 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomatically assessing oral narratives of Afrikaans and isiXhosa children
Jul 18, 2025Developing narrative and comprehension skills in early childhood is critical for later literacy. However, teachers in large preschool classrooms struggle to accurately identify students who require intervention. We present a system for automatically assessing oral narratives of preschool children in Afrikaans and isiXhosa. The system uses automatic speech recognition followed by a machine learning scoring model to predict narrative and comprehension scores. For scoring predicted transcripts, we compare a linear model to a large language model (LLM). The LLM-based system outperforms the linear model in most cases, but the linear system is competitive despite its simplicity. The LLM-based system is comparable to a human expert in flagging children who require intervention. We lay the foundation for automatic oral assessments in classrooms, giving teachers extra capacity to focus on personalised support for children's learning.
Feature-based analysis of oral narratives from Afrikaans and isiXhosa children
Jul 17, 2025Oral narrative skills are strong predictors of later literacy development. This study examines the features of oral narratives from children who were identified by experts as requiring intervention. Using simple machine learning methods, we analyse recorded stories from four- and five-year-old Afrikaans- and isiXhosa-speaking children. Consistent with prior research, we identify lexical diversity (unique words) and length-based features (mean utterance length) as indicators of typical development, but features like articulation rate prove less informative. Despite cross-linguistic variation in part-of-speech patterns, the use of specific verbs and auxiliaries associated with goal-directed storytelling is correlated with a reduced likelihood of requiring intervention. Our analysis of two linguistically distinct languages reveals both language-specific and shared predictors of narrative proficiency, with implications for early assessment in multilingual contexts.
Speech Recognition for Automatically Assessing Afrikaans and isiXhosa Preschool Oral Narratives
Jan 11, 2025We develop automatic speech recognition (ASR) systems for stories told by Afrikaans and isiXhosa preschool children. Oral narratives provide a way to assess children's language development before they learn to read. We consider a range of prior child-speech ASR strategies to determine which is best suited to this unique setting. Using Whisper and only 5 minutes of transcribed in-domain child speech, we find that additional in-domain adult data (adult speech matching the story domain) provides the biggest improvement, especially when coupled with voice conversion. Semi-supervised learning also helps for both languages, while parameter-efficient fine-tuning helps on Afrikaans but not on isiXhosa (which is under-represented in the Whisper model). Few child-speech studies look at non-English data, and even fewer at the preschool ages of 4 and 5. Our work therefore represents a unique validation of a wide range of previous child-speech ASR strategies in an under-explored setting.
