 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamical System Inspired Adaptive Time Stepping Controller for Residual Network Families
Nov 23, 2019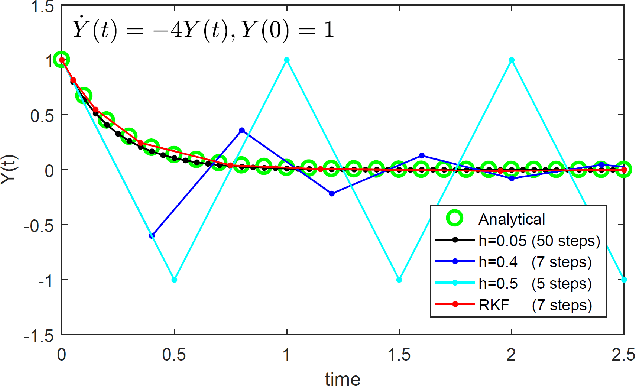
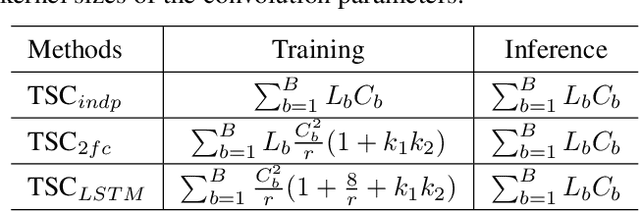

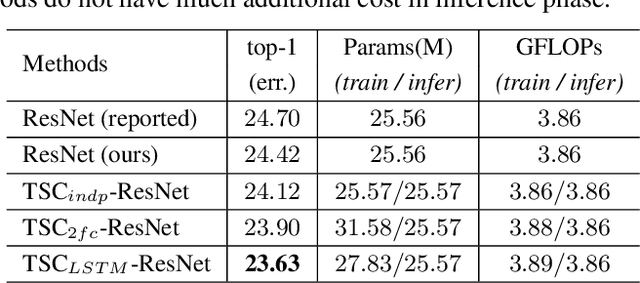
The correspondence between residual networks and dynamical systems motivates researchers to unravel the physics of ResNets with well-developed tools in numeral methods of ODE systems. The Runge-Kutta-Fehlberg method is an adaptive time stepping that renders a good trade-off between the stability and efficiency. Can we also have an adaptive time stepping for ResNets to ensure both stability and performance? In this study, we analyze the effects of time stepping on the Euler method and ResNets. We establish a stability condition for ResNets with step sizes and weight parameters, and point out the effects of step sizes on the stability and performance. Inspired by our analyses, we develop an adaptive time stepping controller that is dependent on the parameters of the current step, and aware of previous steps. The controller is jointly optimized with the network training so that variable step sizes and evolution time can be adaptively adjusted. We conduct experiments on ImageNet and CIFAR to demonstrate the effectiveness. It is shown that our proposed method is able to improve both stability and accuracy without introducing additional overhead in inference phase.
Joint Sub-bands Learning with Clique Structures for Wavelet Domain Super-Resolution
Oct 25, 2018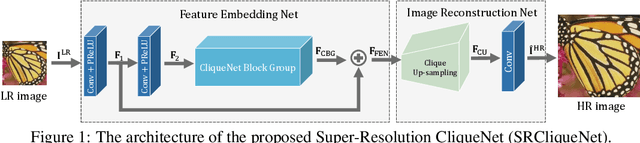
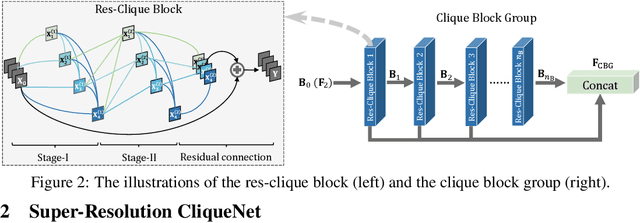
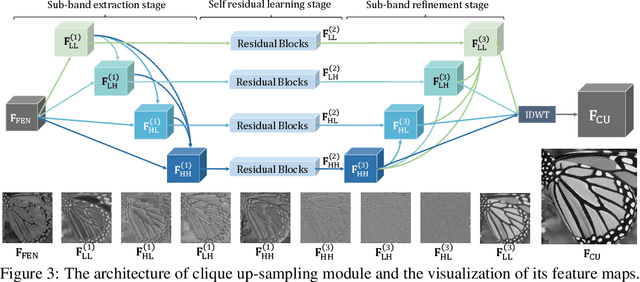
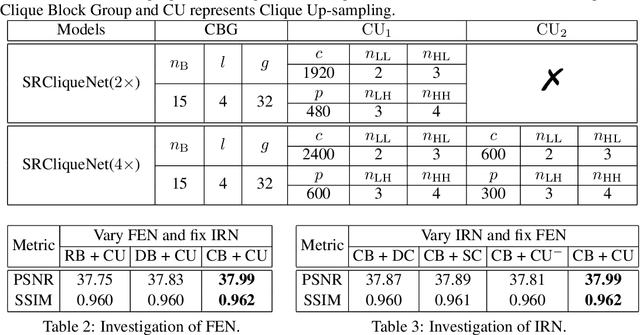
Convolutional neural networks (CNNs) have recently achieved great success in single-image super-resolution (SISR). However, these methods tend to produce over-smoothed outputs and miss some textural details. To solve these problems, we propose the Super-Resolution CliqueNet (SRCliqueNet) to reconstruct the high resolution (HR) image with better textural details in the wavelet domain. The proposed SRCliqueNet firstly extracts a set of feature maps from the low resolution (LR) image by the clique blocks group. Then we send the set of feature maps to the clique up-sampling module to reconstruct the HR image. The clique up-sampling module consists of four sub-nets which predict the high resolution wavelet coefficients of four sub-bands. Since we consider the edge feature properties of four sub-bands, the four sub-nets are connected to the others so that they can learn the coefficients of four sub-bands jointly. Finally we apply inverse discrete wavelet transform (IDWT) to the output of four sub-nets at the end of the clique up-sampling module to increase the resolution and reconstruct the HR image. Extensive quantitative and qualitative experiments on benchmark datasets show that our method achieves superior performance over the state-of-the-art methods.
