 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCommAI: Evaluating the first steps towards a useful general AI
Mar 27, 2017With machine learning successfully applied to new daunting problems almost every day, general AI starts looking like an attainable goal. However, most current research focuses instead on important but narrow applications, such as image classification or machine translation. We believe this to be largely due to the lack of objective ways to measure progress towards broad machine intelligence. In order to fill this gap, we propose here a set of concrete desiderata for general AI, together with a platform to test machines on how well they satisfy such desiderata, while keeping all further complexities to a minimum.
Variable Computation in Recurrent Neural Networks
Mar 02, 2017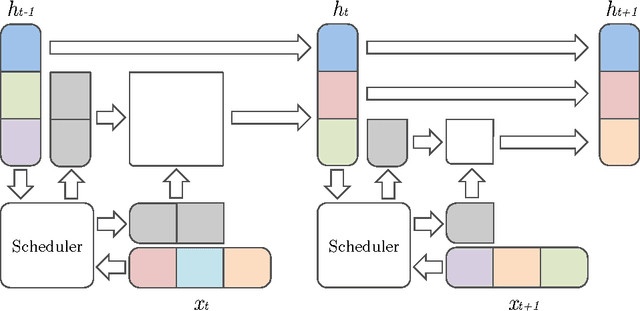


Recurrent neural networks (RNNs) have been used extensively and with increasing success to model various types of sequential data. Much of this progress has been achieved through devising recurrent units and architectures with the flexibility to capture complex statistics in the data, such as long range dependency or localized attention phenomena. However, while many sequential data (such as video, speech or language) can have highly variable information flow, most recurrent models still consume input features at a constant rate and perform a constant number of computations per time step, which can be detrimental to both speed and model capacity. In this paper, we explore a modification to existing recurrent units which allows them to learn to vary the amount of computation they perform at each step, without prior knowledge of the sequence's time structure. We show experimentally that not only do our models require fewer operations, they also lead to better performance overall on evaluation tasks.
