 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCausal-Anticausal Decomposition of Speech using Complex Cepstrum for Glottal Source Estimation
Dec 30, 2019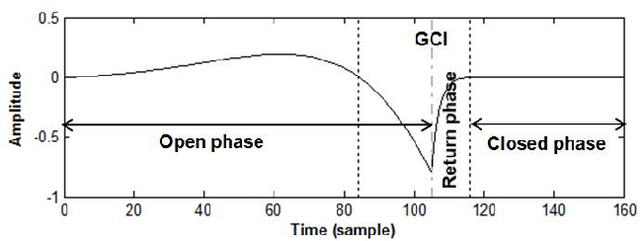
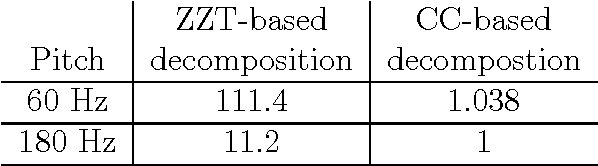
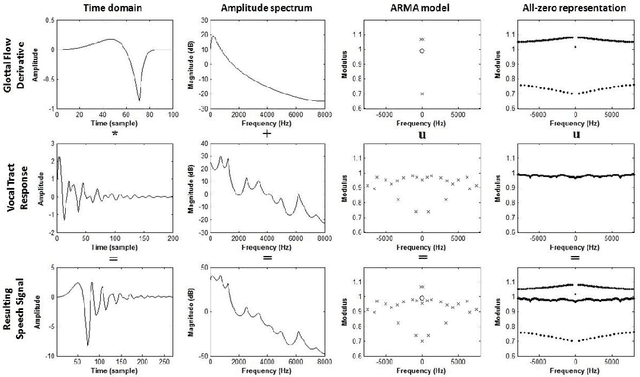

Complex cepstrum is known in the literature for linearly separating causal and anticausal components. Relying on advances achieved by the Zeros of the Z-Transform (ZZT) technique, we here investigate the possibility of using complex cepstrum for glottal flow estimation on a large-scale database. Via a systematic study of the windowing effects on the deconvolution quality, we show that the complex cepstrum causal-anticausal decomposition can be effectively used for glottal flow estimation when specific windowing criteria are met. It is also shown that this complex cepstral decomposition gives similar glottal estimates as obtained with the ZZT method. However, as complex cepstrum uses FFT operations instead of requiring the factoring of high-degree polynomials, the method benefits from a much higher speed. Finally in our tests on a large corpus of real expressive speech, we show that the proposed method has the potential to be used for voice quality analysis.
Complex Cepstrum-based Decomposition of Speech for Glottal Source Estimation
Dec 29, 2019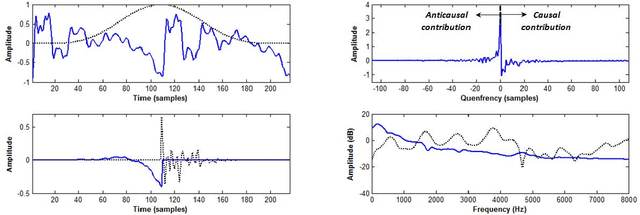
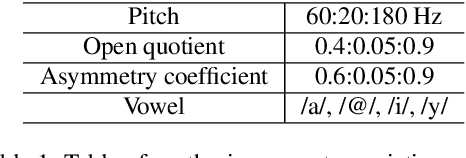
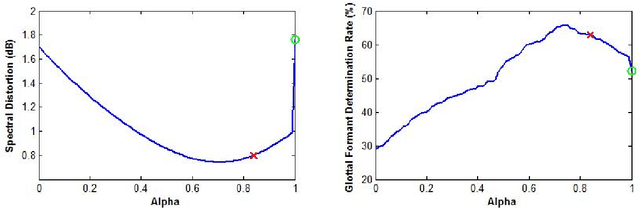
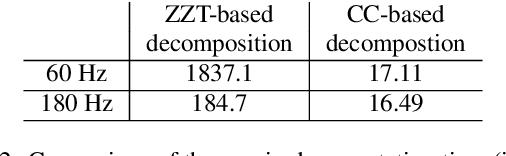
Homomorphic analysis is a well-known method for the separation of non-linearly combined signals. More particularly, the use of complex cepstrum for source-tract deconvolution has been discussed in various articles. However there exists no study which proposes a glottal flow estimation methodology based on cepstrum and reports effective results. In this paper, we show that complex cepstrum can be effectively used for glottal flow estimation by separating the causal and anticausal components of a windowed speech signal as done by the Zeros of the Z-Transform (ZZT) decomposition. Based on exactly the same principles presented for ZZT decomposition, windowing should be applied such that the windowed speech signals exhibit mixed-phase characteristics which conform the speech production model that the anticausal component is mainly due to the glottal flow open phase. The advantage of the complex cepstrum-based approach compared to the ZZT decomposition is its much higher speed.
