 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOne Model to Unite Them All: Personalized Federated Learning of Multi-Contrast MRI Synthesis
Jul 13, 2022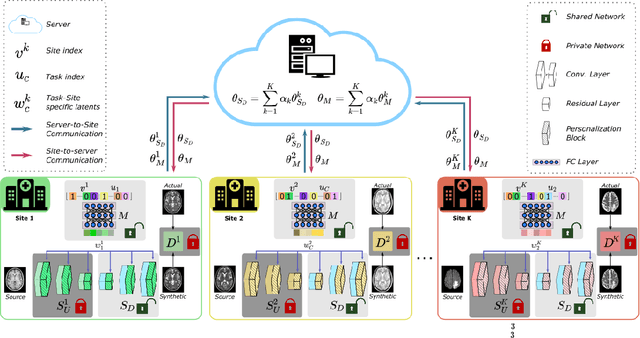
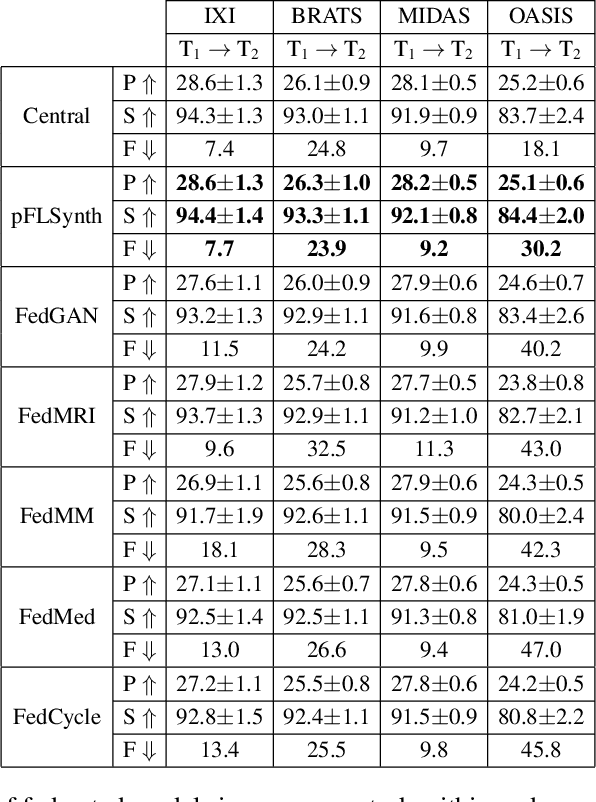
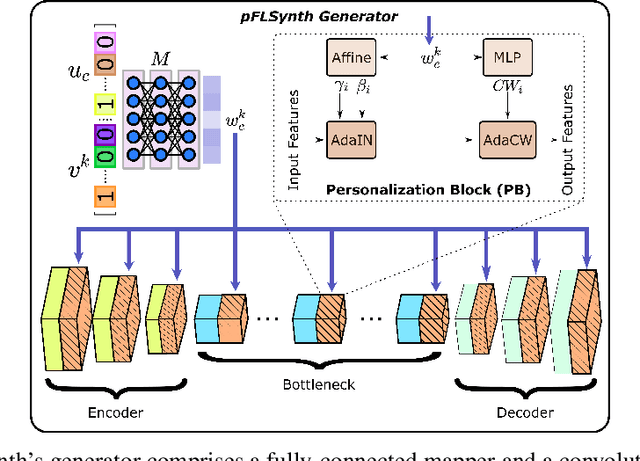
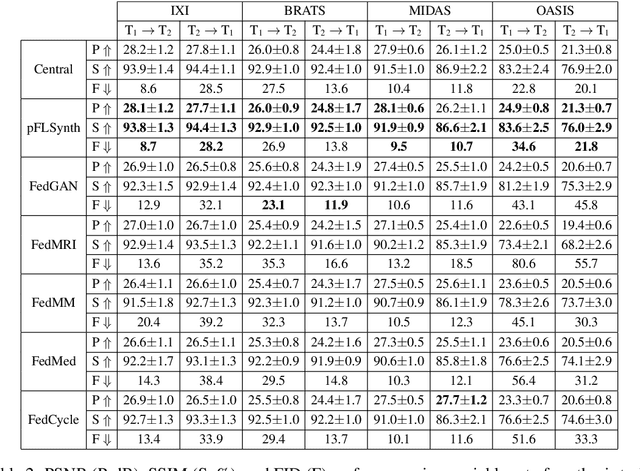
Learning-based MRI translation involves a synthesis model that maps a source-contrast onto a target-contrast image. Multi-institutional collaborations are key to training synthesis models across broad datasets, yet centralized training involves privacy risks. Federated learning (FL) is a collaboration framework that instead adopts decentralized training to avoid sharing imaging data and mitigate privacy concerns. However, FL-trained models can be impaired by the inherent heterogeneity in the distribution of imaging data. On the one hand, implicit shifts in image distribution are evident across sites, even for a common translation task with fixed source-target configuration. Conversely, explicit shifts arise within and across sites when diverse translation tasks with varying source-target configurations are prescribed. To improve reliability against domain shifts, here we introduce the first personalized FL method for MRI Synthesis (pFLSynth). pFLSynth is based on an adversarial model equipped with a mapper that produces latents specific to individual sites and source-target contrasts. It leverages novel personalization blocks that adaptively tune the statistics and weighting of feature maps across the generator based on these latents. To further promote site-specificity, partial model aggregation is employed over downstream layers of the generator while upstream layers are retained locally. As such, pFLSynth enables training of a unified synthesis model that can reliably generalize across multiple sites and translation tasks. Comprehensive experiments on multi-site datasets clearly demonstrate the enhanced performance of pFLSynth against prior federated methods in multi-contrast MRI synthesis.
