 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeimGHUM: Implicit Generative Models of 3D Human Shape and Articulated Pose
Aug 24, 2021

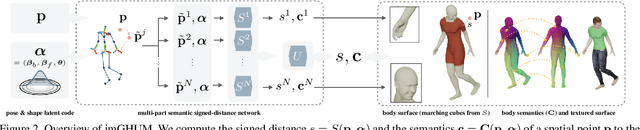
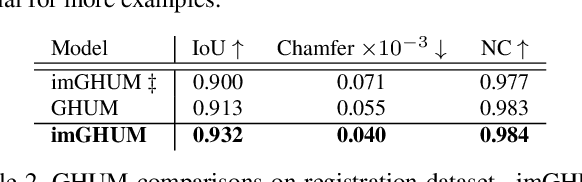
We present imGHUM, the first holistic generative model of 3D human shape and articulated pose, represented as a signed distance function. In contrast to prior work, we model the full human body implicitly as a function zero-level-set and without the use of an explicit template mesh. We propose a novel network architecture and a learning paradigm, which make it possible to learn a detailed implicit generative model of human pose, shape, and semantics, on par with state-of-the-art mesh-based models. Our model features desired detail for human models, such as articulated pose including hand motion and facial expressions, a broad spectrum of shape variations, and can be queried at arbitrary resolutions and spatial locations. Additionally, our model has attached spatial semantics making it straightforward to establish correspondences between different shape instances, thus enabling applications that are difficult to tackle using classical implicit representations. In extensive experiments, we demonstrate the model accuracy and its applicability to current research problems.
SelfPose: 3D Egocentric Pose Estimation from a Headset Mounted Camera
Nov 02, 2020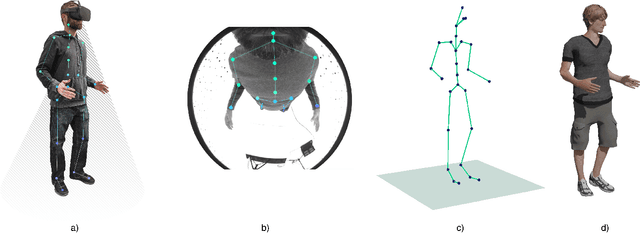


