 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBinary Classification with Bounded Abstention Rate
May 23, 2019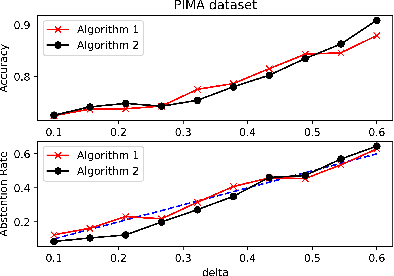
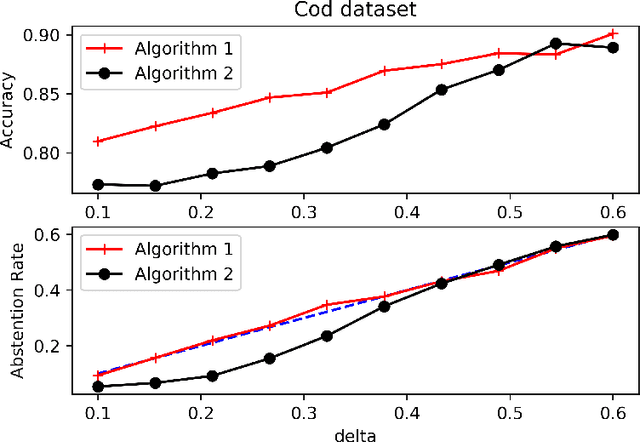
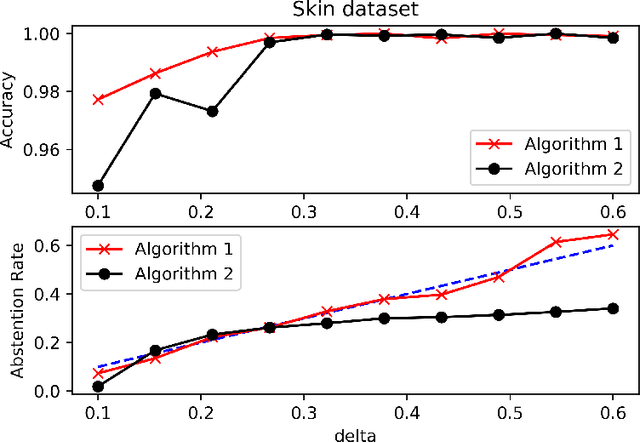
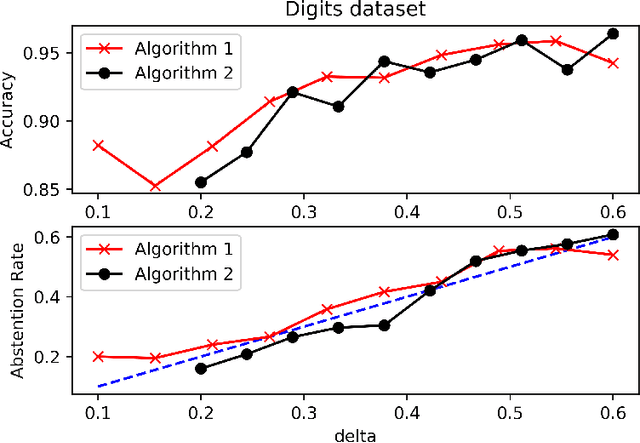
We consider the problem of binary classification with abstention in the relatively less studied \emph{bounded-rate} setting. We begin by obtaining a characterization of the Bayes optimal classifier for an arbitrary input-label distribution $P_{XY}$. Our result generalizes and provides an alternative proof for the result first obtained by \cite{chow1957optimum}, and then re-derived by \citet{denis2015consistency}, under a continuity assumption on $P_{XY}$. We then propose a plug-in classifier that employs unlabeled samples to decide the region of abstention and derive an upper-bound on the excess risk of our classifier under standard \emph{H\"older smoothness} and \emph{margin} assumptions. Unlike the plug-in rule of \citet{denis2015consistency}, our constructed classifier satisfies the abstention constraint with high probability and can also deal with discontinuities in the empirical cdf. We also derive lower-bounds that demonstrate the minimax near-optimality of our proposed algorithm. To address the excessive complexity of the plug-in classifier in high dimensions, we propose a computationally efficient algorithm that builds upon prior work on convex loss surrogates, and obtain bounds on its excess risk in the \emph{realizable} case. We empirically compare the performance of the proposed algorithm with a baseline on a number of UCI benchmark datasets.
