 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData Selection for Language Models via Importance Resampling
Feb 06, 2023



Selecting a suitable training dataset is crucial for both general-domain (e.g., GPT-3) and domain-specific (e.g., Codex) language models (LMs). We formalize this data selection problem as selecting a subset of a large raw unlabeled dataset to match a desired target distribution, given some unlabeled target samples. Due to the large scale and dimensionality of the raw text data, existing methods use simple heuristics to select data that are similar to a high-quality reference corpus (e.g., Wikipedia), or leverage experts to manually curate data. Instead, we extend the classic importance resampling approach used in low-dimensions for LM data selection. Crucially, we work in a reduced feature space to make importance weight estimation tractable over the space of text. To determine an appropriate feature space, we first show that KL reduction, a data metric that measures the proximity between selected data and the target in a feature space, has high correlation with average accuracy on 8 downstream tasks (r=0.89) when computed with simple n-gram features. From this observation, we present Data Selection with Importance Resampling (DSIR), an efficient and scalable algorithm that estimates importance weights in a reduced feature space (e.g., n-gram features in our instantiation) and selects data with importance resampling according to these weights. When training general-domain models (target is Wikipedia + books), DSIR improves over random selection and heuristic filtering baselines by 2--2.5% on the GLUE benchmark. When performing continued pretraining towards a specific domain, DSIR performs comparably to expert curated data across 8 target distributions.
First Steps Toward Understanding the Extrapolation of Nonlinear Models to Unseen Domains
Dec 01, 2022



Real-world machine learning applications often involve deploying neural networks to domains that are not seen in the training time. Hence, we need to understand the extrapolation of nonlinear models -- under what conditions on the distributions and function class, models can be guaranteed to extrapolate to new test distributions. The question is very challenging because even two-layer neural networks cannot be guaranteed to extrapolate outside the support of the training distribution without further assumptions on the domain shift. This paper makes some initial steps toward analyzing the extrapolation of nonlinear models for structured domain shift. We primarily consider settings where the marginal distribution of each coordinate of the data (or subset of coordinates) does not shift significantly across the training and test distributions, but the joint distribution may have a much bigger shift. We prove that the family of nonlinear models of the form $f(x)=\sum f_i(x_i)$, where $f_i$ is an arbitrary function on the subset of features $x_i$, can extrapolate to unseen distributions, if the covariance of the features is well-conditioned. To the best of our knowledge, this is the first result that goes beyond linear models and the bounded density ratio assumption, even though the assumptions on the distribution shift and function class are stylized.
What learning algorithm is in-context learning? Investigations with linear models
Nov 29, 2022



Neural sequence models, especially transformers, exhibit a remarkable capacity for in-context learning. They can construct new predictors from sequences of labeled examples $(x, f(x))$ presented in the input without further parameter updates. We investigate the hypothesis that transformer-based in-context learners implement standard learning algorithms implicitly, by encoding smaller models in their activations, and updating these implicit models as new examples appear in the context. Using linear regression as a prototypical problem, we offer three sources of evidence for this hypothesis. First, we prove by construction that transformers can implement learning algorithms for linear models based on gradient descent and closed-form ridge regression. Second, we show that trained in-context learners closely match the predictors computed by gradient descent, ridge regression, and exact least-squares regression, transitioning between different predictors as transformer depth and dataset noise vary, and converging to Bayesian estimators for large widths and depths. Third, we present preliminary evidence that in-context learners share algorithmic features with these predictors: learners' late layers non-linearly encode weight vectors and moment matrices. These results suggest that in-context learning is understandable in algorithmic terms, and that (at least in the linear case) learners may rediscover standard estimation algorithms. Code and reference implementations are released at https://github.com/ekinakyurek/google-research/blob/master/incontext.
A Theoretical Study of Inductive Biases in Contrastive Learning
Nov 27, 2022



Understanding self-supervised learning is important but challenging. Previous theoretical works study the role of pretraining losses, and view neural networks as general black boxes. However, the recent work of Saunshi et al. argues that the model architecture -- a component largely ignored by previous works -- also has significant influences on the downstream performance of self-supervised learning. In this work, we provide the first theoretical analysis of self-supervised learning that incorporates the effect of inductive biases originating from the model class. In particular, we focus on contrastive learning -- a popular self-supervised learning method that is widely used in the vision domain. We show that when the model has limited capacity, contrastive representations would recover certain special clustering structures that are compatible with the model architecture, but ignore many other clustering structures in the data distribution. As a result, our theory can capture the more realistic setting where contrastive representations have much lower dimensionality than the number of clusters in the data distribution. We instantiate our theory on several synthetic data distributions, and provide empirical evidence to support the theory.
How Does Sharpness-Aware Minimization Minimize Sharpness?
Nov 10, 2022