The Deterministic plus Stochastic Model of the Residual Signal and its Applications
Dec 29, 2019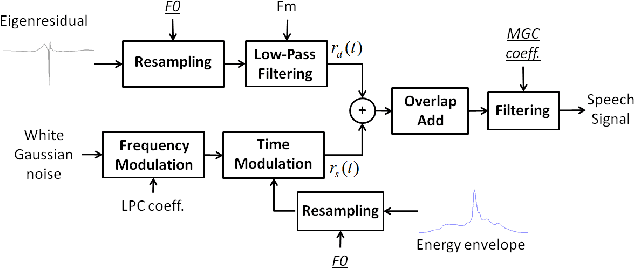
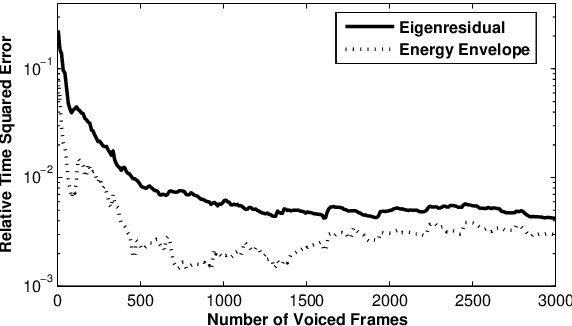
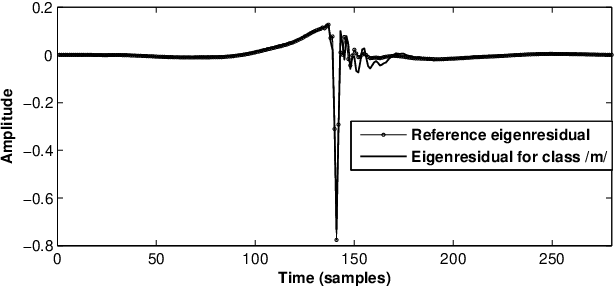
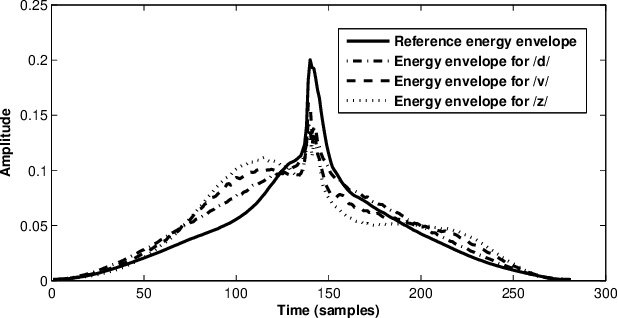
The modeling of speech production often relies on a source-filter approach. Although methods parameterizing the filter have nowadays reached a certain maturity, there is still a lot to be gained for several speech processing applications in finding an appropriate excitation model. This manuscript presents a Deterministic plus Stochastic Model (DSM) of the residual signal. The DSM consists of two contributions acting in two distinct spectral bands delimited by a maximum voiced frequency. Both components are extracted from an analysis performed on a speaker-dependent dataset of pitch-synchronous residual frames. The deterministic part models the low-frequency contents and arises from an orthonormal decomposition of these frames. As for the stochastic component, it is a high-frequency noise modulated both in time and frequency. Some interesting phonetic and computational properties of the DSM are also highlighted. The applicability of the DSM in two fields of speech processing is then studied. First, it is shown that incorporating the DSM vocoder in HMM-based speech synthesis enhances the delivered quality. The proposed approach turns out to significantly outperform the traditional pulse excitation and provides a quality equivalent to STRAIGHT. In a second application, the potential of glottal signatures derived from the proposed DSM is investigated for speaker identification purpose. Interestingly, these signatures are shown to lead to better recognition rates than other glottal-based methods.