Multiscale Gaussian Process Level Set Estimation
Feb 26, 2019In this paper, the problem of estimating the level set of a black-box function from noisy and expensive evaluation queries is considered. A new algorithm for this problem in the Bayesian framework with a Gaussian Process (GP) prior is proposed. The proposed algorithm employs a hierarchical sequence of partitions to explore different regions of the search space at varying levels of detail depending upon their proximity to the level set boundary. It is shown that this approach results in the algorithm having a low complexity implementation whose computational cost is significantly smaller than the existing algorithms for higher dimensional search space $\X$. Furthermore, high probability bounds on a measure of discrepancy between the estimated level set and the true level set for the the proposed algorithm are obtained, which are shown to be strictly better than the existing guarantees for a large class of GPs. In the process, a tighter characterization of the information gain of the proposed algorithm is obtained which takes into account the structured nature of the evaluation points. This approach improves upon the existing technique of bounding the information gain with maximum information gain.
* 15 pages
Peer-to-peer Federated Learning on Graphs
Jan 31, 2019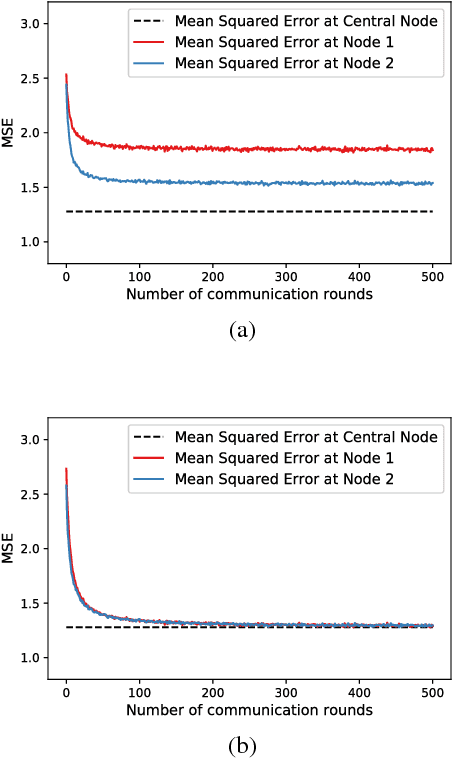
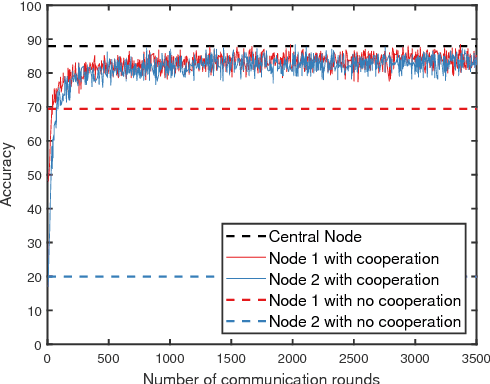

We consider the problem of training a machine learning model over a network of nodes in a fully decentralized framework. The nodes take a Bayesian-like approach via the introduction of a belief over the model parameter space. We propose a distributed learning algorithm in which nodes update their belief by aggregate information from their one-hop neighbors to learn a model that best fits the observations over the entire network. In addition, we also obtain sufficient conditions to ensure that the probability of error is small for every node in the network. We discuss approximations required for applying this algorithm to train Deep Neural Networks (DNNs). Experiments on training linear regression model and on training a DNN show that the proposed learning rule algorithm provides a significant improvement in the accuracy compared to the case where nodes learn without cooperation.
