 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomatic Cough Classification for Tuberculosis Screening in a Real-World Environment
Mar 23, 2021

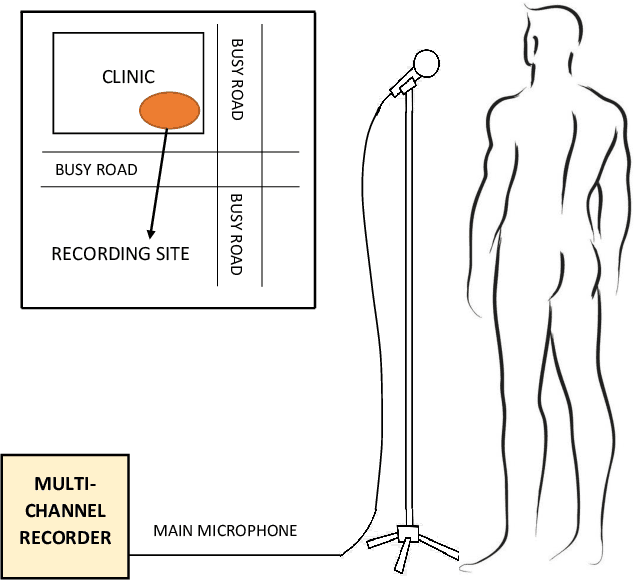

We present first results showing that it is possible to automatically discriminate between the coughing sounds produced by patients with tuberculosis (TB) and those produced by patients with other lung ailments in a real-world noisy environment. Our experiments are based on a dataset of cough recordings obtained in a real-world clinic setting from 16 patients confirmed to be suffering from TB and 33 patients that are suffering from respiratory conditions, confirmed as other than TB. We have trained and evaluated several machine learning classifiers, including logistic regression (LR), support vector machines (SVM), k-nearest neighbour (KNN), multilayer perceptrons (MLP) and convolutional neural networks (CNN) inside a nested k-fold cross-validation and find that, although classification is possible in all cases, the best performance is achieved using the LR classifier. In combination with feature selection by sequential forward search (SFS), our best LR system achieves an area under the ROC curve (AUC) of 0.94 using 23 features selected from a set of 78 high-resolution mel-frequency cepstral coefficients (MFCCs). This system achieves a sensitivity of 93% at a specificity of 95% and thus exceeds the 90\% sensitivity at 70% specificity specification considered by the WHO as minimal requirements for community-based TB triage test. We conclude that automatic classification of cough audio sounds is promising as a viable means of low-cost easily-deployable front-line screening for TB, which will greatly benefit developing countries with a heavy TB burden.
A Hybrid CNN-BiLSTM Voice Activity Detector
Mar 05, 2021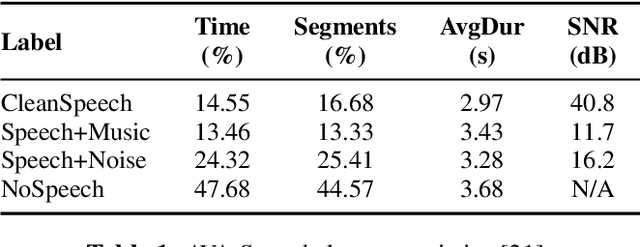
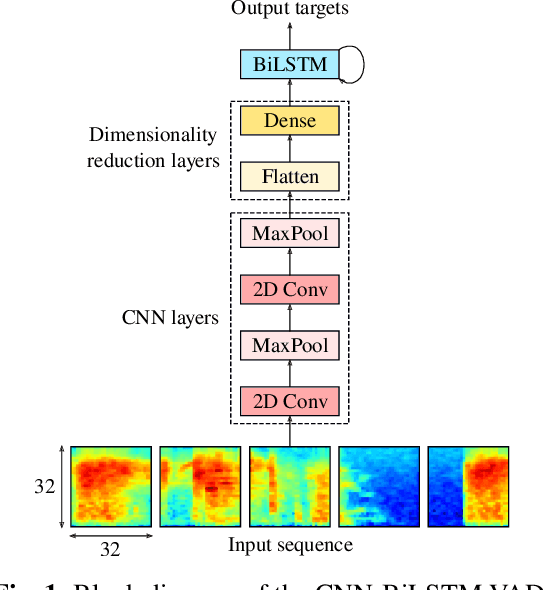
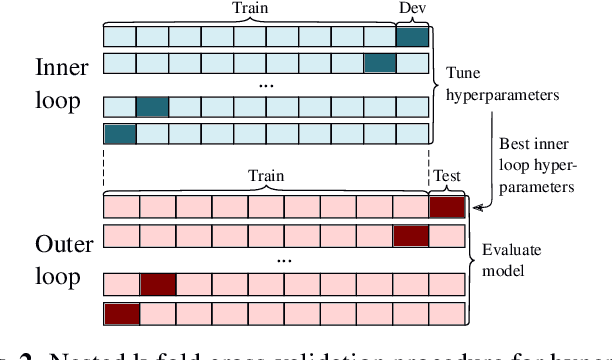

This paper presents a new hybrid architecture for voice activity detection (VAD) incorporating both convolutional neural network (CNN) and bidirectional long short-term memory (BiLSTM) layers trained in an end-to-end manner. In addition, we focus specifically on optimising the computational efficiency of our architecture in order to deliver robust performance in difficult in-the-wild