 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHigher Order Kernel Mean Embeddings to Capture Filtrations of Stochastic Processes
Sep 29, 2021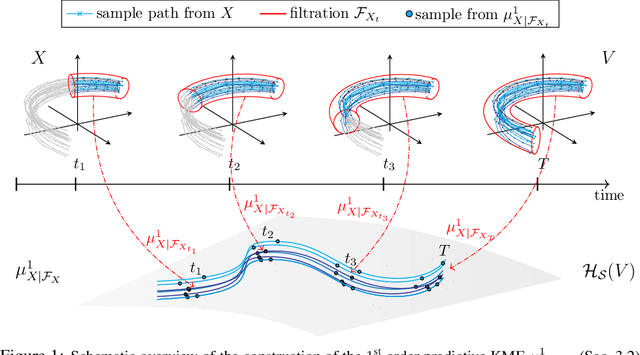


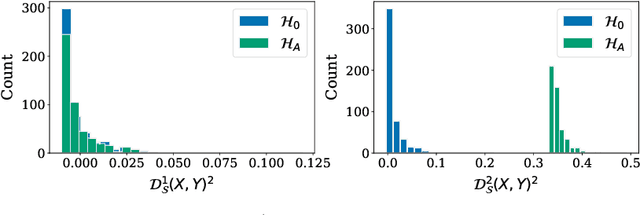
Stochastic processes are random variables with values in some space of paths. However, reducing a stochastic process to a path-valued random variable ignores its filtration, i.e. the flow of information carried by the process through time. By conditioning the process on its filtration, we introduce a family of higher order kernel mean embeddings (KMEs) that generalizes the notion of KME and captures additional information related to the filtration. We derive empirical estimators for the associated higher order maximum mean discrepancies (MMDs) and prove consistency. We then construct a filtration-sensitive kernel two-sample test able to pick up information that gets missed by the standard MMD test. In addition, leveraging our higher order MMDs we construct a family of universal kernels on stochastic processes that allows to solve real-world calibration and optimal stopping problems in quantitative finance (such as the pricing of American options) via classical kernel-based regression methods. Finally, adapting existing tests for conditional independence to the case of stochastic processes, we design a causal-discovery algorithm to recover the causal graph of structural dependencies among interacting bodies solely from observations of their multidimensional trajectories.
A variational Bayesian spatial interaction model for estimating revenue and demand at business facilities
Aug 05, 2021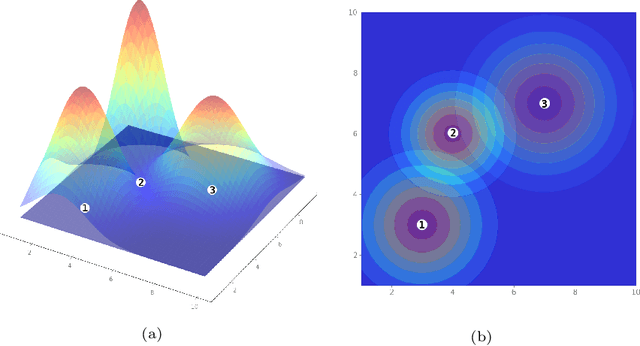
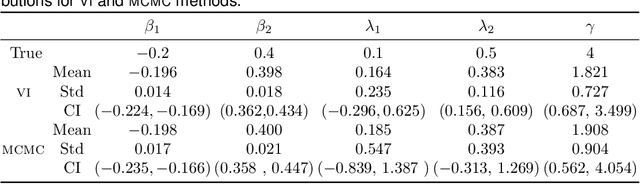
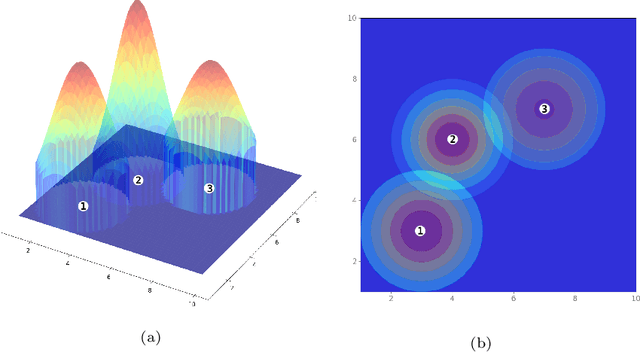
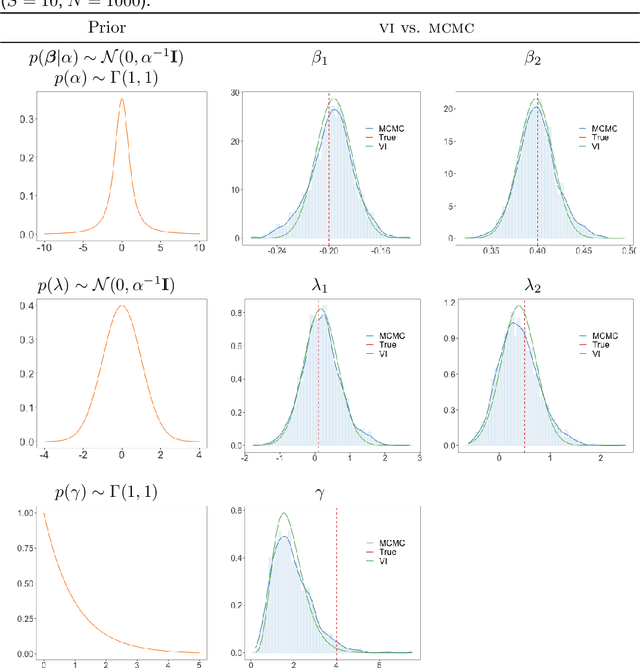
We study the problem of estimating potential revenue or demand at business facilities and understanding its generating mechanism. This problem arises in different fields such as operation research or urban science, and more generally, it is crucial for businesses' planning and decision making. We develop a Bayesian spatial interaction model, henceforth BSIM, which provides probabilistic predictions about