Active Learning and CSI acquisition for mmWave Initial Alignment
Dec 19, 2018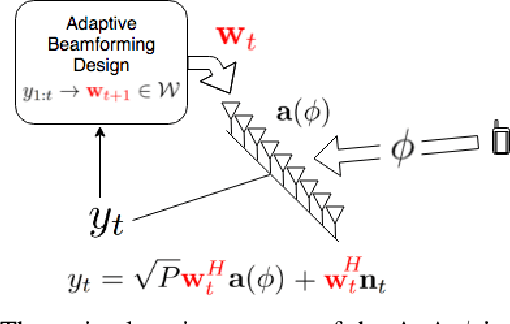
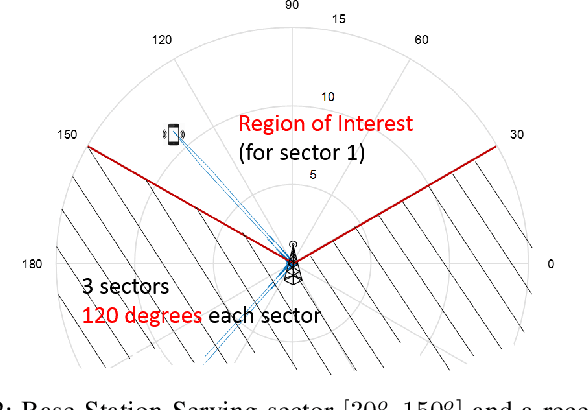
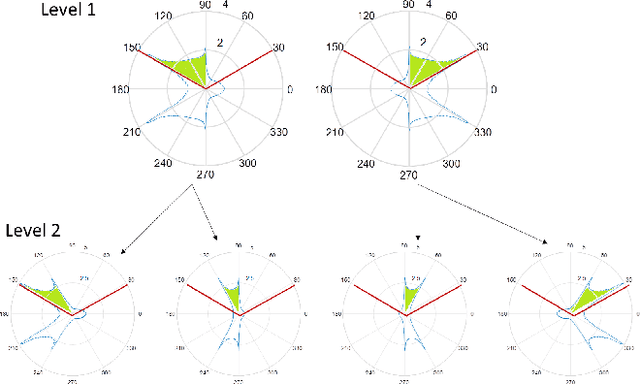
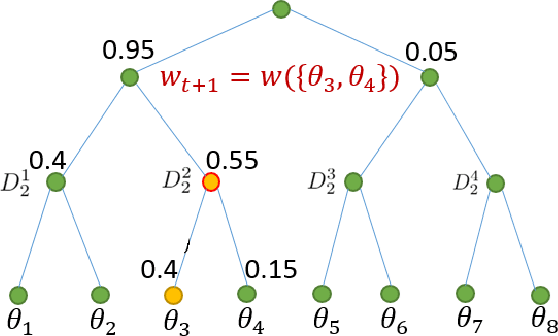
Millimeter wave (mmWave) communication with large antenna arrays is a promising technique to enable extremely high data rates due to large available bandwidth. Given the knowledge of an optimal directional beamforming vector, large antenna arrays have been shown to overcome both the severe signal attenuation in mmWave. However, fundamental limits and achievable learning of an optimal beamforming vector remain. This paper considers the problem of adaptive and sequential optimization of the beamforming vectors during the initial access phase of communication. With a single-path channel model, the problem is reduced to actively learning the Angle-of-Arrival (AoA) of the signal sent from the user to the Base Station (BS). Drawing on the recent results in the design of a hierarchical beamforming codebook [1], sequential measurement dependent noisy search [2], and active learning from an imperfect labeler [3], an adaptive and sequential alignment algorithm is proposed. For any given resolution and error probability of the estimated AoA, an upper bound on the expected search time of the proposed algorithm is derived via the Extrinsic Jensen Shannon Divergence. The upper bound demonstrates that the search time of the proposed algorithm asymptotically matches the performance of the noiseless bisection search up to a constant factor characterizing the AoA acquisition rate. Furthermore, the acquired AoA error probability decays exponentially fast with the search time with an exponent that is a decreasing function of the acquisition rate.Numerically, the proposed algorithm is compared with prior work where a significant improvement of the system communication rate is observed. Most notably, in the relevant regime of low (- 10dB to 5dB) raw SNR, this establishes the first practically viable solution for initial access and, hence, the first demonstration of stand-alone mmWave communication.