FastText.zip: Compressing text classification models
Dec 12, 2016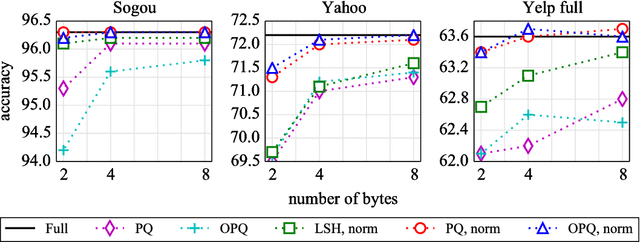
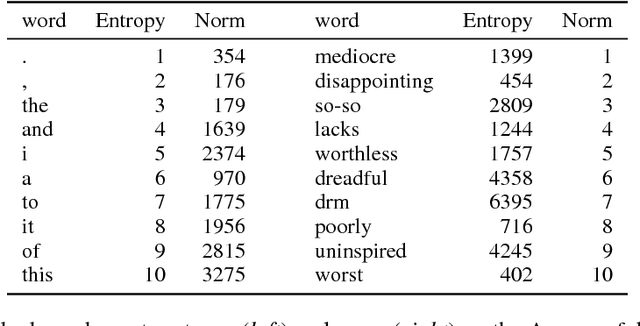
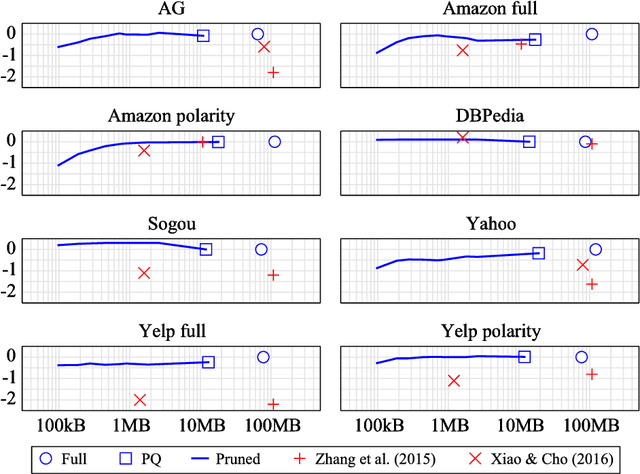
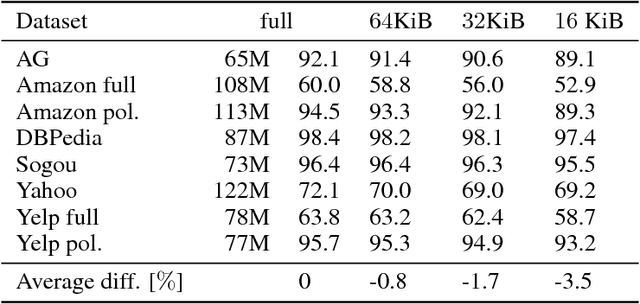
We consider the problem of producing compact architectures for text classification, such that the full model fits in a limited amount of memory. After considering different solutions inspired by the hashing literature, we propose a method built upon product quantization to store word embeddings. While the original technique leads to a loss in accuracy, we adapt this method to circumvent quantization artefacts. Our experiments carried out on several benchmarks show that our approach typically requires two orders of magnitude less memory than fastText while being only slightly inferior with respect to accuracy. As a result, it outperforms the state of the art by a good margin in terms of the compromise between memory usage and accuracy.
Bag of Tricks for Efficient Text Classification
Aug 09, 2016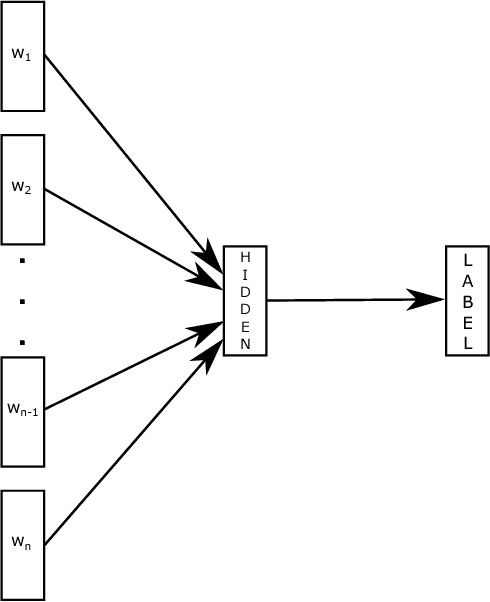
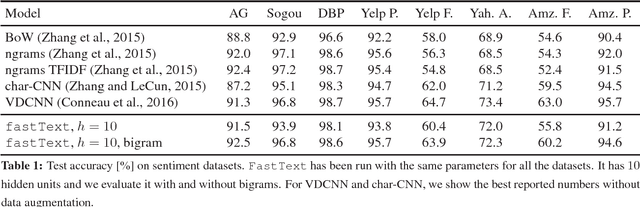
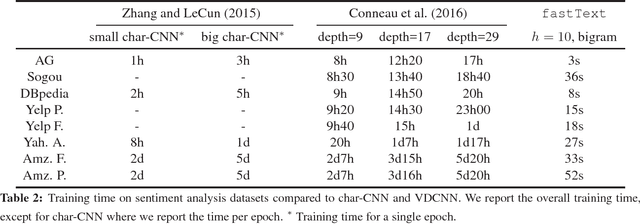
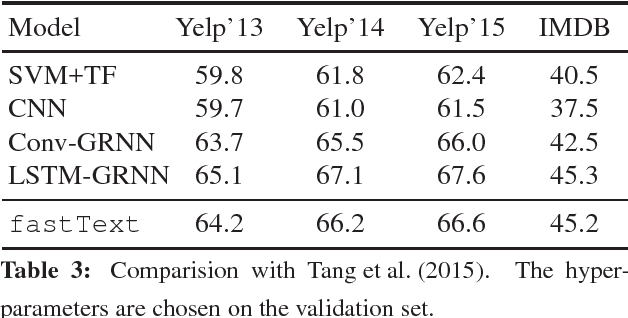
This paper explores a simple and efficient baseline for text classification. Our experiments show that our fast text classifier fastText is often on par with deep learning classifiers in terms of accuracy, and many orders of magnitude faster for training and evaluation. We can train fastText on more than one billion words in less than ten minutes using a standard multicore~CPU, and classify half a million sentences among~312K classes in less than a minute.