revenues generated by a particular business location provided their features and the potential customers' characteristics in a given region. BSIM explicitly accounts for the competition among the competitive facilities through a probability value determined by evaluating a store-specific Gaussian distribution at a given customer location. We propose a scalable variational inference framework that, while being significantly faster than competing Markov Chain Monte Carlo inference schemes, exhibits comparable performances in terms of parameters identification and uncertainty quantification. We demonstrate the benefits of BSIM in various synthetic settings characterised by an increasing number of stores and customers. Finally, we construct a real-world, large spatial dataset for pub activities in London, UK, which includes over 1,500 pubs and 150,000 customer regions. We demonstrate how BSIM outperforms competing approaches on this large dataset in terms of prediction performances while providing results that are both interpretable and consistent with related indicators observed for the London region.
SigGPDE: Scaling Sparse Gaussian Processes on Sequential Data
May 10, 2021

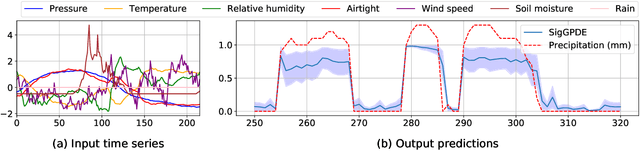
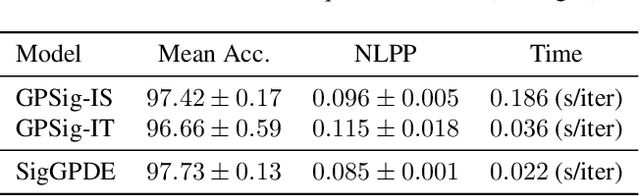
Making predictions and quantifying their uncertainty when the input data is sequential is a fundamental learning challenge, recently attracting increasing attention. We develop SigGPDE, a new scalable sparse variational inference framework for Gaussian Processes (GPs) on sequential data. Our contribution is twofold. First, we construct inducing variables underpinning the sparse approximation so that the resulting evidence lower bound (ELBO) does not require any matrix inversion. Second, we show that the gradients of the GP signature kernel are solutions of a hyperbolic partial differential equation (PDE). This theoretical insight allows us to build an efficient back-propagation algorithm to optimize the ELBO. We showcase the significant computational gains of SigGPDE compared to existing methods, while achieving state-of-the-art performance for classification tasks on large datasets of up to 1 million multivariate time series.