noise conditions in a severely under-resourced setting. Nested k-fold cross-validation was used to explore the hyperparameter space, and the trade-off between optimal parameters and model size is discussed. The performance effect of a BiLSTM layer compared to a unidirectional LSTM layer was also considered. We compare our systems with three established baselines on the AVA-Speech dataset. We find that significantly smaller models with near optimal parameters perform on par with larger models trained with optimal parameters. BiLSTM layers were shown to improve accuracy over unidirectional layers by $\approx$2% absolute on average. With an area under the curve (AUC) of 0.951, our system outperforms all baselines, including a much larger ResNet system, particularly in difficult noise conditions.
Deep Neural Network based Cough Detection using Bed-mounted Accelerometer Measurements
Feb 09, 2021
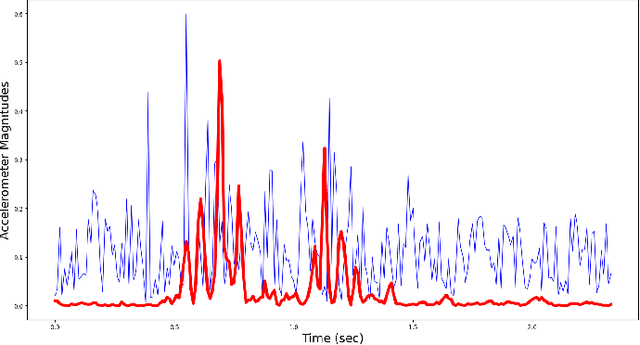

We have performed cough detection based on measurements from an accelerometer attached to the patient's bed. This form of monitoring is less intrusive than body-attached accelerometer sensors, and sidesteps privacy concerns encountered when using audio for cough detection. For our experiments, we have compiled a manually-annotated dataset containing the acceleration signals of approximately 6000 cough and 68000 non-cough events from 14 adult male patients in a tuberculosis clinic. As classifiers, we have considered convolutional neural networks (CNN), long-short-term-memory (LSTM) networks, and a residual neural network (Resnet50). We find that all classifiers are able to distinguish between the acceleration signals due to coughing and those due to other activities including sneezing, throat-clearing and movement in the bed with high accuracy. The Resnet50 performs the best, achieving an area under the ROC curve (AUC) exceeding 0.98 in cross-validation experiments. We conclude that high-accuracy cough monitoring based only on measurements from the accelerometer in a consumer smartphone is possible. Since the need to gather audio is avoided and therefore privacy is inherently protected, and since the accelerometer is attached to the bed and not worn, this form of monitoring may represent a more convenient and readily accepted method of long-term patient cough monitoring.