Sharpness-Aware Minimization (SAM) is a highly effective regularization technique for improving the generalization of deep neural networks for various settings. However, the underlying working of SAM remains elusive because of various intriguing approximations in the theoretical characterizations. SAM intends to penalize a notion of sharpness of the model but implements a computationally efficient variant; moreover, a third notion of sharpness was used for proving generalization guarantees. The subtle differences in these notions of sharpness can indeed lead to significantly different empirical results. This paper rigorously nails down the exact sharpness notion that SAM regularizes and clarifies the underlying mechanism. We also show that the two steps of approximations in the original motivation of SAM individually lead to inaccurate local conclusions, but their combination accidentally reveals the correct effect, when full-batch gradients are applied. Furthermore, we also prove that the stochastic version of SAM in fact regularizes the third notion of sharpness mentioned above, which is most likely to be the preferred notion for practical performance. The key mechanism behind this intriguing phenomenon is the alignment between the gradient and the top eigenvector of Hessian when SAM is applied.
Same Pre-training Loss, Better Downstream: Implicit Bias Matters for Language Models
Oct 25, 2022



Language modeling on large-scale datasets leads to impressive performance gains on various downstream language tasks. The validation pre-training loss (or perplexity in autoregressive language modeling) is often used as the evaluation metric when developing language models since the pre-training loss tends to be well-correlated with downstream performance (which is itself difficult to evaluate comprehensively). Contrary to this conventional wisdom, this paper shows that 1) pre-training loss cannot fully explain downstream performance and 2) flatness of the model is well-correlated with downstream performance where pre-training loss is not. On simplified datasets, we identify three ways to produce models with the same (statistically optimal) pre-training loss but different downstream performance: continue pre-training after convergence, increasing the model size, and changing the training algorithm. These experiments demonstrate the existence of implicit bias of pre-training algorithms/optimizers -- among models with the same minimal pre-training loss, they implicitly prefer more transferable ones. Toward understanding this implicit bias, we prove that SGD with standard mini-batch noise implicitly prefers flatter minima in language models, and empirically observe a strong correlation between flatness and downstream performance among models with the same minimal pre-training loss. We also prove in a synthetic language setting that among the models with the minimal pre-training loss, the flattest model transfers to downstream tasks.
Calibrated ensembles can mitigate accuracy tradeoffs under distribution shift
Jul 18, 2022
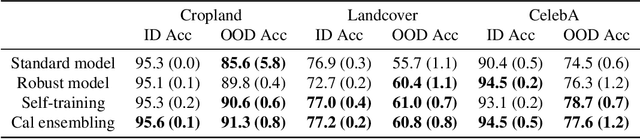
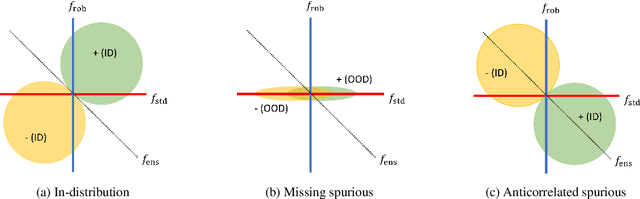
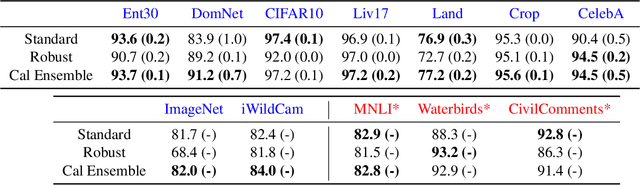
We often see undesirable tradeoffs in robust machine learning where out-of-distribution (OOD) accuracy is at odds with in-distribution (ID) accuracy: a robust classifier obtained via specialized techniques such as removing spurious features often has better OOD but worse ID accuracy compared to a standard classifier trained via ERM. In this paper, we find that ID-calibrated ensembles -- where we simply ensemble the standard and robust models after calibrating on only ID data -- outperforms prior state-of-the-art (based on self-training) on both ID and OOD accuracy. On eleven natural distribution shift datasets, ID-calibrated ensembles obtain the best of both worlds: strong ID accuracy and OOD accuracy. We analyze this method in stylized settings, and identify two important conditions for ensembles to perform well both ID and OOD: (1) we need to calibrate the standard and robust models (on ID data, because OOD data is unavailable), (2) OOD has no anticorrelated spurious features.
Max-Margin Works while Large Margin Fails: Generalization without Uniform Convergence
Jun 16, 2022
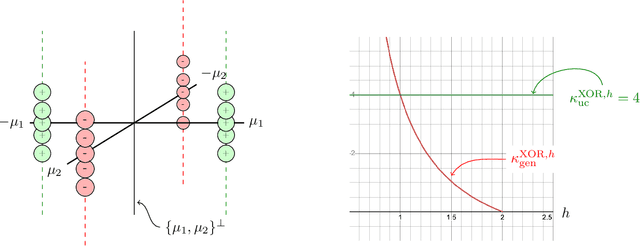
A major challenge in modern machine learning is theoretically understanding the generalization properties of overparameterized models. Many existing tools rely on \em uniform convergence \em (UC), a property that, when it holds, guarantees that the test loss will be close to the training loss, uniformly over a class of candidate models. Nagarajan and Kolter (2019) show that in certain simple linear and neural-network settings, any uniform convergence bound will be vacuous, leaving open the question of how to prove generalization in settings where UC fails. Our main contribution is proving novel generalization bounds in two such settings, one linear, and one non-linear. We study the linear classification setting of Nagarajan and Kolter, and a quadratic ground truth function learned via a two-layer neural network in the non-linear regime. We prove a new type of margin bound showing that above a certain signal-to-noise threshold, any near-max-margin classifier will achieve almost no test loss in these two settings. Our results show that near-max-margin is important: while any model that achieves at least a $(1 - \epsilon)$-fraction of the max-margin generalizes well, a classifier achieving half of the max-margin may fail terribly. We additionally strengthen the UC impossibility results of Nagarajan and Kolter, proving that \em one-sided \em UC bounds and classical margin bounds will fail on near-max-margin classifiers. Our analysis provides insight on why memorization can coexist with generalization: we show that in this challenging regime where generalization occurs but UC fails, near-max-margin classifiers simultaneously contain some generalizable components and some overfitting components that memorize the data. The presence of the overfitting components is enough to preclude UC, but the near-extremal margin guarantees that sufficient generalizable components are present.
Asymptotic Instance-Optimal Algorithms for Interactive Decision Making
Jun 06, 2022Past research on interactive decision making problems (bandits, reinforcement learning, etc.) mostly focuses on the minimax regret that measures the algorithm's performance on the hardest instance. However, an ideal algorithm should adapt to the complexity of a particular problem instance and incur smaller regrets on easy instances than worst-case instances. In this paper, we design the first asymptotic instance-optimal algorithm for general interactive decision making problems with finite number of decisions under mild conditions. On \textit{every} instance $f$, our algorithm outperforms \emph{all} consistent algorithms (those achieving non-trivial regrets on all instances), and has asymptotic regret $\mathcal{C}(f) \ln n$, where $\mathcal{C}(f)$ is an exact characterization of the complexity of $f$. The key step of the algorithm involves hypothesis testing with active data collection. It computes the most economical decisions with which the algorithm collects observations to test whether an estimated instance is indeed correct; thus, the complexity $\mathcal{C}(f)$ is the minimum cost to test the instance $f$ against other instances. Our results, instantiated on concrete problems, recover the classical gap-dependent bounds for multi-armed bandits [Lai and Robbins, 1985] and prior works on linear bandits [Lattimore and Szepesvari, 2017], and improve upon the previous best instance-dependent upper bound [Xu et al., 2021] for reinforcement learning.
Near-Optimal Algorithms for Autonomous Exploration and Multi-Goal Stochastic Shortest Path
May 22, 2022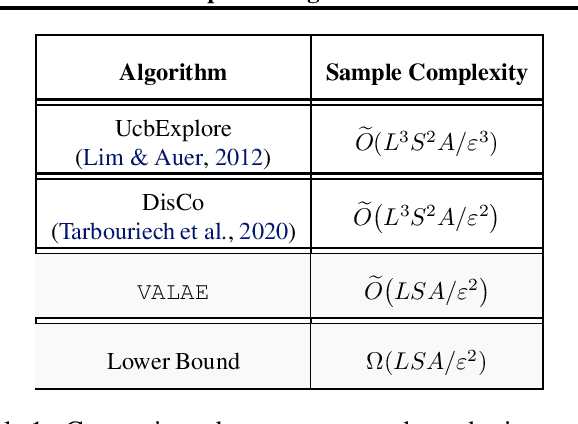

