 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDatasets: A Community Library for Natural Language Processing
Sep 07, 2021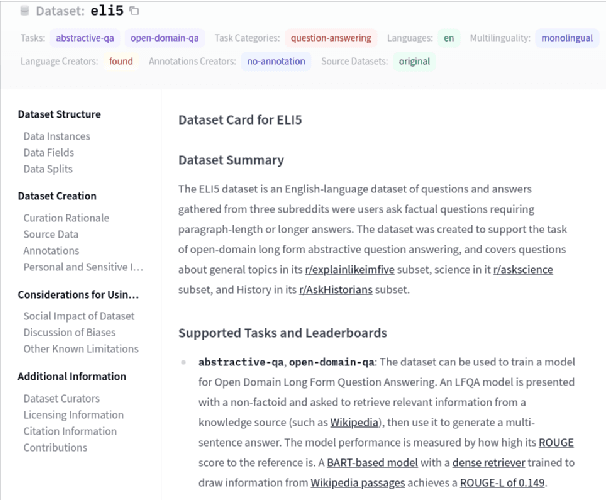
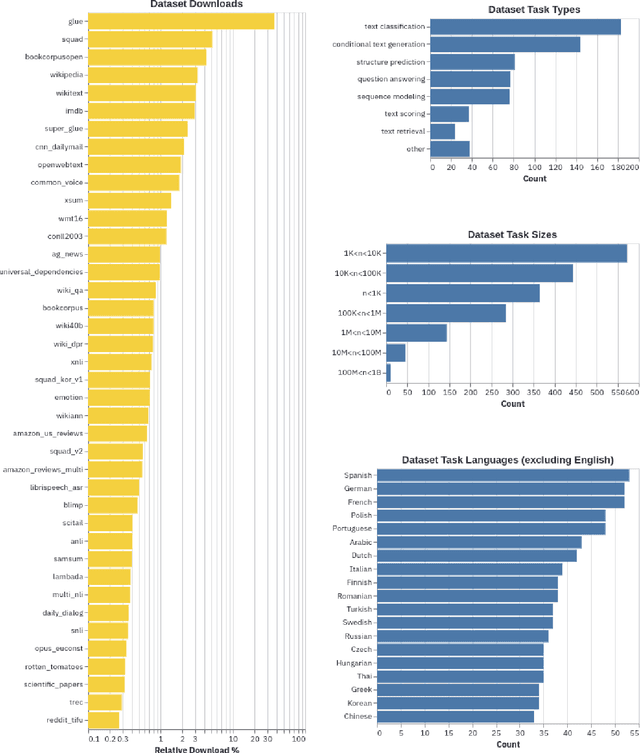
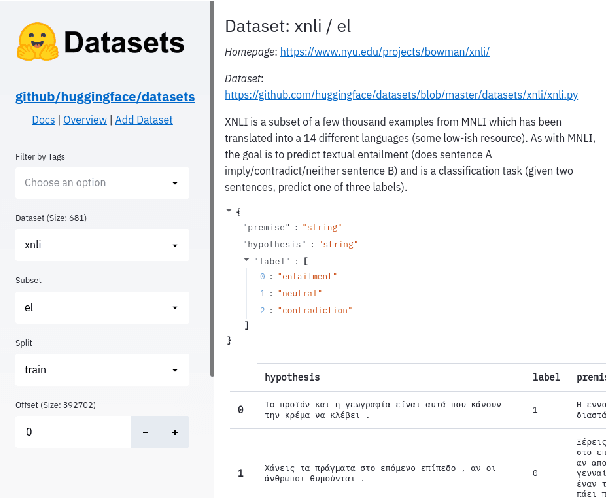
The scale, variety, and quantity of publicly-available NLP datasets has grown rapidly as researchers propose new tasks, larger models, and novel benchmarks. Datasets is a community library for contemporary NLP designed to support this ecosystem. Datasets aims to standardize end-user interfaces, versioning, and documentation, while providing a lightweight front-end that behaves similarly for small datasets as for internet-scale corpora. The design of the library incorporates a distributed, community-driven approach to adding datasets and documenting usage. After a year of development, the library now includes more than 650 unique datasets, has more than 250 contributors, and has helped support a variety of novel cross-dataset research projects and shared tasks. The library is available at https://github.com/huggingface/datasets.
