 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnd-to-End Learning Using Cycle Consistency for Image-to-Caption Transformations
Mar 25, 2019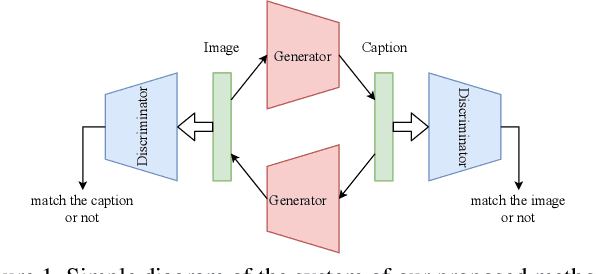
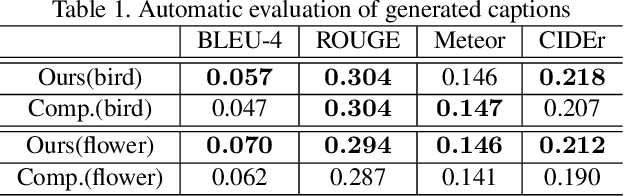
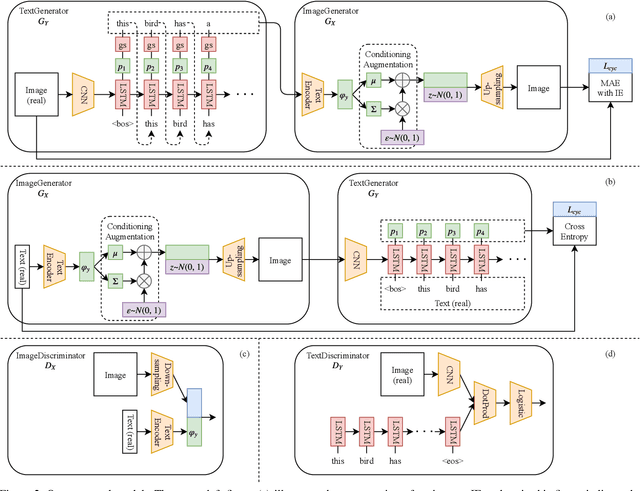
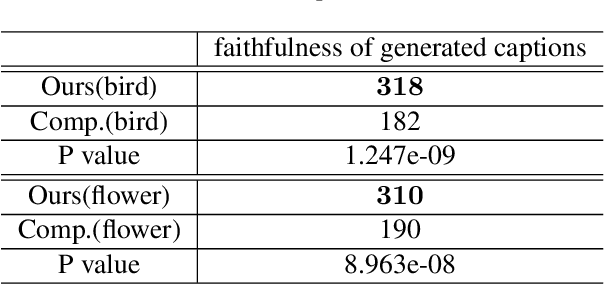
So far, research to generate captions from images has been carried out from the viewpoint that a caption holds sufficient information for an image. If it is possible to generate an image that is close to the input image from a generated caption, i.e., if it is possible to generate a natural language caption containing sufficient information to reproduce the image, then the caption is considered to be faithful to the image. To make such regeneration possible, learning using the cycle-consistency loss is effective. In this study, we propose a method of generating captions by learning end-to-end mutual transformations between images and texts. To evaluate our method, we perform comparative experiments with and without the cycle consistency. The results are evaluated by an automatic evaluation and crowdsourcing, demonstrating that our proposed method is effective.