A Deterministic plus Stochastic Model of the Residual Signal for Improved Parametric Speech Synthesis
Dec 29, 2019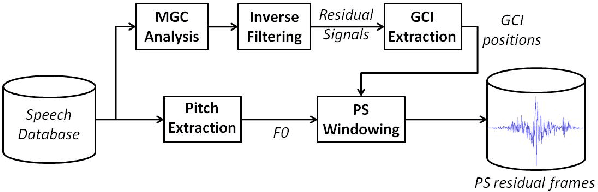
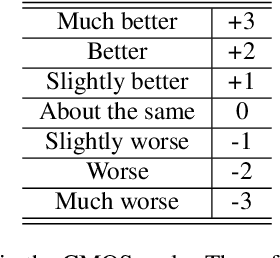
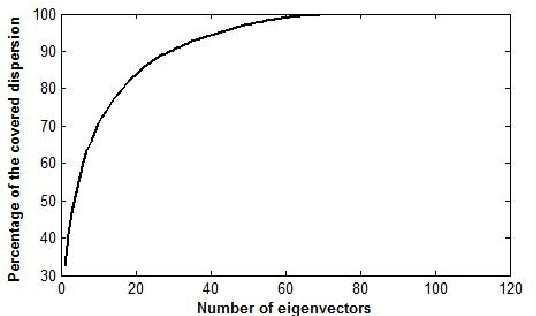
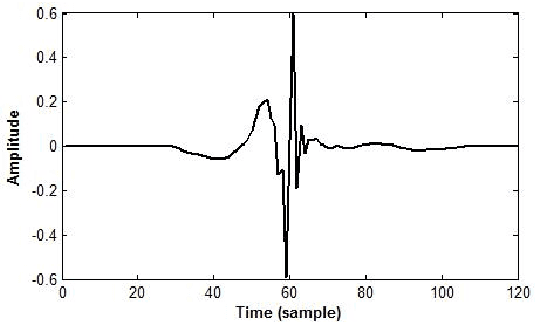
Speech generated by parametric synthesizers generally suffers from a typical buzziness, similar to what was encountered in old LPC-like vocoders. In order to alleviate this problem, a more suited modeling of the excitation should be adopted. For this, we hereby propose an adaptation of the Deterministic plus Stochastic Model (DSM) for the residual. In this model, the excitation is divided into two distinct spectral bands delimited by the maximum voiced frequency. The deterministic part concerns the low-frequency contents and consists of a decomposition of pitch-synchronous residual frames on an orthonormal basis obtained by Principal Component Analysis. The stochastic component is a high-pass filtered noise whose time structure is modulated by an energy-envelope, similarly to what is done in the Harmonic plus Noise Model (HNM). The proposed residual model is integrated within a HMM-based speech synthesizer and is compared to the traditional excitation through a subjective test. Results show a significative improvement for both male and female voices. In addition the proposed model requires few computational load and memory, which is essential for its integration in commercial applications.
