 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTuckER: Tensor Factorization for Knowledge Graph Completion
Jan 28, 2019
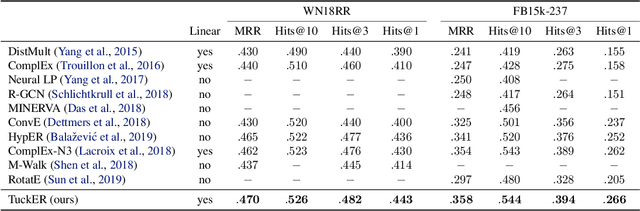
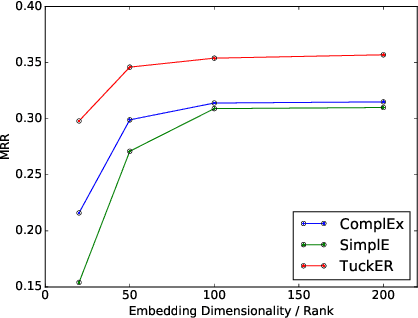
Knowledge graphs are structured representations of real world facts. However, they typically contain only a small subset of all possible facts. Link prediction is a task of inferring missing facts based on existing ones. We propose TuckER, a relatively simple but powerful linear model based on Tucker decomposition of the binary tensor representation of knowledge graph triples. TuckER outperforms all previous state-of-the-art models across standard link prediction datasets. We prove that TuckER is a fully expressive model, deriving the bound on its entity and relation embedding dimensionality for full expressiveness which is several orders of magnitude smaller than the bound of previous state-of-the-art models ComplEx and SimplE. We further show that several previously introduced linear models can be viewed as special cases of TuckER.
Disjoint Label Space Transfer Learning with Common Factorised Space
Dec 06, 2018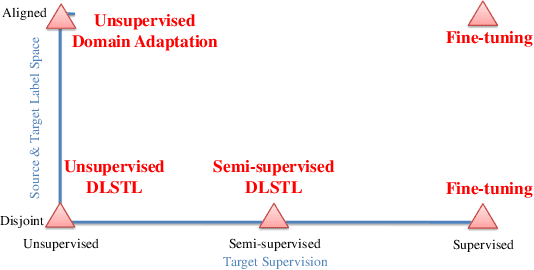
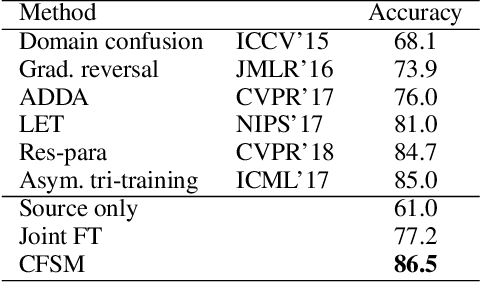
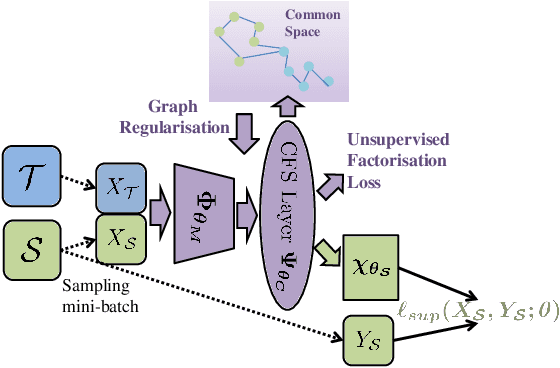
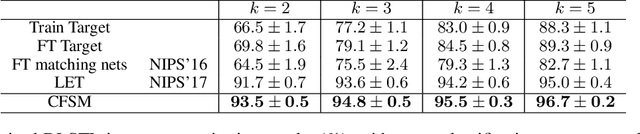
In this paper, a unified approach is presented to transfer learning that addresses several source and target domain label-space and annotation assumptions with a single model. It is particularly effective in handling a challenging case, where source and target label-spaces are disjoint, and outperforms alternatives in both unsupervised and semi-supervised settings. The key ingredient is a common representation termed Common Factorised Space. It is shared between source and target domains, and trained with an unsupervised factorisation loss and a graph-based loss. With a wide range of experiments, we demonstrate the flexibility, relevance and efficacy of our method, both in the challenging cases with disjoint label spaces, and in the more conventional cases such as unsupervised domain adaptation, where the source and target domains share the same label-sets.
