 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNearly Optimal Subdata Selection
Apr 27, 2026When, in terms of the number of data points, the size of a dataset exceeds available computing resources, or when labeling is expensive, an attractive solution consists of selecting only some of the data points (subdata) for further consideration. A central question for selecting subdata of size $n$ from $N$ available data points is which $n$ points to select. While an answer to this question depends on the objective, one approach for a parametric model and a focus on parameter estimation is to select subdata that retains maximal information. Identifying such subdata is a classical NP-hard problem due to its inherent discreteness. Based on optimal approximate design theory, we develop a new methodology for information-based subdata selection, resulting in subdata that approaches the optimal solution. To achieve this, we develop a novel algorithm that applies to a general model, accommodates arbitrary choices of $N$ and $n$, and supports multiple optimality criteria, and we prove its convergence. Moreover, the new methodology facilitates an assessment of the efficiency of subdata selected by any method by obtaining tight lower and upper bounds for the efficiency. We show that the subdata obtained through the new methodology is highly efficient and outperforms all existing methods.
Factor selection in screening experiments by aggregation over random models
May 26, 2022
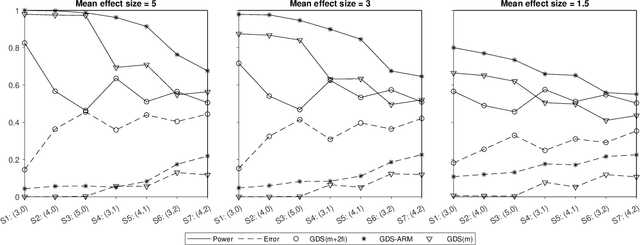


Screening experiments are useful for screening out a small number of truly important factors from a large number of potentially important factors. The Gauss-Dantzig Selector (GDS) is often the preferred analysis method for screening experiments. Just considering main-effects models can result in erroneous conclusions, but including interaction terms, even if restricted to two-factor interactions, increases the number of model terms dramatically and challenges the GDS analysis. We propose a new analysis method, called Gauss-Dantzig Selector Aggregation over Random Models (GDS-ARM), which performs a GDS analysis on multiple models that include only some randomly selected interactions. Results from these different analyses are then aggregated to identify the important factors. We discuss the proposed method, suggest choices for the tuning parameters, and study its performance on real and simulated data.