Pose Graph Optimization for Unsupervised Monocular Visual Odometry
Mar 15, 2019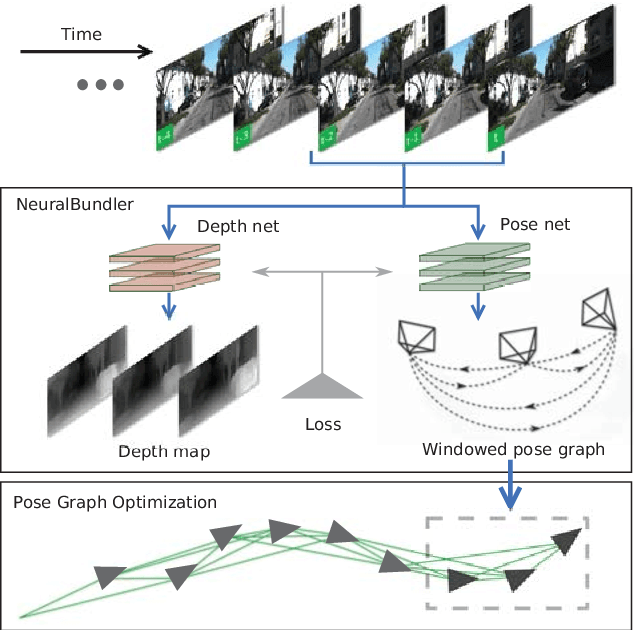
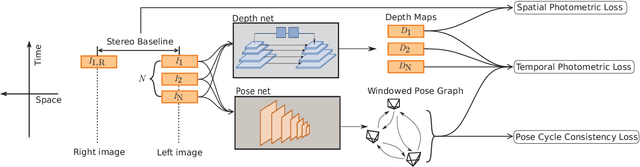
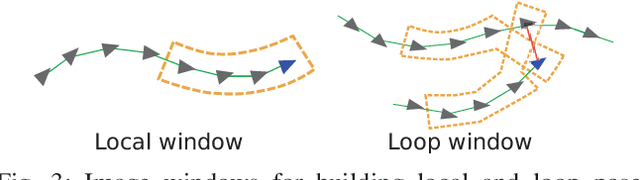
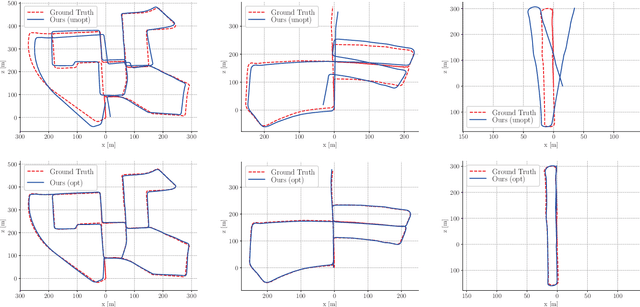
Unsupervised Learning based monocular visual odometry (VO) has lately drawn significant attention for its potential in label-free leaning ability and robustness to camera parameters and environmental variations. However, partially due to the lack of drift correction technique, these methods are still by far less accurate than geometric approaches for large-scale odometry estimation. In this paper, we propose to leverage graph optimization and loop closure detection to overcome limitations of unsupervised learning based monocular visual odometry. To this end, we propose a hybrid VO system which combines an unsupervised monocular VO called NeuralBundler with a pose graph optimization back-end. NeuralBundler is a neural network architecture that uses temporal and spatial photometric loss as main supervision and generates a windowed pose graph consists of multi-view 6DoF constraints. We propose a novel pose cycle consistency loss to relieve the tensions in the windowed pose graph, leading to improved performance and robustness. In the back-end, a global pose graph is built from local and loop 6DoF constraints estimated by NeuralBundler and is optimized over SE(3). Empirical evaluation on the KITTI odometry dataset demonstrates that 1) NeuralBundler achieves state-of-the-art performance on unsupervised monocular VO estimation, and 2) our whole approach can achieve efficient loop closing and show favorable overall translational accuracy compared to established monocular SLAM systems.