An Expectation-Based Network Scan Statistic for a COVID-19 Early Warning System
Dec 08, 2020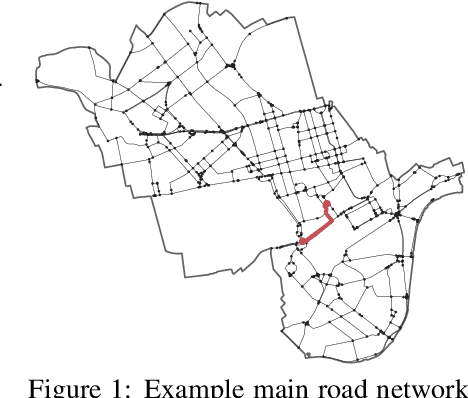
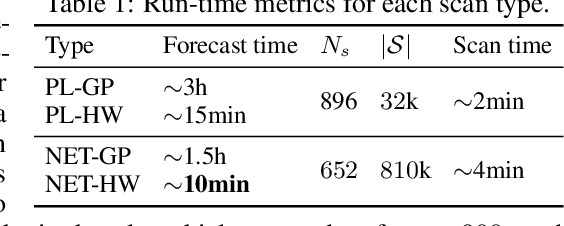
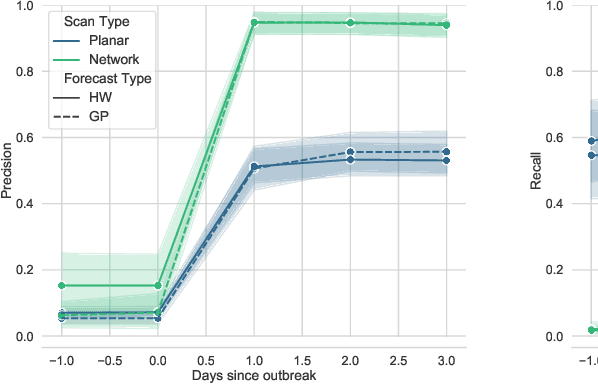
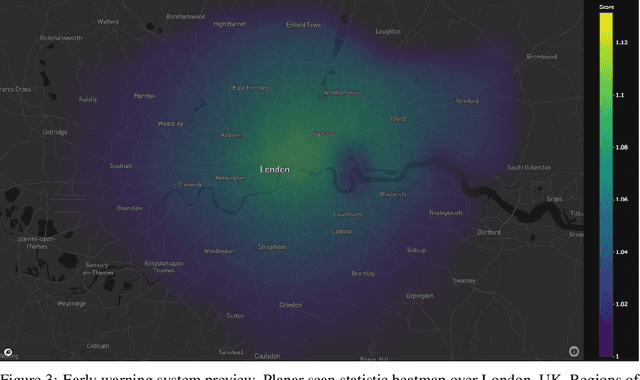
One of the Greater London Authority's (GLA) response to the COVID-19 pandemic brings together multiple large-scale and heterogeneous datasets capturing mobility, transportation and traffic activity over the city of London to better understand 'busyness' and enable targeted interventions and effective policy-making. As part of Project Odysseus we describe an early-warning system and introduce an expectation-based scan statistic for networks to help the GLA and Transport for London, understand the extent to which populations are following government COVID-19 guidelines. We explicitly treat the case of geographically fixed time-series data located on a (road) network and primarily focus on monitoring the dynamics across large regions of the capital. Additionally, we also focus on the detection and reporting of significant spatio-temporal regions. Our approach is extending the Network Based Scan Statistic (NBSS) by making it expectation-based (EBP) and by using stochastic processes for time-series forecasting, which enables us to quantify metric uncertainty in both the EBP and NBSS frameworks. We introduce a variant of the metric used in the EBP model which focuses on identifying space-time regions in which activity is quieter than expected.