SIGNet: Semantic Instance Aided Unsupervised 3D Geometry Perception
Dec 13, 2018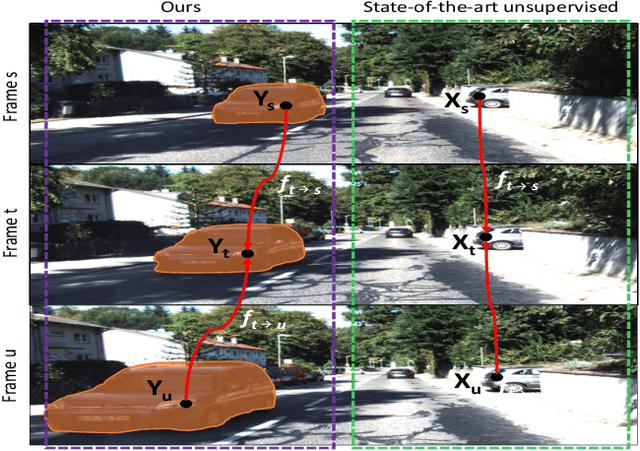
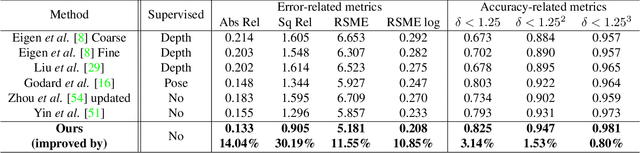
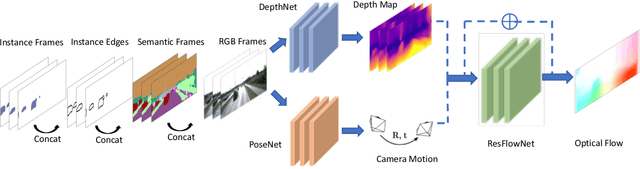
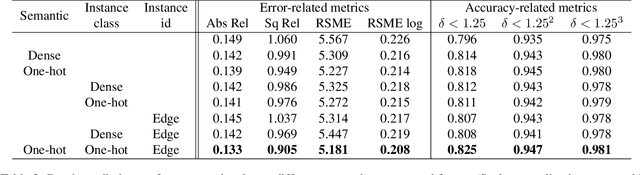
Unsupervised learning for visual perception of 3D geometry is of great interest to autonomous systems. Recent works on unsupervised learning have made considerable progress on geometry perception; however, they perform poorly on dynamic objects and scenarios with dark and noisy environments. In contrast, supervised learning algorithms, which are robust, require large labeled geometric data-set. This paper introduces SIGNet, a novel framework that provides robust geometry perception without requiring geometrically informative labels. Specifically, SIGNet integrates semantic information to make unsupervised robust geometric predictions for dynamic objects in low lighting and noisy environments. SIGNet is shown to improve upon the state of art unsupervised learning for geometry perception by 30% (in squared relative error for depth prediction). In particular, SIGNet improves the dynamic object class performance by 39% in depth prediction and 29% in flow prediction.
