 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeState of the Art on Neural Rendering
Apr 08, 2020



Efficient rendering of photo-realistic virtual worlds is a long standing effort of computer graphics. Modern graphics techniques have succeeded in synthesizing photo-realistic images from hand-crafted scene representations. However, the automatic generation of shape, materials, lighting, and other aspects of scenes remains a challenging problem that, if solved, would make photo-realistic computer graphics more widely accessible. Concurrently, progress in computer vision and machine learning have given rise to a new approach to image synthesis and editing, namely deep generative models. Neural rendering is a new and rapidly emerging field that combines generative machine learning techniques with physical knowledge from computer graphics, e.g., by the integration of differentiable rendering into network training. With a plethora of applications in computer graphics and vision, neural rendering is poised to become a new area in the graphics community, yet no survey of this emerging field exists. This state-of-the-art report summarizes the recent trends and applications of neural rendering. We focus on approaches that combine classic computer graphics techniques with deep generative models to obtain controllable and photo-realistic outputs. Starting with an overview of the underlying computer graphics and machine learning concepts, we discuss critical aspects of neural rendering approaches. This state-of-the-art report is focused on the many important use cases for the described algorithms such as novel view synthesis, semantic photo manipulation, facial and body reenactment, relighting, free-viewpoint video, and the creation of photo-realistic avatars for virtual and augmented reality telepresence. Finally, we conclude with a discussion of the social implications of such technology and investigate open research problems.
PIFuHD: Multi-Level Pixel-Aligned Implicit Function for High-Resolution 3D Human Digitization
Apr 01, 2020
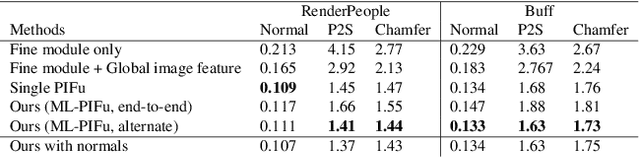
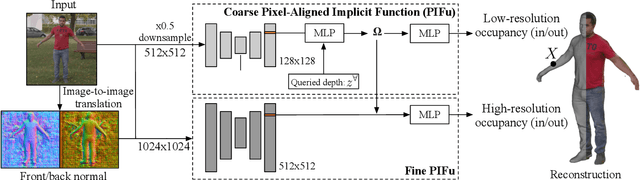
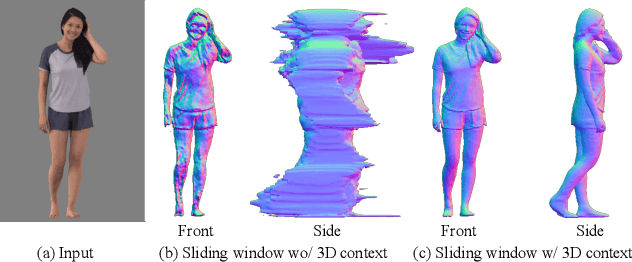
Recent advances in image-based 3D human shape estimation have been driven by the significant improvement in representation power afforded by deep neural networks. Although current approaches have demonstrated the potential in real world settings, they still fail to produce reconstructions with the level of detail often present in the input images. We argue that this limitation stems primarily form two conflicting requirements; accurate predictions require large context, but precise predictions require high resolution. Due to memory limitations in current hardware, previous approaches tend to take low resolution images as input to cover large spatial context, and produce less precise (or low resolution) 3D estimates as a result. We address this limitation by formulating a multi-level architecture that is end-to-end trainable. A coarse level observes the whole image at lower resolution and focuses on holistic reasoning. This provides context to an fine level which estimates highly detailed geometry by observing higher-resolution images. We demonstrate that our approach significantly outperforms existing state-of-the-art techniques on single image human shape reconstruction by fully leveraging 1k-resolution input images.