Near Real-Time Social Distancing in London
Dec 07, 2020
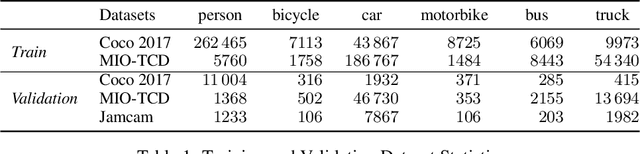
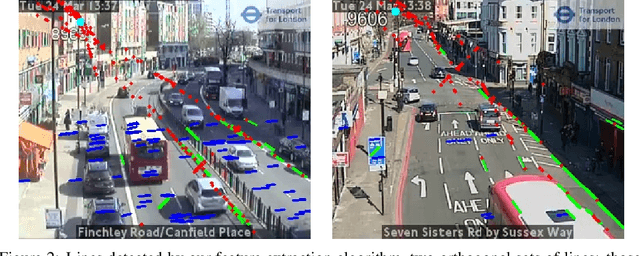
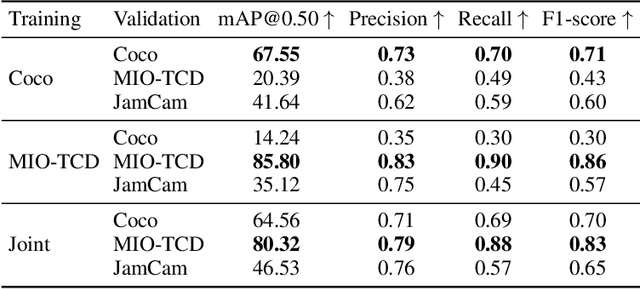
During the COVID-19 pandemic, policy makers at the Greater London Authority, the regional governance body of London, UK, are reliant upon prompt and accurate data sources. Large well-defined heterogeneous compositions of activity throughout the city are sometimes difficult to acquire, yet are a necessity in order to learn 'busyness' and consequently make safe policy decisions. One component of our project within this space is to utilise existing infrastructure to estimate social distancing adherence by the general public. Our method enables near immediate sampling and contextualisation of activity and physical distancing on the streets of London via live traffic camera feeds. We introduce a framework for inspecting and improving upon existing methods, whilst also describing its active deployment on over 900 real-time feeds.
Transforming Gaussian Processes With Normalizing Flows
Nov 03, 2020

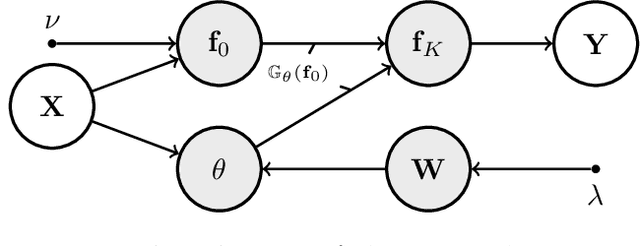
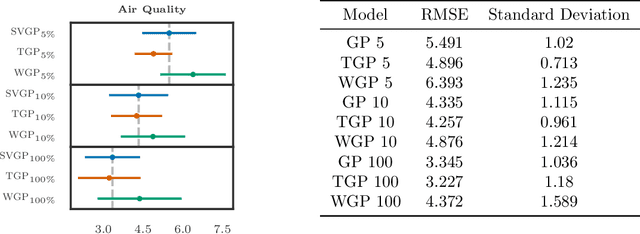
Gaussian Processes (GPs) can be used as flexible, non-parametric function priors. Inspired by the growing body of work on Normalizing Flows, we enlarge this class of priors through a parametric invertible transformation that can be made input-dependent. Doing so also allows us to encode interpretable prior knowledge (e.g., boundedness constraints). We derive a variational approximation to the resulting Bayesian inference problem, which is as fast as stochastic variational GP regression (Hensman et al., 2013; Dezfouli and Bonilla,2015). This makes the model a computationally efficient alternative to other hierarchical extensions of GP priors (Lazaro-Gredilla,2012; Damianou and Lawrence, 2013). The resulting algorithm's computational and inferential performance is excellent, and we demonstrate this on a range of data sets. For example, even with only 5 inducing points and an input-dependent flow, our method is consistently competitive with a standard sparse GP fitted using 100 inducing points.
