 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCluster Size Management in Multi-Stage Agglomerative Hierarchical Clustering of Acoustic Speech Segments
Oct 30, 2018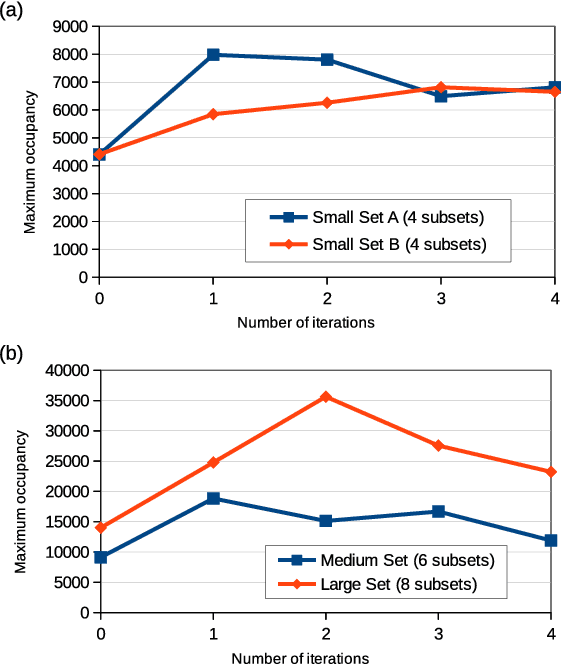

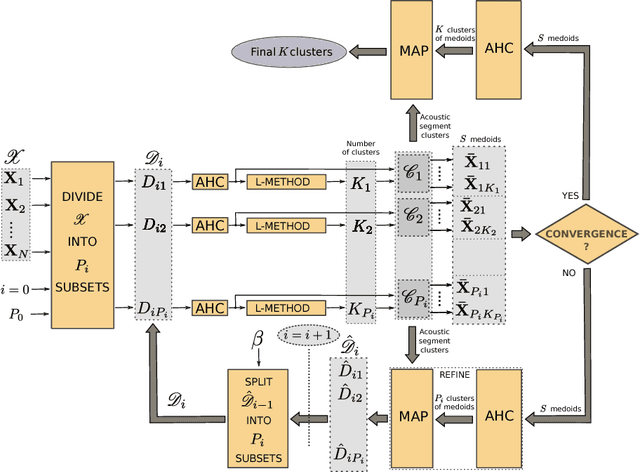
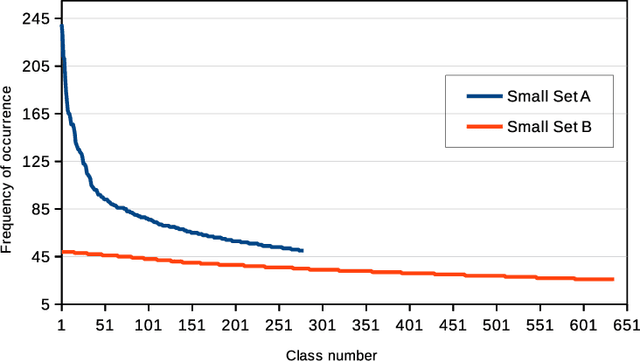
Agglomerative hierarchical clustering (AHC) requires only the similarity between objects to be known. This is attractive when clustering signals of varying length, such as speech, which are not readily represented in fixed-dimensional vector space. However, AHC is characterised by $O(N^2)$ space and time complexity, making it infeasible for partitioning large datasets. This has recently been addressed by an approach based on the iterative re-clustering of independent subsets of the larger dataset. We show that, due to its iterative nature, this procedure can sometimes lead to unchecked growth of individual subsets, thereby compromising its effectiveness. We propose the integration of a simple space management strategy into the iterative process, and show experimentally that this leads to no loss in performance in terms of F-measure while guaranteeing that a threshold space complexity is not breached.