COVID-19 Cough Classification using Machine Learning and Global Smartphone Recordings
Dec 02, 2020
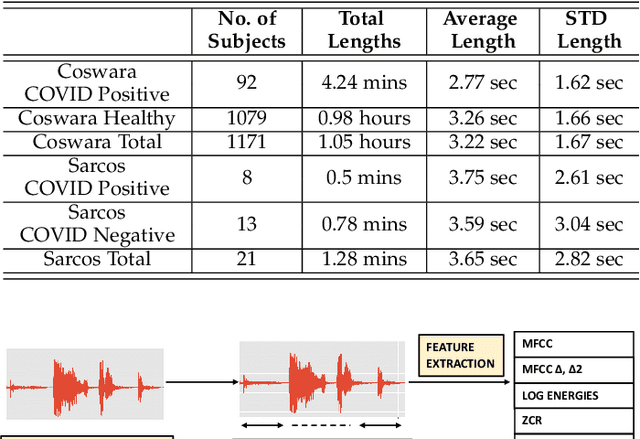
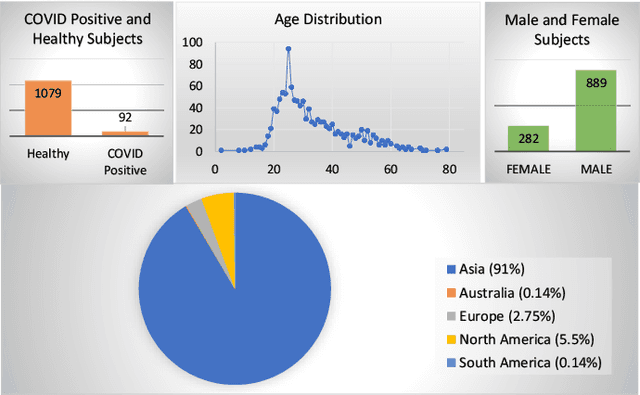

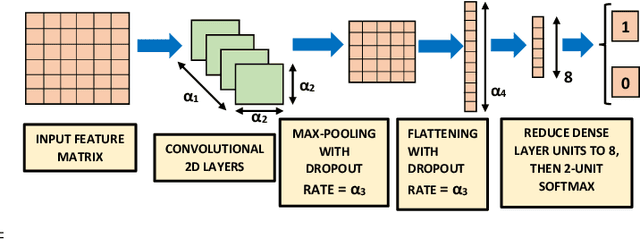
We present a machine learning based COVID-19 cough classifier which is able to discriminate COVID-19 positive coughs from both COVID-19 negative and healthy coughs recorded on a smartphone. This type of screening is non-contact and easily applied, and could help reduce workload in testing centers as well as limit transmission by recommending early self-isolation to those who have a cough suggestive of COVID-19. The two dataset used in this study include subjects from all six continents and contain both forced and natural coughs. The publicly available Coswara dataset contains 92 COVID-19 positive and 1079 healthy subjects, while the second smaller dataset was collected mostly in South Africa and contains 8 COVID-19 positive and 13 COVID-19 negative subjects who have undergone a SARS-CoV laboratory test. Dataset skew was addressed by applying synthetic minority oversampling (SMOTE) and leave-p-out cross validation was used to train and evaluate classifiers. Logistic regression (LR), support vector machines (SVM), multilayer perceptrons (MLP), convolutional neural networks (CNN), long-short term memory (LSTM) and a residual-based neural network architecture (Resnet50) were considered as classifiers. Our results show that the Resnet50 classifier was best able to discriminate between the COVID-19 positive and the healthy coughs with an area under the ROC curve (AUC) of 0.98 while a LSTM classifier was best able to discriminate between the COVID-19 positive and COVID-19 negative coughs with an AUC of 0.94. The LSTM classifier achieved these results using 13 features selected by sequential forward search (SFS). Since it can be implemented on a smartphone, cough audio classification is cost-effective and easy to apply and deploy, and therefore is potentially a useful and viable means of non-contact COVID-19 screening.