Multi-task Causal Learning with Gaussian Processes
Sep 27, 2020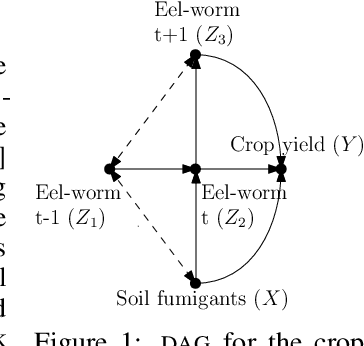
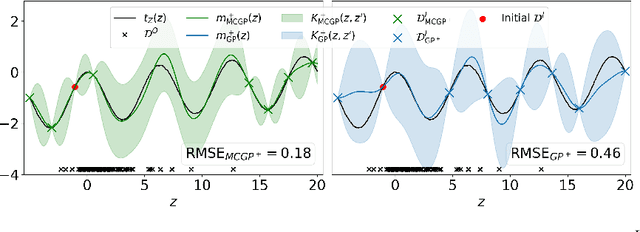
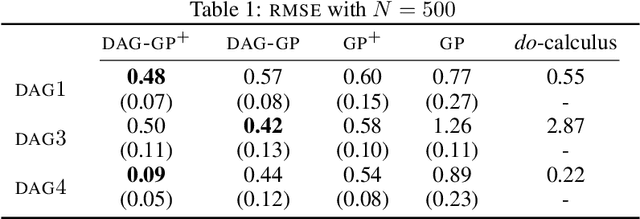
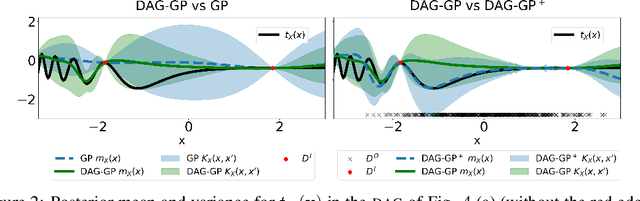
This paper studies the problem of learning the correlation structure of a set of intervention functions defined on the directed acyclic graph (DAG) of a causal model. This is useful when we are interested in jointly learning the causal effects of interventions on different subsets of variables in a DAG, which is common in field such as healthcare or operations research. We propose the first multi-task causal Gaussian process (GP) model, which we call DAG-GP, that allows for information sharing across continuous interventions and across experiments on different variables. DAG-GP accommodates different assumptions in terms of data availability and captures the correlation between functions lying in input spaces of different dimensionality via a well-defined integral operator. We give theoretical results detailing when and how the DAG-GP model can be formulated depending on the DAG. We test both the quality of its predictions and its calibrated uncertainties. Compared to single-task models, DAG-GP achieves the best fitting performance in a variety of real and synthetic settings. In addition, it helps to select optimal interventions faster than competing approaches when used within sequential decision making frameworks, like active learning or Bayesian optimization.
