 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSHANDS: A Multi-View Dataset and Benchmark for Surgical Hand-Gesture and Error Recognition Toward Medical Training
Mar 27, 2026In surgical training for medical students, proficiency development relies on expert-led skill assessment, which is costly, time-limited, difficult to scale, and its expertise remains confined to institutions with available specialists. Automated AI-based assessment offers a viable alternative, but progress is constrained by the lack of datasets containing realistic trainee errors and the multi-view variability needed to train robust computer vision approaches. To address this gap, we present Surgical-Hands (SHands), a large-scale multi-view video dataset for surgical hand-gesture and error recognition for medical training. \textsc{SHands} captures linear incision and suturing using five RGB cameras from complementary viewpoints, performed by 52 participants (20 experts and 32 trainees), each completing three standardized trials per procedure. The videos are annotated at the frame level with 15 gesture primitives and include a validated taxonomy of 8 trainee error types, enabling both gesture recognition and error detection. We further define standardized evaluation protocols for single-view, multi-view, and cross-view generalization, and benchmark state-of-the-art deep learning models on the dataset. SHands is publicly released to support the development of robust and scalable AI systems for surgical training grounded in clinically curated domain knowledge.
Can Interpretability Layouts Influence Human Perception of Offensive Sentences?
Mar 01, 2024This paper conducts a user study to assess whether three machine learning (ML) interpretability layouts can influence participants' views when evaluating sentences containing hate speech, focusing on the "Misogyny" and "Racism" classes. Given the existence of divergent conclusions in the literature, we provide empirical evidence on using ML interpretability in online communities through statistical and qualitative analyses of questionnaire responses. The Generalized Additive Model estimates participants' ratings, incorporating within-subject and between-subject designs. While our statistical analysis indicates that none of the interpretability layouts significantly influences participants' views, our qualitative analysis demonstrates the advantages of ML interpretability: 1) triggering participants to provide corrective feedback in case of discrepancies between their views and the model, and 2) providing insights to evaluate a model's behavior beyond traditional performance metrics.
Learning for Detecting Norm Violation in Online Communities
Apr 30, 2021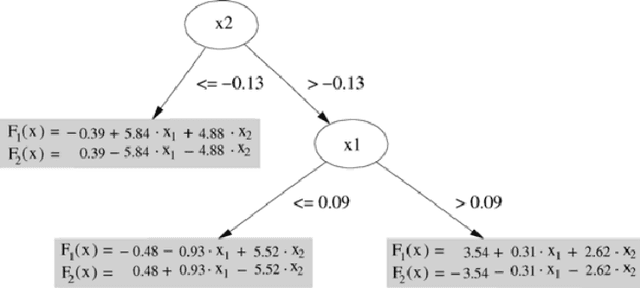

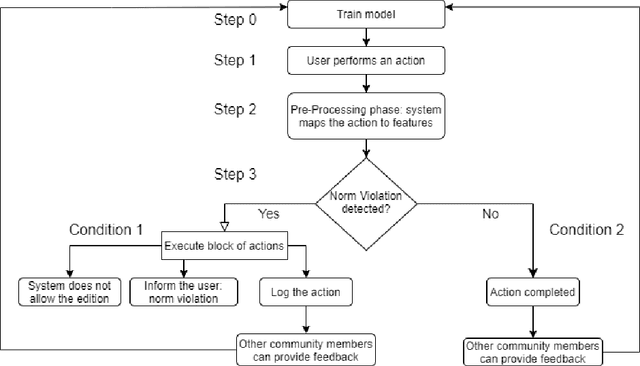
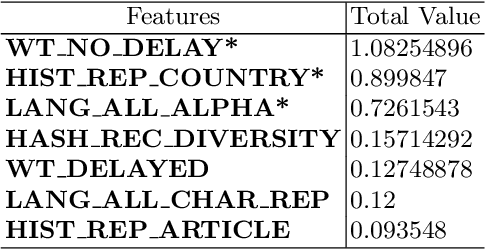
In this paper, we focus on normative systems for online communities. The paper addresses the issue that arises when different community members interpret these norms in different ways, possibly leading to unexpected behavior in interactions, usually with norm violations that affect the individual and community experiences. To address this issue, we propose a framework capable of detecting norm violations and providing the violator with information about the features of their action that makes this action violate a norm. We build our framework using Machine Learning, with Logistic Model Trees as the classification algorithm. Since norm violations can be highly contextual, we train our model using data from the Wikipedia online community, namely data on Wikipedia edits. Our work is then evaluated with the Wikipedia use case where we focus on the norm that prohibits vandalism in Wikipedia edits.