VIMPAC: Video Pre-Training via Masked Token Prediction and Contrastive Learning
Jun 21, 2021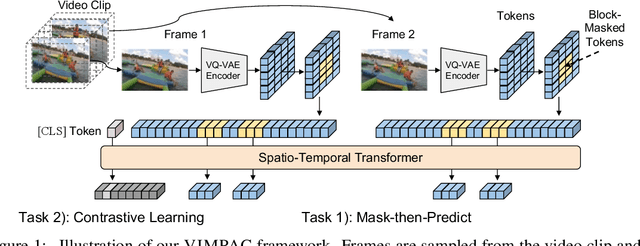
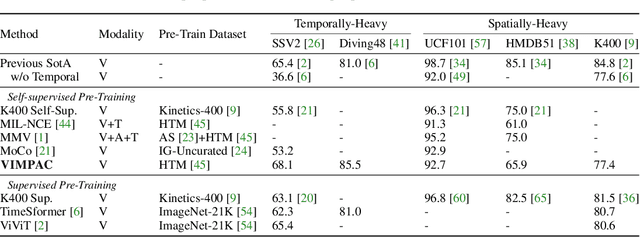
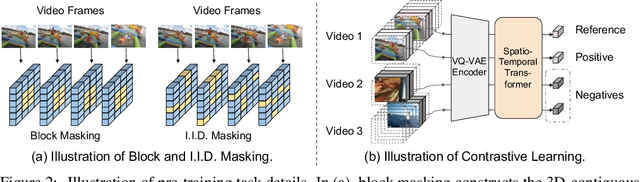
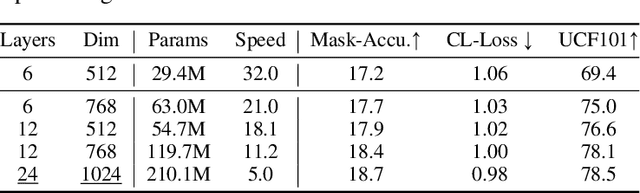
Video understanding relies on perceiving the global content and modeling its internal connections (e.g., causality, movement, and spatio-temporal correspondence). To learn these interactions, we apply a mask-then-predict pre-training task on discretized video tokens generated via VQ-VAE. Unlike language, where the text tokens are more independent, neighboring video tokens typically have strong correlations (e.g., consecutive video frames usually look very similar), and hence uniformly masking individual tokens will make the task too trivial to learn useful representations. To deal with this issue, we propose a block-wise masking strategy where we mask neighboring video tokens in both spatial and temporal domains. We also add an augmentation-free contrastive learning method to further capture the global content by predicting whether the video clips are sampled from the same video. We pre-train our model on uncurated videos and show that our pre-trained model can reach state-of-the-art results on several video understanding datasets (e.g., SSV2, Diving48). Lastly, we provide detailed analyses on model scalability and pre-training method design. Code is released at https://github.com/airsplay/vimpac.