Exoplanet Validation with Machine Learning: 50 new validated Kepler planets
Aug 24, 2020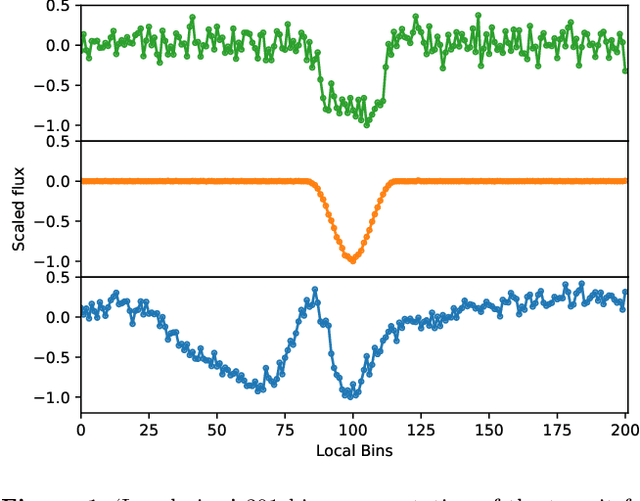
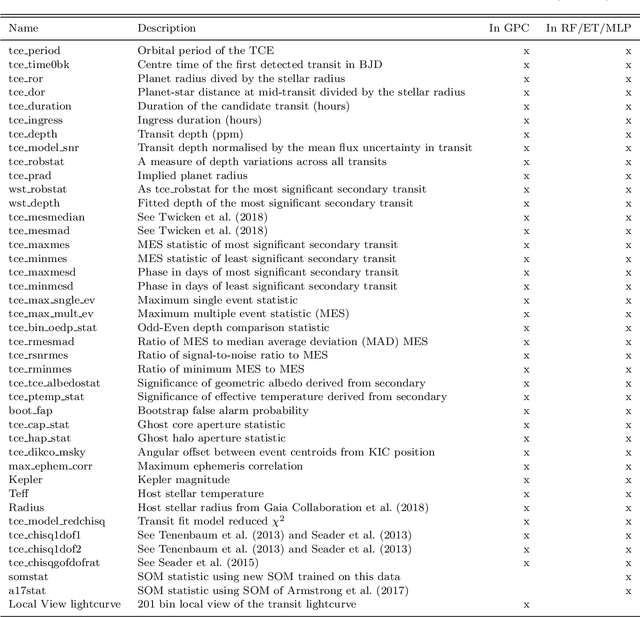

Over 30% of the ~4000 known exoplanets to date have been discovered using 'validation', where the statistical likelihood of a transit arising from a false positive (FP), non-planetary scenario is calculated. For the large majority of these validated planets calculations were performed using the vespa algorithm (Morton et al. 2016). Regardless of the strengths and weaknesses of vespa, it is highly desirable for the catalogue of known planets not to be dependent on a single method. We demonstrate the use of machine learning algorithms, specifically a gaussian process classifier (GPC) reinforced by other models, to perform probabilistic planet validation incorporating prior probabilities for possible FP scenarios. The GPC can attain a mean log-loss per sample of 0.54 when separating confirmed planets from FPs in the Kepler threshold crossing event (TCE) catalogue. Our models can validate thousands of unseen candidates in seconds once applicable vetting metrics are calculated, and can be adapted to work with the active TESS mission, where the large number of observed targets necessitates the use of automated algorithms. We discuss the limitations and caveats of this methodology, and after accounting for possible failure modes newly validate 50 Kepler candidates as planets, sanity checking the validations by confirming them with vespa using up to date stellar information. Concerning discrepancies with vespa arise for many other candidates, which typically resolve in favour of our models. Given such issues, we caution against using single-method planet validation with either method until the discrepancies are fully understood.