* project page: https://shunsukesaito.github.io/PIFuHD
Single-Network Whole-Body Pose Estimation
Sep 30, 2019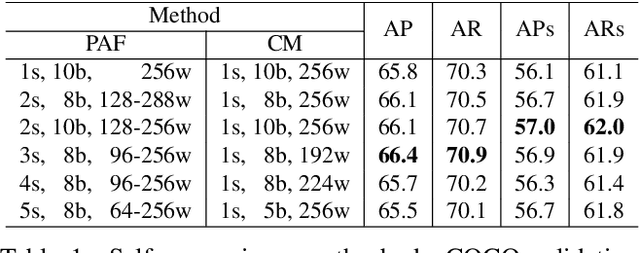
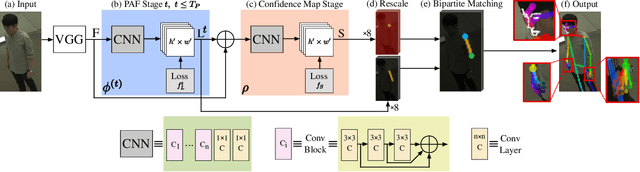


We present the first single-network approach for 2D~whole-body pose estimation, which entails simultaneous localization of body, face, hands, and feet keypoints. Due to the bottom-up formulation, our method maintains constant real-time performance regardless of the number of people in the image. The network is trained in a single stage using multi-task learning, through an improved architecture which can handle scale differences between body/foot and face/hand keypoints. Our approach considerably improves upon OpenPose~\cite{cao2018openpose}, the only work so far capable of whole-body pose estimation, both in terms of speed and global accuracy. Unlike OpenPose, our method does not need to run an additional network for each hand and face candidate, making it substantially faster for multi-person scenarios. This work directly results in a reduction of computational complexity for applications that require 2D whole-body information (e.g., VR/AR, re-targeting). In addition, it yields higher accuracy, especially for occluded, blurry, and low resolution faces and hands. For code, trained models, and validation benchmarks, visit our project page: https://github.com/CMU-Perceptual-Computing-Lab/openpose_train.
Neural Volumes: Learning Dynamic Renderable Volumes from Images
Jun 18, 2019

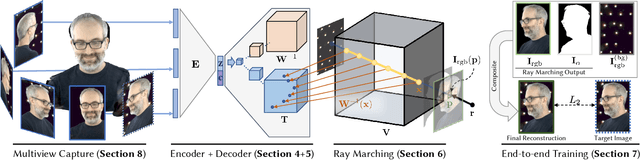
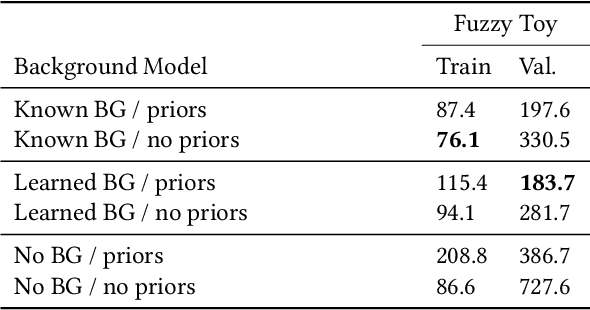
Modeling and rendering of dynamic scenes is challenging, as natural scenes often contain complex phenomena such as thin structures, evolving topology, translucency, scattering, occlusion, and biological motion. Mesh-based reconstruction and tracking often fail in these cases, and other approaches (e.g., light field video) typically rely on constrained viewing conditions, which limit interactivity. We circumvent these difficulties by presenting a learning-based approach to representing dynamic objects inspired by the integral projection model used in tomographic imaging. The approach is supervised directly from 2D images in a multi-view capture setting and does not require explicit reconstruction or tracking of the object. Our method has two primary components: an encoder-decoder network that transforms input images into a 3D volume representation, and a differentiable ray-marching operation that enables end-to-end training. By virtue of its 3D representation, our construction extrapolates better to novel viewpoints compared to screen-space rendering techniques. The encoder-decoder architecture learns a latent representation of a dynamic scene that enables us to produce novel content sequences not seen during training. To overcome memory limitations of voxel-based representations, we learn a dynamic irregular grid structure implemented with a warp field during ray-marching. This structure greatly improves the apparent resolution and reduces grid-like artifacts and jagged motion. Finally, we demonstrate how to incorporate surface-based representations into our volumetric-learning framework for applications where the highest resolution is required, using facial performance capture as a case in point.