TWINs: Two Weighted Inconsistency-reduced Networks for Partial Domain Adaptation
Dec 18, 2018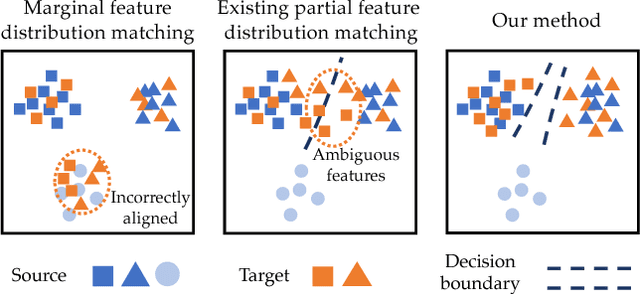
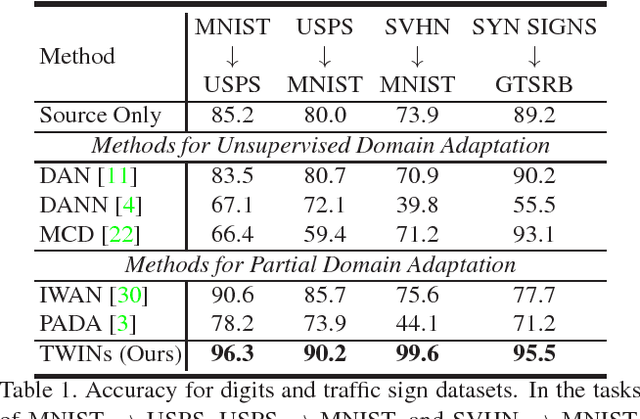
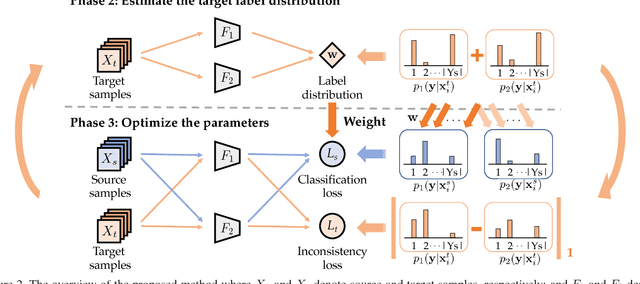
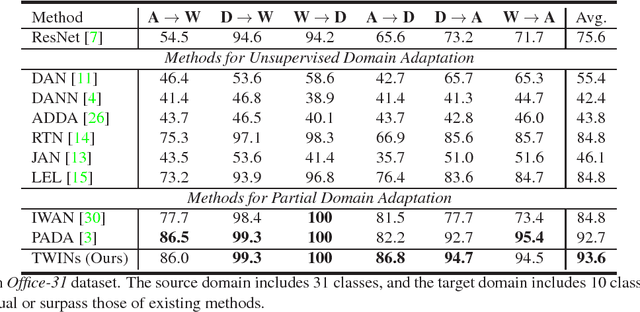
The task of unsupervised domain adaptation is proposed to transfer the knowledge of a label-rich domain (source domain) to a label-scarce domain (target domain). Matching feature distributions between different domains is a widely applied method for the aforementioned task. However, the method does not perform well when classes in the two domains are not identical. Specifically, when the classes of the target correspond to a subset of those of the source, target samples can be incorrectly aligned with the classes that exist only in the source. This problem setting is termed as partial domain adaptation (PDA). In this study, we propose a novel method called Two Weighted Inconsistency-reduced Networks (TWINs) for PDA. We utilize two classification networks to estimate the ratio of the target samples in each class with which a classification loss is weighted to adapt the classes present in the target domain. Furthermore, to extract discriminative features for the target, we propose to minimize the divergence between domains measured by the classifiers' inconsistency on target samples. We empirically demonstrate that reducing the inconsistency between two networks is effective for PDA and that our method outperforms other existing methods with a large margin in several datasets.