Variational Autoencoding of PDE Inverse Problems
Jun 28, 2020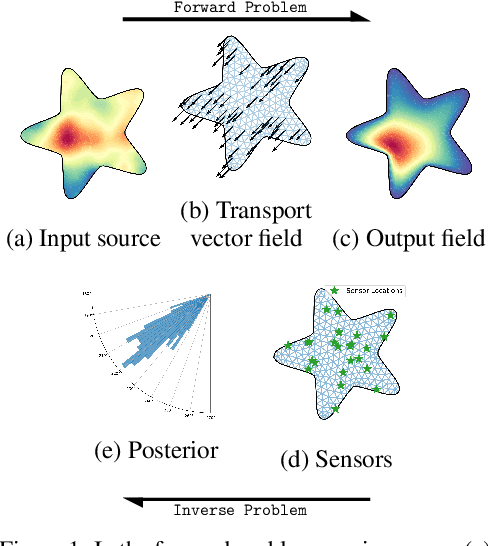

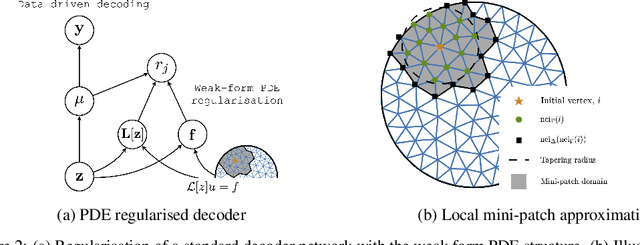

Specifying a governing physical model in the presence of missing physics and recovering its parameters are two intertwined and fundamental problems in science. Modern machine learning allows one to circumvent these, via emulators and surrogates, but in doing so disregards prior knowledge and physical laws that are especially important for small data regimes, interpretability, and decision making. In this work we fold the mechanistic model into a flexible data-driven surrogate to arrive at a physically structured decoder network. This provides accelerated inference for the Bayesian inverse problem, and can act as a drop-in regulariser that encodes a-priori physical information. We employ the variational form of the PDE problem and introduce stochastic local approximations as a form of model based data augmentation. We demonstrate both the accuracy and increased computational efficiency of the framework on real world settings and structured spatial processes.
Distribution Regression for Continuous-Time Processes via the Expected Signature
Jun 22, 2020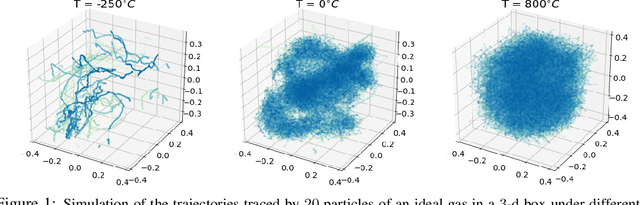

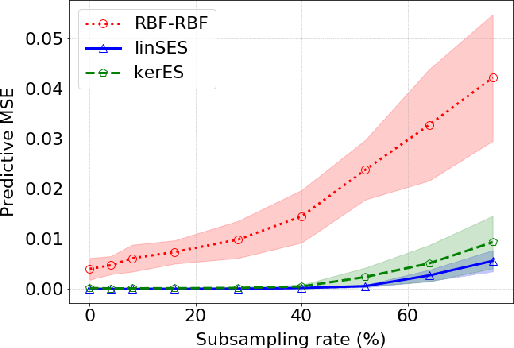

We introduce a learning framework to infer macroscopic properties of an evolving system from longitudinal trajectories of its components. By considering probability measures on continuous paths we view this problem as a distribution regression task for continuous-time processes and propose two distinct solutions leveraging the recently established properties of the expected signature. Firstly, we embed the measures in a Hilbert space, enabling the application of an existing kernel-based technique. Secondly, we recast the complex task of learning a non-linear regression function on probability measures to a simpler functional linear regression on the signature of a single vector-valued path. We provide theoretical results on the universality of both approaches, and demonstrate empirically their robustness to densely and irregularly sampled multivariate time-series, outperforming existing methods adapted to this task on both synthetic and real-world examples from thermodynamics, mathematical finance and agricultural science.