Deep Comparison: Relation Columns for Few-Shot Learning
Nov 20, 2018
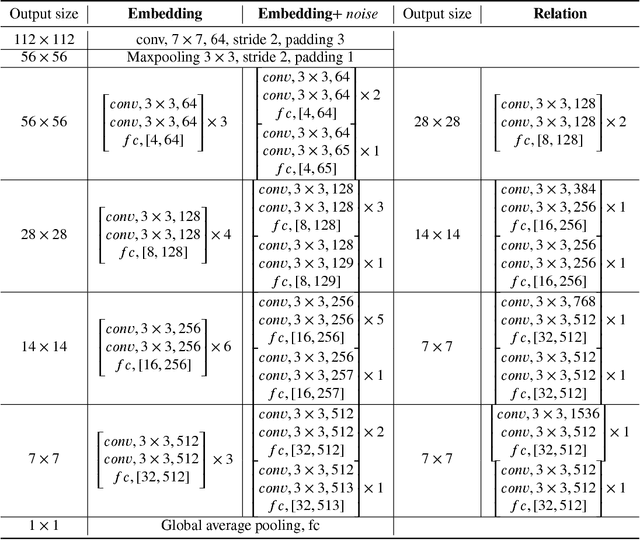
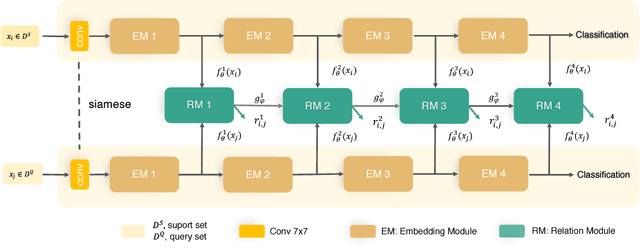
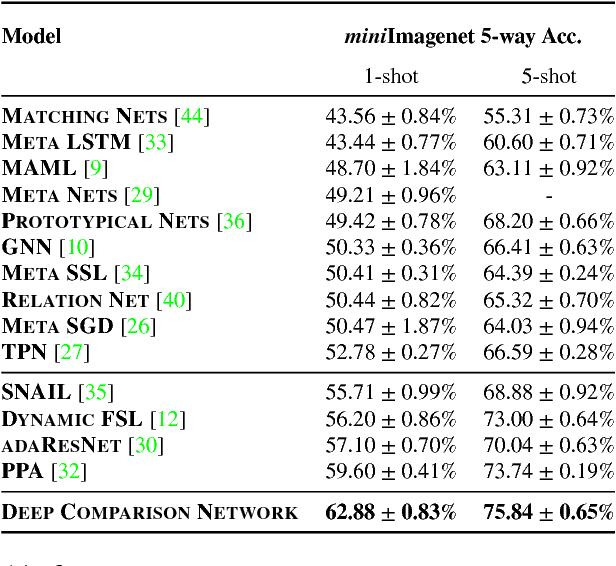
Few-shot deep learning is a topical challenge area for scaling visual recognition to open-ended growth in the space of categories to recognise. A promising line work towards realising this vision is deep networks that learn to match queries with stored training images. However, methods in this paradigm usually train a deep embedding followed by a single linear classifier. Our insight is that effective general-purpose matching requires discrimination with regards to features at multiple abstraction levels. We therefore propose a new framework termed Deep Comparison Network(DCN) that decomposes embedding learning into a sequence of modules, and pairs each with a relation module. The relation modules compute a non-linear metric to score the match using the corresponding embedding module's representation. To ensure that all embedding module's features are used, the relation modules are deeply supervised. Finally generalisation is further improved by a learned noise regulariser. The resulting network achieves state of the art performance on both miniImageNet and tieredImageNet, while retaining the appealing simplicity and efficiency of deep metric learning approaches.