Towards Social Artificial Intelligence: Nonverbal Social Signal Prediction in A Triadic Interaction
Jun 10, 2019
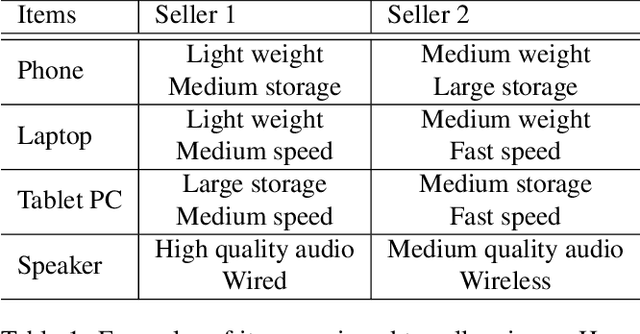

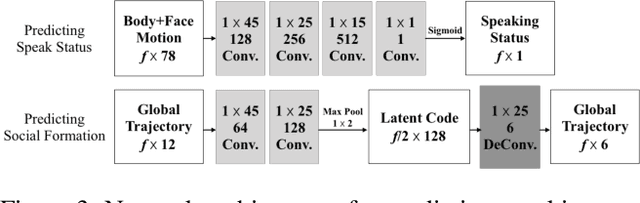
We present a new research task and a dataset to understand human social interactions via computational methods, to ultimately endow machines with the ability to encode and decode a broad channel of social signals humans use. This research direction is essential to make a machine that genuinely communicates with humans, which we call Social Artificial Intelligence. We first formulate the "social signal prediction" problem as a way to model the dynamics of social signals exchanged among interacting individuals in a data-driven way. We then present a new 3D motion capture dataset to explore this problem, where the broad spectrum of social signals (3D body, face, and hand motions) are captured in a triadic social interaction scenario. Baseline approaches to predict speaking status, social formation, and body gestures of interacting individuals are presented in the defined social prediction framework.
LBS Autoencoder: Self-supervised Fitting of Articulated Meshes to Point Clouds
Apr 22, 2019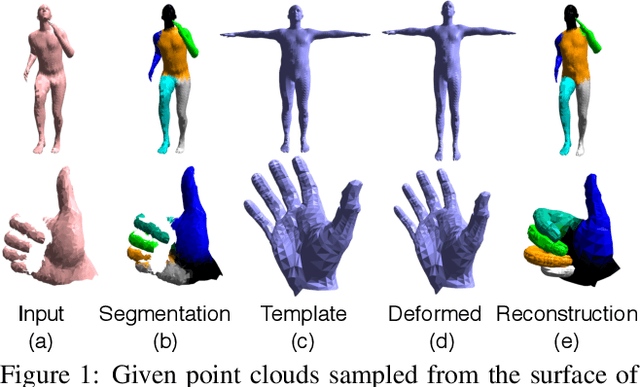
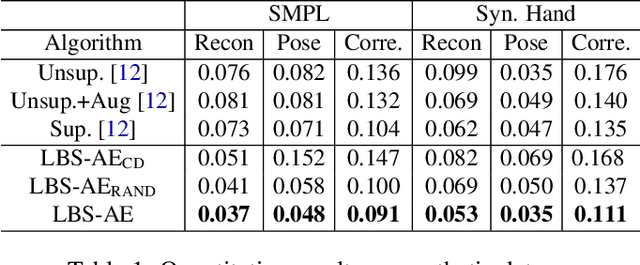
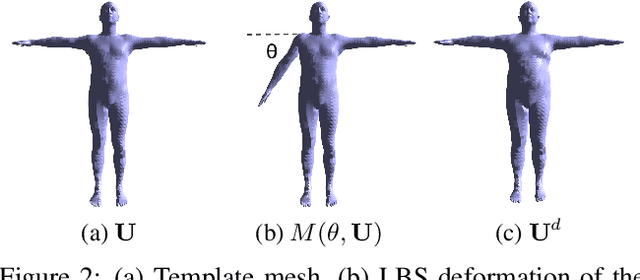
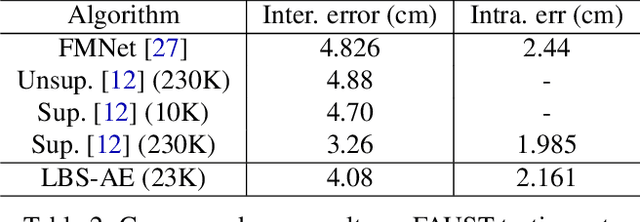
We present LBS-AE; a self-supervised autoencoding algorithm for fitting articulated mesh models to point clouds. As input, we take a sequence of point clouds to be registered as well as an artist-rigged mesh, i.e. a template mesh equipped with a linear-blend skinning (LBS) deformation space parameterized by a skeleton hierarchy. As output, we learn an LBS-based autoencoder that produces registered meshes from the input point clouds. To bridge the gap between the artist-defined geometry and the captured point clouds, our autoencoder models pose-dependent deviations from the template geometry. During training, instead of using explicit correspondences, such as key points or