 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edgen-stage Latent Dirichlet Allocation: A Novel Approach for LDA
Oct 20, 2021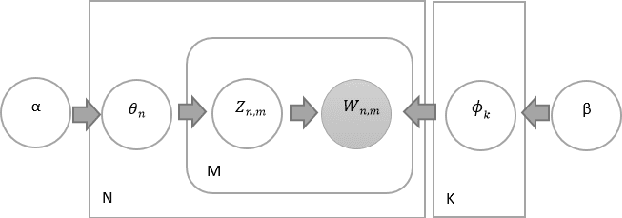

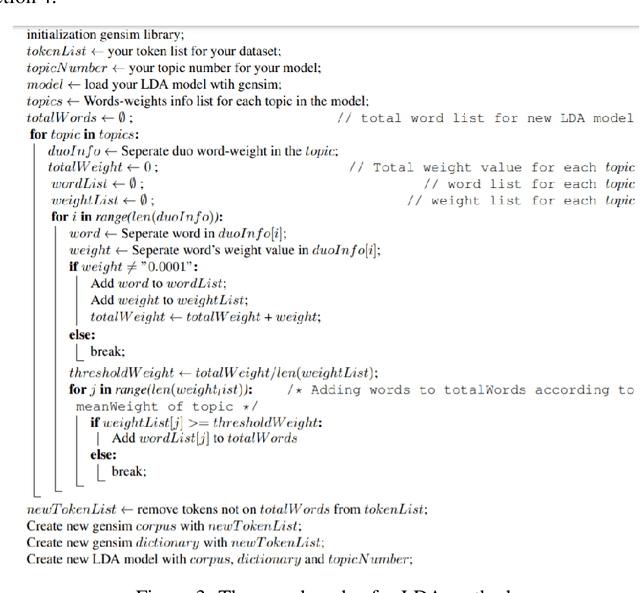
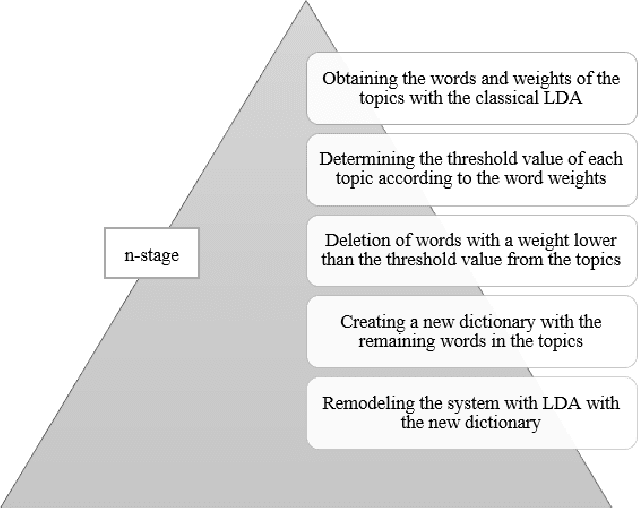
Nowadays, data analysis has become a problem as the amount of data is constantly increasing. In order to overcome this problem in textual data, many models and methods are used in natural language processing. The topic modeling field is one of these methods. Topic modeling allows determining the semantic structure of a text document. Latent Dirichlet Allocation (LDA) is the most common method among topic modeling methods. In this article, the proposed n-stage LDA method, which can enable the LDA method to be used more effectively, is explained in detail. The positive effect of the method has been demonstrated by the applied English and Turkish studies. Since the method focuses on reducing the word count in the dictionary, it can be used language-independently. You can access the open-source code of the method and the example: https://github.com/anil1055/n-stage_LDA
Evaluation of Non-Negative Matrix Factorization and n-stage Latent Dirichlet Allocation for Emotion Analysis in Turkish Tweets
Sep 27, 2021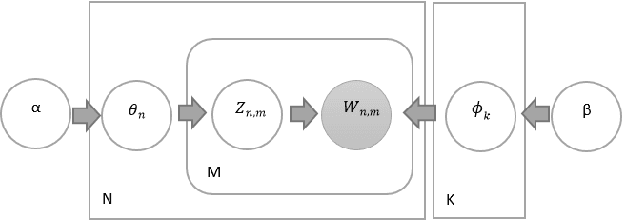


With the development of technology, the use of social media has become quite common. Analyzing comments on social media in areas such as media and advertising plays an important role today. For this reason, new and traditional natural language processing methods are used to detect the emotion of these shares. In this paper, the Latent Dirichlet Allocation, namely LDA, and Non-Negative Matrix Factorization methods in topic modeling were used to determine which emotion the Turkish tweets posted via Twitter. In addition, the accuracy of a proposed n-level method based on LDA was analyzed. Dataset consists of 5 emotions, namely angry, fear, happy, sad and confused. NMF was the most successful method among all topic modeling methods in this study. Then, the F1-measure of Random Forest, Naive Bayes and Support Vector Machine methods was analyzed by obtaining a file suitable for Weka by using the word weights and class labels of the topics. Among the Weka results, the most successful method was n-stage LDA, and the most successful algorithm was Random Forest.
* Published in: 2019 Innovations in Intelligent Systems and Applications Conference (ASYU). This paper is extension version of Comparison Method for Emotion Detection of Twitter Users (http://dx.doi.org/10.1109/ASYU48272.2019.8946435). Please citation this IEEE paper