Hypernetwork Knowledge Graph Embeddings
Oct 18, 2018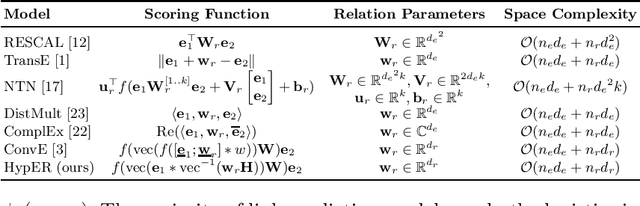
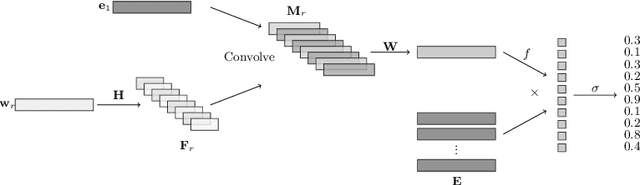
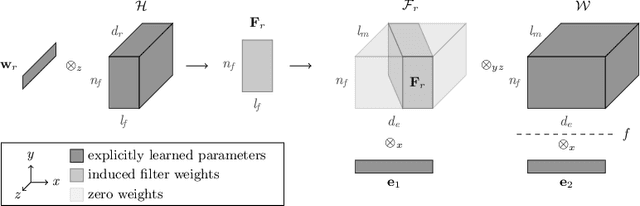

Knowledge graphs are large graph-structured databases of facts, which typically suffer from incompleteness. Link prediction is the task of inferring missing relations (links) between entities (nodes) in a knowledge graph. We approach this task using a hypernetwork architecture to generate convolutional layer filters specific to each relation and apply those filters to the subject entity embeddings. This architecture enables a trade-off between non-linear expressiveness and the number of parameters to learn. Our model simplifies the entity and relation embedding interactions introduced by the predecessor convolutional model, while outperforming all previous approaches to link prediction across all standard link prediction datasets.
Dynamic Ensemble Active Learning: A Non-Stationary Bandit with Expert Advice
Sep 29, 2018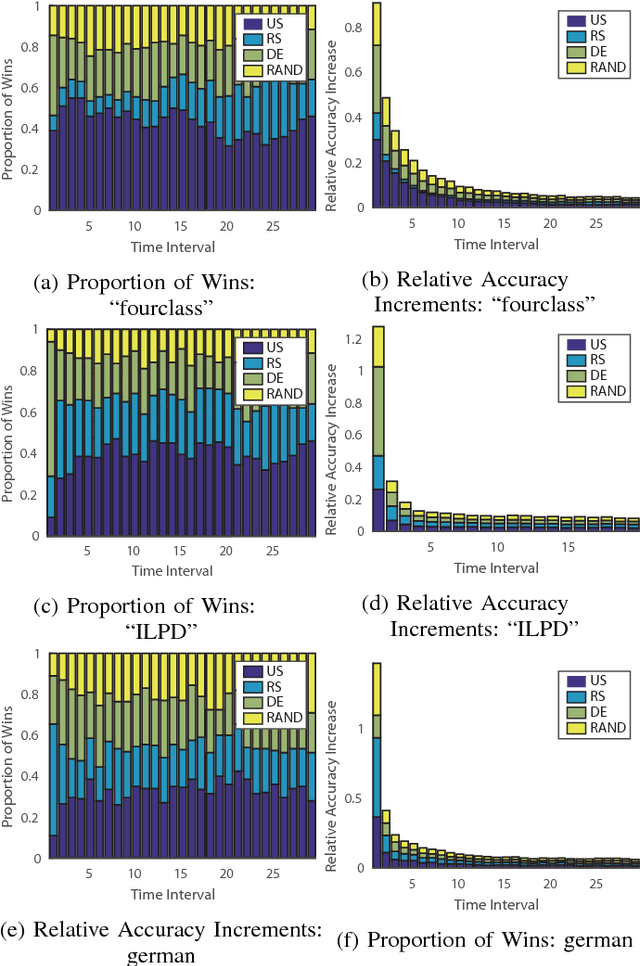
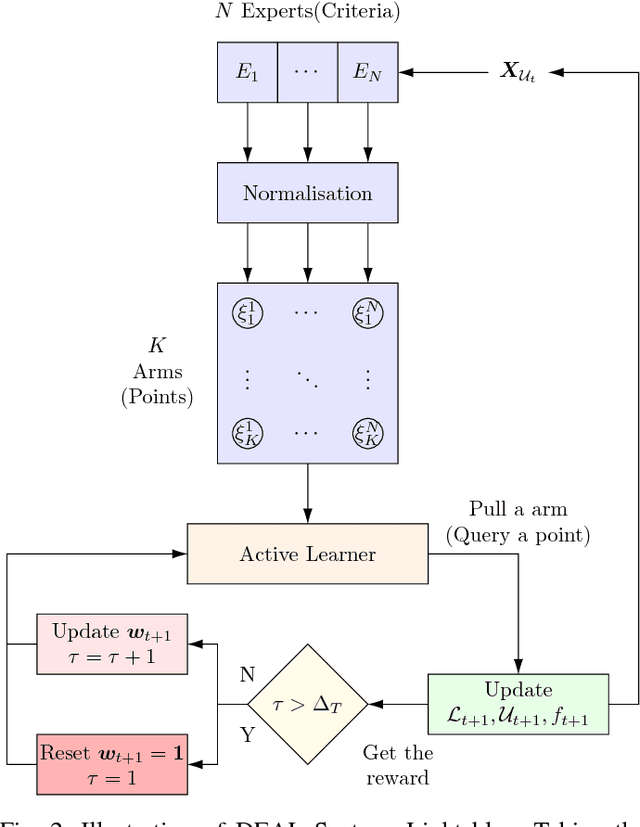
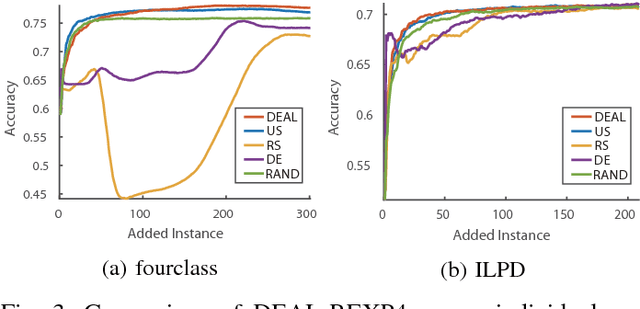
Active learning aims to reduce annotation cost by predicting which samples are useful for a human teacher to label. However it has become clear there is no best active learning algorithm. Inspired by various philosophies about what constitutes a good criteria, different algorithms perform well on different datasets. This has motivated research into ensembles of active learners that learn what constitutes a good criteria in a given scenario, typically via multi-armed bandit algorithms. Though algorithm ensembles can lead to better results, they overlook the fact that not only does algorithm efficacy vary