 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCultural Evaluations of Vision-Language Models Have a Lot to Learn from Cultural Theory
May 28, 2025Modern vision-language models (VLMs) often fail at cultural competency evaluations and benchmarks. Given the diversity of applications built upon VLMs, there is renewed interest in understanding how they encode cultural nuances. While individual aspects of this problem have been studied, we still lack a comprehensive framework for systematically identifying and annotating the nuanced cultural dimensions present in images for VLMs. This position paper argues that foundational methodologies from visual culture studies (cultural studies, semiotics, and visual studies) are necessary for cultural analysis of images. Building upon this review, we propose a set of five frameworks, corresponding to cultural dimensions, that must be considered for a more complete analysis of the cultural competencies of VLMs.
Explainable Search and Discovery of Visual Cultural Heritage Collections with Multimodal Large Language Models
Nov 07, 2024



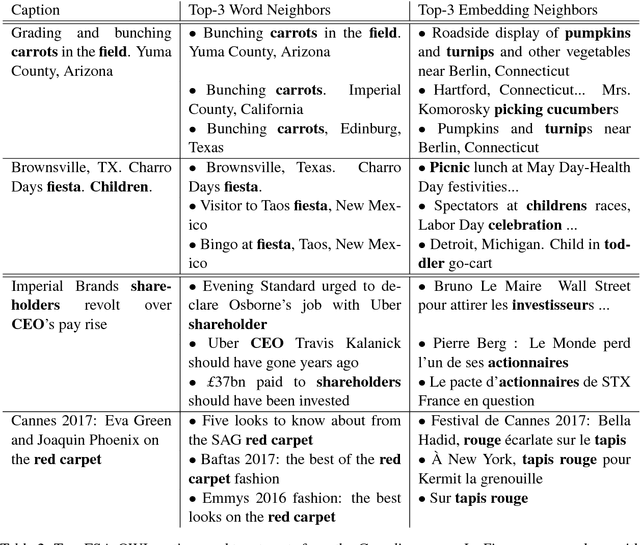
Many cultural institutions have made large digitized visual collections available online, often under permissible re-use licences. Creating interfaces for exploring and searching these collections is difficult, particularly in the absence of granular metadata. In this paper, we introduce a method for using state-of-the-art multimodal large language models (LLMs) to enable an open-ended, explainable search and discovery interface for visual collections. We show how our approach can create novel clustering and recommendation systems that avoid common pitfalls of methods based directly on visual embeddings. Of particular interest is the ability to offer concrete textual explanations of each recommendation without the need to preselect the features of interest. Together, these features can create a digital interface that is more open-ended and flexible while also being better suited to addressing privacy and ethical concerns. Through a case study using a collection of documentary photographs, we provide several metrics showing the efficacy and possibilities of our approach.
Automated Image Color Mapping for a Historic Photographic Collection
Nov 07, 2024



In the 1970s, the United States Environmental Protection Agency sponsored Documerica, a large-scale photography initiative to document environmental subjects nation-wide. While over 15,000 digitized public-domain photographs from the collection are available online, most of the images were scanned from damaged copies of the original prints. We present and evaluate a modified histogram matching technique based on the underlying chemistry of the prints for correcting the damaged images by using training data collected from a small set of undamaged prints. The entire set of color-adjusted Documerica images is made available in an open repository.
Cross-Discourse and Multilingual Exploration of Textual Corpora with the DualNeighbors Algorithm
Jun 28, 2018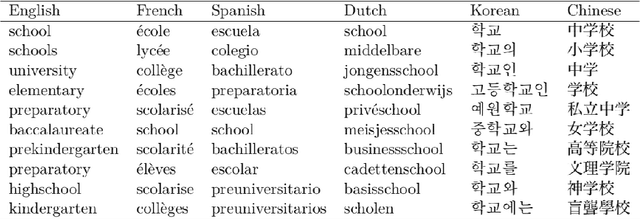

Word choice is dependent on the cultural context of writers and their subjects. Different words are used to describe similar actions, objects, and features based on factors such as class, race, gender, geography and political affinity. Exploratory techniques based on locating and counting words may, therefore, lead to conclusions that reinforce culturally inflected boundaries. We offer a new method, the DualNeighbors algorithm, for linking thematically similar documents both within and across discursive and linguistic barriers to reveal cross-cultural connections. Qualitative and quantitative evaluations of this technique are shown as applied to two cultural datasets of interest to researchers across the humanities and social sciences. An open-source implementation of the DualNeighbors algorithm is provided to assist in its application.
Predicting CEFRL levels in learner English on the basis of metrics and full texts
Jun 28, 2018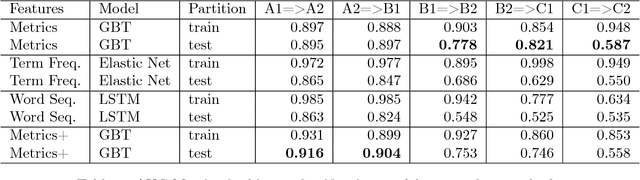
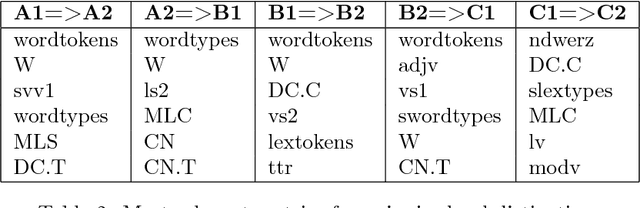
This paper analyses the contribution of language metrics and, potentially, of linguistic structures, to classify French learners of English according to levels of the Common European Framework of Reference for Languages (CEFRL). The purpose is to build a model for the prediction of learner levels as a function of language complexity features. We used the EFCAMDAT corpus, a database of one million written assignments by learners. After applying language complexity metrics on the texts, we built a representation matching the language metrics of the texts to their assigned CEFRL levels. Lexical and syntactic metrics were computed with LCA, LSA, and koRpus. Several supervised learning models were built by using Gradient Boosted Trees and Keras Neural Network methods and by contrasting pairs of CEFRL levels. Results show that it is possible to implement pairwise distinctions, especially for levels ranging from A1 to B1 (A1=>A2: 0.916 AUC and A2=>B1: 0.904 AUC). Model explanation reveals significant linguistic features for the predictiveness in the corpus. Word tokens and word types appear to play a significant role in determining levels. This shows that levels are highly dependent on specific semantic profiles.
A Tidy Data Model for Natural Language Processing using cleanNLP
May 03, 2018

The package cleanNLP provides a set of fast tools for converting a textual corpus into a set of normalized tables. The underlying natural language processing pipeline utilizes Stanford's CoreNLP library, exposing a number of annotation tasks for text written in English, French, German, and Spanish. Annotators include tokenization, part of speech tagging, named entity recognition, entity linking, sentiment analysis, dependency parsing, coreference resolution, and information extraction.
* 20 pages; 4 figures
Efficient Implementations of the Generalized Lasso Dual Path Algorithm
Nov 03, 2014We consider efficient implementations of the generalized lasso dual path algorithm of Tibshirani and Taylor (2011). We first describe a generic approach that covers any penalty matrix D and any (full column rank) matrix X of predictor variables. We then describe fast implementations for the special cases of trend filtering problems, fused lasso problems, and sparse fused lasso problems, both with X=I and a general matrix X. These specialized implementations offer a considerable improvement over the generic implementation, both in terms of numerical stability and efficiency of the solution path computation. These algorithms are all available for use in the genlasso R package, which can be found in the CRAN repository.