Efficient Video Understanding via Layered Multi Frame-Rate Analysis
Nov 24, 2018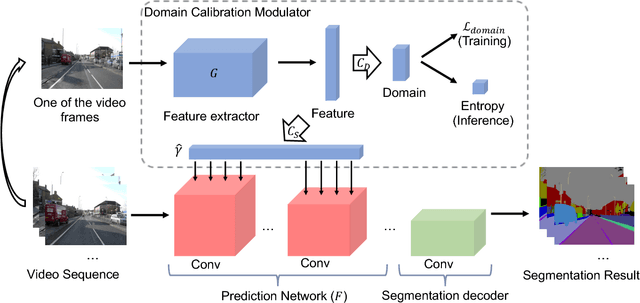
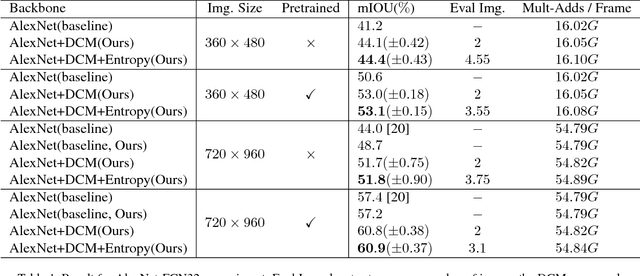
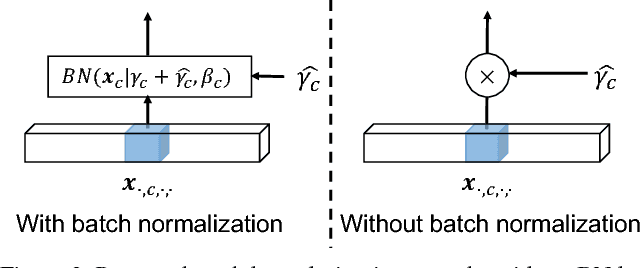
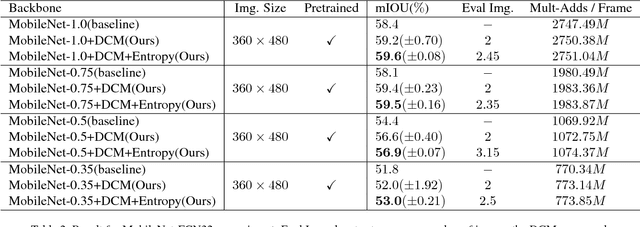
One of the greatest challenges in the design of a real-time perception system for autonomous driving vehicles and drones is the conflicting requirement of safety (high prediction accuracy) and efficiency. Traditional approaches use a single frame rate for the entire system. Motivated by the observation that the lack of robustness against environmental factors is the major weakness of compact ConvNet architectures, we propose a dual frame-rate system that brings in the best of both worlds: A modulator stream that executes an expensive models robust to environmental factors at a low frame rate to extract slowly changing features describing the environment, and a prediction stream that executes a light-weight model at real-time to extract transient signals that describes particularities of the current frame. The advantage of our design is validated by our extensive empirical study, showing that our solution leads to consistent improvements using a variety of backbone architecture choice and input resolutions. These findings suggest multiple frame-rate systems as a promising direction in designing efficient perception for autonomous agents.
Authentication of cyber-physical systems under learning-based attacks
Sep 17, 2018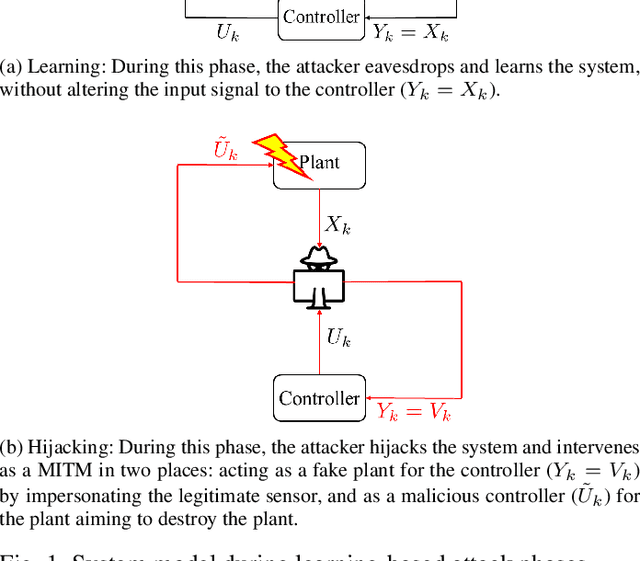
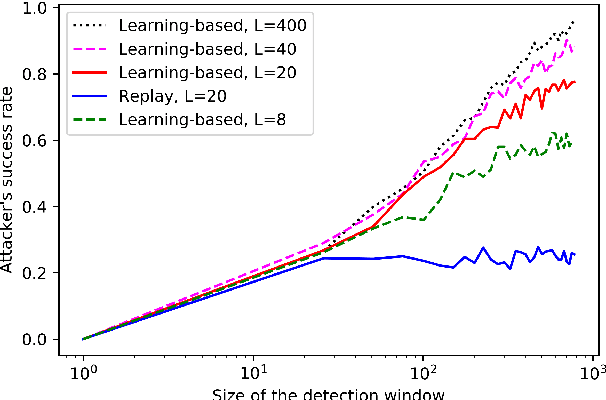
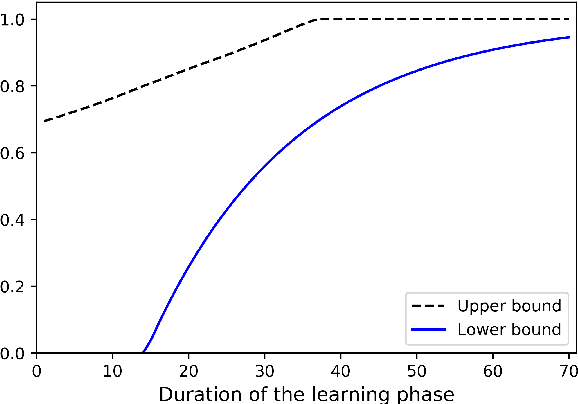
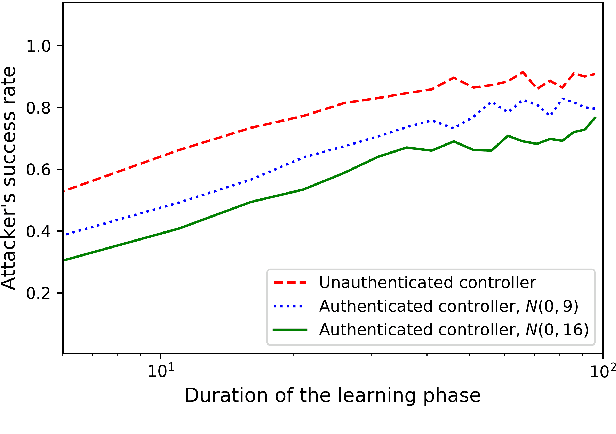
The problem of attacking and authenticating cyber-physical systems is considered. This paper concentrates on the case of a scalar, discrete-time, time-invariant, linear plant under an attack which can override the sensor and the controller signals. Prior works assumed the system was known to all parties and developed watermark-based methods. In contrast, in this paper the attacker needs to learn the open-loop gain in order to carry out a successful attack. A class of two-phase attacks are considered: during an exploration phase, the attacker passively eavesdrops and learns