Multilingual Bottleneck Features for Improving ASR Performance of Code-Switched Speech in Under-Resourced Languages
Oct 31, 2020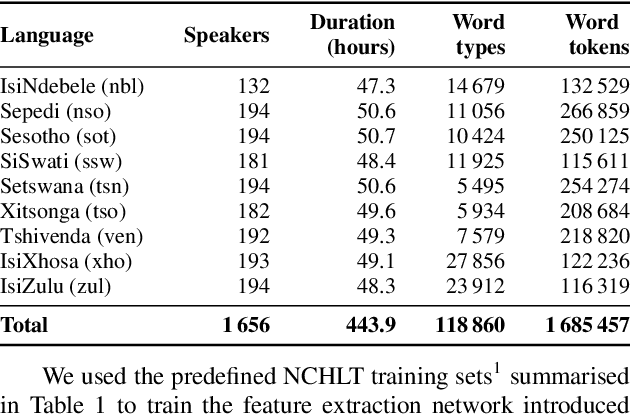
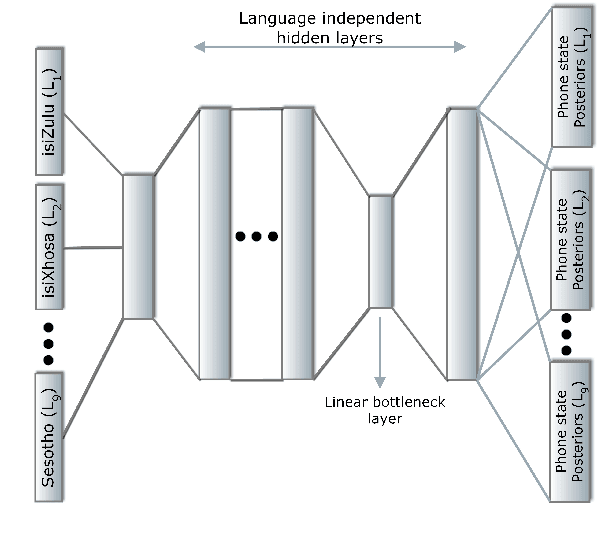
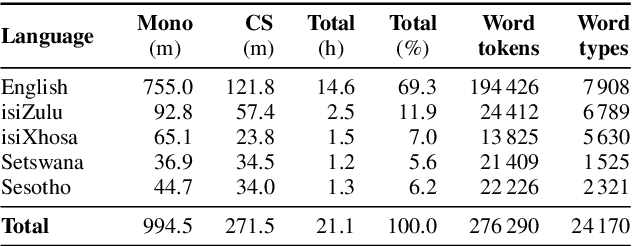
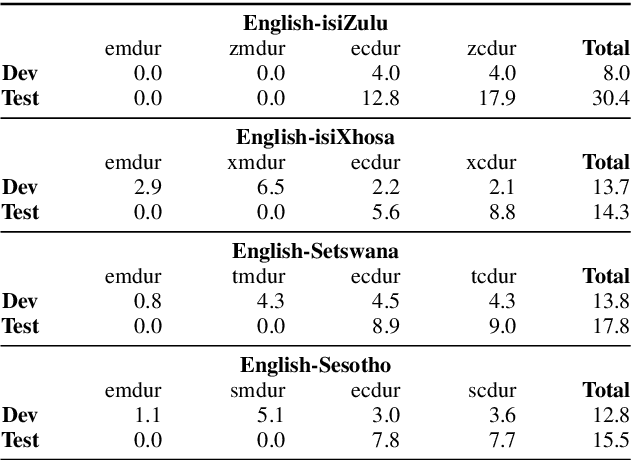
In this work, we explore the benefits of using multilingual bottleneck features (mBNF) in acoustic modelling for the automatic speech recognition of code-switched (CS) speech in African languages. The unavailability of annotated corpora in the languages of interest has always been a primary challenge when developing speech recognition systems for this severely under-resourced type of speech. Hence, it is worthwhile to investigate the potential of using speech corpora available for other better-resourced languages to improve speech recognition performance. To achieve this, we train a mBNF extractor using nine Southern Bantu languages that form part of the freely available multilingual NCHLT corpus. We append these mBNFs to the existing MFCCs, pitch features and i-vectors to train acoustic models for automatic speech recognition (ASR) in the target code-switched languages. Our results show that the inclusion of the mBNF features leads to clear performance improvements over a baseline trained without the mBNFs for code-switched English-isiZulu, English-isiXhosa, English-Sesotho and English-Setswana speech.