Semi-supervised Development of ASR Systems for Multilingual Code-switched Speech in Under-resourced Languages
Mar 06, 2020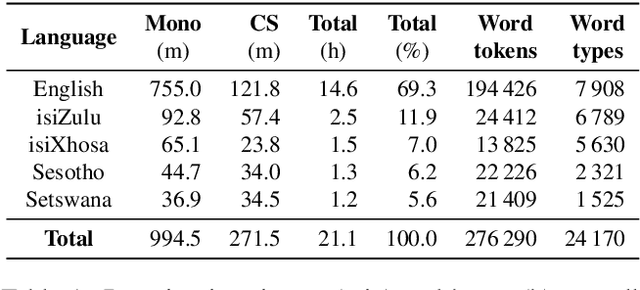
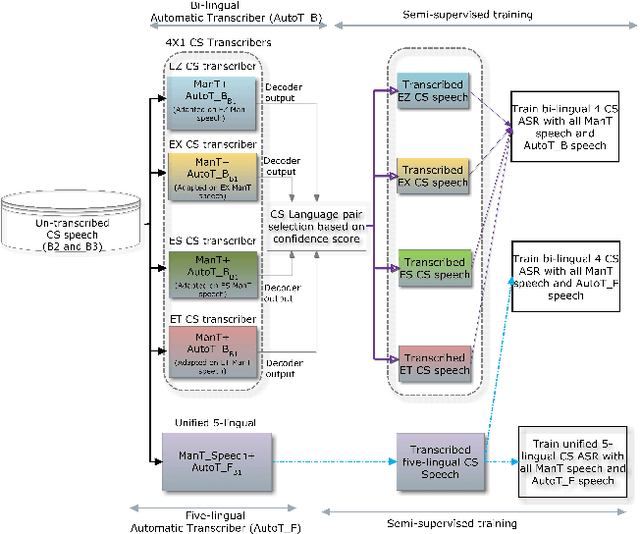
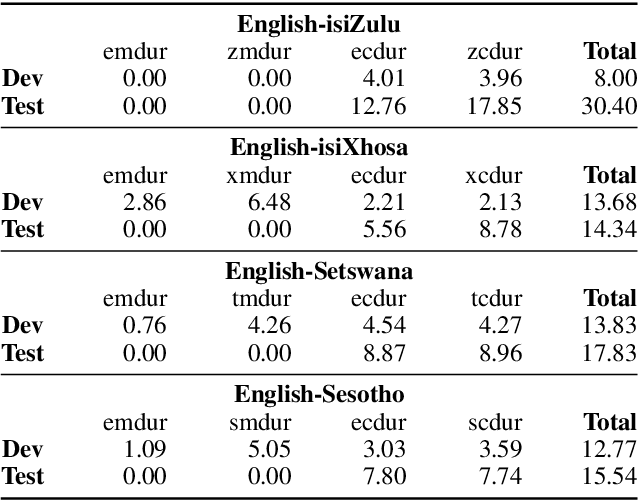
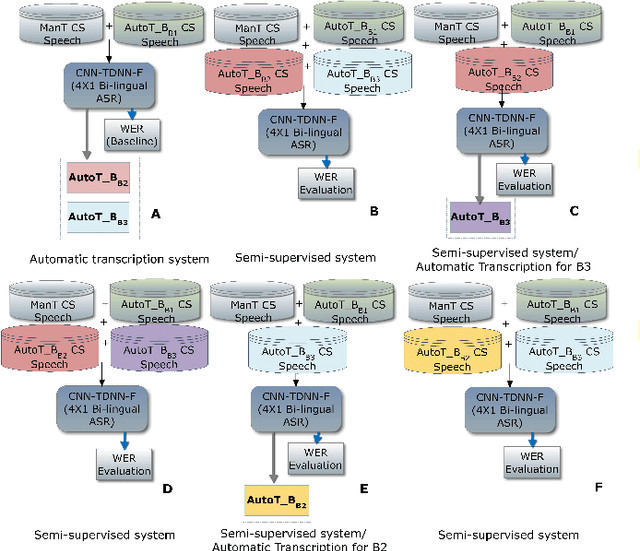
This paper reports on the semi-supervised development of acoustic and language models for under-resourced, code-switched speech in five South African languages. Two approaches are considered. The first constructs four separate bilingual automatic speech recognisers (ASRs) corresponding to four different language pairs between which speakers switch frequently. The second uses a single, unified, five-lingual ASR system that represents all the languages (English, isiZulu, isiXhosa, Setswana and Sesotho). We evaluate the effectiveness of these two approaches when used to add additional data to our extremely sparse training sets. Results indicate that batch-wise semi-supervised training yields better results than a non-batch-wise approach. Furthermore, while the separate bilingual systems achieved better recognition performance than the unified system, they benefited more from pseudo-labels generated by the five-lingual system than from those generated by the bilingual systems.
Semi-supervised acoustic model training for five-lingual code-switched ASR
Jun 20, 2019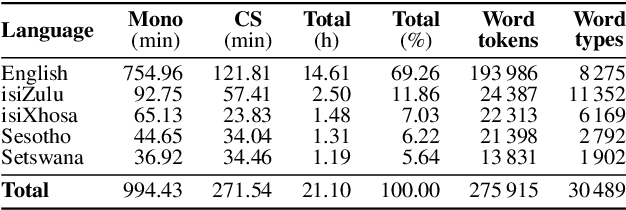
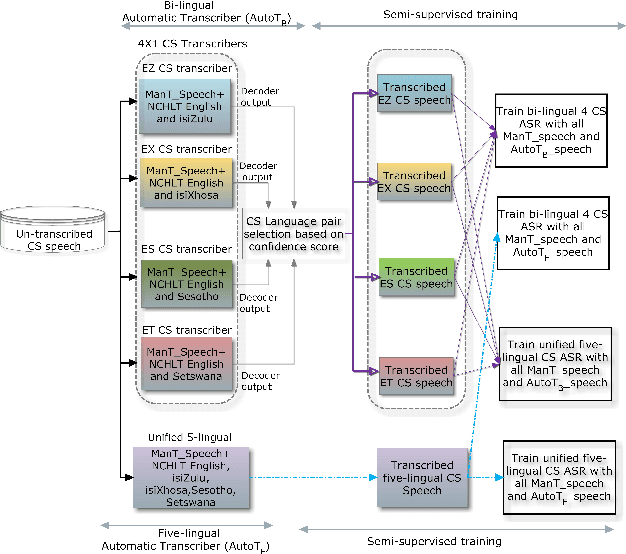
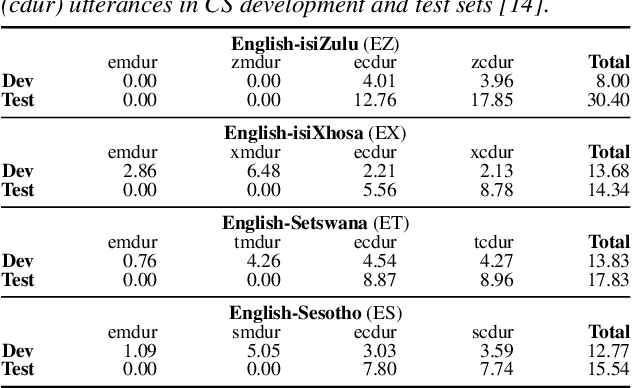
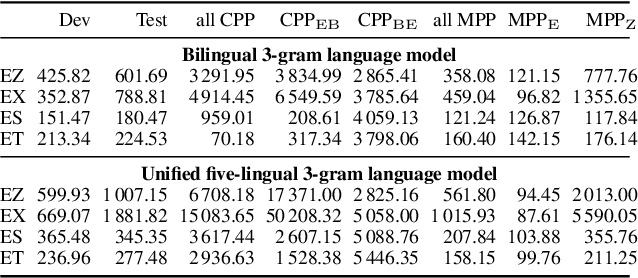
This paper presents recent progress in the acoustic modelling of under-resourced code-switched (CS) speech in multiple South African languages. We consider two approaches. The first constructs separate bilingual acoustic models corresponding to language pairs (English-isiZulu, English-isiXhosa, English-Setswana and English-Sesotho). The second constructs a single unified five-lingual acoustic model representing all the languages (English, isiZulu, isiXhosa, Setswana and Sesotho). For these two approaches we consider the effectiveness of semi-supervised training to increase the size of the very sparse acoustic training sets. Using approximately 11 hours of untranscribed speech, we show that both approaches benefit from semi-supervised training. The bilingual TDNN-F acoustic models also benefit from the addition of CNN layers (CNN-TDNN-F), while the five-lingual system does not show any significant improvement. Furthermore, because English is common to all language pairs in our data, it dominates when training a unified language model, leading to improved English ASR performance at the expense of the other languages. Nevertheless, the five-lingual model offers flexibility because it can process more than two languages simultaneously, and is therefore an attractive option as an automatic transcription system in a semi-supervised training pipeline.