Feature Trajectory Dynamic Time Warping for Clustering of Speech Segments
Oct 30, 2018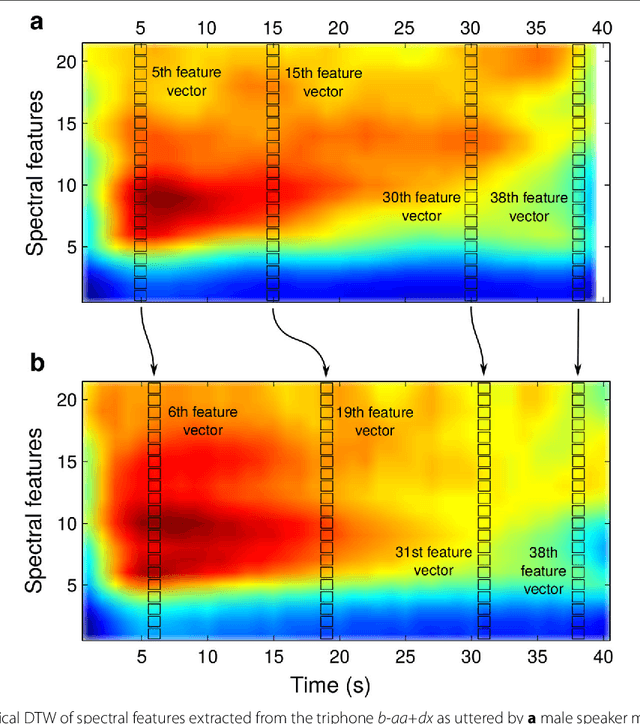

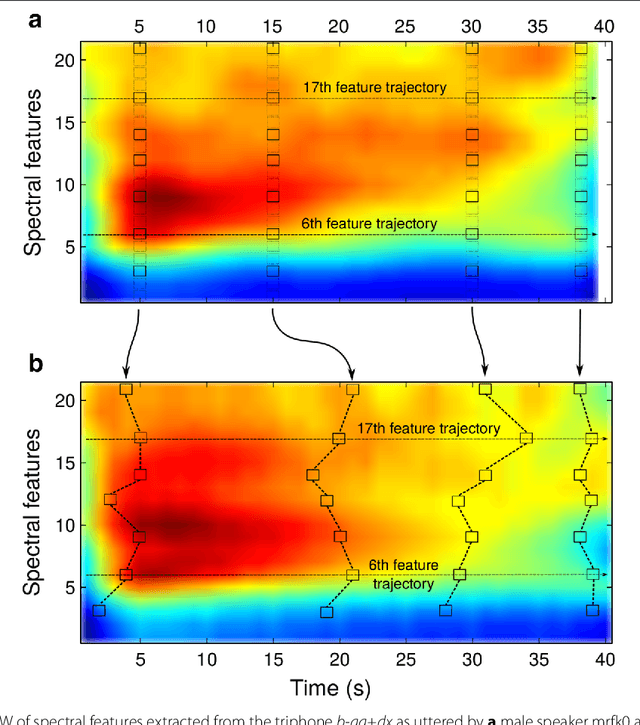
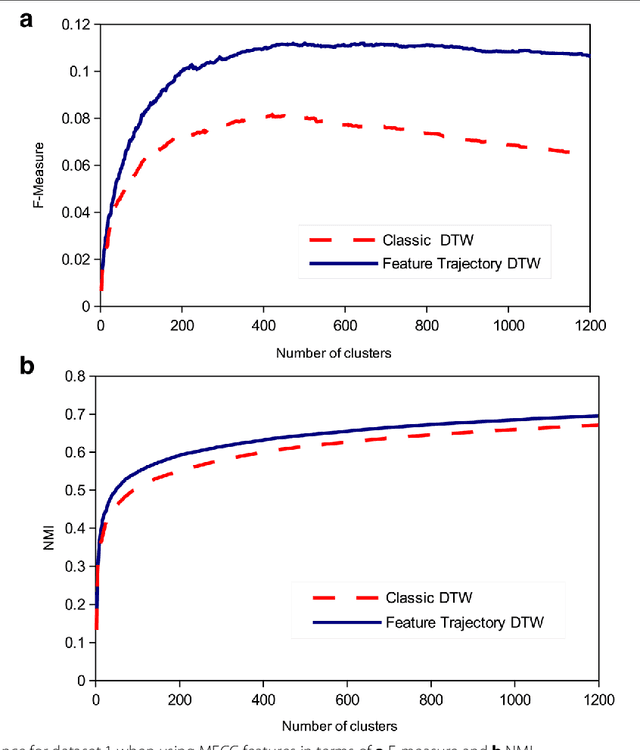
Dynamic time warping (DTW) can be used to compute the similarity between two sequences of generally differing length. We propose a modification to DTW that performs individual and independent pairwise alignment of feature trajectories. The modified technique, termed feature trajectory dynamic time warping (FTDTW), is applied as a similarity measure in the agglomerative hierarchical clustering of speech segments. Experiments using MFCC and PLP parametrisations extracted from TIMIT and from the Spoken Arabic Digit Dataset (SADD) show consistent and statistically significant improvements in the quality of the resulting clusters in terms of F-measure and normalised mutual information (NMI).