 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSequential Membership Inference Attacks
Feb 18, 2026Modern AI models are not static. They go through multiple updates in their lifecycles. Thus, exploiting the model dynamics to create stronger Membership Inference (MI) attacks and tighter privacy audits are timely questions. Though the literature empirically shows that using a sequence of model updates can increase the power of MI attacks, rigorous analysis of the `optimal' MI attacks is limited to static models with infinite samples. Hence, we develop an `optimal' MI attack, SeMI*, that uses the sequence of model updates to identify the presence of a target inserted at a certain update step. For the empirical mean computation, we derive the optimal power of SeMI*, while accessing a finite number of samples with or without privacy. Our results retrieve the existing asymptotic analysis. We observe that having access to the model sequence avoids the dilution of MI signals unlike the existing attacks on the final model, where the MI signal vanishes as training data accumulates. Furthermore, an adversary can use SeMI* to tune both the insertion time and the canary to yield tighter privacy audits. Finally, we conduct experiments across data distributions and models trained or fine-tuned with DP-SGD demonstrating that practical variants of SeMI* lead to tighter privacy audits than the baselines.
Octax: Accelerated CHIP-8 Arcade Environments for Reinforcement Learning in JAX
Oct 02, 2025Reinforcement learning (RL) research requires diverse, challenging environments that are both tractable and scalable. While modern video games may offer rich dynamics, they are computationally expensive and poorly suited for large-scale experimentation due to their CPU-bound execution. We introduce Octax, a high-performance suite of classic arcade game environments implemented in JAX, based on CHIP-8 emulation, a predecessor to Atari, which is widely adopted as a benchmark in RL research. Octax provides the JAX community with a long-awaited end-to-end GPU alternative to the Atari benchmark, offering image-based environments, spanning puzzle, action, and strategy genres, all executable at massive scale on modern GPUs. Our JAX-based implementation achieves orders-of-magnitude speedups over traditional CPU emulators while maintaining perfect fidelity to the original game mechanics. We demonstrate Octax's capabilities by training RL agents across multiple games, showing significant improvements in training speed and scalability compared to existing solutions. The environment's modular design enables researchers to easily extend the suite with new games or generate novel environments using large language models, making it an ideal platform for large-scale RL experimentation.
DP-SPRT: Differentially Private Sequential Probability Ratio Tests
Aug 08, 2025We revisit Wald's celebrated Sequential Probability Ratio Test for sequential tests of two simple hypotheses, under privacy constraints. We propose DP-SPRT, a wrapper that can be calibrated to achieve desired error probabilities and privacy constraints, addressing a significant gap in previous work. DP-SPRT relies on a private mechanism that processes a sequence of queries and stops after privately determining when the query results fall outside a predefined interval. This OutsideInterval mechanism improves upon naive composition of existing techniques like AboveThreshold, potentially benefiting other sequential algorithms. We prove generic upper bounds on the error and sample complexity of DP-SPRT that can accommodate various noise distributions based on the practitioner's privacy needs. We exemplify them in two settings: Laplace noise (pure Differential Privacy) and Gaussian noise (R\'enyi differential privacy). In the former setting, by providing a lower bound on the sample complexity of any $\epsilon$-DP test with prescribed type I and type II errors, we show that DP-SPRT is near optimal when both errors are small and the two hypotheses are close. Moreover, we conduct an experimental study revealing its good practical performance.
Exploring Flow-Lenia Universes with a Curiosity-driven AI Scientist: Discovering Diverse Ecosystem Dynamics
May 21, 2025We present a method for the automated discovery of system-level dynamics in Flow-Lenia$-$a continuous cellular automaton (CA) with mass conservation and parameter localization$-$using a curiosity-driven AI scientist. This method aims to uncover processes leading to self-organization of evolutionary and ecosystemic dynamics in CAs. We build on previous work which uses diversity search algorithms in Lenia to find self-organized individual patterns, and extend it to large environments that support distinct interacting patterns. We adapt Intrinsically Motivated Goal Exploration Processes (IMGEPs) to drive exploration of diverse Flow-Lenia environments using simulation-wide metrics, such as evolutionary activity, compression-based complexity, and multi-scale entropy. We test our method in two experiments, showcasing its ability to illuminate significantly more diverse dynamics compared to random search. We show qualitative results illustrating how ecosystemic simulations enable self-organization of complex collective behaviors not captured by previous individual pattern search and analysis. We complement automated discovery with an interactive exploration tool, creating an effective human-AI collaborative workflow for scientific investigation. Though demonstrated specifically with Flow-Lenia, this methodology provides a framework potentially applicable to other parameterizable complex systems where understanding emergent collective properties is of interest.