A Comparative Study of Glottal Source Estimation Techniques
Dec 28, 2019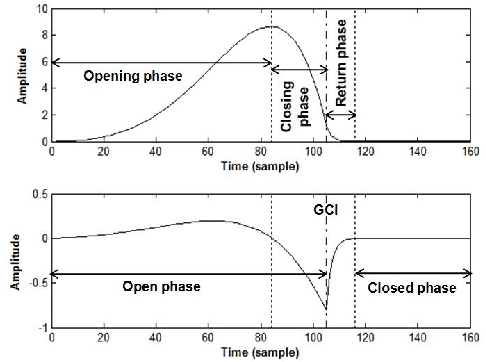

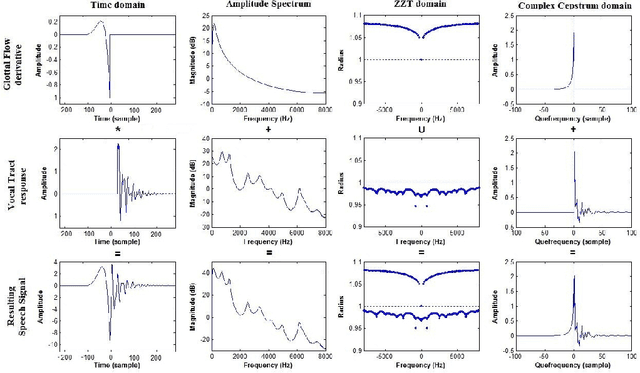
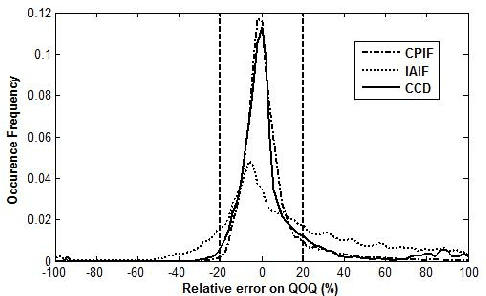
Source-tract decomposition (or glottal flow estimation) is one of the basic problems of speech processing. For this, several techniques have been proposed in the literature. However studies comparing different approaches are almost nonexistent. Besides, experiments have been systematically performed either on synthetic speech or on sustained vowels. In this study we compare three of the main representative state-of-the-art methods of glottal flow estimation: closed-phase inverse filtering, iterative and adaptive inverse filtering, and mixed-phase decomposition. These techniques are first submitted to an objective assessment test on synthetic speech signals. Their sensitivity to various factors affecting the estimation quality, as well as their robustness to noise are studied. In a second experiment, their ability to label voice quality (tensed, modal, soft) is studied on a large corpus of real connected speech. It is shown that changes of voice quality are reflected by significant modifications in glottal feature distributions. Techniques based on the mixed-phase decomposition and on a closed-phase inverse filtering process turn out to give the best results on both clean synthetic and real speech signals. On the other hand, iterative and adaptive inverse filtering is recommended in noisy environments for its high robustness.