A Roadmap towards Machine Intelligence
Feb 26, 2016

The development of intelligent machines is one of the biggest unsolved challenges in computer science. In this paper, we propose some fundamental properties these machines should have, focusing in particular on communication and learning. We discuss a simple environment that could be used to incrementally teach a machine the basics of natural-language-based communication, as a prerequisite to more complex interaction with human users. We also present some conjectures on the sort of algorithms the machine should support in order to profitably learn from the environment.
Towards AI-Complete Question Answering: A Set of Prerequisite Toy Tasks
Dec 31, 2015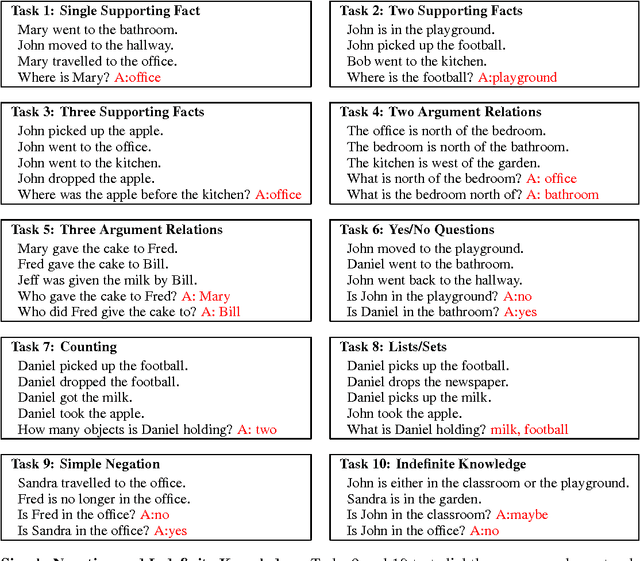

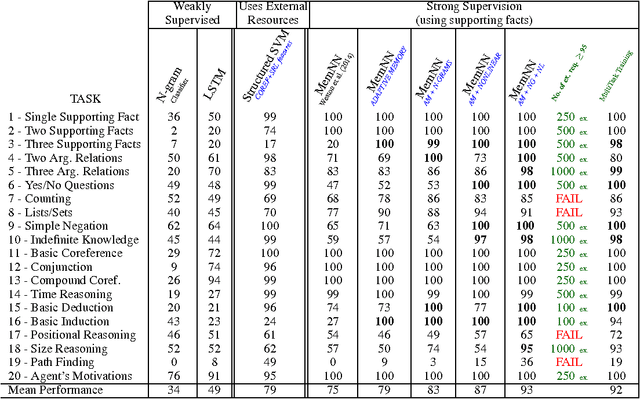
One long-term goal of machine learning research is to produce methods that are applicable to reasoning and natural language, in particular building an intelligent dialogue agent. To measure progress towards that goal, we argue for the usefulness of a set of proxy tasks that evaluate reading comprehension via question answering. Our tasks measure understanding in several ways: whether a system is able to answer questions via chaining facts, simple induction, deduction and many more. The tasks are designed to be prerequisites for any system that aims to be capable of conversing with a human. We believe many existing learning systems can currently not solve them, and hence our aim is to classify these tasks into skill sets, so that researchers can identify (and then rectify) the failings of their systems. We also extend and improve the recently introduced Memory Networks model, and show it is able to solve some, but not all, of the tasks.