We present a solution to egocentric 3D body pose estimation from monocular images captured from downward looking fish-eye cameras installed on the rim of a head mounted VR device. This unusual viewpoint leads to images with unique visual appearance, with severe self-occlusions and perspective distortions that result in drastic differences in resolution between lower and upper body. We propose an encoder-decoder architecture with a novel multi-branch decoder designed to account for the varying uncertainty in 2D predictions. The quantitative evaluation, on synthetic and real-world datasets, shows that our strategy leads to substantial improvements in accuracy over state of the art egocentric approaches. To tackle the lack of labelled data we also introduced a large photo-realistic synthetic dataset. xR-EgoPose offers high quality renderings of people with diverse skintones, body shapes and clothing, performing a range of actions. Our experiments show that the high variability in our new synthetic training corpus leads to good generalization to real world footage and to state of theart results on real world datasets with ground truth. Moreover, an evaluation on the Human3.6M benchmark shows that the performance of our method is on par with top performing approaches on the more classic problem of 3D human pose from a third person viewpoint.
* 14 pages. arXiv admin note: substantial text overlap with arXiv:1907.10045
Implicit Functions in Feature Space for 3D Shape Reconstruction and Completion
Apr 15, 2020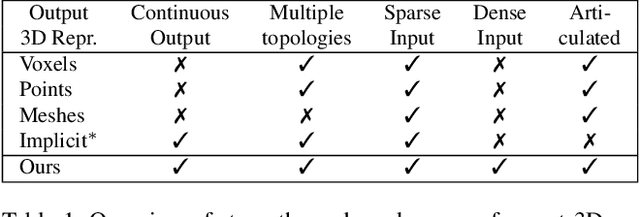
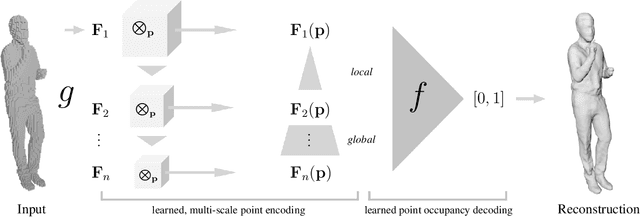
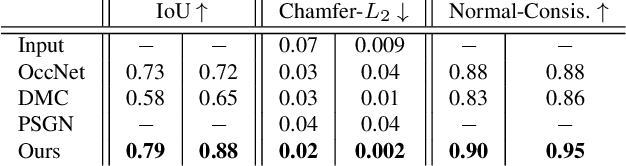
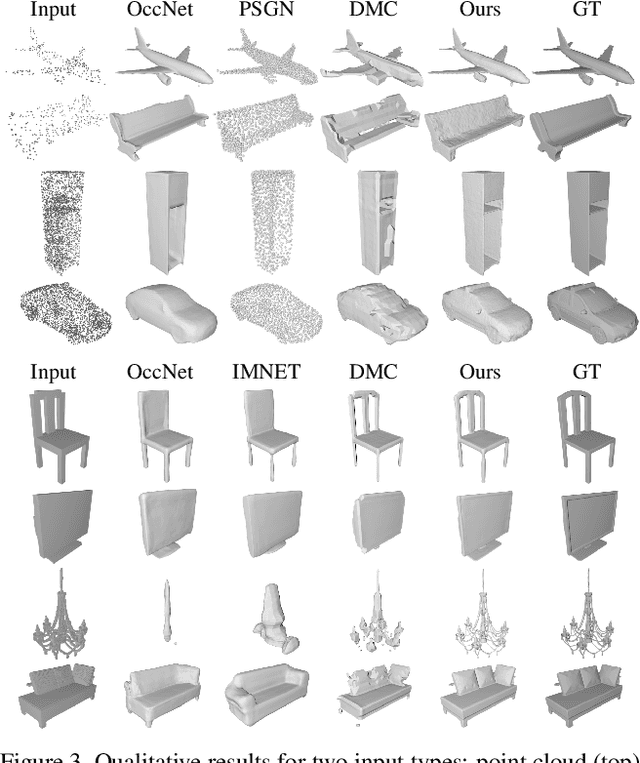
While many works focus on 3D reconstruction from images, in this paper, we focus on 3D shape reconstruction and completion from a variety of 3D inputs, which are deficient in some respect: low and high resolution voxels, sparse and dense point clouds, complete or incomplete. Processing of such 3D inputs is an increasingly important problem as they are the output of 3D scanners, which are becoming more accessible, and are the intermediate output of 3D computer vision algorithms. Recently, learned implicit functions have shown great promise as they produce continuous reconstructions. However, we identified two limitations in reconstruction from 3D inputs: 1) details present in the input data are not retained, and 2) poor reconstruction of articulated humans. To solve this, we propose Implicit Feature Networks (IF-Nets), which deliver continuous outputs, can handle multiple topologies, and complete shapes for missing or sparse input data retaining the nice properties of recent learned implicit functions, but critically they can also retain detail when it is present in the input data, and can reconstruct articulated humans. Our work differs from prior work in two crucial aspects. First, instead of using a single vector to encode a 3D shape, we extract a learnable 3-dimensional multi-scale tensor of deep features, which is aligned with the original Euclidean space embedding the shape. Second, instead of classifying x-y-z point coordinates directly, we classify deep features extracted from the tensor at a continuous query point. We show that this forces our model to make decisions based on global and local shape structure, as opposed to point coordinates, which are arbitrary under Euclidean transformations. Experiments demonstrate that IF-Nets clearly outperform prior work in 3D object reconstruction in ShapeNet, and obtain significantly more accurate 3D human reconstructions.
* {IEEE} Conference on Computer Vision and Pattern Recognition (CVPR)2020
Learning to Transfer Texture from Clothing Images to 3D Humans
Mar 30, 2020
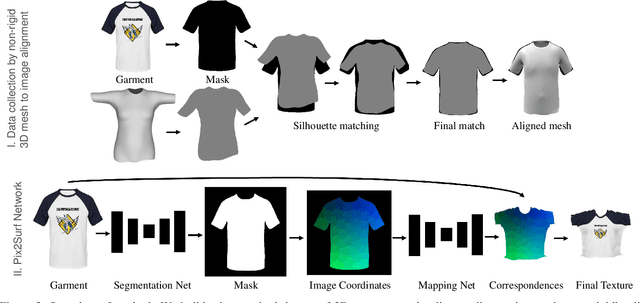