the plant dynamics, followed by an exploitation phase, during which the attacker hijacks the input to the plant and replaces the input to the controller with a carefully crafted fictitious sensor reading with the aim of destabilizing the plant without being detected by the controller. For an authentication test that examines the variance over a time window, tools from information theory and statistics are utilized to derive bounds on the detection and deception probabilities with and without a watermark signal, when the attacker uses an arbitrary learning algorithm to estimate the open-loop gain of the plant.
DeepFense: Online Accelerated Defense Against Adversarial Deep Learning
Aug 21, 2018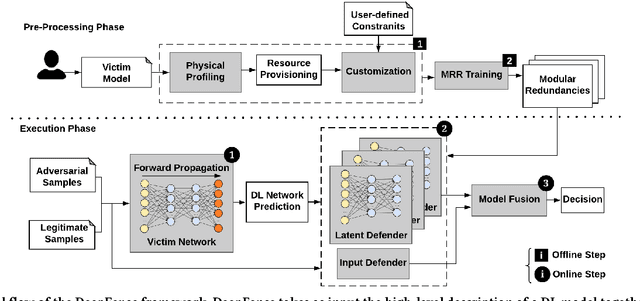


Recent advances in adversarial Deep Learning (DL) have opened up a largely unexplored surface for malicious attacks jeopardizing the integrity of autonomous DL systems. With the wide-spread usage of DL in critical and time-sensitive applications, including unmanned vehicles, drones, and video surveillance systems, online detection of malicious inputs is of utmost importance. We propose DeepFense, the first end-to-end automated framework that simultaneously enables efficient and safe execution of DL models. DeepFense formalizes the goal of thwarting adversarial attacks as an optimization problem that minimizes the rarely observed regions in the latent feature space spanned by a DL network. To solve the aforementioned minimization problem, a set of complementary but disjoint modular redundancies are trained to validate the legitimacy of the input samples in parallel with the victim DL model. DeepFense leverages hardware/software/algorithm co-design and customized acceleration to achieve just-in-time performance in resource-constrained settings. The proposed countermeasure is unsupervised, meaning that no adversarial sample is leveraged to train modular redundancies. We further provide an accompanying API to reduce the non-recurring engineering cost and ensure automated adaptation to various platforms. Extensive evaluations on FPGAs and GPUs demonstrate up to two orders of magnitude performance improvement while enabling online adversarial sample detection.