Adaptive Diffusion Priors for Accelerated MRI Reconstruction
Jul 12, 2022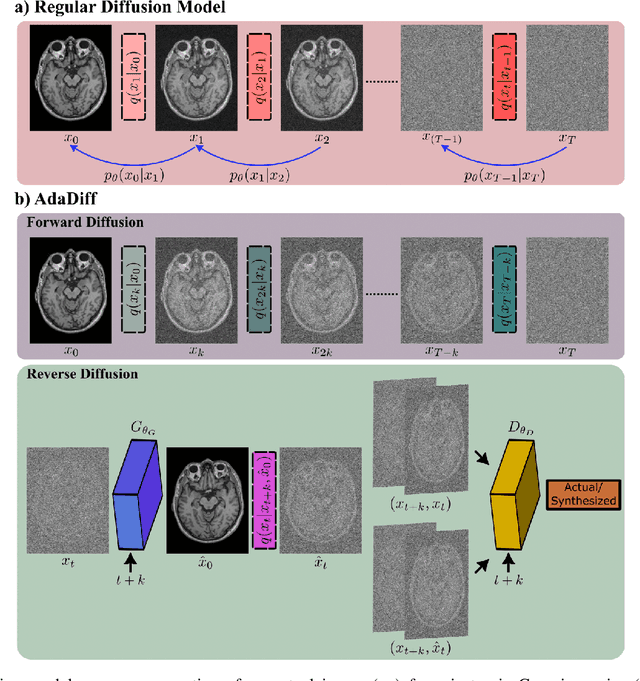
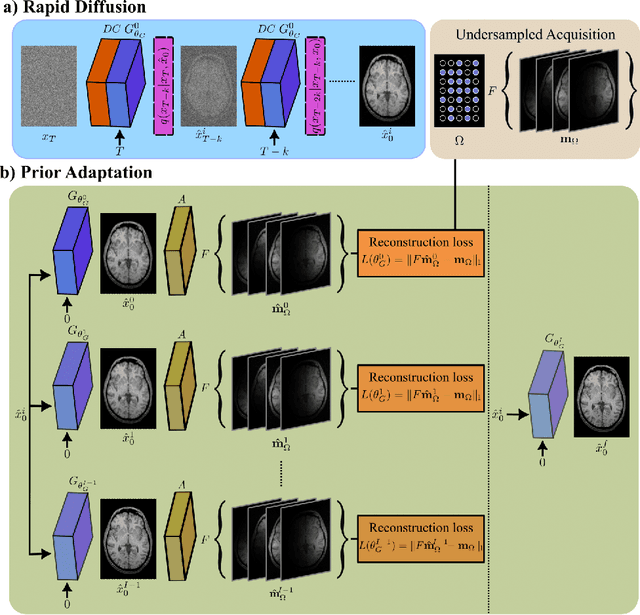
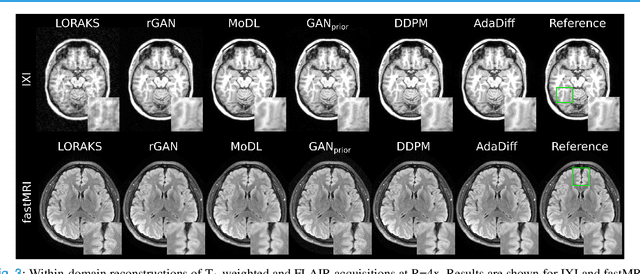
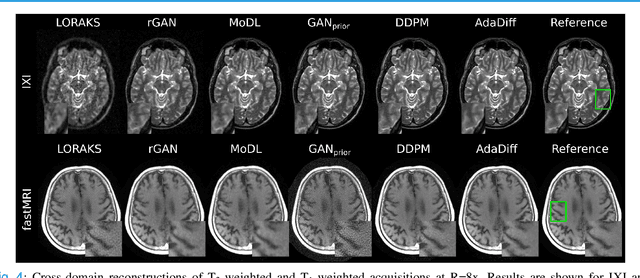
Deep MRI reconstruction is commonly performed with conditional models that map undersampled data as input onto fully-sampled data as output. Conditional models perform de-aliasing under knowledge of the accelerated imaging operator, so they poorly generalize under domain shifts in the operator. Unconditional models are a powerful alternative that instead learn generative image priors to improve reliability against domain shifts. Recent diffusion models are particularly promising given their high representational diversity and sample quality. Nevertheless, projections through a static image prior can lead to suboptimal performance. Here we propose a novel MRI reconstruction, AdaDiff, based on an adaptive diffusion prior. To enable efficient image sampling, an adversarial mapper is introduced that enables use of large diffusion steps. A two-phase reconstruction is performed with the trained prior: a rapid-diffusion phase that produces an initial reconstruction, and an adaptation phase where the diffusion prior is updated to minimize reconstruction loss on acquired k-space data. Demonstrations on multi-contrast brain MRI clearly indicate that AdaDiff achieves superior performance to competing models in cross-domain tasks, and superior or on par performance in within-domain tasks.