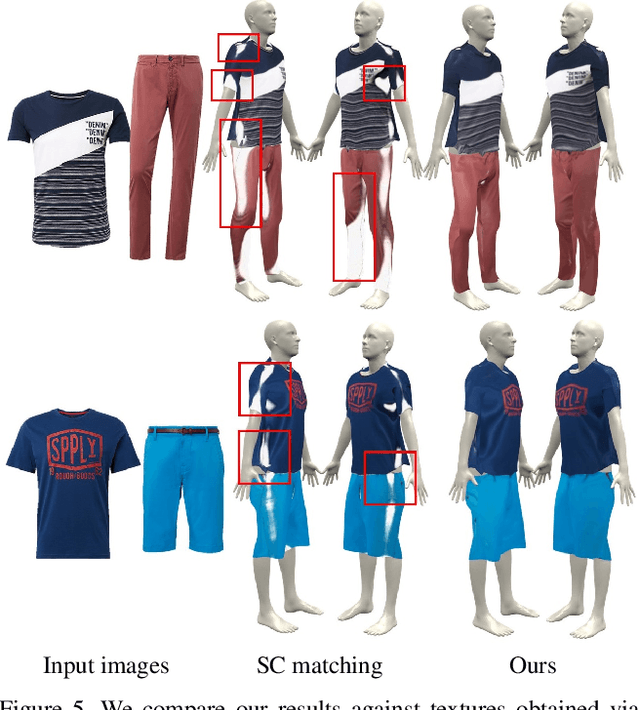
In this paper, we present a simple yet effective method to automatically transfer textures of clothing images (front and back) to 3D garments worn on top SMPL, in real time. We first automatically compute training pairs of images with aligned 3D garments using a custom non-rigid 3D to 2D registration method, which is accurate but slow. Using these pairs, we learn a mapping from pixels to the 3D garment surface. Our idea is to learn dense correspondences from garment image silhouettes to a 2D-UV map of a 3D garment surface using shape information alone, completely ignoring texture, which allows us to generalize to the wide range of web images. Several experiments demonstrate that our model is more accurate than widely used baselines such as thin-plate-spline warping and image-to-image translation networks while being orders of magnitude faster. Our model opens the door for applications such as virtual try-on, and allows for generation of 3D humans with varied textures which is necessary for learning.
Tex2Shape: Detailed Full Human Body Geometry from a Single Image
Apr 18, 2019



We present a simple yet effective method to infer detailed full human body shape from only a single photograph. Our model can infer full-body shape including face, hair, and clothing including wrinkles at interactive frame-rates. Results feature details even on parts that are occluded in the input image. Our main idea is to turn shape regression into an aligned image-to-image translation problem. The input to our method is a partial texture map of the visible region obtained from off-the-shelf methods. From a partial texture, we estimate detailed normal and vector displacement maps, which can be applied to a low-resolution smooth body model to add detail and clothing. Despite being trained purely with synthetic data, our model generalizes well to real-world photographs. Numerous results demonstrate the versatility and robustness of our method.
Learning to Reconstruct People in Clothing from a Single RGB Camera
Apr 08, 2019
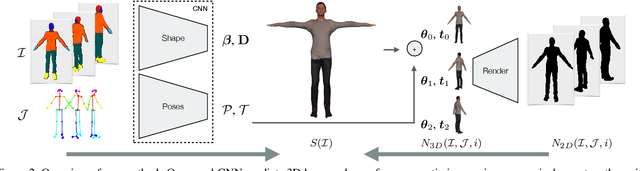
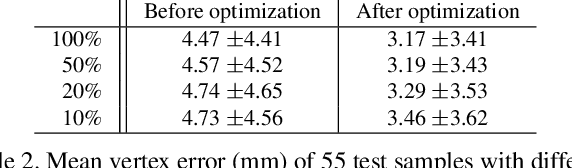
We present a learning-based model to infer the personalized 3D shape of people from a few frames (1-8) of a monocular video in which the person is moving, in less than 10 seconds with a reconstruction accuracy of 5mm. Our model learns to predict the parameters of a statistical body model and instance displacements that add clothing and hair to the shape. The model achieves fast and accurate predictions based on two key design choices. First, by predicting shape in a canonical T-pose space, the network learns to encode the images of the person into pose-invariant latent codes, where the information is fused. Second, based on the observation that feed-forward predictions are fast but do not always align with the input images, we predict using both, bottom-up and top-down streams (one per view) allowing information to flow in both directions. Learning relies only on synthetic 3D data. Once learned, the model can take a variable number of frames as input, and is able to reconstruct shapes even from a single image with an accuracy of 6mm. Results on 3 different datasets demonstrate the efficacy and accuracy of our approach.
Detailed Human Avatars from Monocular Video
Aug 03, 2018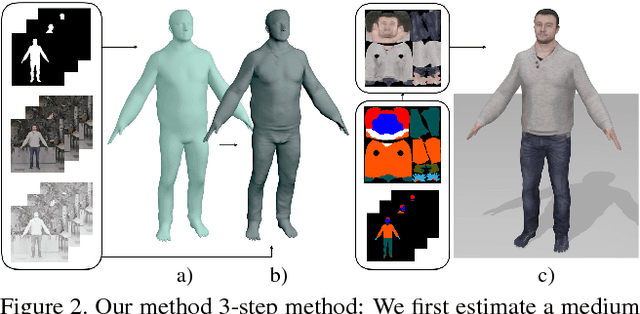
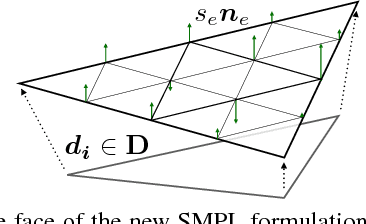