Strong-Weak Distribution Alignment for Adaptive Object Detection
Dec 12, 2018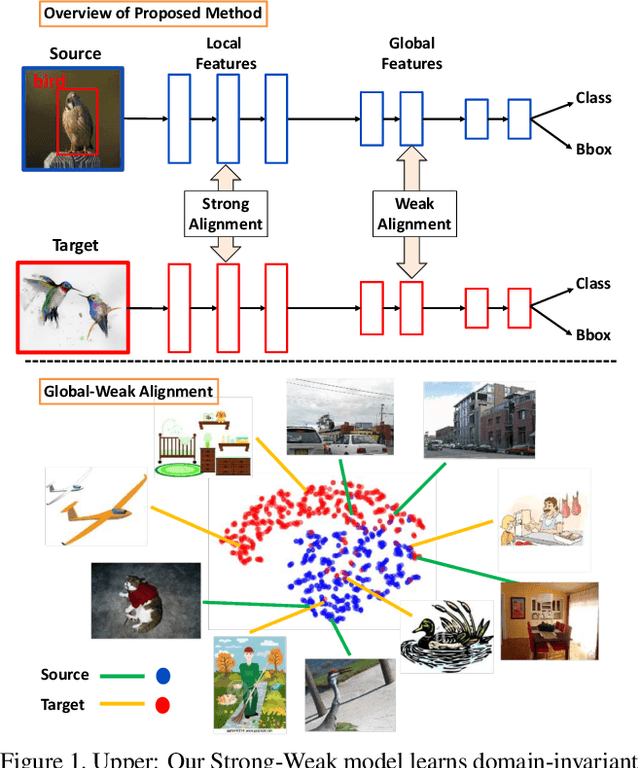

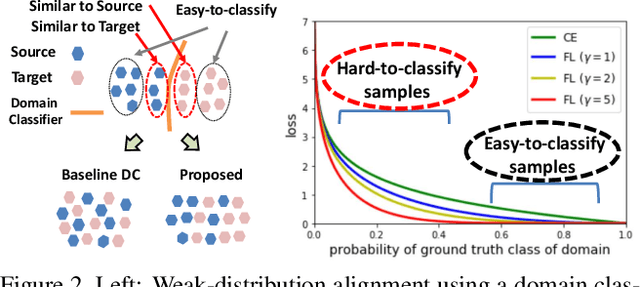
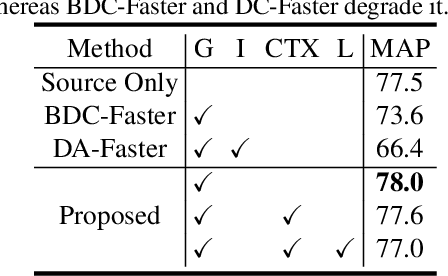
We propose an approach for unsupervised adaptation of object detectors from label-rich to label-poor domains which can significantly reduce annotation costs associated with detection. Recently, approaches that align distributions of source and target images using an adversarial loss have been proven effective for adapting object classifiers. However, for object detection, fully matching the entire distributions of source and target images to each other at the global image level may fail, as domains could have distinct scene layouts and different combinations of objects. On the other hand, strong matching of local features such as texture and color makes sense, as it does not change category level semantics. This motivates us to propose a novel approach for detector adaptation based on strong local alignment and weak global alignment. Our key contribution is the weak alignment model, which focuses the adversarial alignment loss on images that are globally similar and puts less emphasis on aligning images that are globally dissimilar. Additionally, we design the strong domain alignment model to only look at local receptive fields of the feature map. We empirically verify the effectiveness of our approach on several detection datasets comprising both large and small domain shifts.