Alternative structures for character-level RNNs
Nov 24, 2015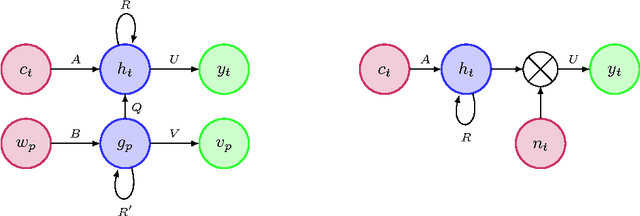
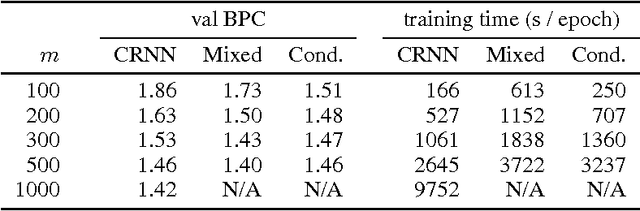

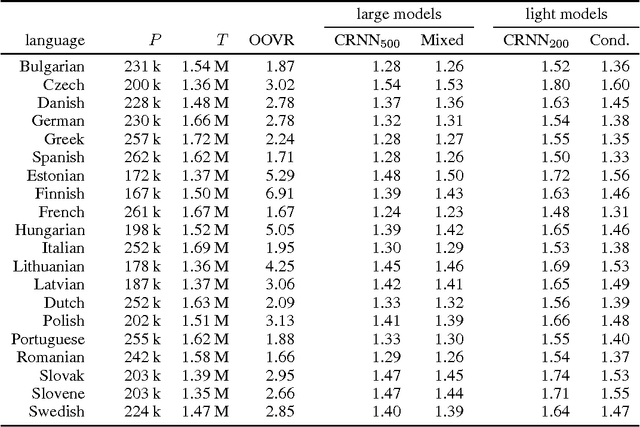
Recurrent neural networks are convenient and efficient models for language modeling. However, when applied on the level of characters instead of words, they suffer from several problems. In order to successfully model long-term dependencies, the hidden representation needs to be large. This in turn implies higher computational costs, which can become prohibitive in practice. We propose two alternative structural modifications to the classical RNN model. The first one consists on conditioning the character level representation on the previous word representation. The other one uses the character history to condition the output probability. We evaluate the performance of the two proposed modifications on challenging, multi-lingual real world data.
Learning Simple Algorithms from Examples
Nov 24, 2015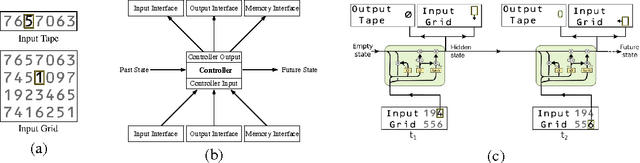
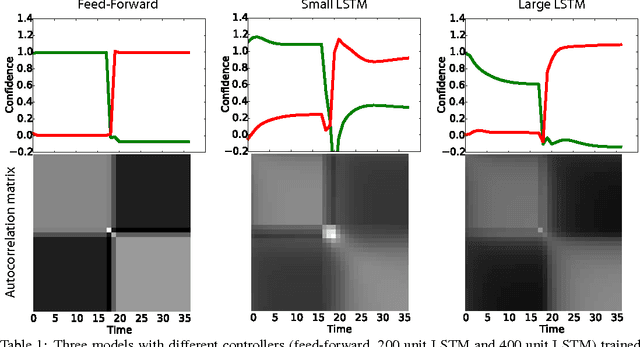
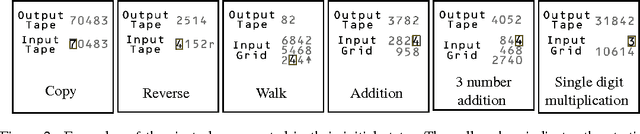
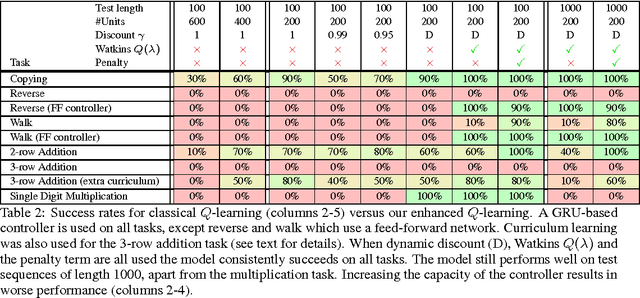
We present an approach for learning simple algorithms such as copying, multi-digit addition and single digit multiplication directly from examples. Our framework consists of a set of interfaces, accessed by a controller. Typical interfaces are 1-D tapes or 2-D grids that hold the input and output data. For the controller, we explore a range of neural network-based models which vary in their ability to abstract the underlying algorithm from training instances and generalize to test examples with many thousands of digits. The controller is trained using $Q$-learning with several enhancements and we show that the bottleneck is in the capabilities of the controller rather than in the search incurred by $Q$-learning.