across datasets, but also during a single active learning session. That is, the best criteria is non-stationary. This breaks existing algorithms' guarantees and hampers their performance in practice. In this paper, we propose dynamic ensemble active learning as a more general and promising research direction. We develop a dynamic ensemble active learner based on a non-stationary multi-armed bandit with expert advice algorithm. Our dynamic ensemble selects the right criteria at each step of active learning. It has theoretical guarantees, and shows encouraging results on $13$ popular datasets.
Deep Factorised Inverse-Sketching
Aug 07, 2018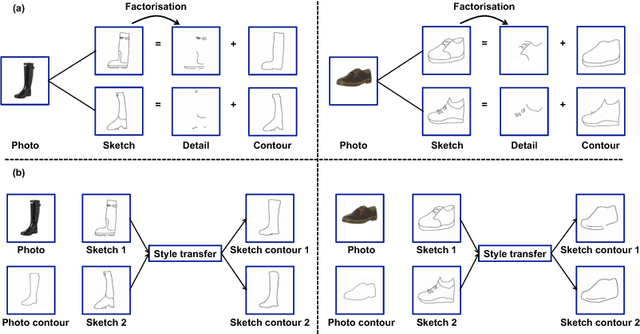
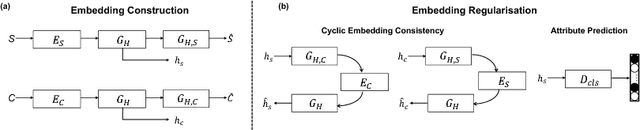
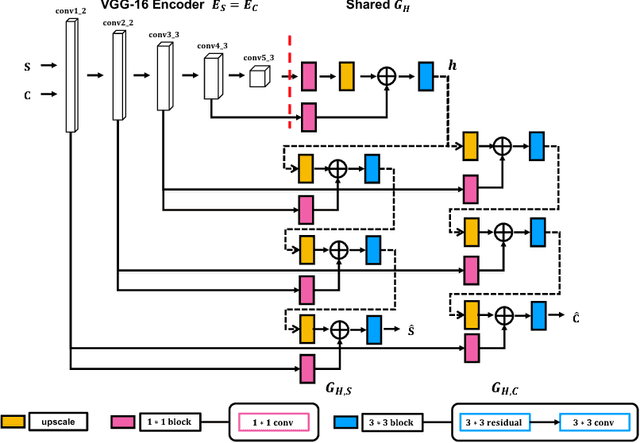
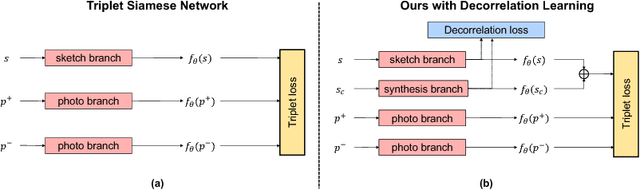
Modelling human free-hand sketches has become topical recently, driven by practical applications such as fine-grained sketch based image retrieval (FG-SBIR). Sketches are clearly related to photo edge-maps, but a human free-hand sketch of a photo is not simply a clean rendering of that photo's edge map. Instead there is a fundamental process of abstraction and iconic rendering, where overall geometry is warped and salient details are selectively included. In this paper we study this sketching process and attempt to invert it. We model this inversion by translating iconic free-hand sketches to contours that resemble more geometrically realistic projections of object boundaries, and separately factorise out the salient added details. This factorised re-representation makes it easier to match a free-hand sketch to a photo instance of an object. Specifically, we propose a novel unsupervised image style transfer model