BolT: Fused Window Transformers for fMRI Time Series Analysis
May 23, 2022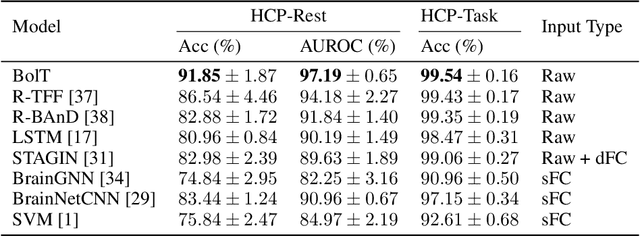
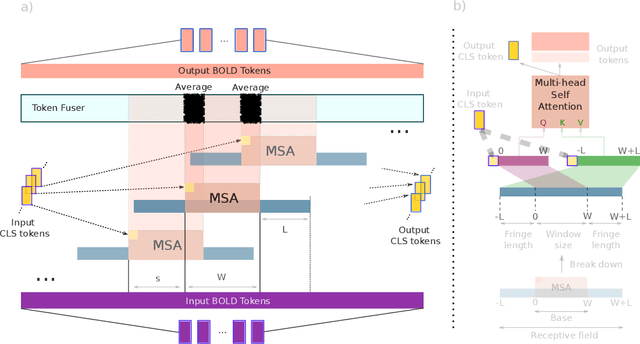
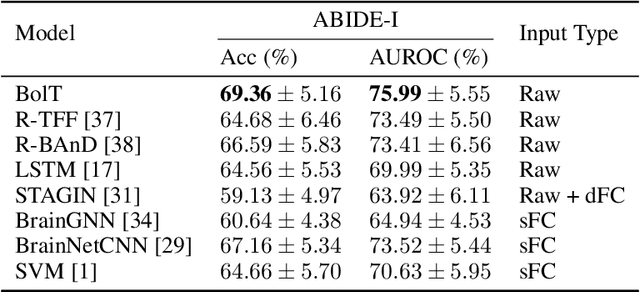
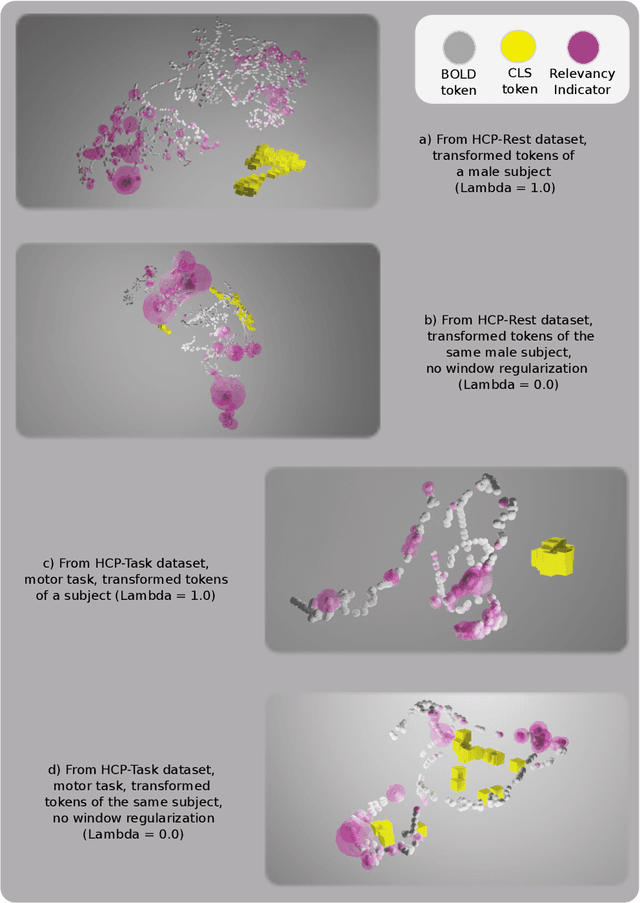
Functional magnetic resonance imaging (fMRI) enables examination of inter-regional interactions in the brain via functional connectivity (FC) analyses that measure the synchrony between the temporal activations of separate regions. Given their exceptional sensitivity, deep-learning methods have received growing interest for FC analyses of high-dimensional fMRI data. In this domain, models that operate directly on raw time series as opposed to pre-computed FC features have the potential benefit of leveraging the full scale of information present in fMRI data. However, previous models are based on architectures suboptimal for temporal integration of representations across multiple time scales. Here, we present BolT, blood-oxygen-level-dependent transformer, for analyzing multi-variate fMRI time series. BolT leverages a cascade of transformer encoders equipped with a novel fused window attention mechanism. Transformer encoding is performed on temporally-overlapped time windows within the fMRI time series to capture short time-scale representations. To integrate information across windows, cross-window attention is computed between base tokens in each time window and fringe tokens from neighboring time windows. To transition from local to global representations, the extent of window overlap and thereby number of fringe tokens is progressively increased across the cascade. Finally, a novel cross-window regularization is enforced to align the high-level representations of global $CLS$ features across time windows. Comprehensive experiments on public fMRI datasets clearly illustrate the superior performance of BolT against state-of-the-art methods. Posthoc explanatory analyses to identify landmark time points and regions that contribute most significantly to model decisions corroborate prominent neuroscientific findings from recent fMRI studies.