Inferring Algorithmic Patterns with Stack-Augmented Recurrent Nets
Jun 01, 2015
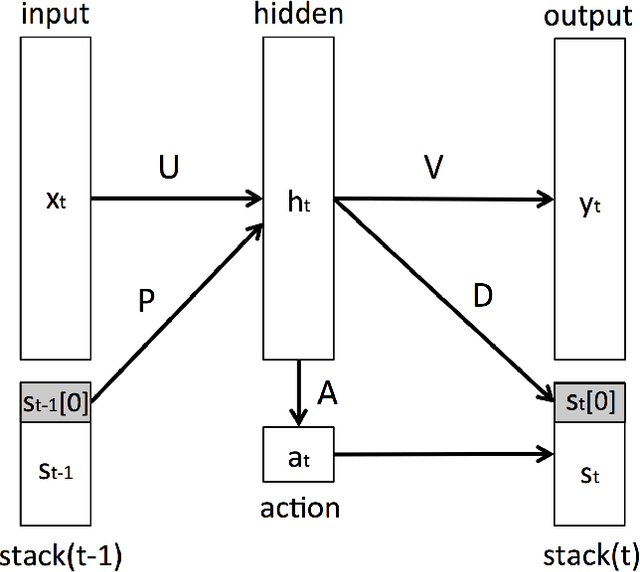
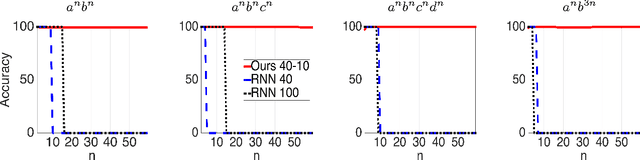
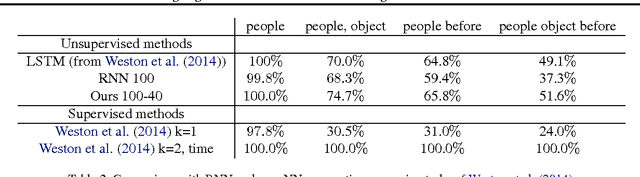
Despite the recent achievements in machine learning, we are still very far from achieving real artificial intelligence. In this paper, we discuss the limitations of standard deep learning approaches and show that some of these limitations can be overcome by learning how to grow the complexity of a model in a structured way. Specifically, we study the simplest sequence prediction problems that are beyond the scope of what is learnable with standard recurrent networks, algorithmically generated sequences which can only be learned by models which have the capacity to count and to memorize sequences. We show that some basic algorithms can be learned from sequential data using a recurrent network associated with a trainable memory.
Ensemble of Generative and Discriminative Techniques for Sentiment Analysis of Movie Reviews
May 27, 2015

Sentiment analysis is a common task in natural language processing that aims to detect polarity of a text document (typically a consumer review). In the simplest settings, we discriminate only between positive and negative sentiment, turning the task into a standard binary classification problem. We compare several ma- chine learning approaches to this problem, and combine them to achieve the best possible results. We show how to use for this task the standard generative lan- guage models, which are slightly complementary to the state of the art techniques. We achieve strong results on a well-known dataset of IMDB movie reviews. Our results are easily reproducible, as we publish also the code needed to repeat the experiments. This should simplify further advance of the state of the art, as other researchers can combine their techniques with ours with little effort.