based on enforcing a cyclic embedding consistency constraint. A deep FG-SBIR model is then formulated to accommodate complementary discriminative detail from each factorised sketch for better matching with the corresponding photo. Our method is evaluated both qualitatively and quantitatively to demonstrate its superiority over a number of state-of-the-art alternatives for style transfer and FG-SBIR.
Universal Perceptual Grouping
Aug 07, 2018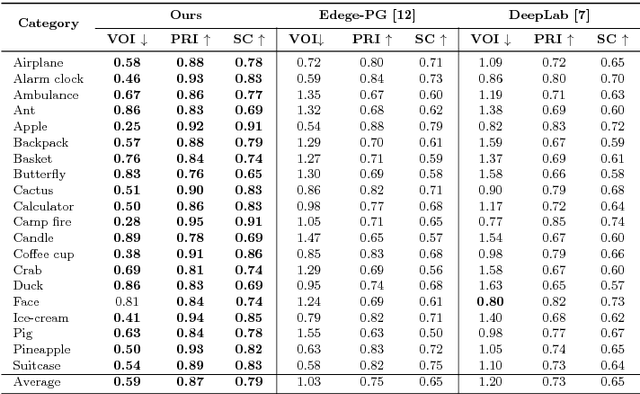
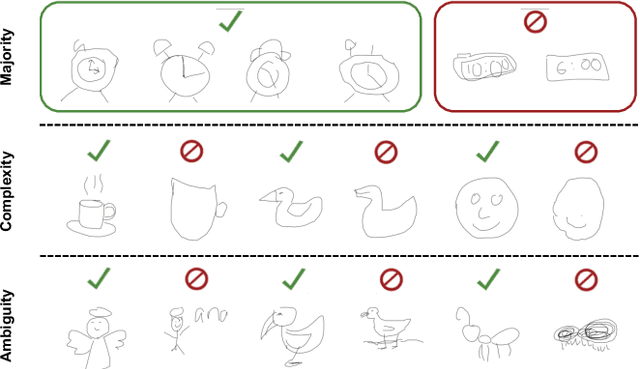
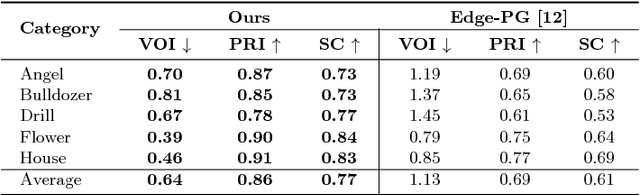
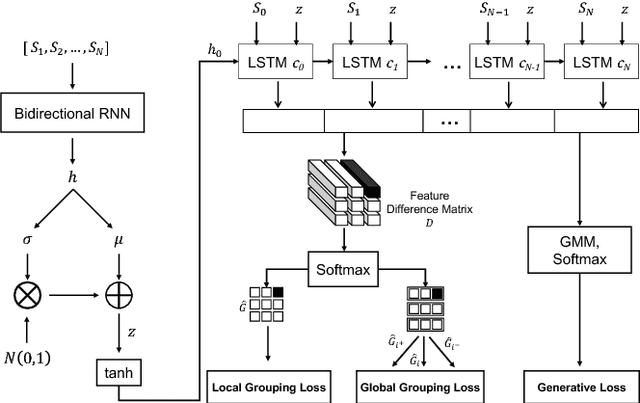
In this work we aim to develop a universal sketch grouper. That is, a grouper that can be applied to sketches of any category in any domain to group constituent strokes/segments into semantically meaningful object parts. The first obstacle to this goal is the lack of large-scale datasets with grouping annotation. To overcome this, we contribute the largest sketch perceptual grouping (SPG) dataset to date, consisting of 20,000 unique sketches evenly distributed over 25 object categories. Furthermore, we propose a novel deep universal perceptual grouping model. The model is learned with both generative and discriminative losses. The generative losses improve the generalisation ability of the model to unseen object categories and datasets. The discriminative losses include a local grouping loss and a novel global grouping loss to enforce global grouping consistency. We show that the proposed model significantly outperforms the state-of-the-art groupers. Further, we show that our grouper is useful for a number of sketch analysis tasks including sketch synthesis and fine-grained sketch-based image retrieval (FG-SBIR).