Federated Learning of Generative Image Priors for MRI Reconstruction
Feb 08, 2022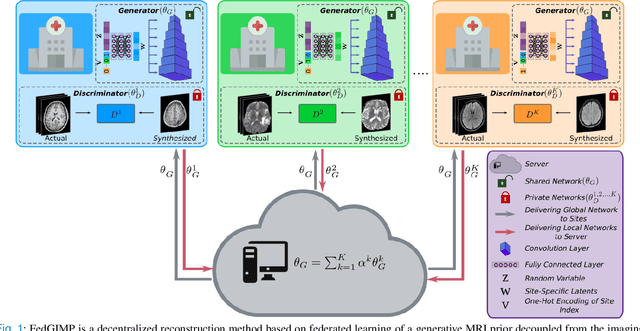
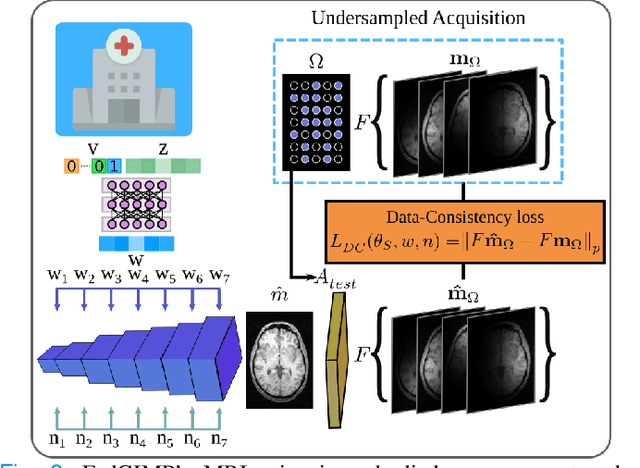
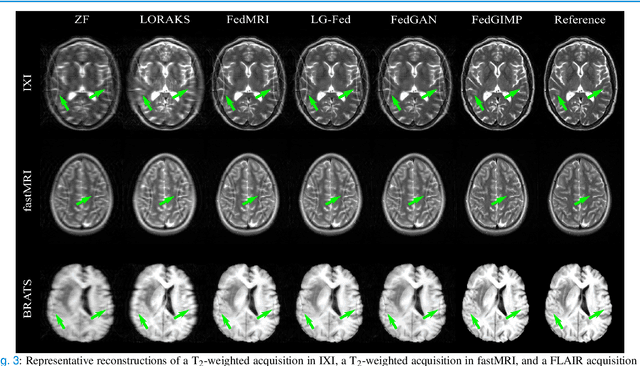
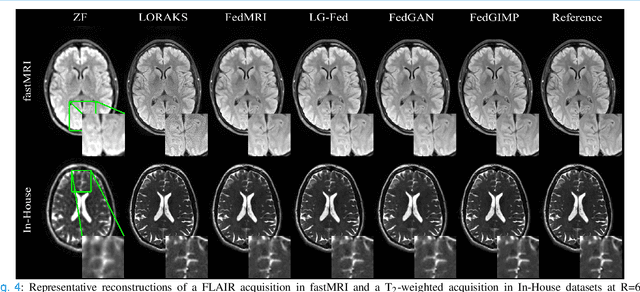
Multi-institutional efforts can facilitate training of deep MRI reconstruction models, albeit privacy risks arise during cross-site sharing of imaging data. Federated learning (FL) has recently been introduced to address privacy concerns by enabling distributed training without transfer of imaging data. Existing FL methods for MRI reconstruction employ conditional models to map from undersampled to fully-sampled acquisitions via explicit knowledge of the imaging operator. Since conditional models generalize poorly across different acceleration rates or sampling densities, imaging operators must be fixed between training and testing, and they are typically matched across sites. To improve generalization and flexibility in multi-institutional collaborations, here we introduce a novel method for MRI reconstruction based on Federated learning of Generative IMage Priors (FedGIMP). FedGIMP leverages a two-stage approach: cross-site learning of a generative MRI prior, and subject-specific injection of the imaging operator. The global MRI prior is learned via an unconditional adversarial model that synthesizes high-quality MR images based on latent variables. Specificity in the prior is preserved via a mapper subnetwork that produces site-specific latents. During inference, the prior is combined with subject-specific imaging operators to enable reconstruction, and further adapted to individual test samples by minimizing data-consistency loss. Comprehensive experiments on multi-institutional datasets clearly demonstrate enhanced generalization performance of FedGIMP against site-specific and federated methods based on conditional models, as well as traditional reconstruction methods.