Glottal Closure and Opening Instant Detection from Speech Signals
Dec 28, 2019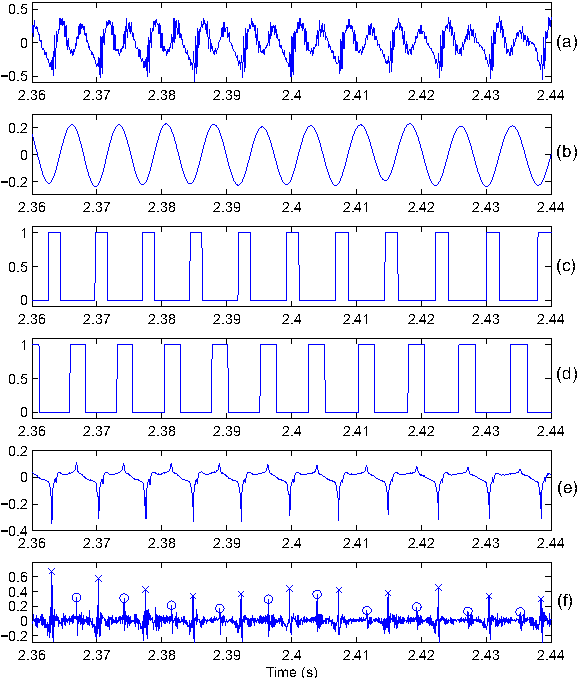
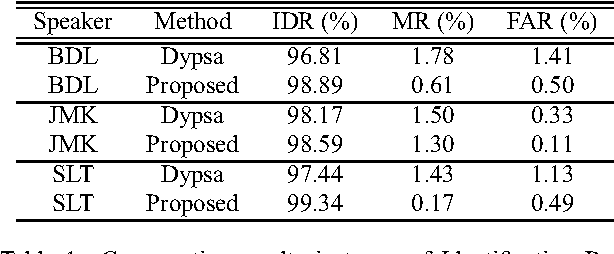
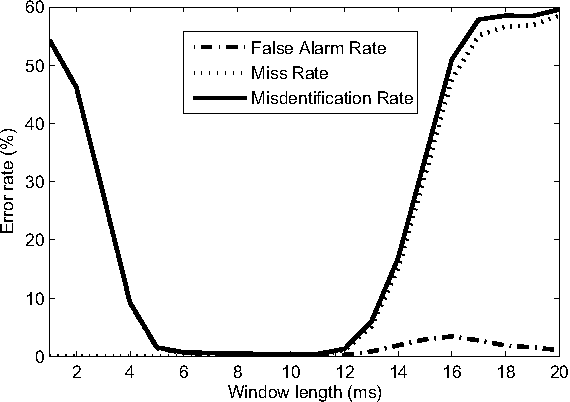
This paper proposes a new procedure to detect Glottal Closure and Opening Instants (GCIs and GOIs) directly from speech waveforms. The procedure is divided into two successive steps. First a mean-based signal is computed, and intervals where speech events are expected to occur are extracted from it. Secondly, at each interval a precise position of the speech event is assigned by locating a discontinuity in the Linear Prediction residual. The proposed method is compared to the DYPSA algorithm on the CMU ARCTIC database. A significant improvement as well as a better noise robustness are reported. Besides, results of GOI identification accuracy are promising for the glottal source characterization.
Detection of Glottal Closure Instants from Speech Signals: a Quantitative Review
Dec 28, 2019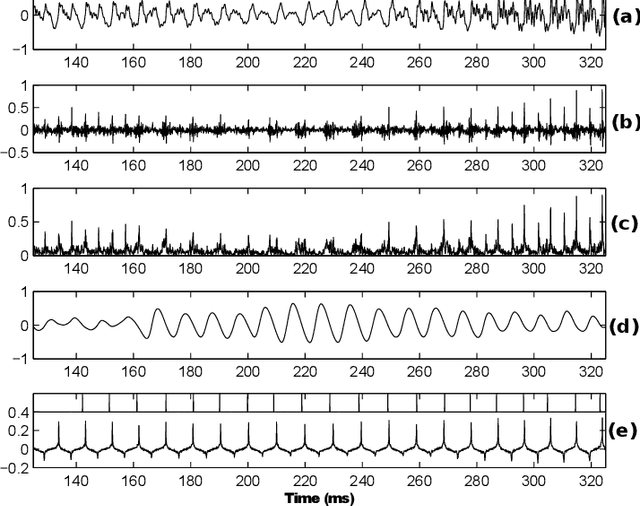
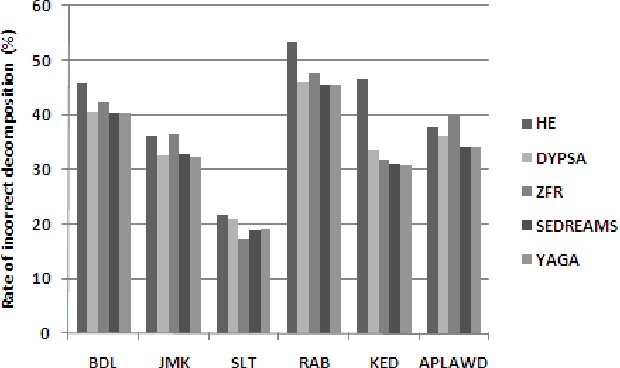
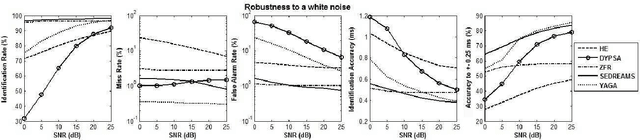
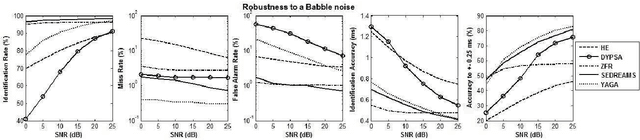
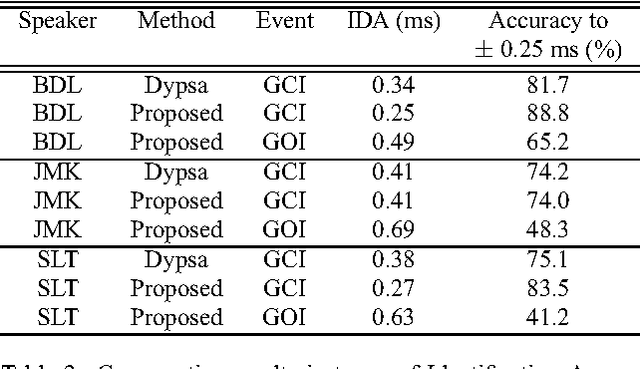
The pseudo-periodicity of voiced speech can be exploited in several speech processing applications. This requires however that the precise locations of the Glottal Closure Instants (GCIs) are available. The focus of this paper is the evaluation of automatic methods for the detection of GCIs directly from the speech waveform. Five state-of-the-art GCI detection algorithms are compared using six different databases with contemporaneous electroglottographic recordings as ground truth, and containing many hours of speech by multiple speakers. The five techniques compared are the Hilbert Envelope-based detection (HE), the Zero Frequency Resonator-based method (ZFR), the Dynamic Programming Phase Slope Algorithm (DYPSA), the Speech Event Detection using the Residual Excitation And a Mean-based Signal (SEDREAMS) and the Yet Another GCI Algorithm (YAGA). The efficacy of these methods is first evaluated on clean speech, both in terms of reliabililty and accuracy. Their robustness to additive noise and to reverberation is also assessed. A further contribution of the paper is the evaluation of their performance on a concrete application of speech processing: the causal-anticausal decomposition of speech. It is shown that for clean speech, SEDREAMS and YAGA are the best performing techniques, both in terms of identification rate and accuracy. ZFR and SEDREAMS also show a superior robustness to additive noise and reverberation.