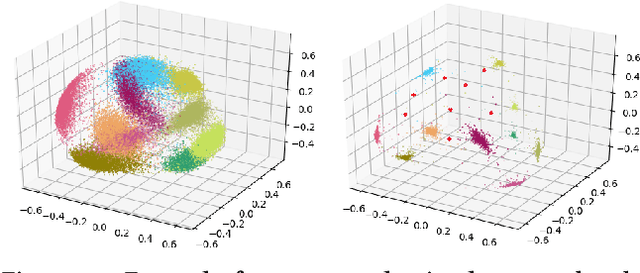
Active Learning with Logged Data
Jun 13, 2018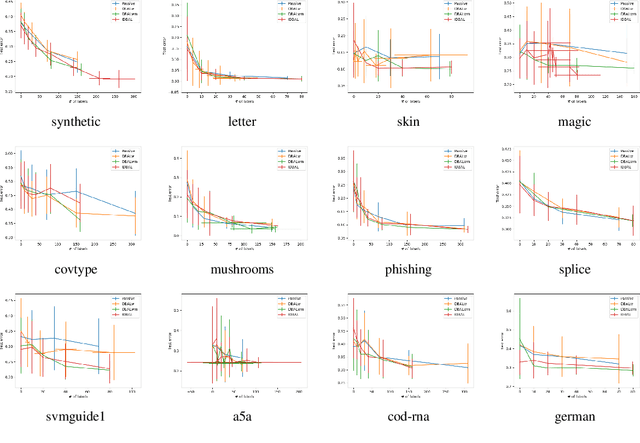
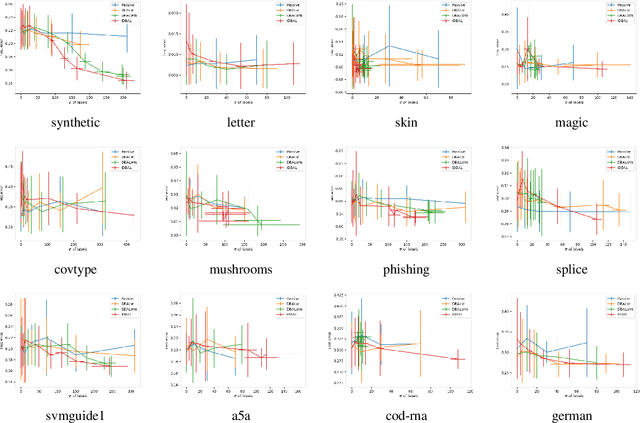
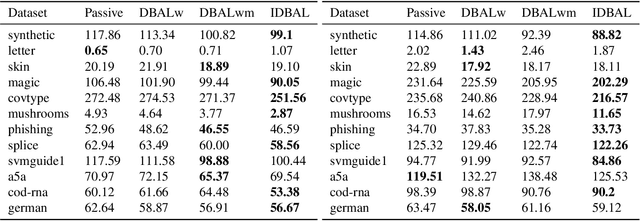
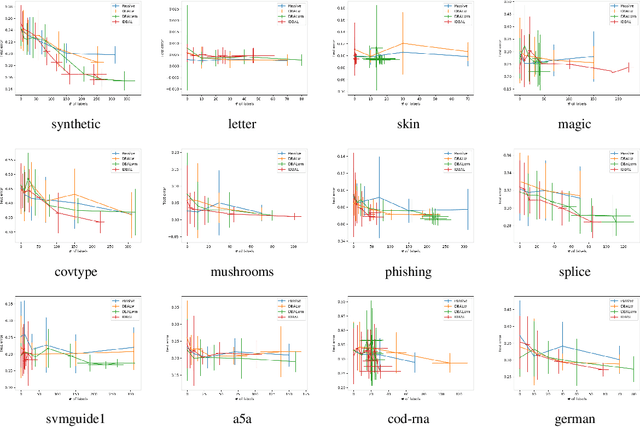
We consider active learning with logged data, where labeled examples are drawn conditioned on a predetermined logging policy, and the goal is to learn a classifier on the entire population, not just conditioned on the logging policy. Prior work addresses this problem either when only logged data is available, or purely in a controlled random experimentation setting where the logged data is ignored. In this work, we combine both approaches to provide an algorithm that uses logged data to bootstrap and inform experimentation, thus achieving the best of both worlds. Our work is inspired by a connection between controlled random experimentation and active learning, and modifies existing disagreement-based active learning algorithms to exploit logged data.