Deep Neural Decision Trees
Jun 19, 2018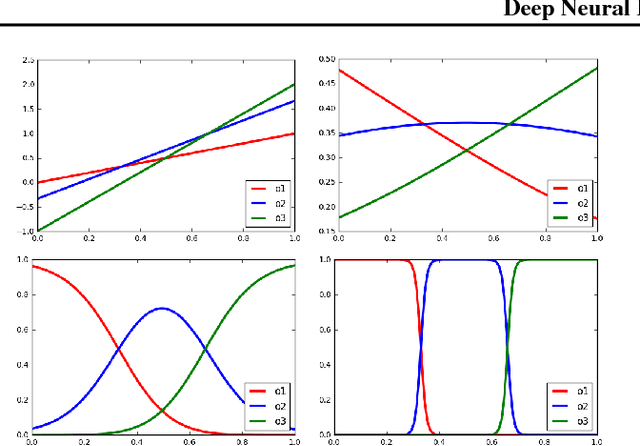
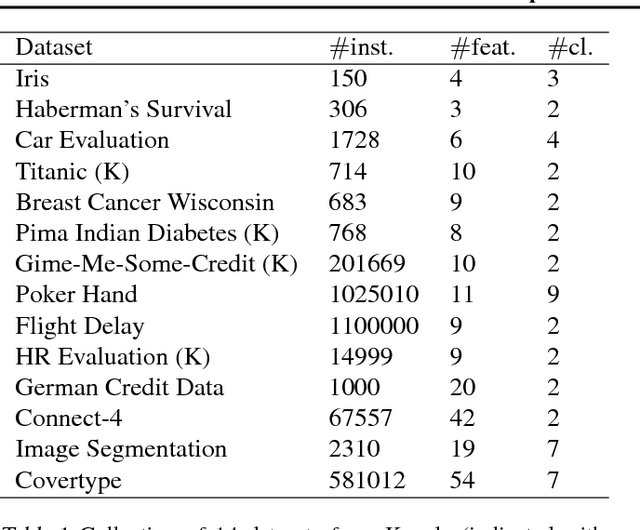
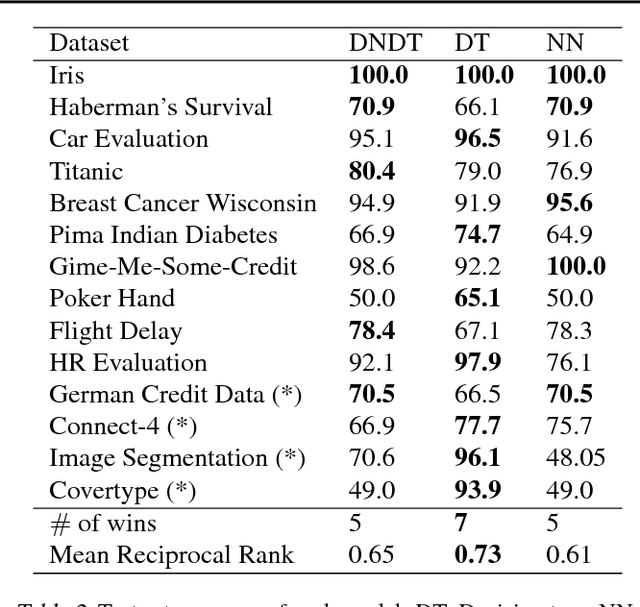

Deep neural networks have been proven powerful at processing perceptual data, such as images and audio. However for tabular data, tree-based models are more popular. A nice property of tree-based models is their natural interpretability. In this work, we present Deep Neural Decision Trees (DNDT) -- tree models realised by neural networks. A DNDT is intrinsically interpretable, as it is a tree. Yet as it is also a neural network (NN), it can be easily implemented in NN toolkits, and trained with gradient descent rather than greedy splitting. We evaluate DNDT on several tabular datasets, verify its efficacy, and investigate similarities and differences between DNDT and vanilla decision trees. Interestingly, DNDT self-prunes at both split and feature-level.