The Theory behind Controllable Expressive Speech Synthesis: a Cross-disciplinary Approach
Oct 14, 2019
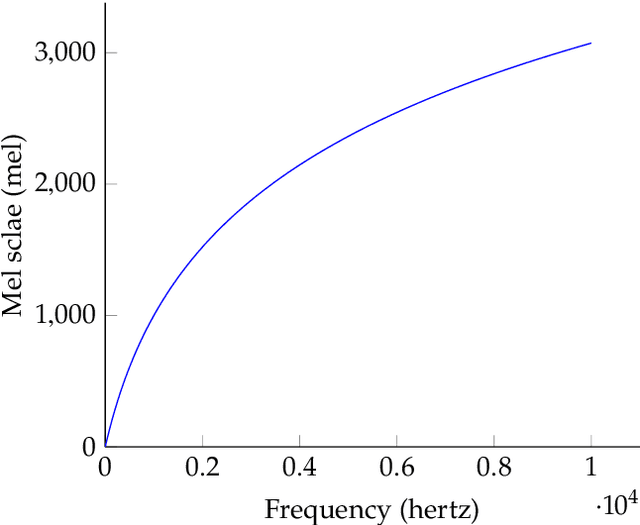
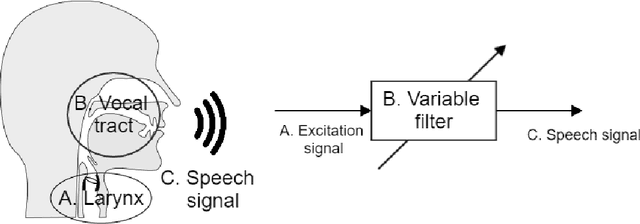
As part of the Human-Computer Interaction field, Expressive speech synthesis is a very rich domain as it requires knowledge in areas such as machine learning, signal processing, sociology, psychology. In this Chapter, we will focus mostly on the technical side. From the recording of expressive speech to its modeling, the reader will have an overview of the main paradigms used in this field, through some of the most prominent systems and methods. We explain how speech can be represented and encoded with audio features. We present a history of the main methods of Text-to-Speech synthesis: concatenative, parametric and statistical parametric speech synthesis. Finally, we focus on the last one, with the last techniques modeling Text-to-Speech synthesis as a sequence-to-sequence problem. This enables the use of Deep Learning blocks such as Convolutional and Recurrent Neural Networks as well as Attention Mechanism. The last part of the Chapter intends to assemble the different aspects of the theory and summarize the concepts.
Visualization and Interpretation of Latent Spaces for Controlling Expressive Speech Synthesis through Audio Analysis
Mar 27, 2019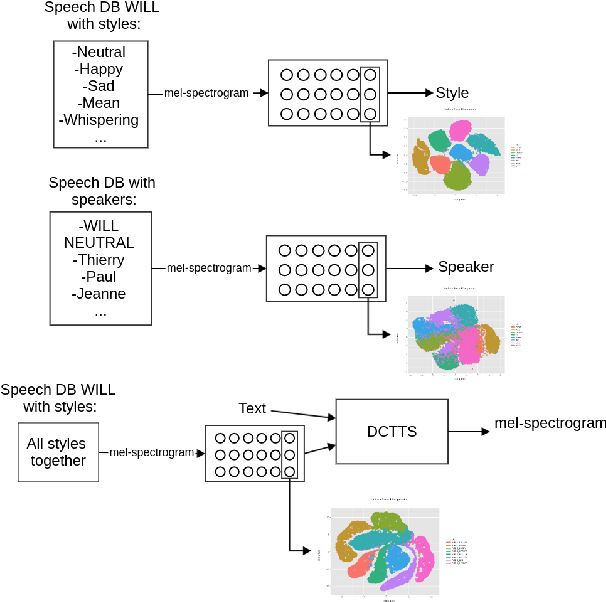
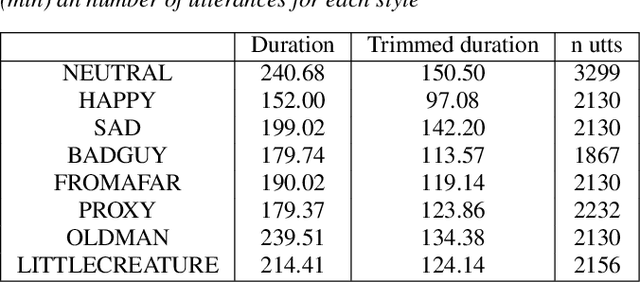
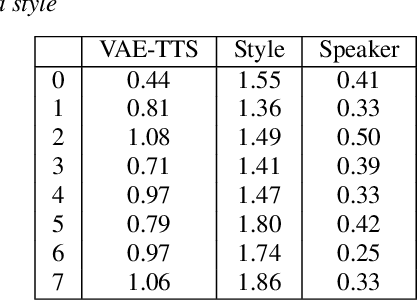
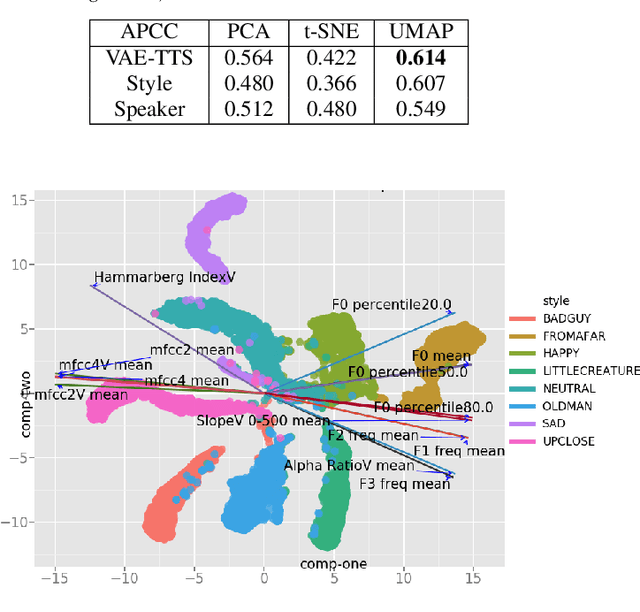