TranSMS: Transformers for Super-Resolution Calibration in Magnetic Particle Imaging
Nov 03, 2021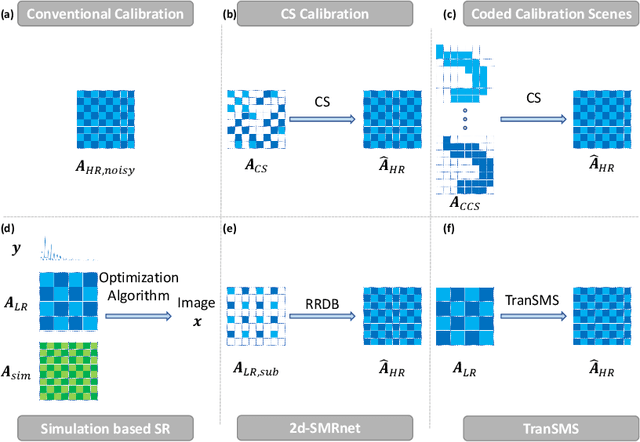
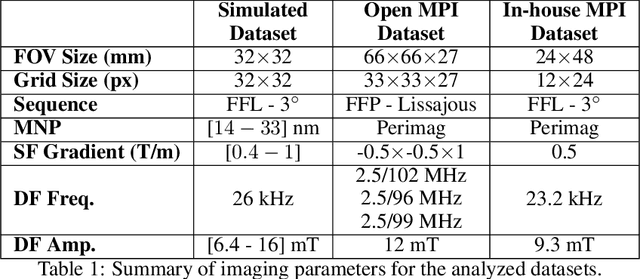
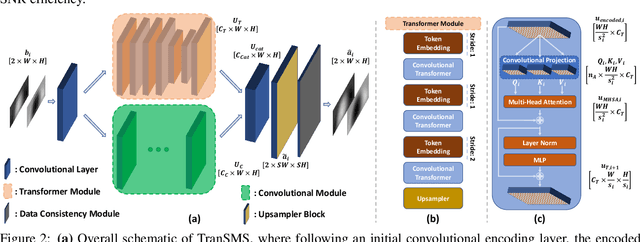
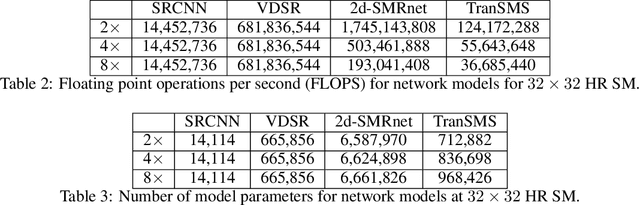
Magnetic particle imaging (MPI) is a recent modality that offers exceptional contrast for magnetic nanoparticles (MNP) at high spatio-temporal resolution. A common procedure in MPI starts with a calibration scan to measure the system matrix (SM), which is then used to setup an inverse problem to reconstruct images of the particle distribution during subsequent scans. This calibration enables the reconstruction to sensitively account for various system imperfections. Yet time-consuming SM measurements have to be repeated under notable drifts or changes in system properties. Here, we introduce a novel deep learning approach for accelerated MPI calibration based on transformers for SM super-resolution (TranSMS). Low-resolution SM measurements are performed using large MNP samples for improved signal-to-noise ratio efficiency, and the high-resolution SM is super-resolved via a model-based deep network. TranSMS leverages a vision transformer module to capture contextual relationships in low-resolution input images, a dense convolutional module for localizing high-resolution image features, and a data-consistency module to ensure consistency to measurements. Demonstrations on simulated and experimental data indicate that TranSMS achieves significantly improved SM recovery and image reconstruction in MPI, while enabling acceleration up to 64-fold during two-dimensional calibration.