* In Proceedings of The First Workshop on Speech Technologies for Code-Switching in Multilingual Communities
Semi-supervised Development of ASR Systems for Multilingual Code-switched Speech in Under-resourced Languages
Mar 06, 2020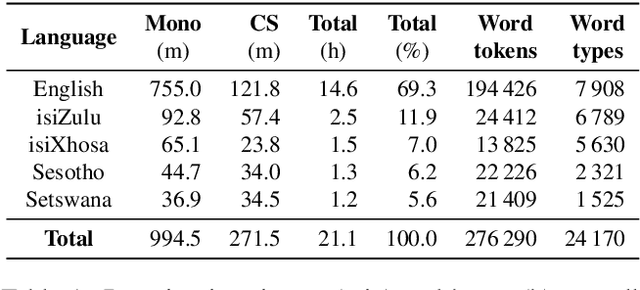
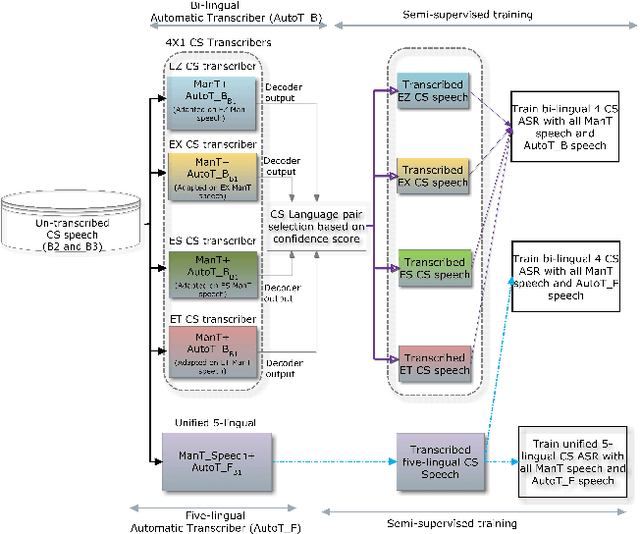
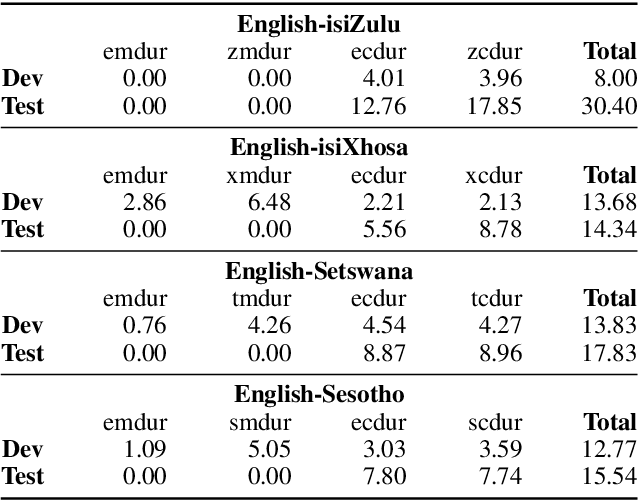
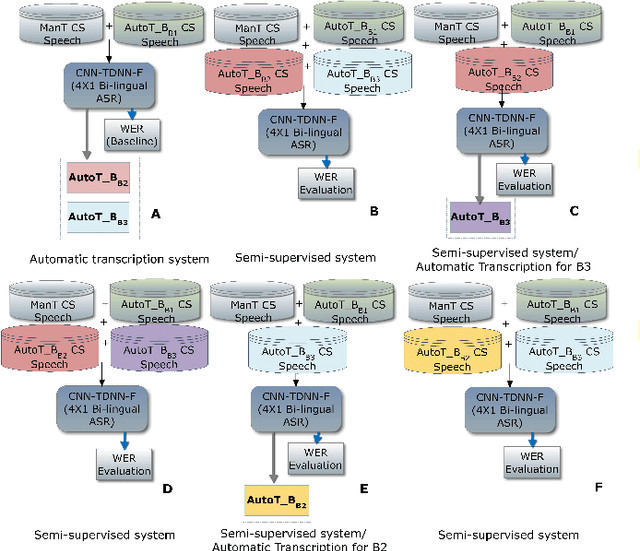
This paper reports on the semi-supervised development of acoustic and language models for under-resourced, code-switched speech in five South African languages. Two approaches are considered. The first constructs four separate bilingual automatic speech recognisers (ASRs) corresponding to four different language pairs between which speakers switch frequently. The second uses a single, unified, five-lingual ASR system that represents all the languages (English, isiZulu, isiXhosa, Setswana and Sesotho). We evaluate the effectiveness of these two approaches when used to add additional data to our extremely sparse training sets. Results indicate that batch-wise semi-supervised training yields better results than a non-batch-wise approach. Furthermore, while the separate bilingual systems achieved better recognition performance than the unified system, they benefited more from pseudo-labels generated by the five-lingual system than from those generated by the bilingual systems.