Distributed Deep Learning in Open Collaborations
Jun 18, 2021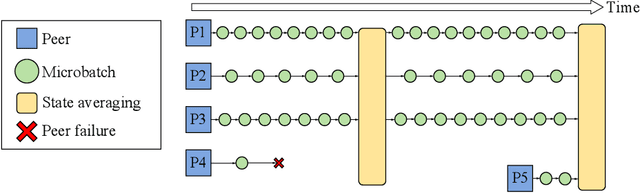
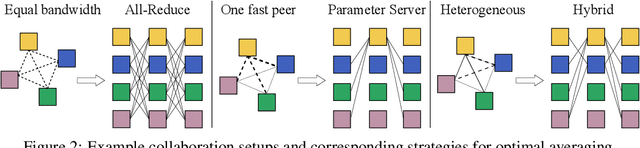
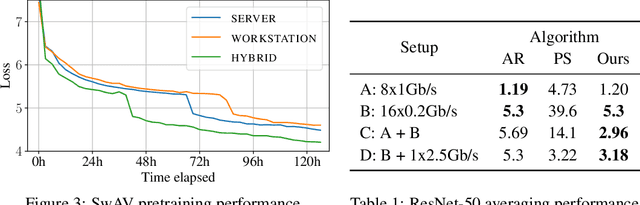

Modern deep learning applications require increasingly more compute to train state-of-the-art models. To address this demand, large corporations and institutions use dedicated High-Performance Computing clusters, whose construction and maintenance are both environmentally costly and well beyond the budget of most organizations. As a result, some research directions become the exclusive domain of a few large industrial and even fewer academic actors. To alleviate this disparity, smaller groups may pool their computational resources and run collaborative experiments that benefit all participants. This paradigm, known as grid- or volunteer computing, has seen successful applications in numerous scientific areas. However, using this approach for machine learning is difficult due to high latency, asymmetric bandwidth, and several challenges unique to volunteer computing. In this work, we carefully analyze these constraints and propose a novel algorithmic framework designed specifically for collaborative training. We demonstrate the effectiveness of our approach for SwAV and ALBERT pretraining in realistic conditions and achieve performance comparable to traditional setups at a fraction of the cost. Finally, we provide a detailed report of successful collaborative language model pretraining with 40 participants.
Learning from others' mistakes: Avoiding dataset biases without modeling them
Dec 02, 2020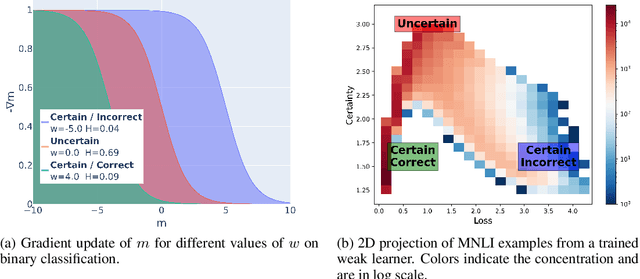

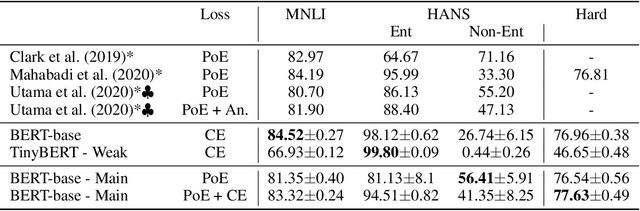
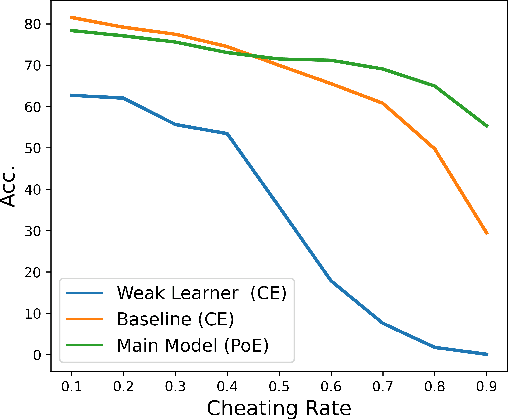
State-of-the-art natural language processing (NLP) models often learn to model dataset biases and surface form correlations instead of features that target the intended underlying task. Previous work has demonstrated effective methods to circumvent these issues when knowledge of the bias is available. We consider cases where the bias issues may not be explicitly identified, and show a method for training models that learn to ignore these problematic correlations. Our approach relies on the observation that models with limited capacity primarily learn to exploit biases in the dataset. We can leverage the errors of such limited capacity models to train a more robust model in a product of experts, thus bypassing the need to hand-craft a biased model. We show the effectiveness of this method to retain improvements in out-of-distribution settings even if no particular bias is targeted by the biased model.