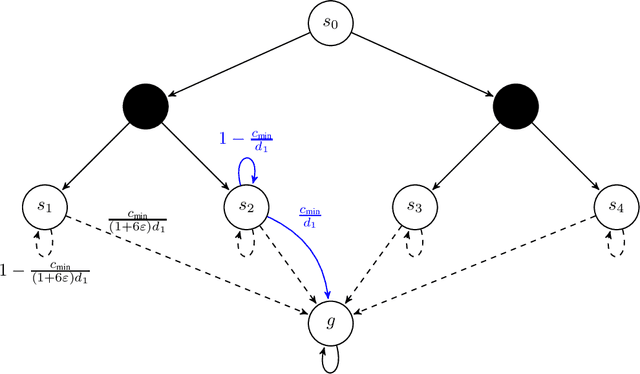
We revisit the incremental autonomous exploration problem proposed by Lim & Auer (2012). In this setting, the agent aims to learn a set of near-optimal goal-conditioned policies to reach the $L$-controllable states: states that are incrementally reachable from an initial state $s_0$ within $L$ steps in expectation. We introduce a new algorithm with stronger sample complexity bounds than existing ones. Furthermore, we also prove the first lower bound for the autonomous exploration problem. In particular, the lower bound implies that our proposed algorithm, Value-Aware Autonomous Exploration, is nearly minimax-optimal when the number of $L$-controllable states grows polynomially with respect to $L$. Key in our algorithm design is a connection between autonomous exploration and multi-goal stochastic shortest path, a new problem that naturally generalizes the classical stochastic shortest path problem. This new problem and its connection to autonomous exploration can be of independent interest.