Heuristics, Answer Set Programming and Markov Decision Process for Solving a Set of Spatial Puzzles
Feb 16, 2019
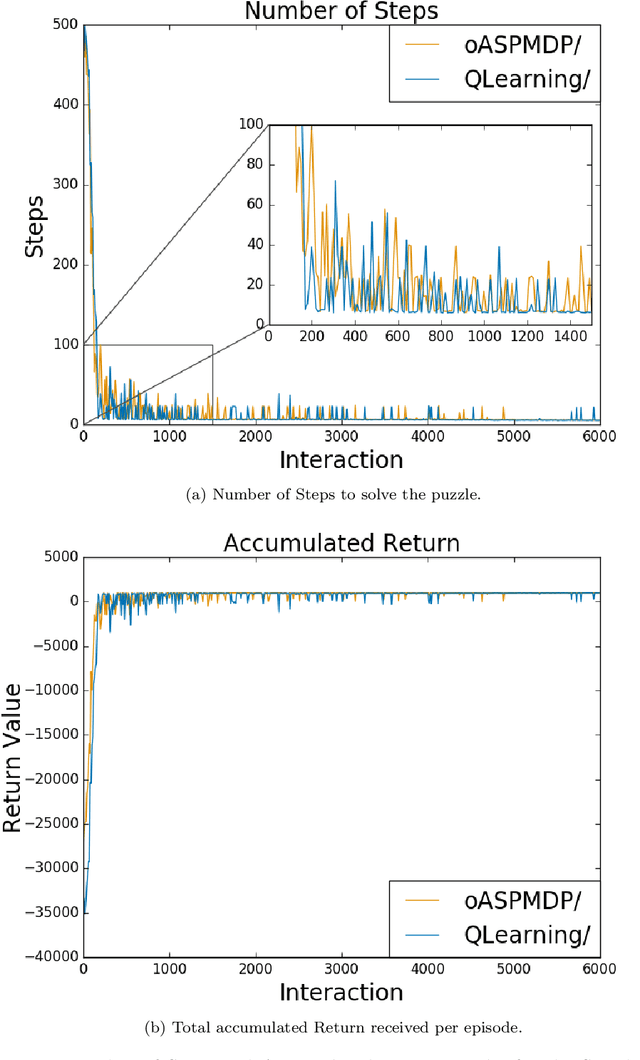
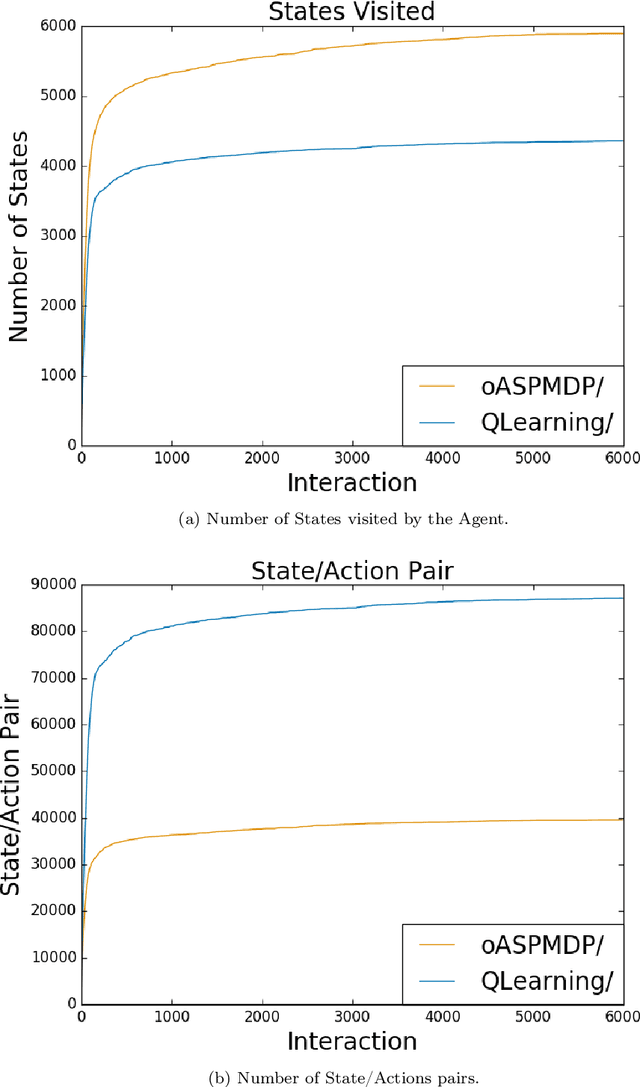
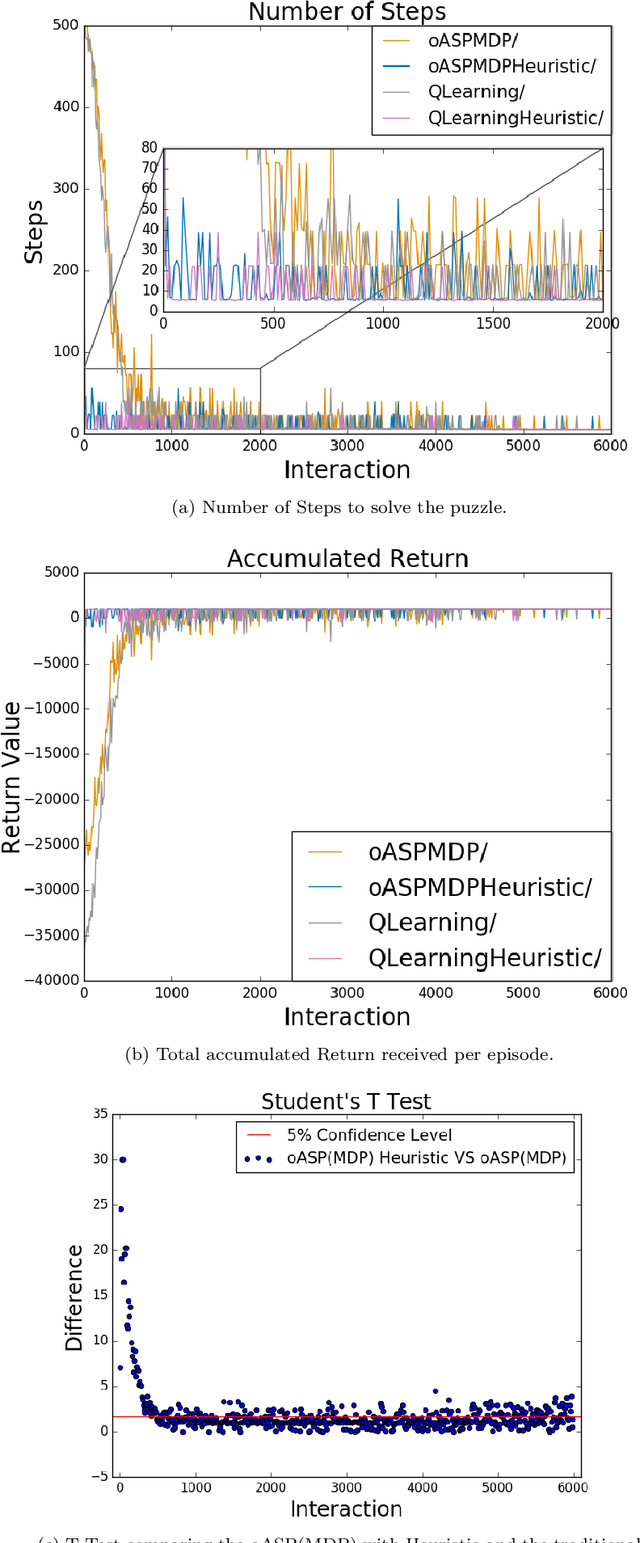
Spatial puzzles composed of rigid objects, flexible strings and holes offer interesting domains for reasoning about spatial entities that are common in the human daily-life's activities. The goal of this work is to investigate the automated solution of this kind of puzzles adapting an algorithm that combines Answer Set Programming (ASP) with Markov Decision Process (MDP), algorithm oASP(MDP), to use heuristics accelerating the learning process. ASP is applied to represent the domain as an MDP, while a Reinforcement Learning algorithm (Q-Learning) is used to find the optimal policies. In this work, the heuristics were obtained from the solution of relaxed versions of the puzzles. Experiments were performed on deterministic, non-deterministic and non-stationary versions of the puzzles. Results show that the proposed approach can accelerate the learning process, presenting an advantage when compared to the non-heuristic versions of oASP(MDP) and Q-Learning.