Multichannel Semantic Segmentation with Unsupervised Domain Adaptation
Dec 11, 2018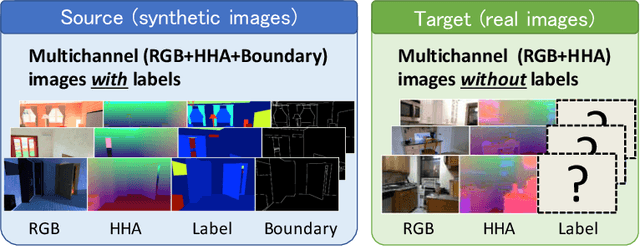
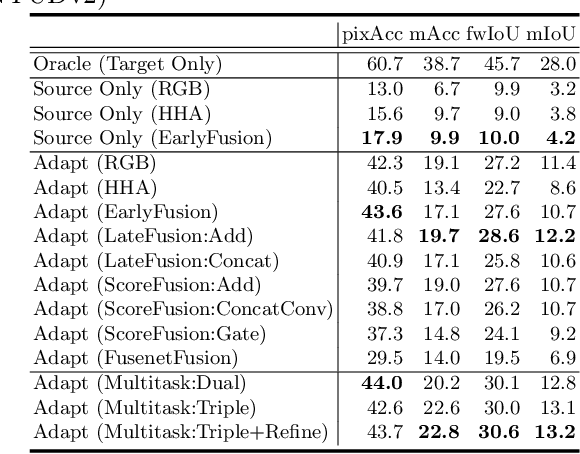
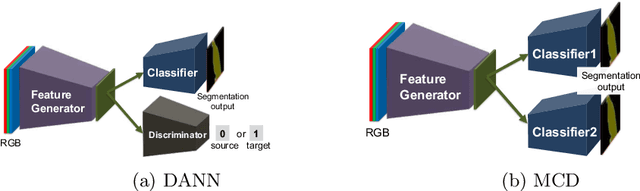
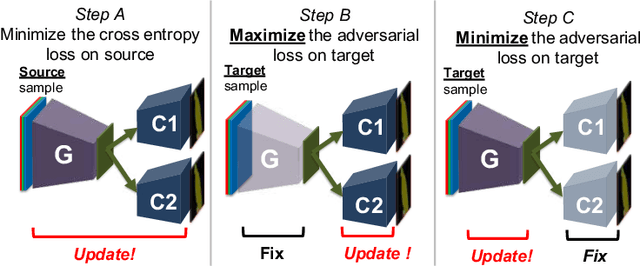
Most contemporary robots have depth sensors, and research on semantic segmentation with RGBD images has shown that depth images boost the accuracy of segmentation. Since it is time-consuming to annotate images with semantic labels per pixel, it would be ideal if we could avoid this laborious work by utilizing an existing dataset or a synthetic dataset which we can generate on our own. Robot motions are often tested in a synthetic environment, where multichannel (eg, RGB + depth + instance boundary) images plus their pixel-level semantic labels are available. However, models trained simply on synthetic images tend to demonstrate poor performance on real images. In order to address this, we propose two approaches that can efficiently exploit multichannel inputs combined with an unsupervised domain adaptation (UDA) algorithm. One is a fusion-based approach that uses depth images as inputs. The other is a multitask learning approach that uses depth images as outputs. We demonstrated that the segmentation results were improved by using a multitask learning approach with a post-process and created a benchmark for this task.