ResViT: Residual vision transformers for multi-modal medical image synthesis
Jun 30, 2021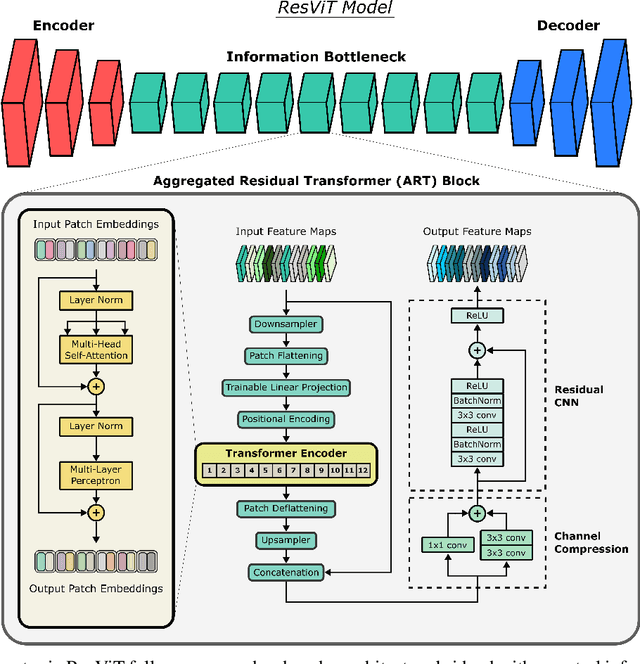
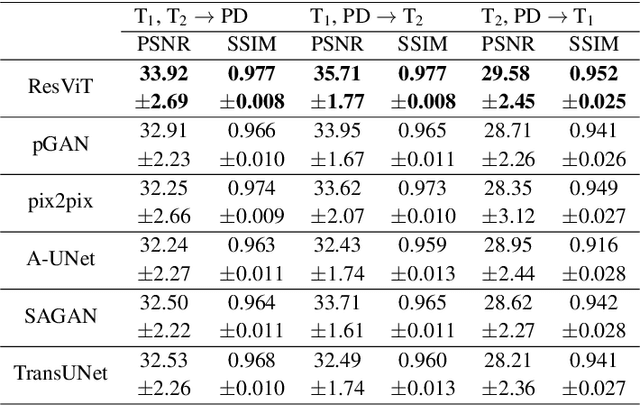
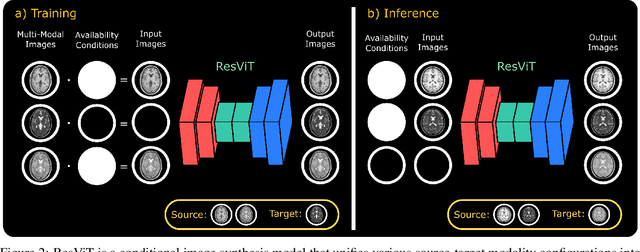
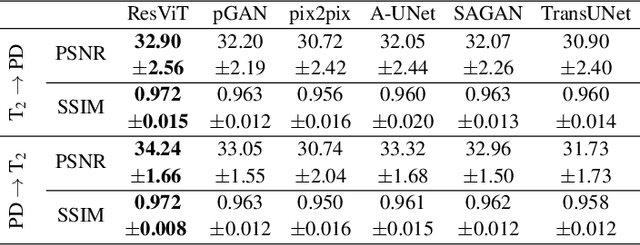
Multi-modal imaging is a key healthcare technology in the diagnosis and management of disease, but it is often underutilized due to costs associated with multiple separate scans. This limitation yields the need for synthesis of unacquired modalities from the subset of available modalities. In recent years, generative adversarial network (GAN) models with superior depiction of structural details have been established as state-of-the-art in numerous medical image synthesis tasks. However, GANs are characteristically based on convolutional neural network (CNN) backbones that perform local processing with compact filters. This inductive bias, in turn, compromises learning of long-range spatial dependencies. While attention maps incorporated in GANs can multiplicatively modulate CNN features to emphasize critical image regions, their capture of global context is mostly implicit. Here, we propose a novel generative adversarial approach for medical image synthesis, ResViT, to combine local precision of convolution operators with contextual sensitivity of vision transformers. Based on an encoder-decoder architecture, ResViT employs a central bottleneck comprising novel aggregated residual transformer (ART) blocks that synergistically combine convolutional and transformer modules. Comprehensive demonstrations are performed for synthesizing missing sequences in multi-contrast MRI and CT images from MRI. Our results indicate the superiority of ResViT against competing methods in terms of qualitative observations and quantitative metrics.
Constrained Ellipse Fitting for Efficient Parameter Mapping with Phase-cycled bSSFP MRI
Jun 06, 2021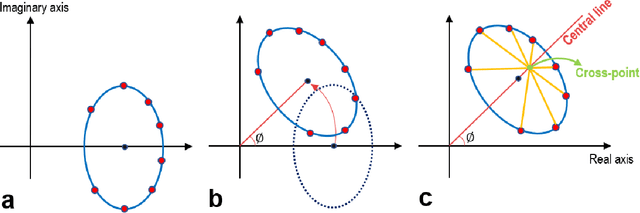
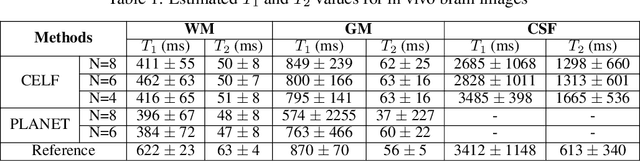

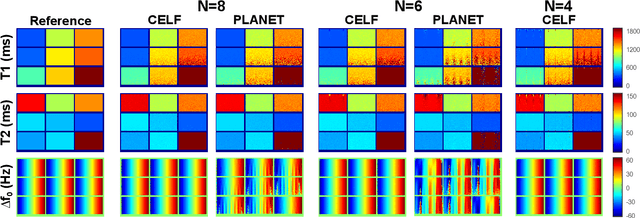
Balanced steady-state free precession (bSSFP) imaging enables high scan efficiency in MRI, but differs from conventional sequences in terms of elevated sensitivity to main field inhomogeneity and nonstandard T2/T1-weighted tissue contrast. To address these limitations, multiple bSSFP images of the same anatomy are commonly acquired with a set of different RF phase-cycling increments. Joint processing of phase-cycled acquisitions serves to mitigate sensitivity to field inhomogeneity. Recently phase-cycled bSSFP acquisitions were also leveraged to estimate relaxation parameters based on explicit signal models. While effective, these model-based methods often involve a large number of acquisitions (N~10-16), degrading scan efficiency. Here, we propose a new constrained ellipse fitting method (CELF) for parameter estimation with improved efficiency and accuracy in phase-cycled bSSFP MRI. CELF is based on the elliptical signal model framework for complex bSSFP signals; and it introduces geometrical constraints on ellipse properties to improve estimation efficiency, and dictionary-based identification to improve estimation accuracy. Simulated, phantom and in vivo experiments demonstrate that the proposed method enables enhanced parameter estimation with as few as N=4 acquisitions, thus it holds great potential for improving utility of bSSFP-based parametric mapping.