Gaussian Process bandits with adaptive discretization
Jan 05, 2018
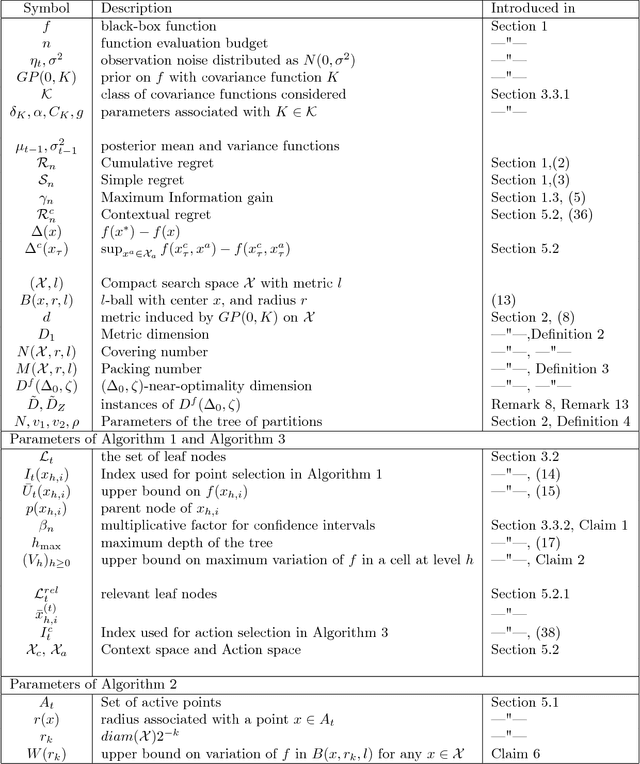
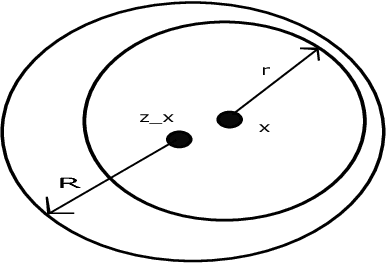
In this paper, the problem of maximizing a black-box function $f:\mathcal{X} \to \mathbb{R}$ is studied in the Bayesian framework with a Gaussian Process (GP) prior. In particular, a new algorithm for this problem is proposed, and high probability bounds on its simple and cumulative regret are established. The query point selection rule in most existing methods involves an exhaustive search over an increasingly fine sequence of uniform discretizations of $\mathcal{X}$. The proposed algorithm, in contrast, adaptively refines $\mathcal{X}$ which leads to a lower computational complexity, particularly when $\mathcal{X}$ is a subset of a high dimensional Euclidean space. In addition to the computational gains, sufficient conditions are identified under which the regret bounds of the new algorithm improve upon the known results. Finally an extension of the algorithm to the case of contextual bandits is proposed, and high probability bounds on the contextual regret are presented.