pose supervision, our method leverages LBS deformations to bootstrap the learning process. To avoid poor local minima from erroneous point-to-point correspondences, we utilize a structured Chamfer distance based on part-segmentations, which are learned concurrently using self-supervision. We demonstrate qualitative results on real captured hands, and report quantitative evaluations on the FAUST benchmark for body registration. Our method achieves performance that is superior to other unsupervised approaches and comparable to methods using supervised examples.
OpenPose: Realtime Multi-Person 2D Pose Estimation using Part Affinity Fields
Dec 18, 2018
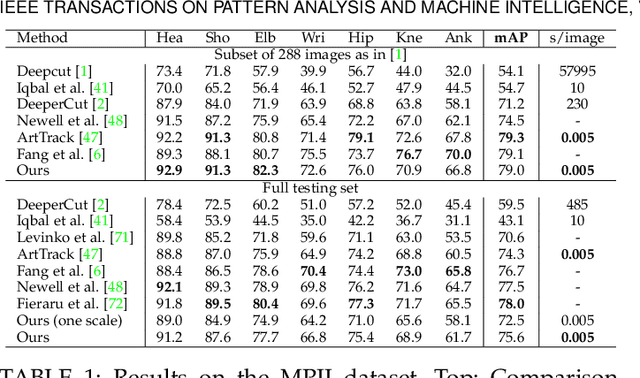

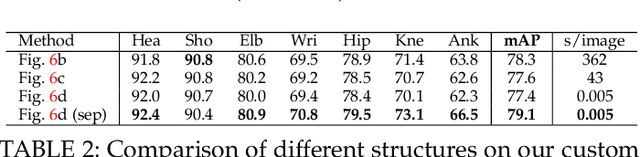
Realtime multi-person 2D pose estimation is a key component in enabling machines to have an understanding of people in images and videos. In this work, we present a realtime approach to detect the 2D pose of multiple people in an image. The proposed method uses a nonparametric representation, which we refer to as Part Affinity Fields (PAFs), to learn to associate body parts with individuals in the image. This bottom-up system achieves high accuracy and realtime performance, regardless of the number of people in the image. In previous work, PAFs and body part location estimation were refined simultaneously across training stages. We demonstrate that a PAF-only refinement rather than both PAF and body part location refinement results in a substantial increase in both runtime performance and accuracy. We also present the first combined body and foot keypoint detector, based on an internal annotated foot dataset that we have publicly released. We show that the combined detector not only reduces the inference time compared to running them sequentially, but also maintains the accuracy of each component individually. This work has culminated in the release of OpenPose, the first open-source realtime system for multi-person 2D pose detection, including body, foot, hand, and facial keypoints.
