 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Agent Reinforcement Learning for Safe Autonomous Driving Under Pedestrian Behavioral Uncertainty
May 18, 2026Simulation-based testing of self-driving cars (SDCs) typically relies on scripted or simplified pedestrian models that do not capture the heterogeneity and uncertainty of real human crossing behavior. This limits the realism of safety assessments, especially in scenarios involving jaywalking, which is governed by latent personality traits that the vehicle cannot observe. We hypothesize that jointly training pedestrians and the SDC with multi-agent reinforcement learning (MARL) produces more realistic interaction scenarios than training the SDC against fixed pedestrian policies, and that the resulting behavior gap between predictable and unpredictable crossings can be measured directly from trajectories. This paper describes a MARL environment in which an SDC and 12 pedestrians are co-trained using Multi-Agent Proximal Policy Optimization (MAPPO). Pedestrian locomotion follows scripted Dijkstra pathfinding, while an RL policy controls high-level go/wait decisions. Jaywalking probability depends on a per-pedestrian personality trait sampled at episode start and hidden from the SDC. In 500-episode evaluations, the co-trained SDC reached 78% of goals with a 14% collision rate, compared to 35% goals and 33% collisions for the best rule-based baseline. A speed differential metric shows that the SDC traveled 2.65 m/s faster near jaywalkers than near crosswalk users at close range (0-3 m), indicating that jaywalking encounters were not anticipated. Jaywalking accounted for 13% of crossing events but was associated with 62% of collisions. Co-training with MARL pedestrians reduced collisions by 30% relative to single-agent RL, as pedestrians learned to wait when the SDC approached at speed.
Can We Make Code Green? Understanding Trade-Offs in LLMs vs. Human Code Optimizations
Mar 26, 2025The rapid technological evolution has accelerated software development for various domains and use cases, contributing to a growing share of global carbon emissions. While recent large language models (LLMs) claim to assist developers in optimizing code for performance and energy efficiency, their efficacy in real-world scenarios remains under exploration. In this work, we explore the effectiveness of LLMs in reducing the environmental footprint of real-world projects, focusing on software written in Matlab-widely used in both academia and industry for scientific and engineering applications. We analyze energy-focused optimization on 400 scripts across 100 top GitHub repositories. We examine potential 2,176 optimizations recommended by leading LLMs, such as GPT-3, GPT-4, Llama, and Mixtral, and a senior Matlab developer, on energy consumption, memory usage, execution time consumption, and code correctness. The developer serves as a real-world baseline for comparing typical human and LLM-generated optimizations. Mapping these optimizations to 13 high-level themes, we found that LLMs propose a broad spectrum of improvements--beyond energy efficiency--including improving code readability and maintainability, memory management, error handling while the developer overlooked some parallel processing, error handling etc. However, our statistical tests reveal that the energy-focused optimizations unexpectedly negatively impacted memory usage, with no clear benefits regarding execution time or energy consumption. Our qualitative analysis of energy-time trade-offs revealed that some themes, such as vectorization preallocation, were among the common themes shaping these trade-offs. With LLMs becoming ubiquitous in modern software development, our study serves as a call to action: prioritizing the evaluation of common coding practices to identify the green ones.
VUDENC: Vulnerability Detection with Deep Learning on a Natural Codebase for Python
Jan 20, 2022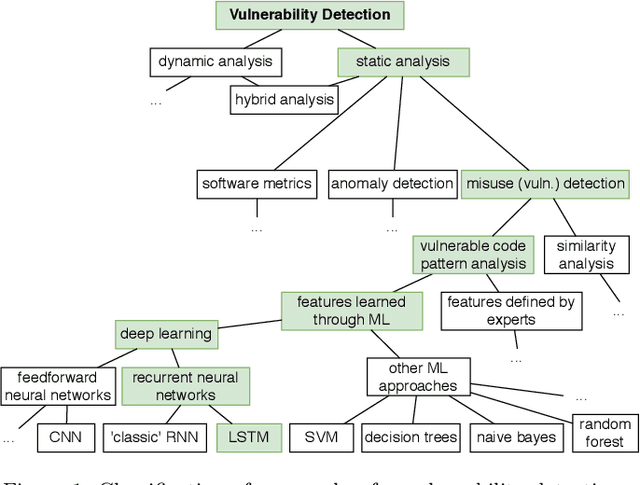


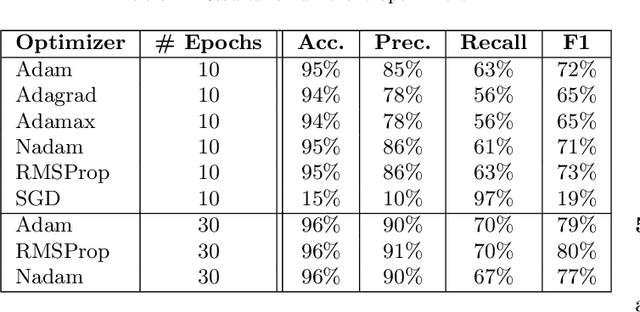
Context: Identifying potential vulnerable code is important to improve the security of our software systems. However, the manual detection of software vulnerabilities requires expert knowledge and is time-consuming, and must be supported by automated techniques. Objective: Such automated vulnerability detection techniques should achieve a high accuracy, point developers directly to the vulnerable code fragments, scale to real-world software, generalize across the boundaries of a specific software project, and require no or only moderate setup or configuration effort. Method: In this article, we present VUDENC (Vulnerability Detection with Deep Learning on a Natural Codebase), a deep learning-based vulnerability detection tool that automatically learns features of vulnerable code from a large and real-world Python codebase. VUDENC applies a word2vec model to identify semantically similar code tokens and to provide a vector representation. A network of long-short-term memory cells (LSTM) is then used to classify vulnerable code token sequences at a fine-grained level, highlight the specific areas in the source code that are likely to contain vulnerabilities, and provide confidence levels for its predictions. Results: To evaluate VUDENC, we used 1,009 vulnerability-fixing commits from different GitHub repositories that contain seven different types of vulnerabilities (SQL injection, XSS, Command injection, XSRF, Remote code execution, Path disclosure, Open redirect) for training. In the experimental evaluation, VUDENC achieves a recall of 78%-87%, a precision of 82%-96%, and an F1 score of 80%-90%. VUDENC's code, the datasets for the vulnerabilities, and the Python corpus for the word2vec model are available for reproduction. Conclusions: Our experimental results suggest...
* Accepted Manuscript