 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInstantiating Bayesian CVaR lower bounds in Interactive Decision Making Problems
Apr 14, 2026Recent work established a generalized-Fano framework for lower bounding prior-predictive (Bayesian) CVaR in interactive statistical decision making. In this paper, we show how to instantiate that framework in concrete interactive problems and derive explicit Bayesian CVaR lower bounds from its abstract corollaries. Our approach compares a hard model with a reference model using squared Hellinger distance, and combines a lower bound on a reference hinge term with a bound on the distinguishability of the two models. We apply this approach to canonical examples, including Gaussian bandits, and obtain explicit bounds that make the dependence on key problem parameters transparent. These results show how the generalized-Fano Bayesian CVaR framework can be used as a practical lower-bound tool for interactive learning and risk-sensitive decision making.
Refined PAC-Bayes Bounds for Offline Bandits
Feb 17, 2025In this paper, we present refined probabilistic bounds on empirical reward estimates for off-policy learning in bandit problems. We build on the PAC-Bayesian bounds from Seldin et al. (2010) and improve on their results using a new parameter optimization approach introduced by Rodr\'iguez et al. (2024). This technique is based on a discretization of the space of possible events to optimize the "in probability" parameter. We provide two parameter-free PAC-Bayes bounds, one based on Hoeffding-Azuma's inequality and the other based on Bernstein's inequality. We prove that our bounds are almost optimal as they recover the same rate as would be obtained by setting the "in probability" parameter after the realization of the data.
Information-Theoretic Minimax Regret Bounds for Reinforcement Learning based on Duality
Oct 21, 2024We study agents acting in an unknown environment where the agent's goal is to find a robust policy. We consider robust policies as policies that achieve high cumulative rewards for all possible environments. To this end, we consider agents minimizing the maximum regret over different environment parameters, leading to the study of minimax regret. This research focuses on deriving information-theoretic bounds for minimax regret in Markov Decision Processes (MDPs) with a finite time horizon. Building on concepts from supervised learning, such as minimum excess risk (MER) and minimax excess risk, we use recent bounds on the Bayesian regret to derive minimax regret bounds. Specifically, we establish minimax theorems and use bounds on the Bayesian regret to perform minimax regret analysis using these minimax theorems. Our contributions include defining a suitable minimax regret in the context of MDPs, finding information-theoretic bounds for it, and applying these bounds in various scenarios.
Chained Information-Theoretic bounds and Tight Regret Rate for Linear Bandit Problems
Mar 05, 2024This paper studies the Bayesian regret of a variant of the Thompson-Sampling algorithm for bandit problems. It builds upon the information-theoretic framework of [Russo and Van Roy, 2015] and, more specifically, on the rate-distortion analysis from [Dong and Van Roy, 2020], where they proved a bound with regret rate of $O(d\sqrt{T \log(T)})$ for the $d$-dimensional linear bandit setting. We focus on bandit problems with a metric action space and, using a chaining argument, we establish new bounds that depend on the metric entropy of the action space for a variant of Thompson-Sampling. Under suitable continuity assumption of the rewards, our bound offers a tight rate of $O(d\sqrt{T})$ for $d$-dimensional linear bandit problems.
Thompson Sampling Regret Bounds for Contextual Bandits with sub-Gaussian rewards
Apr 26, 2023In this work, we study the performance of the Thompson Sampling algorithm for Contextual Bandit problems based on the framework introduced by Neu et al. and their concept of lifted information ratio. First, we prove a comprehensive bound on the Thompson Sampling expected cumulative regret that depends on the mutual information of the environment parameters and the history. Then, we introduce new bounds on the lifted information ratio that hold for sub-Gaussian rewards, thus generalizing the results from Neu et al. which analysis requires binary rewards. Finally, we provide explicit regret bounds for the special cases of unstructured bounded contextual bandits, structured bounded contextual bandits with Laplace likelihood, structured Bernoulli bandits, and bounded linear contextual bandits.
An Information-Theoretic Analysis of Bayesian Reinforcement Learning
Jul 18, 2022Building on the framework introduced by Xu and Raginksy [1] for supervised learning problems, we study the best achievable performance for model-based Bayesian reinforcement learning problems. With this purpose, we define minimum Bayesian regret (MBR) as the difference between the maximum expected cumulative reward obtainable either by learning from the collected data or by knowing the environment and its dynamics. We specialize this definition to reinforcement learning problems modeled as Markov decision processes (MDPs) whose kernel parameters are unknown to the agent and whose uncertainty is expressed by a prior distribution. One method for deriving upper bounds on the MBR is presented and specific bounds based on the relative entropy and the Wasserstein distance are given. We then focus on two particular cases of MDPs, the multi-armed bandit problem (MAB) and the online optimization with partial feedback problem. For the latter problem, we show that our bounds can recover from below the current information-theoretic bounds by Russo and Van Roy [2].
Decentralized Differentially Private Segmentation with PATE
Apr 10, 2020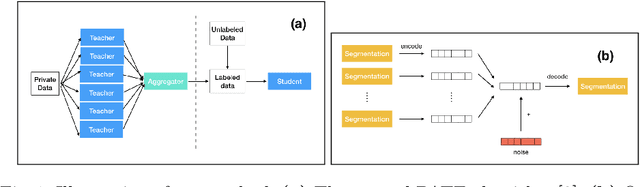
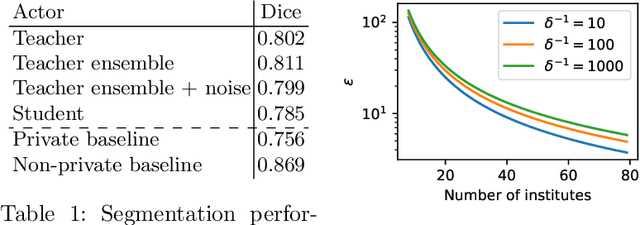
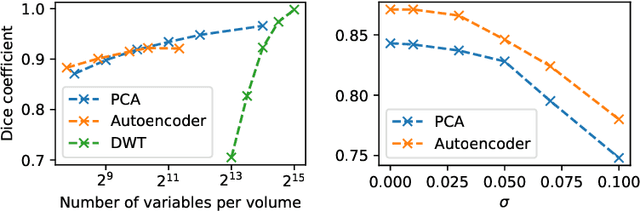
When it comes to preserving privacy in medical machine learning, two important considerations are (1) keeping data local to the institution and (2) avoiding inference of sensitive information from the trained model. These are often addressed using federated learning and differential privacy, respectively. However, the commonly used Federated Averaging algorithm requires a high degree of synchronization between participating institutions. For this reason, we turn our attention to Private Aggregation of Teacher Ensembles (PATE), where all local models can be trained independently without inter-institutional communication. The purpose of this paper is thus to explore how PATE -- originally designed for classification -- can best be adapted for semantic segmentation. To this end, we build low-dimensional representations of segmentation masks which the student can obtain through low-sensitivity queries to the private aggregator. On the Brain Tumor Segmentation (BraTS 2019) dataset, an Autoencoder-based PATE variant achieves a higher Dice coefficient for the same privacy guarantee than prior work based on noisy Federated Averaging.