Deep Appearance Models for Face Rendering
Aug 01, 2018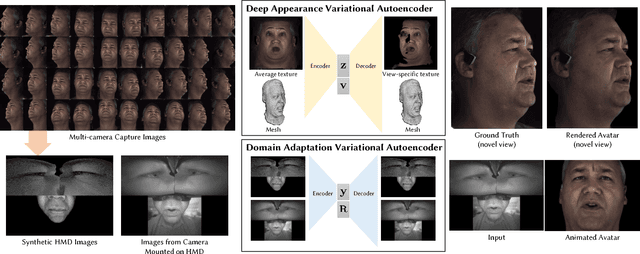
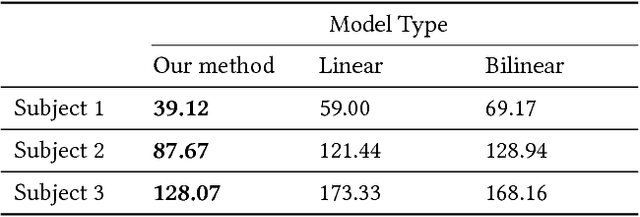
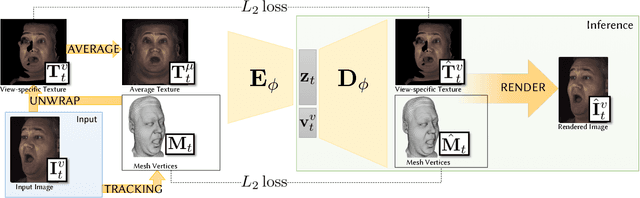

We introduce a deep appearance model for rendering the human face. Inspired by Active Appearance Models, we develop a data-driven rendering pipeline that learns a joint representation of facial geometry and appearance from a multiview capture setup. Vertex positions and view-specific textures are modeled using a deep variational autoencoder that captures complex nonlinear effects while producing a smooth and compact latent representation. View-specific texture enables the modeling of view-dependent effects such as specularity. In addition, it can also correct for imperfect geometry stemming from biased or low resolution estimates. This is a significant departure from the traditional graphics pipeline, which requires highly accurate geometry as well as all elements of the shading model to achieve realism through physically-inspired light transport. Acquiring such a high level of accuracy is difficult in practice, especially for complex and intricate parts of the face, such as eyelashes and the oral cavity. These are handled naturally by our approach, which does not rely on precise estimates of geometry. Instead, the shading model accommodates deficiencies in geometry though the flexibility afforded by the neural network employed. At inference time, we condition the decoding network on the viewpoint of the camera in order to generate the appropriate texture for rendering. The resulting system can be implemented simply using existing rendering engines through dynamic textures with flat lighting. This representation, together with a novel unsupervised technique for mapping images to facial states, results in a system that is naturally suited to real-time interactive settings such as Virtual Reality (VR).
* Accepted to SIGGRAPH 2018
Total Capture: A 3D Deformation Model for Tracking Faces, Hands, and Bodies
Jan 05, 2018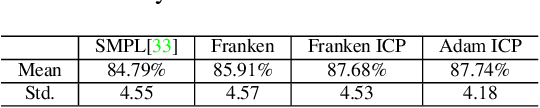
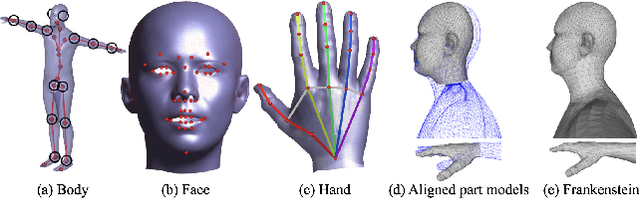
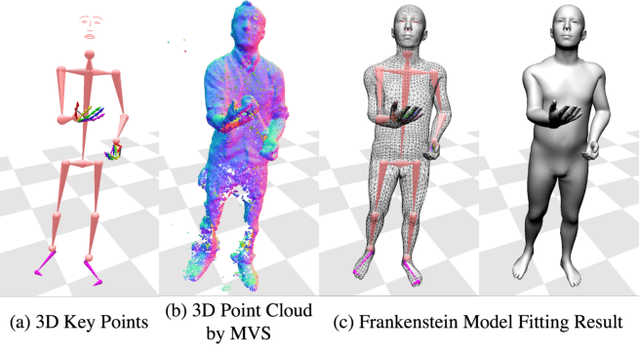
We present a unified deformation model for the markerless capture of multiple scales of human movement, including facial expressions, body motion, and hand gestures. An initial model is generated by locally stitching together models of the individual parts of the human body, which we refer to as the "Frankenstein" model. This model enables the full expression of part movements, including face and hands by a single seamless model. Using a large-scale capture of people wearing everyday clothes, we optimize the Frankenstein model to create "Adam". Adam is a calibrated model that shares the same skeleton hierarchy as the initial model but can express hair and clothing geometry, making it directly usable for fitting people as they normally appear in everyday life. Finally, we demonstrate the use of these models for total motion tracking, simultaneously capturing the large-scale body movements and the subtle face and hand motion of a social group of people.