Improved low-resource Somali speech recognition by semi-supervised acoustic and language model training
Jul 06, 2019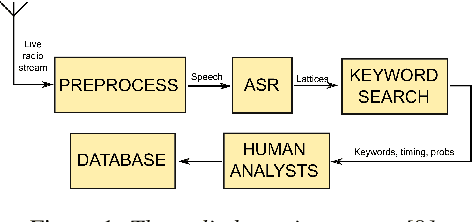
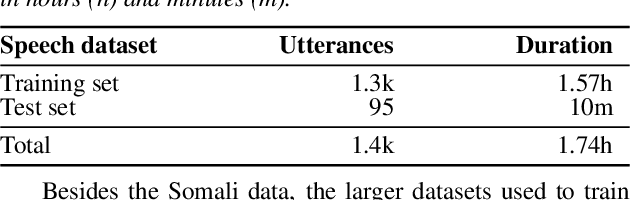
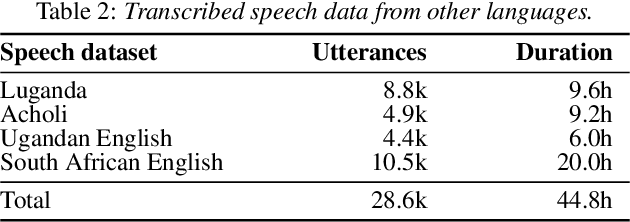
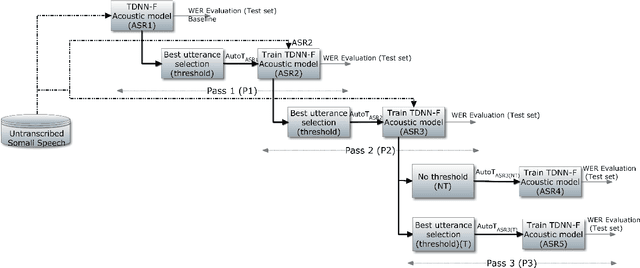
We present improvements in automatic speech recognition (ASR) for Somali, a currently extremely under-resourced language. This forms part of a continuing United Nations (UN) effort to employ ASR-based keyword spotting systems to support humanitarian relief programmes in rural Africa. Using just 1.57 hours of annotated speech data as a seed corpus, we increase the pool of training data by applying semi-supervised training to 17.55 hours of untranscribed speech. We make use of factorised time-delay neural networks (TDNN-F) for acoustic modelling, since these have recently been shown to be effective in resource-scarce situations. Three semi-supervised training passes were performed, where the decoded output from each pass was used for acoustic model training in the subsequent pass. The automatic transcriptions from the best performing pass were used for language model augmentation. To ensure the quality of automatic transcriptions, decoder confidence is used as a threshold. The acoustic and language models obtained from the semi-supervised approach show significant improvement in terms of WER and perplexity compared to the baseline. Incorporating the automatically generated transcriptions yields a 6.55\% improvement in language model perplexity. The use of 17.55 hour of Somali acoustic data in semi-supervised training shows an improvement of 7.74\% relative over the baseline.