Unsupervised MRI Reconstruction via Zero-Shot Learned Adversarial Transformers
May 21, 2021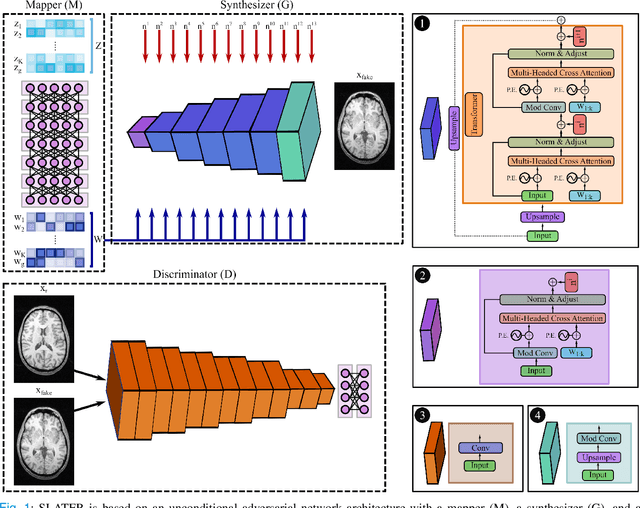
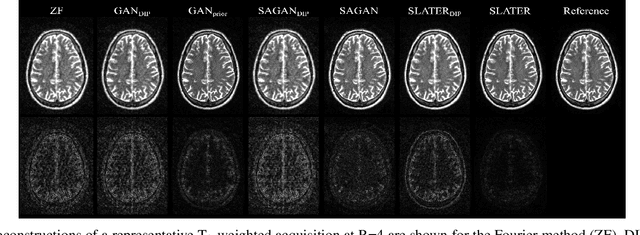
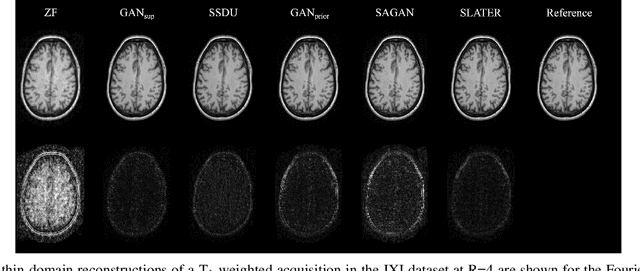
Supervised deep learning has swiftly become a workhorse for accelerated MRI in recent years, offering state-of-the-art performance in image reconstruction from undersampled acquisitions. Training deep supervised models requires large datasets of undersampled and fully-sampled acquisitions typically from a matching set of subjects. Given scarce access to large medical datasets, this limitation has sparked interest in unsupervised methods that reduce reliance on fully-sampled ground-truth data. A common framework is based on the deep image prior, where network-driven regularization is enforced directly during inference on undersampled acquisitions. Yet, canonical convolutional architectures are suboptimal in capturing long-range relationships, and randomly initialized networks may hamper convergence. To address these limitations, here we introduce a novel unsupervised MRI reconstruction method based on zero-Shot Learned Adversarial TransformERs (SLATER). SLATER embodies a deep adversarial network with cross-attention transformer blocks to map noise and latent variables onto MR images. This unconditional network learns a high-quality MRI prior in a self-supervised encoding task. A zero-shot reconstruction is performed on undersampled test data, where inference is performed by optimizing network parameters, latent and noise variables to ensure maximal consistency to multi-coil MRI data. Comprehensive experiments on brain MRI datasets clearly demonstrate the superior performance of SLATER against several state-of-the-art unsupervised methods.