Conditional Video Generation Using Action-Appearance Captions
Dec 05, 2018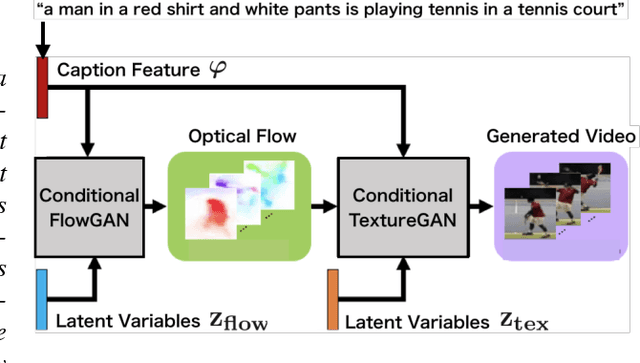

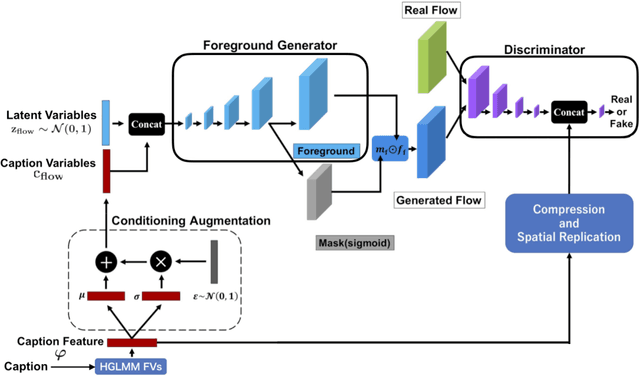

The field of automatic video generation has received a boost thanks to the recent Generative Adversarial Networks (GANs). However, most existing methods cannot control the contents of the generated video using a text caption, losing their usefulness to a large extent. This particularly affects human videos due to their great variety of actions and appearances. This paper presents Conditional Flow and Texture GAN (CFT-GAN), a GAN-based video generation method from action-appearance captions. We propose a novel way of generating video by encoding a caption (e.g., "a man in blue jeans is playing golf") in a two-stage generation pipeline. Our CFT-GAN uses such caption to generate an optical flow (action) and a texture (appearance) for each frame. As a result, the output video reflects the content specified in the caption in a plausible way. Moreover, to train our method, we constructed a new dataset for human video generation with captions. We evaluated the proposed method qualitatively and quantitatively via an ablation study and a user study. The results demonstrate that CFT-GAN is able to successfully generate videos containing the action and appearances indicated in the captions.
Learning to Explain with Complemental Examples
Dec 04, 2018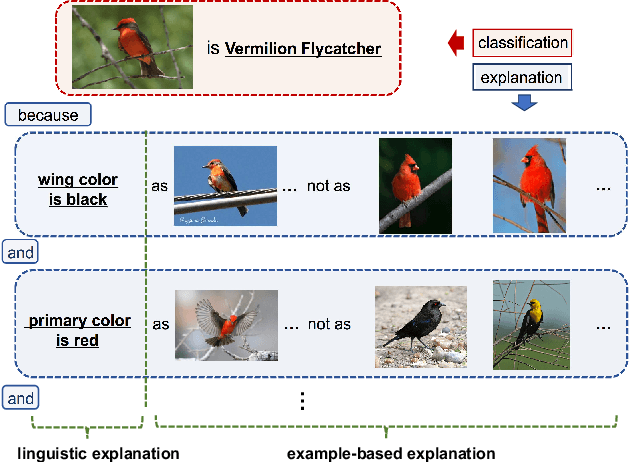
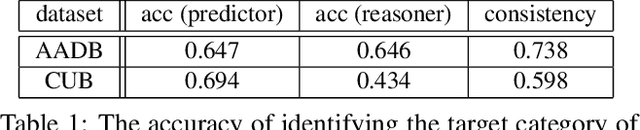
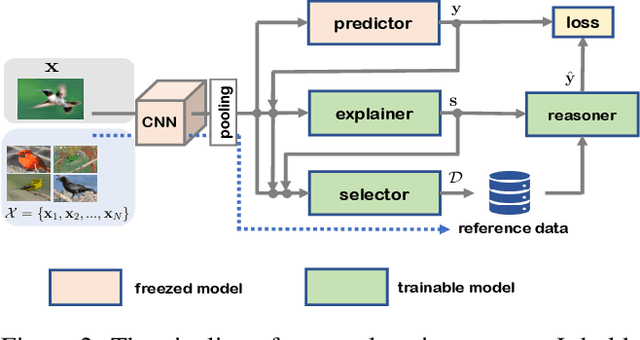

This paper addresses the generation of explanations with visual examples. Given an input sample, we build a system that not only classifies it to a specific category, but also outputs linguistic explanations and a set of visual examples that render the decision interpretable. Focusing especially on the complementarity of the multimodal information, i.e., linguistic and visual examples, we attempt to achieve it by maximizing the interaction information, which provides a natural definition of complementarity from an information theoretical viewpoint. We propose a novel framework to generate complemental explanations, on which the joint distribution of the variables to explain, and those to be explained is parameterized by three different neural networks: predictor, linguistic explainer, and example selector. Explanation models are trained collaboratively to maximize the interaction information to ensure the generated explanation are complemental to each other for the target. The results of experiments conducted on several datasets demonstrate the effectiveness of the proposed method.