Semi-supervised acoustic model training for five-lingual code-switched ASR
Jun 20, 2019
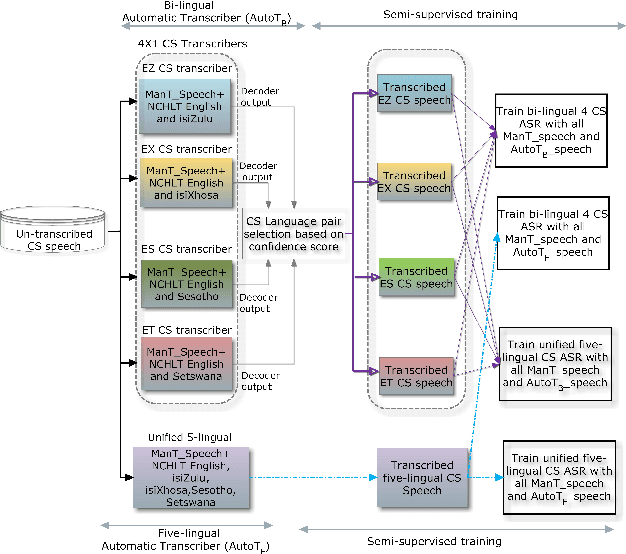
This paper presents recent progress in the acoustic modelling of under-resourced code-switched (CS) speech in multiple South African languages. We consider two approaches. The first constructs separate bilingual acoustic models corresponding to language pairs (English-isiZulu, English-isiXhosa, English-Setswana and English-Sesotho). The second constructs a single unified five-lingual acoustic model representing all the languages (English, isiZulu, isiXhosa, Setswana and Sesotho). For these two approaches we consider the effectiveness of semi-supervised training to increase the size of the very sparse acoustic training sets. Using approximately 11 hours of untranscribed speech, we show that both approaches benefit from semi-supervised training. The bilingual TDNN-F acoustic models also benefit from the addition of CNN layers (CNN-TDNN-F), while the five-lingual system does not show any significant improvement. Furthermore, because English is common to all language pairs in our data, it dominates when training a unified language model, leading to improved English ASR performance at the expense of the other languages. Nevertheless, the five-lingual model offers flexibility because it can process more than two languages simultaneously, and is therefore an attractive option as an automatic transcription system in a semi-supervised training pipeline.
Almost Zero-Resource ASR-free Keyword Spotting using Multilingual Bottleneck Features and Correspondence Autoencoders
Nov 14, 2018
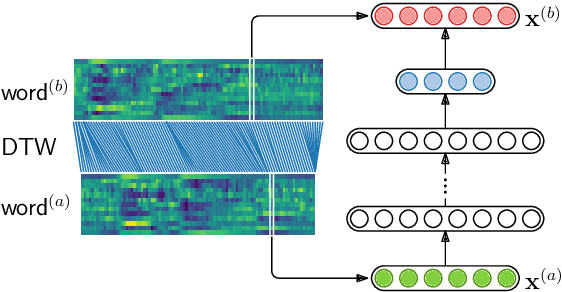
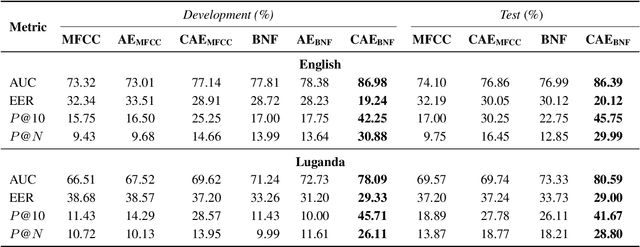
We compare features for dynamic time warping based keyword spotting in an almost zero-resource setting. The objective is to support United Nations (UN) humanitarian relief efforts in parts of Africa with severely under-resourced languages. As supervised resource, we restrict ourselves to an easily-compiled small set of isolated keywords. For feature extraction, we integrate a multilingual bottleneck feature extractor (BNF), trained on well-resourced out-of-domain languages, with a correspondence autoencoder (CAE), trained on extremely sparse in-domain data. We find that, on their own, BNFs and CAE features achieve more than 2% absolute performance improvement over baseline MFCCs. However, by using BNFs as input to the CAE, even better performance is achieved, with an 11% absolute improvement in ROC AUC over MFCCs and twice as many top-10 retrievals. We conclude that integrating BNFs with the CAE allows both large out-of-domain and sparse in-domain resources to be exploited for improved ASR-free keyword spotting.