Sketch-a-Classifier: Sketch-based Photo Classifier Generation
Apr 30, 2018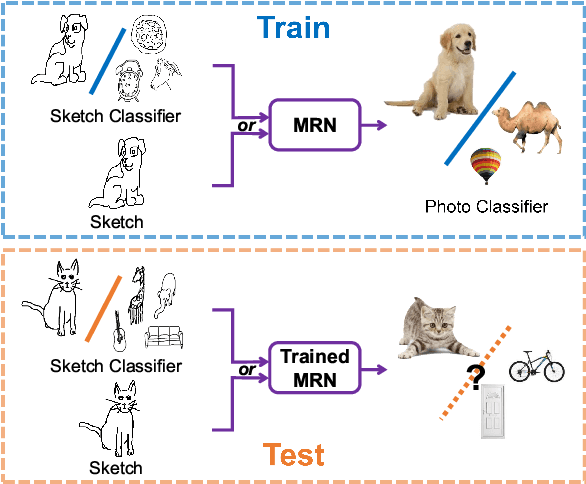

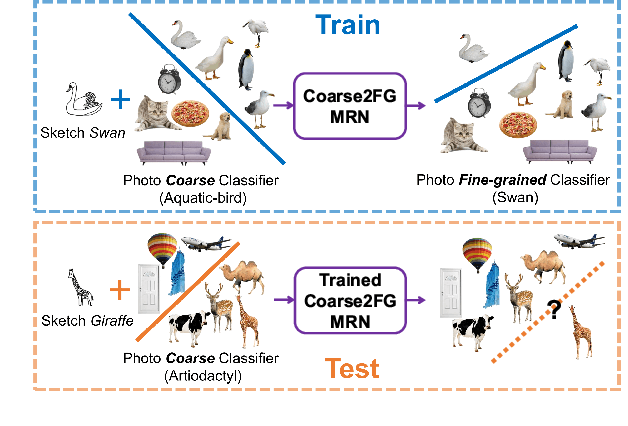
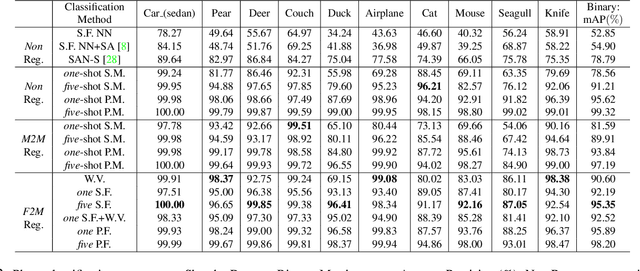
Contemporary deep learning techniques have made image recognition a reasonably reliable technology. However training effective photo classifiers typically takes numerous examples which limits image recognition's scalability and applicability to scenarios where images may not be available. This has motivated investigation into zero-shot learning, which addresses the issue via knowledge transfer from other modalities such as text. In this paper we investigate an alternative approach of synthesizing image classifiers: almost directly from a user's imagination, via free-hand sketch. This approach doesn't require the category to be nameable or describable via attributes as per zero-shot learning. We achieve this via training a {model regression} network to map from {free-hand sketch} space to the space of photo classifiers. It turns out that this mapping can be learned in a category-agnostic way, allowing photo classifiers for new categories to be synthesized by user with no need for annotated training photos. {We also demonstrate that this modality of classifier generation can also be used to enhance the granularity of an existing photo classifier, or as a complement to name-based zero-shot learning.