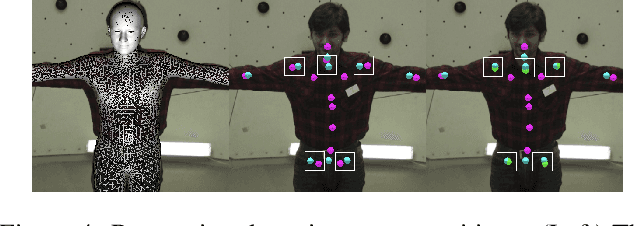
Hand Keypoint Detection in Single Images using Multiview Bootstrapping
Apr 25, 2017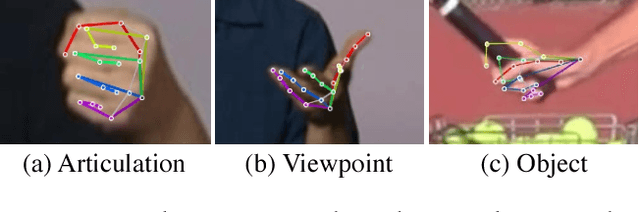
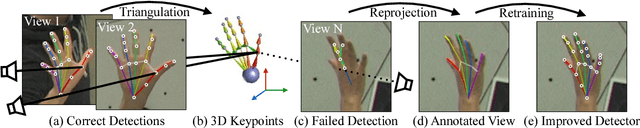
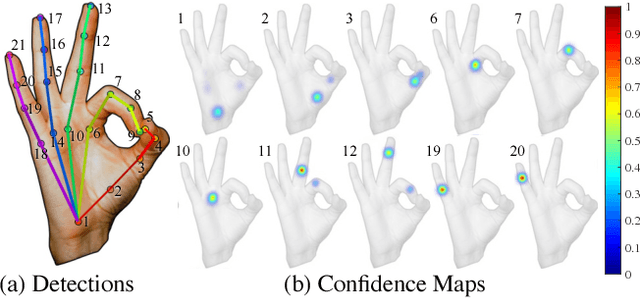
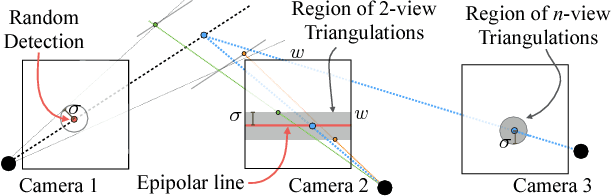
We present an approach that uses a multi-camera system to train fine-grained detectors for keypoints that are prone to occlusion, such as the joints of a hand. We call this procedure multiview bootstrapping: first, an initial keypoint detector is used to produce noisy labels in multiple views of the hand. The noisy detections are then triangulated in 3D using multiview geometry or marked as outliers. Finally, the reprojected triangulations are used as new labeled training data to improve the detector. We repeat this process, generating more labeled data in each iteration. We derive a result analytically relating the minimum number of views to achieve target true and false positive rates for a given detector. The method is used to train a hand keypoint detector for single images. The resulting keypoint detector runs in realtime on RGB images and has accuracy comparable to methods that use depth sensors. The single view detector, triangulated over multiple views, enables 3D markerless hand motion capture with complex object interactions.