Multimodal Explanations by Predicting Counterfactuality in Videos
Dec 04, 2018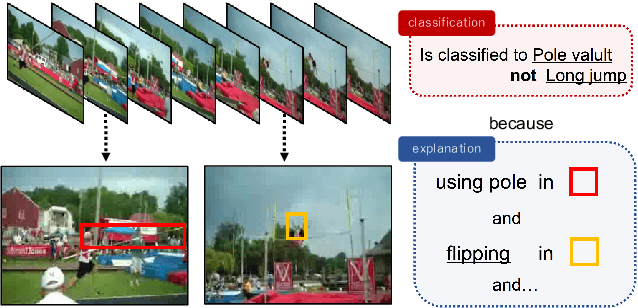
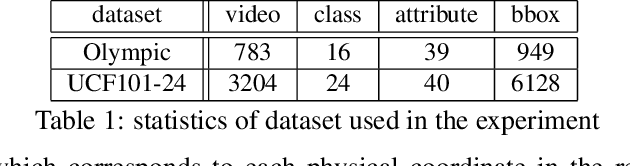
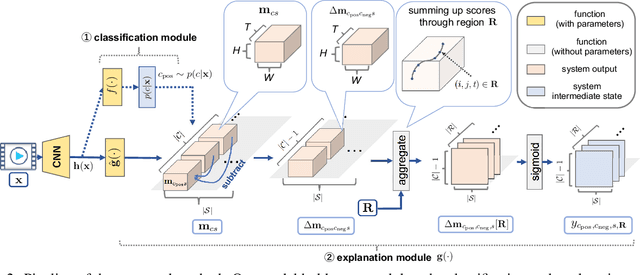
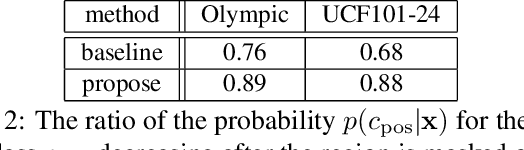
This study addresses generating counterfactual explanations with multimodal information. Our goal is not only to classify a video into a specific category, but also to provide explanations on why it is not predicted as part of a specific class with a combination of visual-linguistic information. Requirements that the expected output should satisfy are referred to as counterfactuality in this paper: (1) Compatibility of visual-linguistic explanations, and (2) Positiveness/negativeness for the specific positive/negative class. Exploiting a spatio-temporal region (tube) and an attribute as visual and linguistic explanations respectively, the explanation model is trained to predict the counterfactuality for possible combinations of multimodal information in a post-hoc manner. The optimization problem, which appears during the training/inference process, can be efficiently solved by inserting a novel neural network layer, namely the maximum subpath layer. We demonstrated the effectiveness of this method by comparison with a baseline of the action-recognition datasets extended for this task. Moreover, we provide information-theoretical insight into the proposed method.