We present a novel method for high detail-preserving human avatar creation from monocular video. A parameterized body model is refined and optimized to maximally resemble subjects from a video showing them from all sides. Our avatars feature a natural face, hairstyle, clothes with garment wrinkles, and high-resolution texture. Our paper contributes facial landmark and shading-based human body shape refinement, a semantic texture prior, and a novel texture stitching strategy, resulting in the most sophisticated-looking human avatars obtained from a single video to date. Numerous results show the robustness and versatility of our method. A user study illustrates its superiority over the state-of-the-art in terms of identity preservation, level of detail, realism, and overall user preference.
Video Based Reconstruction of 3D People Models
Apr 16, 2018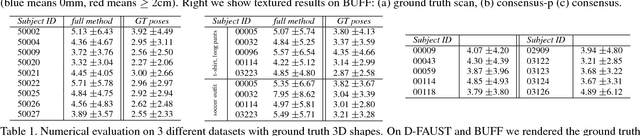
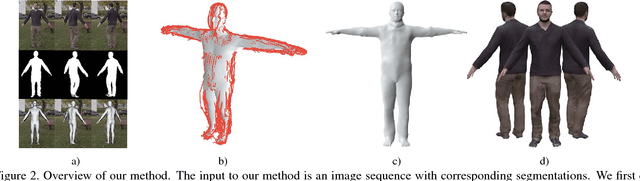

This paper describes how to obtain accurate 3D body models and texture of arbitrary people from a single, monocular video in which a person is moving. Based on a parametric body model, we present a robust processing pipeline achieving 3D model fits with 5mm accuracy also for clothed people. Our main contribution is a method to nonrigidly deform the silhouette cones corresponding to the dynamic human silhouettes, resulting in a visual hull in a common reference frame that enables surface reconstruction. This enables efficient estimation of a consensus 3D shape, texture and implanted animation skeleton based on a large number of frames. We present evaluation results for a number of test subjects and analyze overall performance. Requiring only a smartphone or webcam, our method enables everyone to create their own fully animatable digital double, e.g., for social VR applications or virtual try-on for online fashion shopping.
Optical Flow-based 3D Human Motion Estimation from Monocular Video
Mar 21, 2017


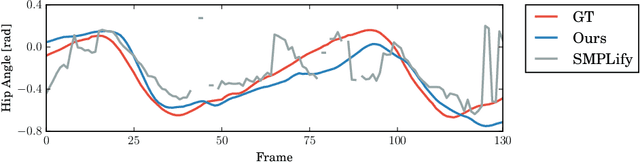
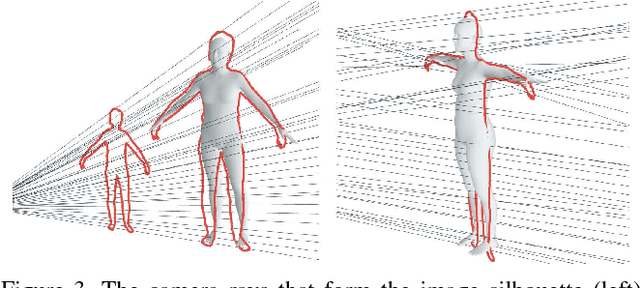
We present a generative method to estimate 3D human motion and body shape from monocular video. Under the assumption that starting from an initial pose optical flow constrains subsequent human motion, we exploit flow to find temporally coherent human poses of a motion sequence. We estimate human motion by minimizing the difference between computed flow fields and the output of an artificial flow renderer. A single initialization step is required to estimate motion over multiple frames. Several regularization functions enhance robustness over time. Our test scenarios demonstrate that optical flow effectively regularizes the under-constrained problem of human shape and motion estimation from monocular video.