 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNearly Optimal Subdata Selection
Apr 27, 2026When, in terms of the number of data points, the size of a dataset exceeds available computing resources, or when labeling is expensive, an attractive solution consists of selecting only some of the data points (subdata) for further consideration. A central question for selecting subdata of size $n$ from $N$ available data points is which $n$ points to select. While an answer to this question depends on the objective, one approach for a parametric model and a focus on parameter estimation is to select subdata that retains maximal information. Identifying such subdata is a classical NP-hard problem due to its inherent discreteness. Based on optimal approximate design theory, we develop a new methodology for information-based subdata selection, resulting in subdata that approaches the optimal solution. To achieve this, we develop a novel algorithm that applies to a general model, accommodates arbitrary choices of $N$ and $n$, and supports multiple optimality criteria, and we prove its convergence. Moreover, the new methodology facilitates an assessment of the efficiency of subdata selected by any method by obtaining tight lower and upper bounds for the efficiency. We show that the subdata obtained through the new methodology is highly efficient and outperforms all existing methods.
Interpretable travel distance on the county-wise COVID-19 by sequence to sequence with attention
May 26, 2022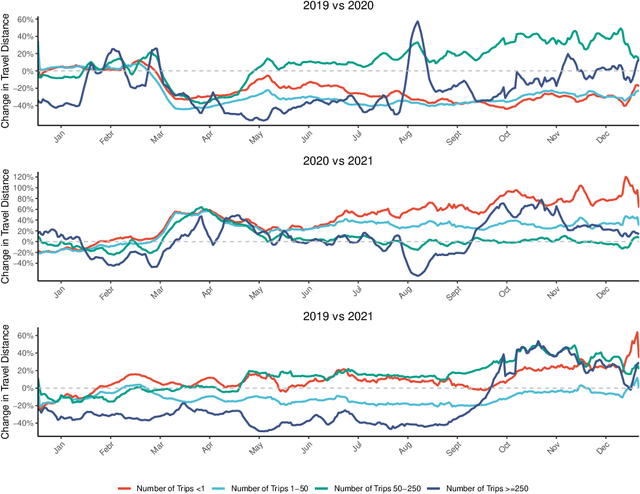
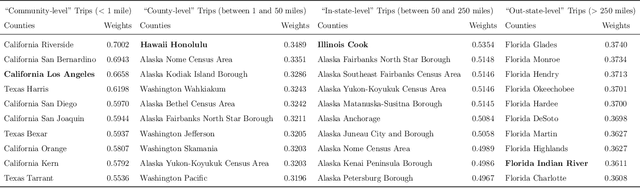
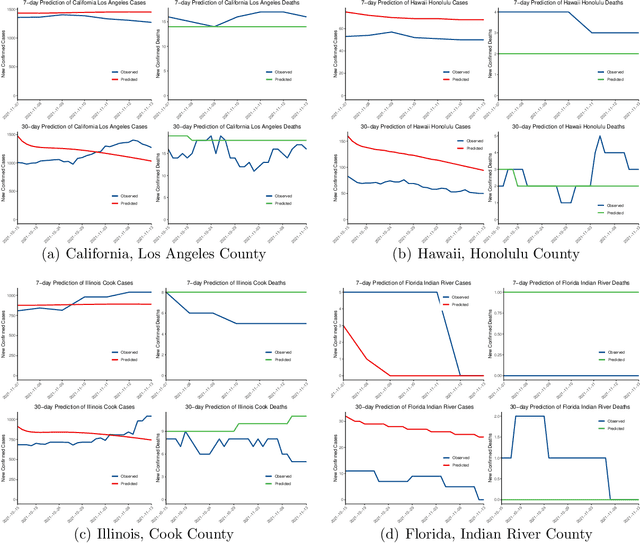
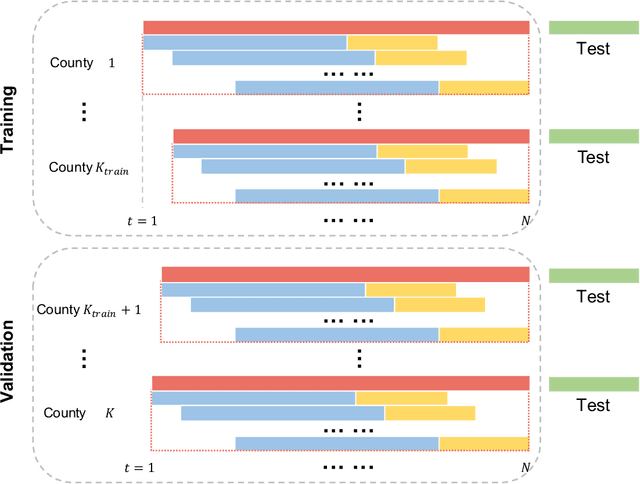
Background: Travel restrictions as a means of intervention in the COVID-19 epidemic have reduced the spread of outbreaks using epidemiological models. We introduce the attention module in the sequencing model to assess the effects of the different classes of travel distances. Objective: To establish a direct relationship between the number of travelers for various travel distances and the COVID-19 trajectories. To improve the prediction performance of sequencing model. Setting: Counties from all over the United States. Participants: New confirmed cases and deaths have been reported in 3158 counties across the United States. Measurements: Outcomes included new confirmed cases and deaths in the 30 days preceding November 13, 2021. The daily number of trips taken by the population for various classes of travel distances and the geographical information of infected counties are assessed. Results: There is a spatial pattern of various classes of travel distances across the country. The varying geographical effects of the number of people travelling for different distances on the epidemic spread are demonstrated. Limitation: We examined data up to November 13, 2021, and the weights of each class of travel distances may change accordingly as the data evolves. Conclusion: Given the weights of people taking trips for various classes of travel distances, the epidemics could be mitigated by reducing the corresponding class of travellers.