Towards Human-Friendly Referring Expression Generation
Nov 29, 2018
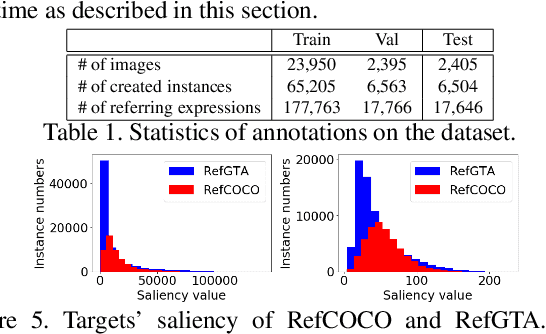
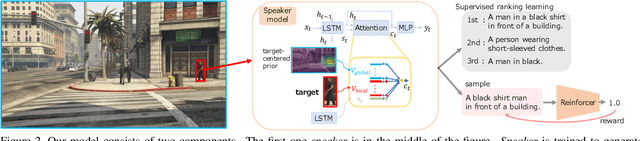
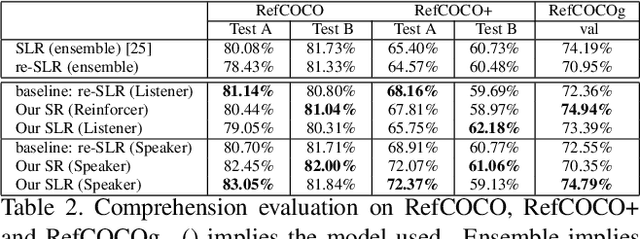
This paper addresses the generation of referring expressions that not only refer to objects correctly but also ease human comprehension. As the composition of an image becomes more complicated and a target becomes relatively less salient, identifying referred objects comes more difficult. However, the existing studies regarded all sentences that refer to objects correctly as equally good, ignoring whether they are easily understood by humans. If the target is not salient, humans utilize relationships with the salient contexts around it to help listeners to comprehend it better. To derive these information from human annotations, our model is designed to extract information from the inside and outside of the target. Moreover, we regard that sentences that are easily understood are those that are comprehended correctly and quickly by humans. We optimized it by using the time required to locate the referred objects by humans and their accuracies. To evaluate our system, we created a new referring expression dataset whose images were acquired from Grand Theft Auto V (GTA V), limiting targets to persons. Our proposed method outperformed previous methods both on machine evaluation and on crowd-sourced human evaluation. The source code and dataset will be available soon.
Label-Noise Robust Generative Adversarial Networks
Nov 27, 2018


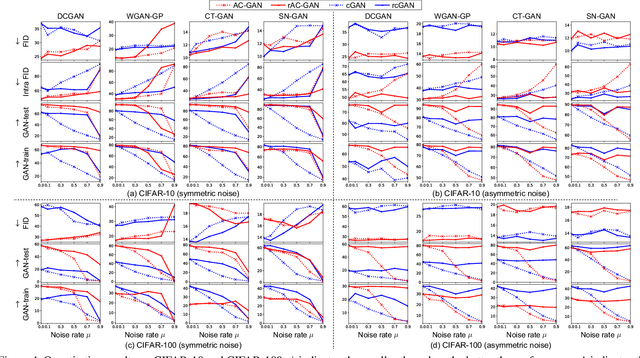
Generative adversarial networks (GANs) are a framework that learns a generative distribution through adversarial training. Recently, their class conditional extensions (e.g., conditional GAN (cGAN) and auxiliary classifier GAN (AC-GAN)) have attracted much attention owing to their ability to learn the disentangled representations and to improve the training stability. However, their training requires the availability of large-scale accurate class-labeled data, which are often laborious or impractical to collect in a real-world scenario. To remedy the drawback, we propose a novel family of GANs called label-noise robust GANs (rGANs), which, by incorporating a noise transition model, can learn a clean label conditional generative distribution even when training labels are noisy. In particular, we propose two variants: rAC-GAN, which is a bridging model between AC-GAN and the noise-robust classification model, and rcGAN, which is an extension of cGAN and is guaranteed to learn the clean label conditional distribution in an optimal condition. In addition to providing the theoretical background, we demonstrate the effectiveness of our models through extensive experiments using diverse GAN configurations, various noise settings, and multiple evaluation metrics (in which we tested 402 patterns in total).