Building a Unified Code-Switching ASR System for South African Languages
Jul 28, 2018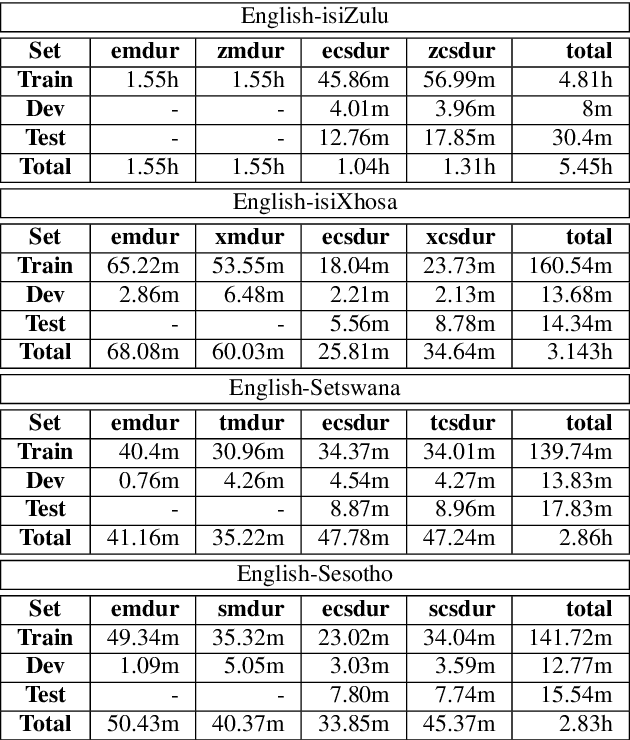
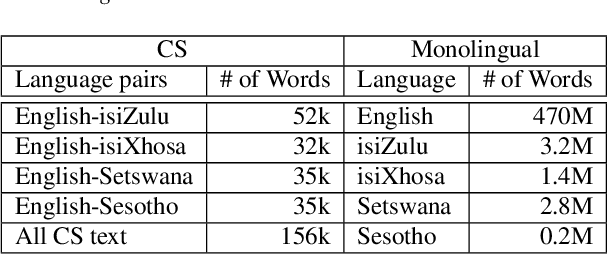
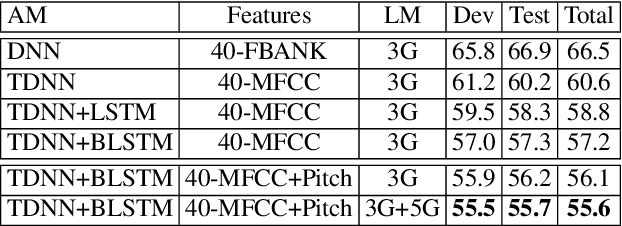

We present our first efforts towards building a single multilingual automatic speech recognition (ASR) system that can process code-switching (CS) speech in five languages spoken within the same population. This contrasts with related prior work which focuses on the recognition of CS speech in bilingual scenarios. Recently, we have compiled a small five-language corpus of South African soap opera speech which contains examples of CS between 5 languages occurring in various contexts such as using English as the matrix language and switching to other indigenous languages. The ASR system presented in this work is trained on 4 corpora containing English-isiZulu, English-isiXhosa, English-Setswana and English-Sesotho CS speech. The interpolation of multiple language models trained on these language pairs enables the ASR system to hypothesize mixed word sequences from these 5 languages. We evaluate various state-of-the-art acoustic models trained on this 5-lingual training data and report ASR accuracy and language recognition performance on the development and test sets of the South African multilingual soap opera corpus.