Movement Pruning: Adaptive Sparsity by Fine-Tuning
May 15, 2020
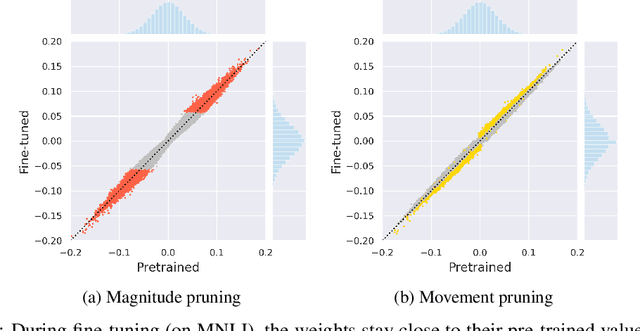
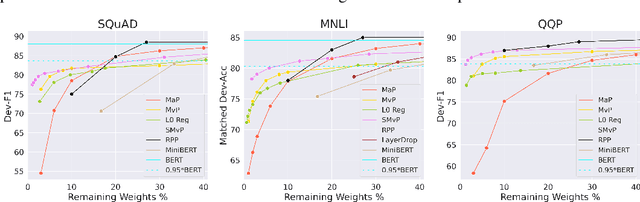
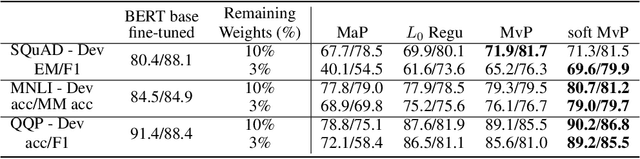
Magnitude pruning is a widely used strategy for reducing model size in pure supervised learning; however, it is less effective in the transfer learning regime that has become standard for state-of-the-art natural language processing applications. We propose the use of movement pruning, a simple, deterministic first-order weight pruning method that is more adaptive to pretrained model fine-tuning. We give mathematical foundations to the method and compare it to existing zeroth- and first-order pruning methods. Experiments show that when pruning large pretrained language models, movement pruning shows significant improvements in high-sparsity regimes. When combined with distillation, the approach achieves minimal accuracy loss with down to only 3% of the model parameters.
TLDR: Token Loss Dynamic Reweighting for Reducing Repetitive Utterance Generation
Apr 09, 2020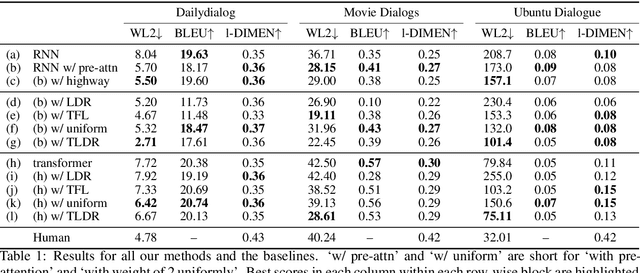
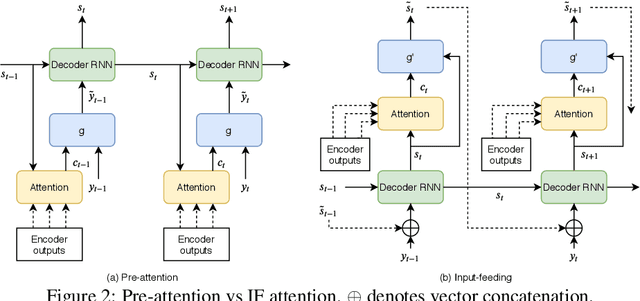
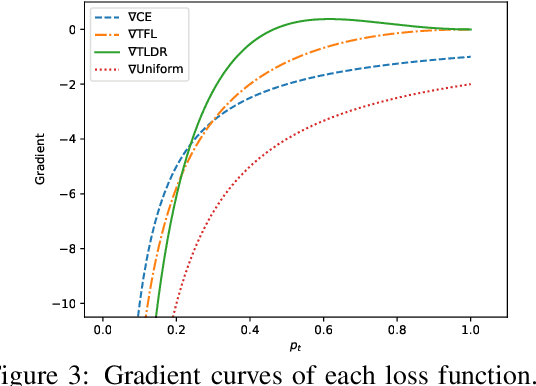
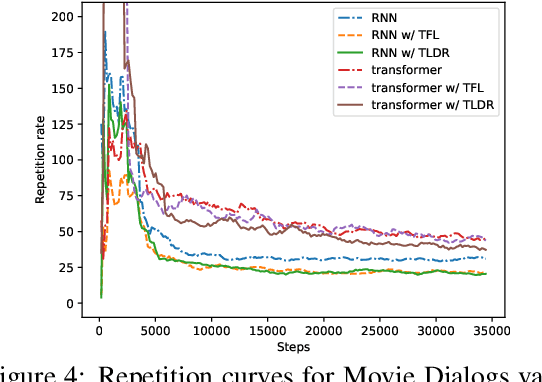
Natural Language Generation (NLG) models are prone to generating repetitive utterances. In this work, we study the repetition problem for encoder-decoder models, using both recurrent neural network (RNN) and transformer architectures. To this end, we consider the chit-chat task, where the problem is more prominent than in other tasks that need encoder-decoder architectures. We first study the influence of model architectures. By using pre-attention and highway connections for RNNs, we manage to achieve lower repetition rates. However, this method does not generalize to other models such as transformers. We hypothesize that the deeper reason is that in the training corpora, there are hard tokens that are more difficult for a generative model to learn than others and, once learning has finished, hard tokens are still under-learned, so that repetitive generations are more likely to happen. Based on this hypothesis, we propose