrate that the proposed method achieves better BO performance than the existing methods.
Few-shot Learning for Unsupervised Feature Selection
Jul 02, 2021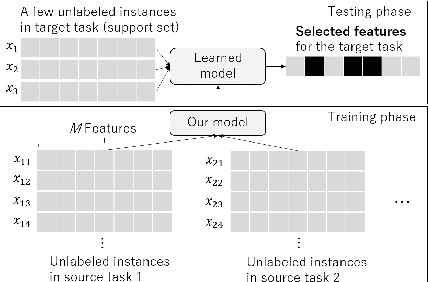
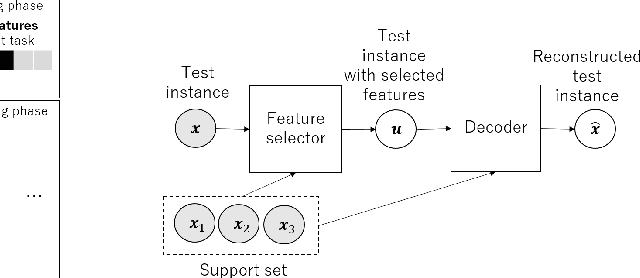

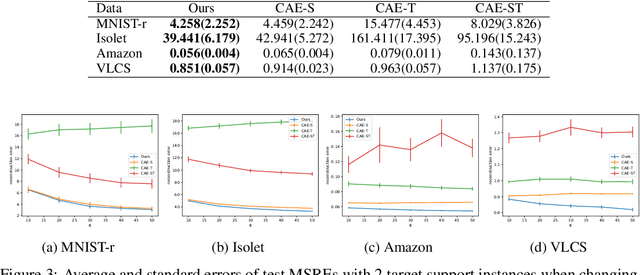
We propose a few-shot learning method for unsupervised feature selection, which is a task to select a subset of relevant features in unlabeled data. Existing methods usually require many instances for feature selection. However, sufficient instances are often unavailable in practice. The proposed method can select a subset of relevant features in a target task given a few unlabeled target instances by training with unlabeled instances in multiple source tasks. Our model consists of a feature selector and decoder. The feature selector outputs a subset of relevant features taking a few unlabeled instances as input such that the decoder can reconstruct the original features of unseen instances from the selected ones. The feature selector uses the Concrete random variables to select features via gradient descent. To encode task-specific properties from a few unlabeled instances to the model, the Concrete random variables and decoder are modeled using permutation-invariant neural networks that take a few unlabeled instances as input. Our model is trained by minimizing the expected test reconstruction error given a few unlabeled instances that is calculated with datasets in source tasks. We experimentally demonstrate that the proposed method outperforms existing feature selection methods.