Convolutional Neural Networks with Alternately Updated Clique
Apr 03, 2018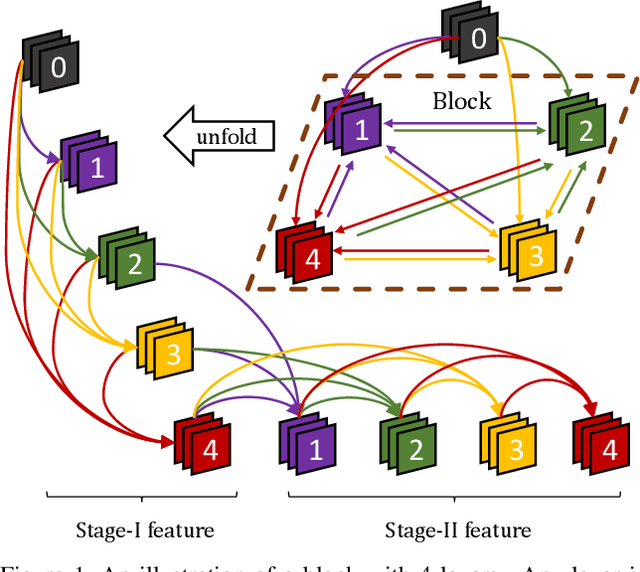
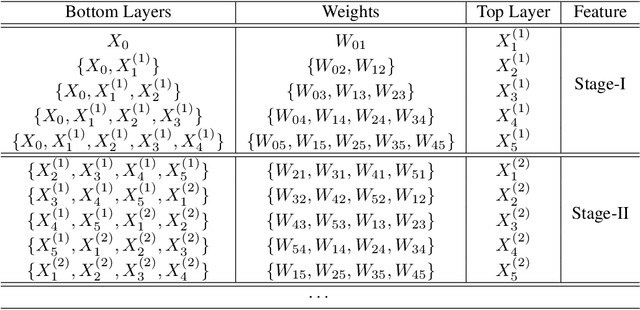
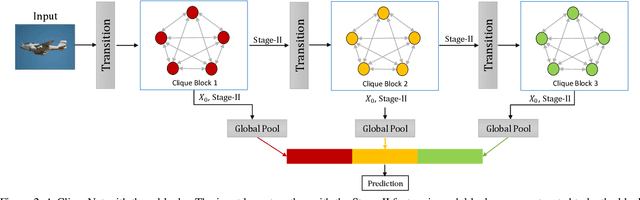

Improving information flow in deep networks helps to ease the training difficulties and utilize parameters more efficiently. Here we propose a new convolutional neural network architecture with alternately updated clique (CliqueNet). In contrast to prior networks, there are both forward and backward connections between any two layers in the same block. The layers are constructed as a loop and are updated alternately. The CliqueNet has some unique properties. For each layer, it is both the input and output of any other layer in the same block, so that the information flow among layers is maximized. During propagation, the newly updated layers are concatenated to re-update previously updated layer, and parameters are reused for multiple times. This recurrent feedback structure is able to bring higher level visual information back to refine low-level filters and achieve spatial attention. We analyze the features generated at different stages and observe that using refined features leads to a better result. We adopt a multi-scale feature strategy that effectively avoids the progressive growth of parameters. Experiments on image recognition datasets including CIFAR-10, CIFAR-100, SVHN and ImageNet show that our proposed models achieve the state-of-the-art performance with fewer parameters.