token loss dynamic reweighting (TLDR) that applies differentiable weights to individual token losses. By using higher weights for hard tokens and lower weights for easy tokens, NLG models are able to learn individual tokens at different paces. Experiments on chit-chat benchmark datasets show that TLDR is more effective in repetition reduction for both RNN and transformer architectures than baselines using different weighting functions.
HuggingFace's Transformers: State-of-the-art Natural Language Processing
Oct 16, 2019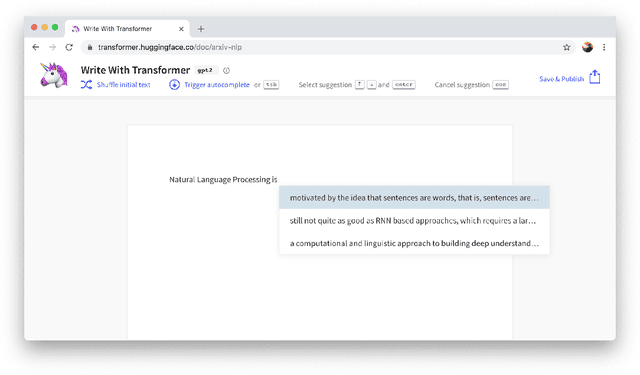
Recent advances in modern Natural Language Processing (NLP) research have been dominated by the combination of Transfer Learning methods with large-scale language models, in particular based on the Transformer architecture. With them came a paradigm shift in NLP with the starting point for training a model on a downstream task moving from a blank specific model to a general-purpose pretrained architecture. Still, creating these general-purpose models remains an expensive and time-consuming process restricting the use of these methods to a small sub-set of the wider NLP community. In this paper, we present HuggingFace's Transformers library, a library for state-of-the-art NLP, making these developments available to the community by gathering state-of-the-art general-purpose pretrained models under a unified API together with an ecosystem of libraries, examples, tutorials and scripts targeting many downstream NLP tasks. HuggingFace's Transformers library features carefully crafted model implementations and high-performance pretrained weights for two main deep learning frameworks, PyTorch and TensorFlow, while supporting all the necessary tools to analyze, evaluate and use these models in downstream tasks such as text/token classification, questions answering and language generation among others. The library has gained significant organic traction and adoption among both the researcher and practitioner communities. We are committed at HuggingFace to pursue the efforts to develop this toolkit with the ambition of creating the standard library for building NLP systems.
DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter
Oct 16, 2019
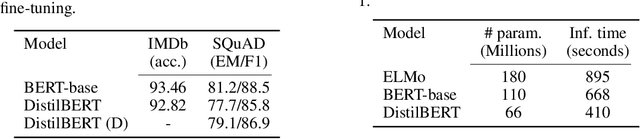

As Transfer Learning from large-scale pre-trained models becomes more prevalent in Natural Language Processing (NLP), operating these large models in on-the-edge and/or under constrained computational training or inference budgets remains challenging. In this work, we propose a method to pre-train a smaller general-purpose language representation model, called DistilBERT, which can then be fine-tuned with good performances on a wide range of tasks like its larger counterparts. While most prior work investigated the use of distillation for building task-specific models, we leverage knowledge distillation during the pre-training phase and show that it is possible to reduce the size of a BERT model by 40%, while retaining 97% of its language understanding capabilities and being 60% faster. To leverage the inductive biases learned by larger models during pre-training, we introduce a triple loss combining language modeling, distillation and cosine-distance losses. Our smaller, faster and lighter model is cheaper to pre-train and we demonstrate its capabilities for on-device computations in a proof-of-concept experiment and a comparative on-device study.
TransferTransfo: A Transfer Learning Approach for Neural Network Based Conversational Agents
Feb 04, 2019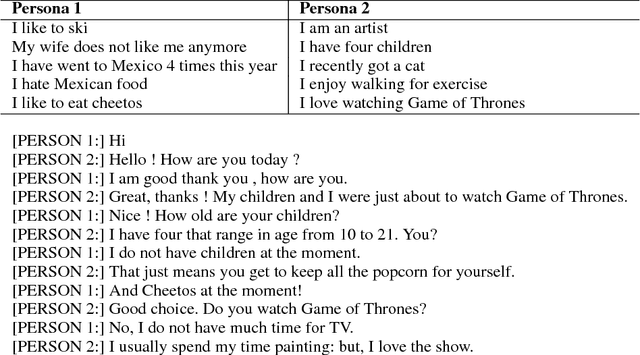

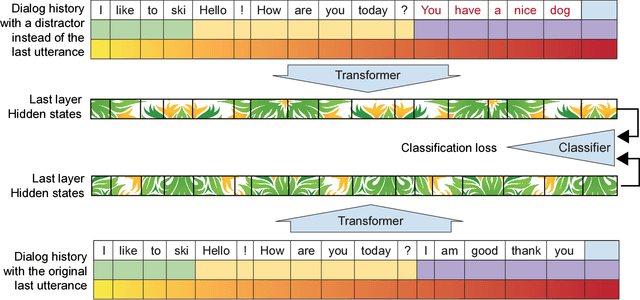
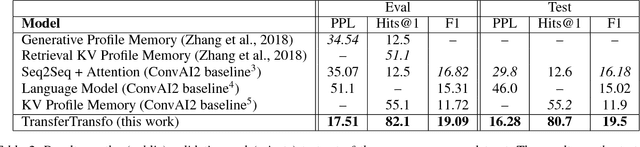
We introduce a new approach to generative data-driven dialogue systems (e.g. chatbots) called TransferTransfo which is a combination of a Transfer learning based training scheme and a high-capacity Transformer model. Fine-tuning is performed by using a multi-task objective which combines several unsupervised prediction tasks. The resulting fine-tuned model shows strong improvements over the current state-of-the-art end-to-end conversational models like memory augmented seq2seq and information-retrieval models. On the privately held PERSONA-CHAT dataset of the Conversational Intelligence Challenge 2, this approach obtains a new state-of-the-art, with respective perplexity, Hits@1 and F1 metrics of 16.28 (45 % absolute improvement), 80.7 (46 % absolute improvement) and 19.5 (20 % absolute improvement).