The field of Text-to-Speech has experienced huge improvements last years benefiting from deep learning techniques. Producing realistic speech becomes possible now. As a consequence, the research on the control of the expressiveness, allowing to generate speech in different styles or manners, has attracted increasing attention lately. Systems able to control style have been developed and show impressive results. However the control parameters often consist of latent variables and remain complex to interpret. In this paper, we analyze and compare different latent spaces and obtain an interpretation of their influence on expressive speech. This will enable the possibility to build controllable speech synthesis systems with an understandable behaviour.
Exploring Transfer Learning for Low Resource Emotional TTS
Jan 14, 2019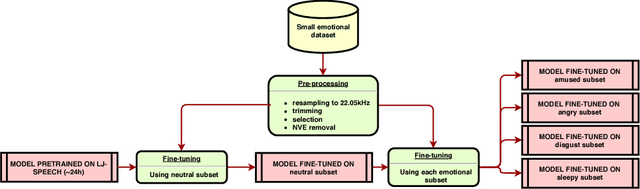
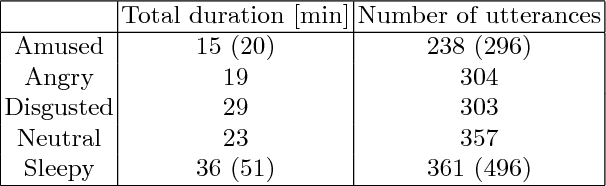

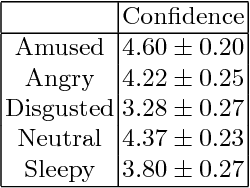
During the last few years, spoken language technologies have known a big improvement thanks to Deep Learning. However Deep Learning-based algorithms require amounts of data that are often difficult and costly to gather. Particularly, modeling the variability in speech of different speakers, different styles or different emotions with few data remains challenging. In this paper, we investigate how to leverage fine-tuning on a pre-trained Deep Learning-based TTS model to synthesize speech with a small dataset of another speaker. Then we investigate the possibility to adapt this model to have emotional TTS by fine-tuning the neutral TTS model with a small emotional dataset.