Leveraging Model Interpretability and Stability to increase Model Robustness
Nov 05, 2019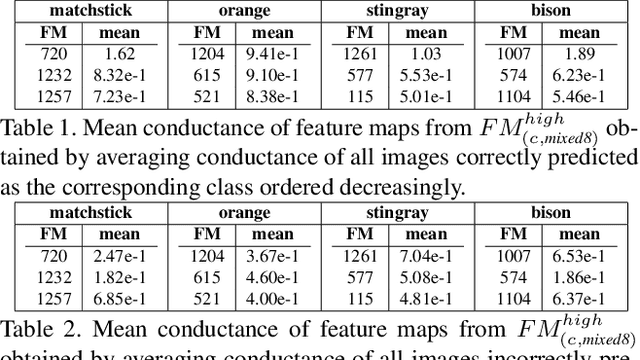
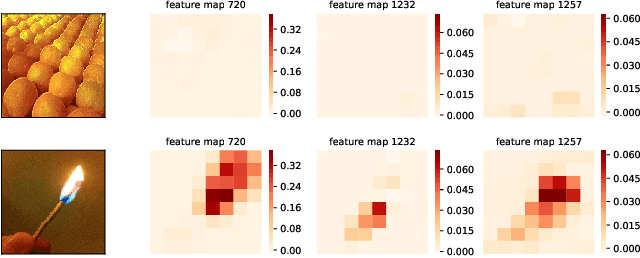
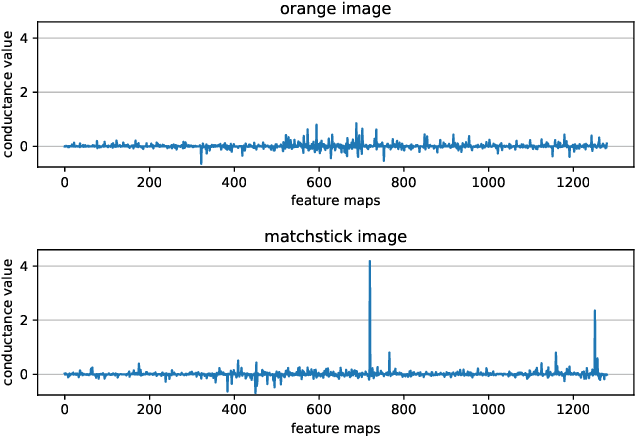
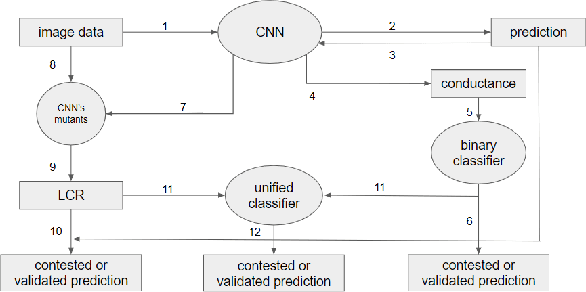
State of the art Deep Neural Networks (DNN) can now achieve above human level accuracy on image classification tasks. However their outstanding performances come along with a complex inference mechanism making them arduously interpretable models. In order to understand the underlying prediction rules of DNNs, Dhamdhere et al. propose an interpretability method to break down a DNN prediction score as sum of its hidden unit contributions, in the form of a metric called conductance. Analyzing conductances of DNN hidden units, we find out there is a difference in how wrong and correct predictions are inferred. We identify distinguishable patterns of hidden unit activations for wrong and correct predictions. We then use an error detector in the form of a binary classifier on top of the DNN to automatically discriminate wrong and correct predictions of the DNN based on their hidden unit activations. Detected wrong predictions are discarded, increasing the model robustness. A different approach to distinguish wrong and correct predictions of DNNs is proposed by Wang et al. whose method is based on the premise that input samples leading a DNN into making wrong predictions are less stable to the DNN weight changes than correctly classified input samples. In our study, we compare both methods and find out by combining them that better detection of wrong predictions can be achieved.