A Hierarchical Multi-task Approach for Learning Embeddings from Semantic Tasks
Nov 26, 2018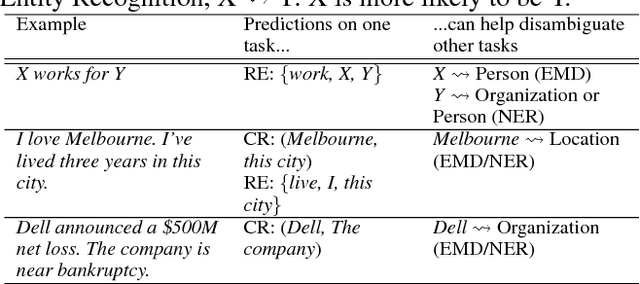
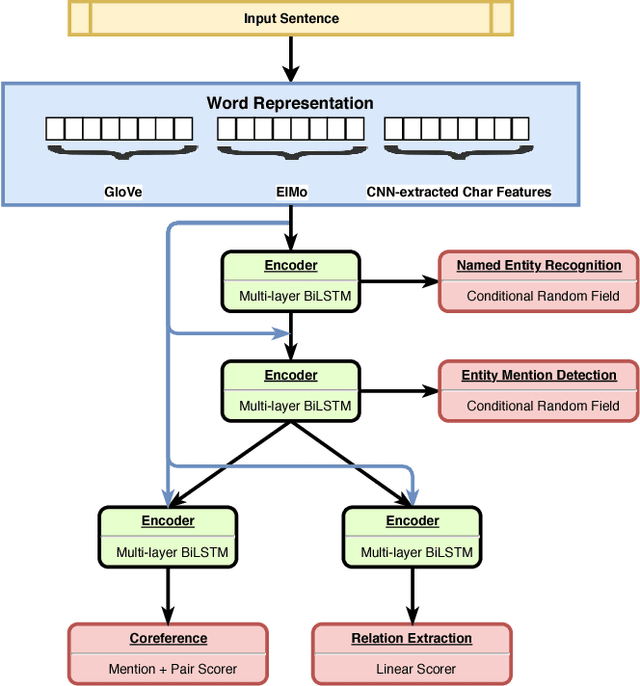
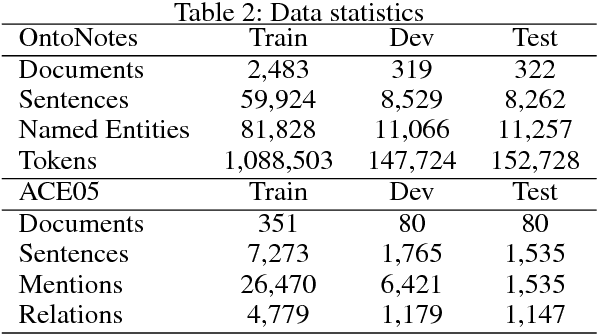
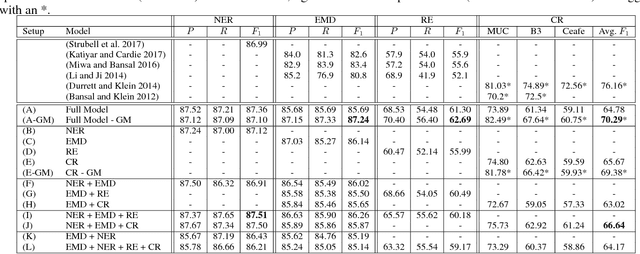
Much effort has been devoted to evaluate whether multi-task learning can be leveraged to learn rich representations that can be used in various Natural Language Processing (NLP) down-stream applications. However, there is still a lack of understanding of the settings in which multi-task learning has a significant effect. In this work, we introduce a hierarchical model trained in a multi-task learning setup on a set of carefully selected semantic tasks. The model is trained in a hierarchical fashion to introduce an inductive bias by supervising a set of low level tasks at the bottom layers of the model and more complex tasks at the top layers of the model. This model achieves state-of-the-art results on a number of tasks, namely Named Entity Recognition, Entity Mention Detection and Relation Extraction without hand-engineered features or external NLP tools like syntactic parsers. The hierarchical training supervision induces a set of shared semantic representations at lower layers of the model. We show that as we move from the bottom to the top layers of the model, the hidden states of the layers tend to represent more complex semantic information.