Multi-Level Factorisation Net for Person Re-Identification
Apr 17, 2018
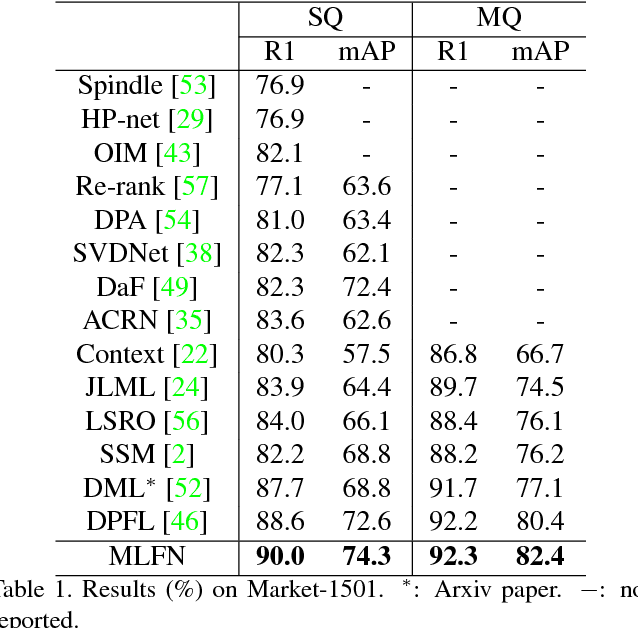
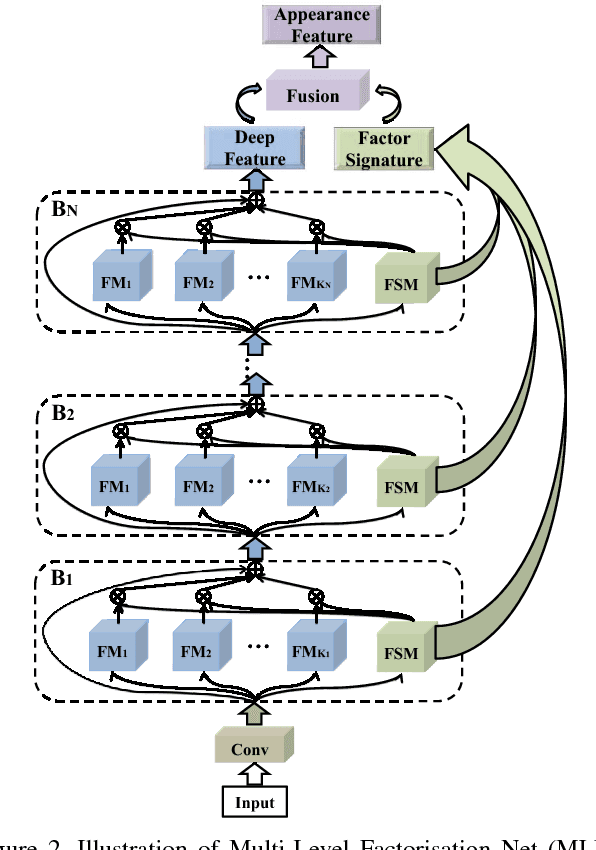
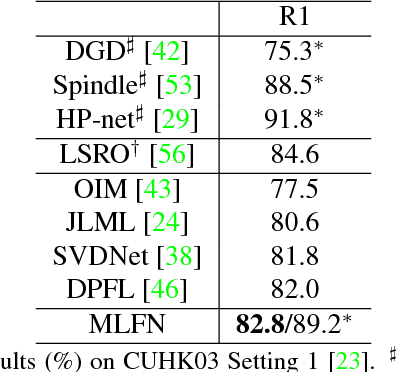
Key to effective person re-identification (Re-ID) is modelling discriminative and view-invariant factors of person appearance at both high and low semantic levels. Recently developed deep Re-ID models either learn a holistic single semantic level feature representation and/or require laborious human annotation of these factors as attributes. We propose Multi-Level Factorisation Net (MLFN), a novel network architecture that factorises the visual appearance of a person into latent discriminative factors at multiple semantic levels without manual annotation. MLFN is composed of multiple stacked blocks. Each block contains multiple factor modules to model latent factors at a specific level, and factor selection modules that dynamically select the factor modules to interpret the content of each input image. The outputs of the factor selection modules also provide a compact latent factor descriptor that is complementary to the conventional deeply learned features. MLFN achieves state-of-the-art results on three Re-ID datasets, as well as compelling results on the general object categorisation CIFAR-100 dataset.