Cluster Size Management in Multi-Stage Agglomerative Hierarchical Clustering of Acoustic Speech Segments
Oct 30, 2018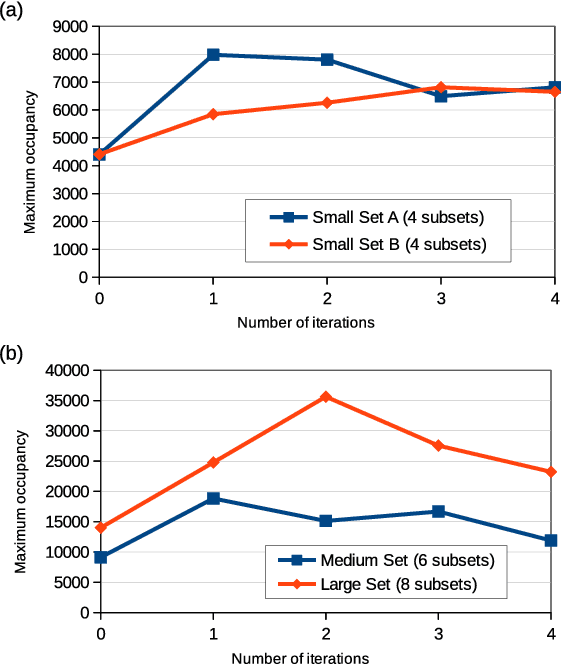

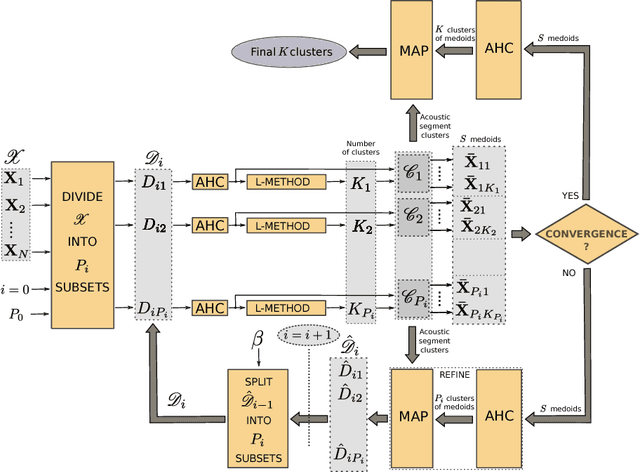
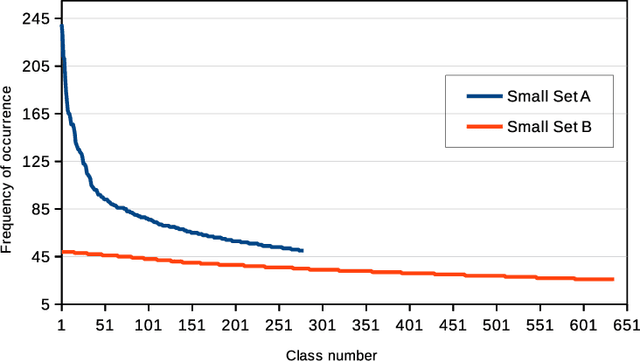
Agglomerative hierarchical clustering (AHC) requires only the similarity between objects to be known. This is attractive when clustering signals of varying length, such as speech, which are not readily represented in fixed-dimensional vector space. However, AHC is characterised by $O(N^2)$ space and time complexity, making it infeasible for partitioning large datasets. This has recently been addressed by an approach based on the iterative re-clustering of independent subsets of the larger dataset. We show that, due to its iterative nature, this procedure can sometimes lead to unchecked growth of individual subsets, thereby compromising its effectiveness. We propose the integration of a simple space management strategy into the iterative process, and show experimentally that this leads to no loss in performance in terms of F-measure while guaranteeing that a threshold space complexity is not breached.