A Few-Shot Learning Approach for Accelerated MRI via Fusion of Data-Driven and Subject-Driven Priors
Mar 13, 2021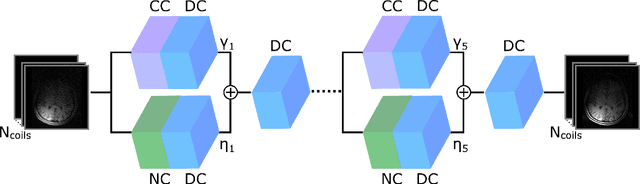

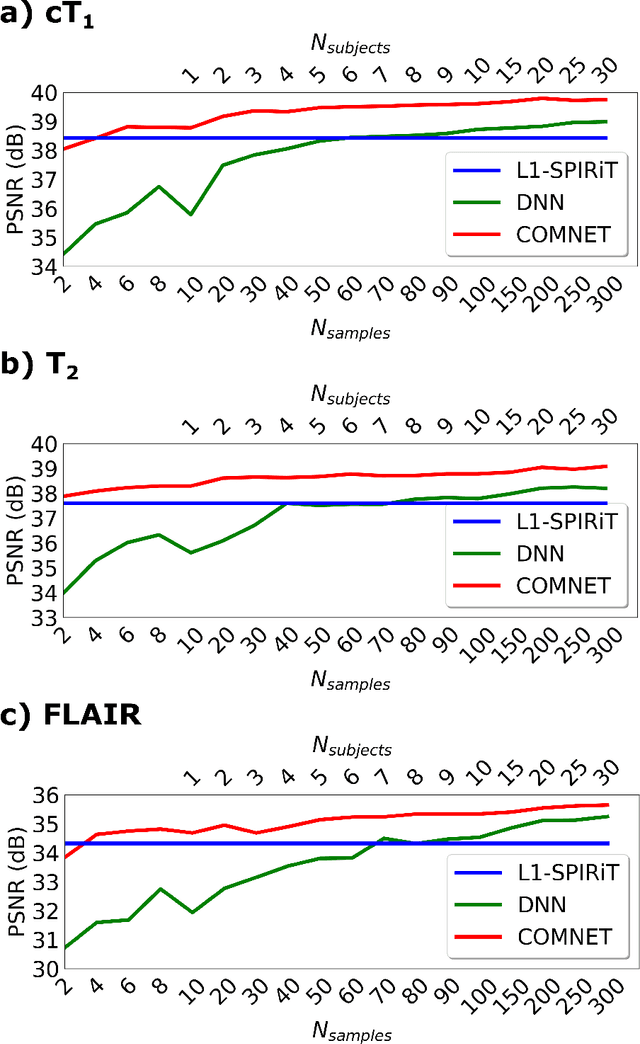
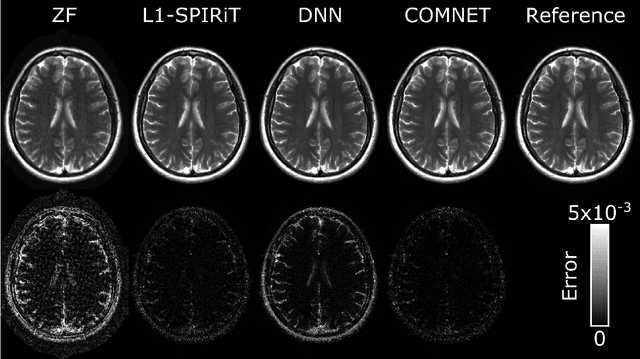
Deep neural networks (DNNs) have recently found emerging use in accelerated MRI reconstruction. DNNs typically learn data-driven priors from large datasets constituting pairs of undersampled and fully-sampled acquisitions. Acquiring such large datasets, however, might be impractical. To mitigate this limitation, we propose a few-shot learning approach for accelerated MRI that merges subject-driven priors obtained via physical signal models with data-driven priors obtained from a few training samples. Demonstrations on brain MR images from the NYU fastMRI dataset indicate that the proposed approach requires just a few samples to outperform traditional parallel imaging and DNN algorithms.
Three Dimensional MR Image Synthesis with Progressive Generative Adversarial Networks
Dec 18, 2020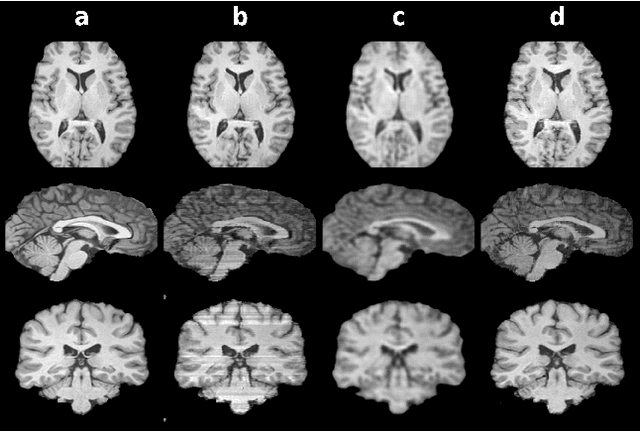
Mainstream deep models for three-dimensional MRI synthesis are either cross-sectional or volumetric depending on the input. Cross-sectional models can decrease the model complexity, but they may lead to discontinuity artifacts. On the other hand, volumetric models can alleviate the discontinuity artifacts, but they might suffer from loss of spatial resolution due to increased model complexity coupled with scarce training data. To mitigate the limitations of both approaches, we propose a novel model that progressively recovers the target volume via simpler synthesis tasks across individual orientations.